leveldb 学习记录(四)Log文件
前文记录
leveldb 学习记录(一) skiplist
leveldb 学习记录(二) Sliceleveldb 学习记录(三) MemTable 与 Immutable Memtableleveldb 学习记录(四) skiplist补完
KV数据库中 大部分是采用内存存储,如果中途发生意外情况,没有dump到磁盘的记录就可能会丢失,但是如果采用log记录操作便可以按照log记录进行这部分的数据恢复
所以,我们在每次操作kv记录的时候都需要将操作记录到log文件中。
每个日志文件都会切分为32KB的BLOCK,BLOCK来记录那些操作RECORD,但是不保证RECORD长度固定。所以有了以下设计
record := checksum: uint32 // crc32c of type and data[]
length: uint16
type: uint8 // One of FULL, FIRST, MIDDLE, LAST
data: uint8[length]
同时也不保证RECORD不跨BLOCK记录
所以RECORD的类型有 FULL, FIRST, MIDDLE, LAST四种类型
当一个RECORD在一个BLOCK内 那么它的类型是FULL
否则跨BLOCK记录RECORD的时候 记录可以分为FIRST, MIDDLE, LAST
如图

上图可以看到LOG文件由三个BLOCK组成BLOCK1 BLOCK2 BLOCK3
不同的RECORD 分配如下
BLOCK1 RECORDA整个数据都在BLOCK1中,所以他的类型是FULL 。接着是 RECORDB的部分数据 类型为FIRST
BLOCK2 RECORDB的数据, 由于部分数据在BLOCK1和BLOCK3中,所以这部分RECORDB的类型是MIDDLE
BLOCK3 首先是RECORDB的数据,类型是LAST。 紧接着是RECORDC,这部分数据类型为FULL
record分为校验和,长度,类型和数据。
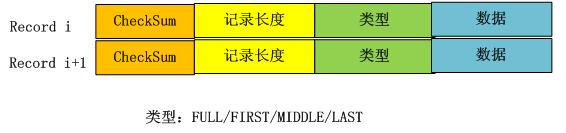
对应的相关LOG 数据结构如下
- enum RecordType {
- // Zero is reserved for preallocated files
- kZeroType = ,
- kFullType = ,
- // For fragments
- kFirstType = ,
- kMiddleType = ,
- kLastType =
- };
- static const int kMaxRecordType = kLastType;
- static const int kBlockSize = ;
- // Header is checksum (4 bytes), type (1 byte), length (2 bytes).
- static const int kHeaderSize = + + ;
- }
- }
写日志类Writer:
头文件
- class Writer {
- public:
- // Create a writer that will append data to "*dest".
- // "*dest" must be initially empty.
- // "*dest" must remain live while this Writer is in use.
- explicit Writer(WritableFile* dest);
- ~Writer();
- Status AddRecord(const Slice& slice);
- private:
- WritableFile* dest_;
- int block_offset_; // Current offset in block
- // crc32c values for all supported record types. These are
- // pre-computed to reduce the overhead of computing the crc of the
- // record type stored in the header.
- uint32_t type_crc_[kMaxRecordType + ];
- Status EmitPhysicalRecord(RecordType type, const char* ptr, size_t length);
- // No copying allowed
- Writer(const Writer&);
- void operator=(const Writer&);
- };
除开构造函数,主要来看看AddRecord和EmitPhysicalRecord函数
- Status Writer::AddRecord(const Slice& slice) {
- const char* ptr = slice.data();
- size_t left = slice.size();
- // Fragment the record if necessary and emit it. Note that if slice
- // is empty, we still want to iterate once to emit a single
- // zero-length record
- Status s;
- bool begin = true;
- do {
- const int leftover = kBlockSize - block_offset_; //剩余要填充的数据长度 是一个BLOCK的长度减去块内已经填充的长度
- assert(leftover >= );
- if (leftover < kHeaderSize) { //要填充的长度大于7 则在下一个BLOCK进行记录 (因为checksum 4字节 length2字节 type 1字节,光是记录信息已经需要7个字节)
- // Switch to a new block
- if (leftover > ) {
- // Fill the trailer (literal below relies on kHeaderSize being 7)
- assert(kHeaderSize == );
- dest_->Append(Slice("\x00\x00\x00\x00\x00\x00", leftover));
- }
- block_offset_ = ;
- }
- // Invariant: we never leave < kHeaderSize bytes in a block.
