DOM遍历
前面的话
DOM遍历模块定义了用于辅助完成顺序遍历DOM结构的类型:Nodeiterator和TreeWalker,它们能够基于给定的起点对DOM结构执行深度优先(depth-first)的遍历操作。本文将详细介绍DOM遍历
[注意]IE8-浏览器不支持
定义
DOM遍历是深度优先的DOM结构遍历,遍历以给定节点为根,不可能向上超出DOM树的根节点。以下面的HTML页面为例
<!DOCTYPE html>
<html>
<head>
<title>Example</title>
</head>
<body>
<p><b>Hello</b> world!</p>
</body>
</html>
下图展示了这个页面的DOM树
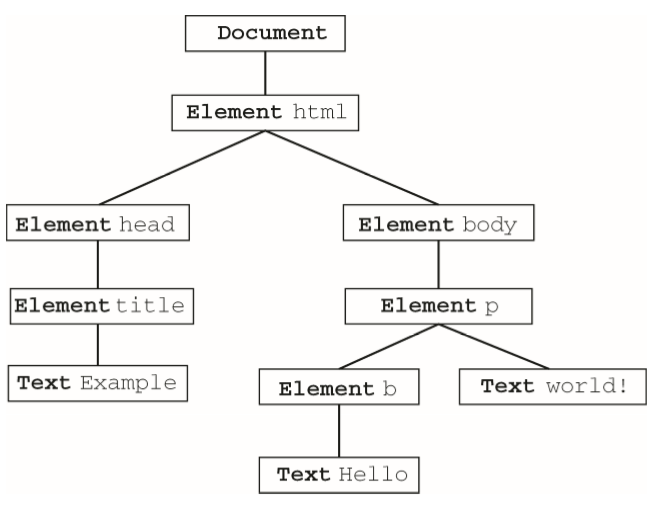
任何节点都可以作为遍历的根节点,如果假设<body>元素为根节点,那么遍历的第一步就是访问<p>元素,然后再访问同为<body>元素后代的两个文本节点。不过,这次遍历永远不会到达<html>、<head>元素,也不会到达不属于<body>元素子树的任何节点。而以document为根节点的遍历则可以访问到文档中的全部节点
下图展示了对以document为根节点的DOM树进行深度优先遍历的先后顺序
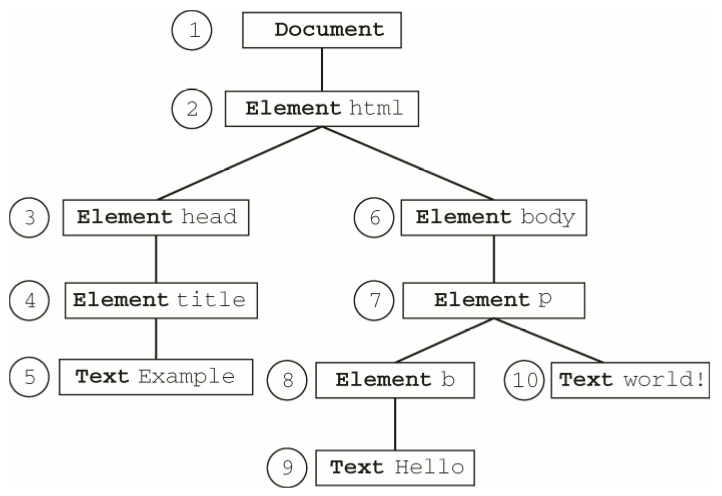
从document开始依序向前,访问的第一个节点是document,访问的最后一个节点是包含"world!"的文本节点。从文档最后的文本节点开始,遍历可以反向移动到DOM树的顶端。此时,访问的第一个节点是包含"Hello"的文本节点,访问的最后一个节点是document节点。Nodeiterator和TreeWalker都以这种方式执行遍历
NodeIterator
可以使用document.createNodeIterator()方法创建NodeIterator类型的新实例。这个方法接受下列4个参数
root:想要作为搜索起点的树中的节点
whatToShow:表示要访问哪些节点的数字代码
filter:是一个NodeFilter对象,或者一个表示应该接受还是拒绝某种特定节点的函数
entityReferenceExpansion:布尔值,表示是否要扩展实体引用。这个参数在HTML页面中没有用,因为其中的实体引用不能扩展
whatToshow参数是一个位掩码,通过应用一或多个过滤器(filter)来确定要访问哪些节点。这个参数的值以常量形式在NodeFilter类型中定义,如下所示
NodeFilter.SHOW_ALL:显示所有类型的节点
NodeFilter.SHOW_ELEMENT:显示元素节点
NodeFilter.SHOW_ATTRIBUTE:显示特性节点。由于DOM结构原因,实际上不能使用这个值
NodeFilter.SHOW_TEXT:显示文本节点
NodeFilter.SHOW_CDATA_SECTION:显示CDATA节点。对HTML页面没有用
NodeFilter.SHOW_ENTITY_REFERENCE:显示实体引用节点。对HTML页面没有用
NodeFilter.SHOW_ENTITYE:显示实体节点。对HTML页面没有用
NodeFilter.SH0W_PROCESSING_INSTRUCTION:显示处理指令节点。对HTML页面没有用
NodeFi1ter.SHOW_COMMENT:显示注释节点
NodeFilter.SHOW_DOCUMENT:显示文档节点
