利用Readability解决网页正文提取问题
分享: 利用Readability解决网页正文提取问题
做数据抓取和分析的各位亲们, 有没有遇到下面的难题呢?
- 如何从各式各样的网页中提取正文!?
虽然可以用SS为各种网站写脚本做解析, 但是互联网各类网站何止千万种, 纵使累死我们也是做不完的. 这里我给大家热情推荐使用Readability来彻底解决这个难题 (呵呵, 不是做广告, 真心热爱这个好东东)
Raedability网站(www.readability.com)最引以为傲的就是其强大的解析引擎, 号称世界上最强大的文本解析神器. Safari中的"阅读器"功能就是用它来实现的! 他们还提供了API可以调用解析器的功能, 而我做了一个c#的代理类来方便大家使用.
开始之前请大家自行注册readability并申请appkey, 免费的.
代理类代码:

public static class ReadabilityProxy
{
public static Article Parse(string url, string token) //token就是各位的appkey
{
WebClient wc = new WebClient();
wc.Encoding = Encoding.UTF8;
var encUrl = HttpUtility.UrlEncode(url);
Uri u = new Uri(string.Format("https://readability.com/api/content/v1/parser?url={0}&token={1}", encUrl, token));
var json = wc.DownloadString(u);
JavaScriptSerializer se = new JavaScriptSerializer();
return se.Deserialize(json, typeof(Article)) as Article;
}
} public class Article
{
public string Domain;
public string Next_Page_Id;
public string Url;
public string Content;
public string Short_Url;
public string Excerpt;
public string Direction;
public int Word_Count;
public int Total_Pages;
public string Date_Published;
public string Dek;
public string Lead_Image_Url;
public string Title;
public int Rendered_Pages; public virtual void Decode()
{
this.Excerpt = HttpUtility.HtmlDecode(this.Excerpt);
this.Content = HttpUtility.HtmlDecode(this.Content);
}
}
由于readability返回的Content, Excerpt都是编码过的, 因此我提供了Article.Decode方法来解码.
在ConsoleApp中测试效果:
class Program
{
static void Main(string[] args)
{
var article = ReadabilityProxy.Parse("http://www.mot.gov.cn/st2010/shanghai/sh_zhaobiaoxx/201203/t20120330_1219097.html", "***此处省略n个字***");
article.Decode();
Console.WriteLine(article.Title);
Console.WriteLine(article.Excerpt);
Console.WriteLine(article.Content);
Console.ReadLine();
}
}
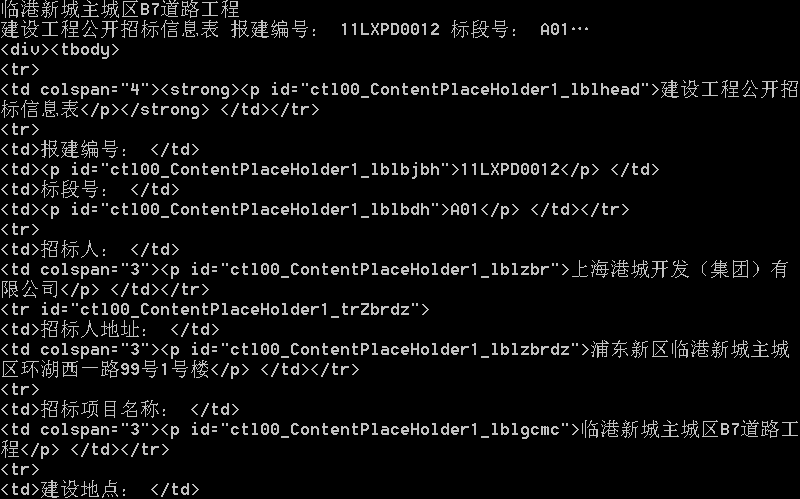
怎么样? 效果不错吧, 赶快试试吧!
利用Readability解决网页正文提取问题的更多相关文章
- 分享: 利用Readability解决网页正文提取问题
原文:http://www.cnblogs.com/iamzyf/p/3529740.html 做数据抓取和分析的各位亲们, 有没有遇到下面的难题呢? - 如何从各式各样的网页中提取正文!? 虽然可以 ...
- 我为开源做贡献,网页正文提取——Html2Article
为什么要做正文提取 一般做舆情分析,都会涉及到网页正文内容提取.对于分析而言,有价值的信息是正文部分,大多数情况下,为了便于分析,需要将网页中和正文不相干的部分给剔除.可以说正文提取的好坏,直接影响了 ...