- assert(kBlockSize - block_offset_ - kHeaderSize >= );
- const size_t avail = kBlockSize - block_offset_ - kHeaderSize;
- const size_t fragment_length = (left < avail) ? left : avail; //根据能否在本BLOCK填充完毕 选择填充长度为left 或者 avail
- RecordType type;
- const bool end = (left == fragment_length);
- if (begin && end) { //beg end在用一个BLOCK里 record的type肯定是FULL
- type = kFullType;
- } else if (begin) { //本BLOCK只有beg 那么record的type 就是FIRST
- type = kFirstType;
- } else if (end) { //本BLOCK只有end 那么record的TYPE就是last
- type = kLastType;
- } else {
- type = kMiddleType; //本BLOCK 没有beg end 那么record填充了整个BLOCK type是MIDDLE
- }
- s = EmitPhysicalRecord(type, ptr, fragment_length); //提交到log文件记录
- ptr += fragment_length;
- left -= fragment_length;
- begin = false;
- } while (s.ok() && left > );
- return s;
- }
- Status Writer::EmitPhysicalRecord(RecordType t, const char* ptr, size_t n) {
- assert(n <= 0xffff); // Must fit in two bytes
- assert(block_offset_ + kHeaderSize + n <= kBlockSize);
- // Format the header
- char buf[kHeaderSize];
- buf[] = static_cast<char>(n & 0xff); //长度低8位
- buf[] = static_cast<char>(n >> ); //长度高8位
- buf[] = static_cast<char>(t); //type
- // Compute the crc of the record type and the payload.
- uint32_t crc = crc32c::Extend(type_crc_[t], ptr, n); //校验和
- crc = crc32c::Mask(crc); // Adjust for storage
- EncodeFixed32(buf, crc);
- // Write the header and the payload
- Status s = dest_->Append(Slice(buf, kHeaderSize)); //数据信息写入
- if (s.ok()) {
- s = dest_->Append(Slice(ptr, n)); //数据写入
- if (s.ok()) {
- s = dest_->Flush();
- }
- }
- block_offset_ += kHeaderSize + n;
- return s;
- }
//========================================================
读日志类Reader:
日志读取代码中还有一个Reporter 类用于报告错误
- class Reader {
- public:
- // Interface for reporting errors.
- class Reporter {
- public:
- virtual ~Reporter();
- // Some corruption was detected. "size" is the approximate number
- // of bytes dropped due to the corruption.
- virtual void Corruption(size_t bytes, const Status& status) = ;
- };
- // Create a reader that will return log records from "*file".
- // "*file" must remain live while this Reader is in use.
- //
- // If "reporter" is non-NULL, it is notified whenever some data is
- // dropped due to a detected corruption. "*reporter" must remain
- // live while this Reader is in use.
- //
- // If "checksum" is true, verify checksums if available.
- //
- // The Reader will start reading at the first record located at physical
- // position >= initial_offset within the file.
- Reader(SequentialFile* file, Reporter* reporter, bool checksum,
- uint64_t initial_offset);
- ~Reader();
- // Read the next record into *record. Returns true if read
- // successfully, false if we hit end of the input. May use
- // "*scratch" as temporary storage. The contents filled in *record
- // will only be valid until the next mutating operation on this
- // reader or the next mutation to *scratch.
- bool ReadRecord(Slice* record, std::string* scratch);
- // Returns the physical offset of the last record returned by ReadRecord.
- //
- // Undefined before the first call to ReadRecord.
- uint64_t LastRecordOffset();
- private:
- SequentialFile* const file_;
- Reporter* const reporter_;
- bool const checksum_;
- char* const backing_store_;
- Slice buffer_;
- bool eof_; // Last Read() indicated EOF by returning < kBlockSize
- // Offset of the last record returned by ReadRecord.
- uint64_t last_record_offset_;
- // Offset of the first location past the end of buffer_.
- uint64_t end_of_buffer_offset_;
- // Offset at which to start looking for the first record to return
- uint64_t const initial_offset_;
- // Extend record types with the following special values
- enum {
- kEof = kMaxRecordType + ,
- // Returned whenever we find an invalid physical record.
- // Currently there are three situations in which this happens:
- // * The record has an invalid CRC (ReadPhysicalRecord reports a drop)
- // * The record is a 0-length record (No drop is reported)
- // * The record is below constructor's initial_offset (No drop is reported)
- kBadRecord = kMaxRecordType +
- };
- // Skips all blocks that are completely before "initial_offset_".
- //
- // Returns true on success. Handles reporting.
- bool SkipToInitialBlock();
- // Return type, or one of the preceding special values
- unsigned int ReadPhysicalRecord(Slice* result);
- // Reports dropped bytes to the reporter.
- // buffer_ must be updated to remove the dropped bytes prior to invocation.
- void ReportCorruption(size_t bytes, const char* reason);
- void ReportDrop(size_t bytes, const Status& reason);
- // No copying allowed
- Reader(const Reader&);
- void operator=(const Reader&);
- };
关键函数是bool Reader::ReadRecord(Slice* record, std::string* scratch)
我的理解中 只要除开完全被 initial_offset_长度覆盖的BLOCK ,
剩下的BLOCK依次读取记录,根据type是FULL MIDDLE FIRST LAST 决定是否继续读取即可
但是源码中的例外情形太多,看的不是太明白,这个留待实际操作在深入研究吧
- bool Reader::ReadRecord(Slice* record, std::string* scratch) {
- if (last_record_offset_ < initial_offset_) { //实际上整个工程中initial_offset_一直为0 ,
- if (!SkipToInitialBlock()) { //block_start_location圆整为包含initial_offset_的BLOCK的偏移
- return false;
- }
- }
- scratch->clear();
- record->clear();
- bool in_fragmented_record = false;
- // Record offset of the logical record that we're reading
- // 0 is a dummy value to make compilers happy
- uint64_t prospective_record_offset = ;
- Slice fragment;
- while (true) {
- uint64_t physical_record_offset = end_of_buffer_offset_ - buffer_.size();
- const unsigned int record_type = ReadPhysicalRecord(&fragment);
- switch (record_type) {
- case kFullType: //一次性读取FULL类型的record 直接返回成功
- if (in_fragmented_record) {
- // Handle bug in earlier versions of log::Writer where
- // it could emit an empty kFirstType record at the tail end
- // of a block followed by a kFullType or kFirstType record
- // at the beginning of the next block.
- if (scratch->empty()) {
- in_fragmented_record = false;
- } else {
- ReportCorruption(scratch->size(), "partial record without end(1)");
- }
- }
- prospective_record_offset = physical_record_offset;
- scratch->clear();
- *record = fragment;
- last_record_offset_ = prospective_record_offset;
- return true;
- case kFirstType: //读取到FIRST类型的record string.assign 然后继续
- if (in_fragmented_record) {
- // Handle bug in earlier versions of log::Writer where
- // it could emit an empty kFirstType record at the tail end
- // of a block followed by a kFullType or kFirstType record
- // at the beginning of the next block.
- if (scratch->empty()) {
- in_fragmented_record = false;
- } else {
- ReportCorruption(scratch->size(), "partial record without end(2)");
- }
- }
- prospective_record_offset = physical_record_offset;
- scratch->assign(fragment.data(), fragment.size());
- in_fragmented_record = true;
- break;
- case kMiddleType: //读取到MIDDLE类型的record string.append 然后继续
- if (!in_fragmented_record) {
- ReportCorruption(fragment.size(),
- "missing start of fragmented record(1)");
- } else {
- scratch->append(fragment.data(), fragment.size());
- }
- break;
- case kLastType: //读取到LAST 类型record string.append
- if (!in_fragmented_record) {
- ReportCorruption(fragment.size(),
- "missing start of fragmented record(2)");
- } else {
- scratch->append(fragment.data(), fragment.size());
- *record = Slice(*scratch);
- last_record_offset_ = prospective_record_offset;
- return true;
- }
- break;
- case kEof:
- if (in_fragmented_record) {
- ReportCorruption(scratch->size(), "partial record without end(3)");
- scratch->clear();
- }
- return false;
- case kBadRecord:
- if (in_fragmented_record) {
- ReportCorruption(scratch->size(), "error in middle of record");
- in_fragmented_record = false;
- scratch->clear();
- }
- break;
- default: {
- char buf[];
- snprintf(buf, sizeof(buf), "unknown record type %u", record_type);
- ReportCorruption(
- (fragment.size() + (in_fragmented_record ? scratch->size() : )),
- buf);
- in_fragmented_record = false;
- scratch->clear();
- break;
- }
- }
- }
- return false;
- }
参考:
https://blog.csdn.net/tankles/article/details/7663873
leveldb 学习记录(四)Log文件的更多相关文章
- leveldb 学习记录(四) skiplist补与变长数字
在leveldb 学习记录(一) skiplist 已经将skiplist的插入 查找等操作流程用图示说明 这里在介绍 下skiplist的代码 里面有几个模块 template<typenam ...