- 网页正文提取,降噪的实现(readability/Document)
安装: pip install readability-lxml 使用: # encoding:utf-8import html2textimport requestsimport refrom re ...
- Python网页正文转换语音文件的操作方法
天气真的是越来越冷啦,有时候我们想翻看网页新闻,但是又冷的不想把手拿出来,移动鼠标翻看.这时候,是不是特别想电脑像讲故事一样,给我们念出来呢?人生苦短,我有python啊,试试用 Python 来朗读 ...
- 利用PhantomJS进行网页截屏,完美解决截取高度的问题
关于PhantomJS PhantomJS 是一个基于WebKit的服务器端 JavaScript API.它全面支持web而不需浏览器支持,其快速,原生支持各种Web标准: DOM 处理, CSS ...
- 爬虫学习笔记(1)-- 利用Python从网页抓取数据
最近想从一个网站上下载资源,懒得一个个的点击下载了,想写一个爬虫把程序全部下载下来,在这里做一个简单的记录 Python的基础语法在这里就不多做叙述了,黑马程序员上有一个基础的视频教学,可以跟着学习一 ...
- nodejs利用ajax实现网页无刷新上传图片
nodejs利用ajax实现网页无刷新上传图片 标签(空格分隔): nodejs 通常情况下上传图片是要通过提交form表单来实现的,但是这又不可避免的产生了网页转. 利用ajax技术和FormDat ...
- 利用sfntly的sfnttool.jar提取中文字体
雨忆博客中提到了sfntly(具体介绍可以看:https://code.google.com/p/sfntly/),利用其中sfnttool.jar就可以提取只包含指定字符的字体,如果想在页面中通过@ ...
- c#利用HttpWebRequest获取网页源代码
c#利用HttpWebRequest获取网页源代码,搞了好几天终于解决了,直接获取网站编码进行数据读取,再也不用担心乱码了! 命名空间:Using System.Net private static ...
随机推荐
- Android - View Alpha值
Android - View Alpha值 本文地址: http://blog.csdn.net/caroline_wendy Alpha值主要控制图像的透明度(0-1),0代表透明.1代表不透明. ...
- yii 使用 mongodb 小工具 YiiMongoDbSuite
YiiMongoDbSuite下载链接: http://www.yiiframework.com/extension/yiimongodbsuite/ 如果你的yii和mongodb它已经建立了一个良 ...
- BCM策略路由交换芯片
BCM几个交换芯片的寄存器和相关的路由 EGR_L3_NEXT_HOP.EGR_L3_INTF.ING_L3_NEXT_HOP BCM XGS系列SDK中和路由相关的几个命令 l3 l3table. ...
- 我在Yahoo与ATS 九死一生的故事
我在Yahoo与ATS 九死一生的故事 http://www.sunchangming.com/blog/post/4667.html 去年9月,我去Yahoo后领导交给我的第一件事,就是把Yahoo ...
- 栈 & 堆 |--> 内存管理
内存管理: 栈区 [stack]:由编译器自动分配并释放,一般存放函数的参数值,局部变量等 堆区 [heap]:由程序员分配和释放,如果程序员不释放,程序结束时,可能会由操作系统回收 全局区(静态区) ...
- java中文件的相对路径以及jar中文件的读取
Java中File类的构造函数需要我们传入一个pathname,当我们传入以"/"开头的pathname表示绝对路径,其他均表示相对路径. 一:绝对路径名:是完整的路径名,不需要任 ...
- 网上收集的WebBrowser的Cookie操作
原文:网上收集的WebBrowser的Cookie操作 1.WebBrowser设置Cookie Code highlighting produced by Actipro CodeHighlight ...
- AngularJS应用开发思维之3:依赖注入
找不到的API? AngularJS提供了一些功能的封装,但是当你试图通过全局对象angular去 访问这些功能时,却发现与以往遇到的库大不相同. $http 比如,在jQuery中,我们知道它的AP ...
- svg的自述
svg可缩放矢量图形(Scalable Vector Graphics). SVG 使用 XML 格式定义图像. SVG 是使用 XML 来描述二维图形和绘图程序的语言. 什么是SVG? SVG 指可 ...
- jmeter java请求
demo下载地址http://yun.baidu.com/share/link?shareid=4277735898&uk=925574576 1.引用jmeter的jar包 到jmeter的 ...