- JavaScript学习记录四
title: JavaScript学习记录四 toc: true date: 2018-09-16 20:31:22 --<JavaScript高级程序设计(第2版)>学习笔记 要多查阅M ...
- leveldb 学习记录(三) MemTable 与 Immutable Memtable
前文: leveldb 学习记录(一) skiplist leveldb 学习记录(二) Slice 存储格式: leveldb数据在内存中以 Memtable存储(核心结构是skiplist 已介绍 ...
- 4.VUE前端框架学习记录四:Vue组件化编码2
VUE前端框架学习记录四:Vue组件化编码2文字信息没办法描述清楚,主要看编码Demo里面,有附带完整的代码下载地址,有需要的同学到脑图里面自取.脑图地址http://naotu.baidu.com/ ...
- leveldb 学习记录(五)SSTable格式介绍
本节主要记录SSTable的结构 为下一步代码阅读打好基础,考虑到已经有大量优秀博客解析透彻 就不再编写了 这里推荐 https://blog.csdn.net/tankles/article/det ...
- leveldb 学习笔记之log结构与存取流程
log文件的格式 log文件每一条记录由四个部分组成: CheckSum,即CRC验证码,占4个字节 记录长度,即数据部分的长度,2个字节 类型,这条记录的类型,后续讲解,1个字节 数据,就是这条记录 ...
- LevelDB源码之四LOG文件
“LOG文件在LevelDb中的主要作用是系统故障恢复时,能够保证不会丢失数据.因为在将记录写入内存的Memtable之前,会先写入Log文件,这样即使系统发生故障,Memtable中的数据没有来得及 ...
- leveldb 学习记录(七) SSTable构造
使用TableBuilder构造一个Table struct TableBuilder::Rep { // TableBuilder内部使用的结构,记录当前的一些状态等 Options options ...
- leveldb 学习记录(八) compact
随着运行时间的增加,memtable会慢慢 转化成 sstable. sstable会越来越多 我们就需要进行整合 compact 代码会在写入查询key值 db写入时等多出位置调用MaybeSche ...
随机推荐
- 用git,clone依赖的库
git clone https://github.com/influxdata/influxdb-java.git cd crfasrnn git submodule update --init -- ...
- Node核心模块
在Node中,模块主要分两大类:核心模块和文件模块.核心模块部分在 Node 源代码的编译过程中,编译进了二进制执行文件.在 Node 进启动时,部分核心模块就被直接加载进内存中,所以这部分核心模块引 ...
- Github访问速度慢和下载慢的解决方法
原因 为什么访问速度慢.下载慢?github的CDN被某墙屏了,由于网络代理商的原因,所以访问下载很慢.Ping github.com 时,速度只有300多ms. 解决方法 绕过dns解析,在本地直接 ...
- storj白皮书v3最全面解读,Docker创始人的加入能否扳倒AWS S3
Storj新发了白皮书v3,地址是:https://storj.io/storjv3.pdf. 这次白皮书一共有90页,看完还真要费不少时间.如果你没有时间看,可以看一下我这篇快速技术解读. 上次St ...
- JAVA 异常类型结构分析
JAVA 异常类型结构分析 Throwable 是所有异常类型的基类,Throwable 下一层分为两个分支,Error 和 Exception. Error 和 Exception Error Er ...
- Linux集群之keepalive+Nginx
集群从功能实现上分高可用和负载均衡: 高可用集群,即“HA"集群,也常称作“双机热备”. 当提供服务的机器宕机,备胎将接替继续提供服务: 实现高可用的开源软件有:heartbeat.keep ...
- js数组条件筛选——map()
在对象数组中检索属性为指定值得某个对象使用map()就非常方便. 对象数组 var studentArray = [ {"name":"小明","ge ...
- C#各种小问题汇总不断更新
IIS Express Worker Process已停止工作-->管理员身份运行CMD 输入netsh winsock reset 回车OK 未能从程序集“System.ServiceMode ...
- junit 基础使用
junit百度百科: JUnit是一个Java语言的单元测试框架.它由Kent Beck和Erich Gamma建立,逐渐成为源于Kent Beck的sUnit的xUnit家族中最为成功的一个. JU ...
- kubectl-常用命令
出处https://cloud.tencent.com/developer/article/1140076 kubectl apply -f kubernetes-dashboard.yaml -n ...