NodeFilter.SHOW_DOCUMENT_TYPE:显示文档类型节点
NodeFilter.SHOW_DOCUMENT_FRAGMENT:显示文档片段节点。对HTML页面没有用
NodeFilter.SHOW_NOTATION:显示符号节点。对HTML页面没有用
除了NodeFilter.SHOW_ALL之外,可以使用按位或操作符来组合多个选项,如下所示:
var whatToShow = NodeFilter.SHOW_ELEMENT | NodeFilter.SHOW_TEXT;
可以通过createNodeIterator()方法的filter参数来指定自定义的NodeFilter对象,或者指定一个功能类似节点过滤器(node filter)的函数。每个NodeFilter对象只有一个方法,即acceptNode();如果应该访问给定的节点,该方法返回NodeFilter.FILTER_ACCEPT,如果不应该访问给定的节点,该方法返回NodeFilter.FILTER_SKIP。由于NodeFilter是一个抽象的类型,因此不能直接创建它的实例。在必要时,只要创建一个包含acceptNode()方法的对象,然后将这个对象传入createNodeIterator()中即可
下列代码展示了如何创建一个只显示<p>元素的节点迭代器
var filter = {
acceptNode:function(node){
return node.tagName.toLowerCase() == "p" ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP;
}
}
var iterator = document.createNodeIterator(root, NodeFilter.SHOW_ELEMENT, filter, false);
第三个参数也可以是一个与acceptNode()方法类似的函数,如下所示
var filter = function(node){
return node.tagName.toLowerCase() == "p" ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP;
}
var iterator = document.createNodeIterator(root, NodeFilter.SHOW_ELEMENT, filter, false);
一般来说,这就是在javascript中使用这个方法的形式,这种形式比较简单,而且也跟其他的javascript代码很相似。如果不指定过滤器,那么应该在第三个参数的位置上传入null
下面的代码创建了一个能够访问所有类型节点的简单的NodeIterator
var iterator = document.createNodeIterator(document, NodeFilter.SHOW_ALL, null, false);
NodeIterator类型的两个主要方法是nextNode()和previousNode()。顾名思义,在深度优先的DOM子树遍历中,nextNode()方法用于向前前进一步,而previousNode()用于向后后退一步
在刚刚创建的NodeIterator对象中,有一个内部指针指向根节点,因此第一次调用nextNode()会返回根节点。当遍历到DOM子树的最后一个节点时,nextNode()返回null。previousNode()方法的工作机制类似。当遍历到DOM子树的最后一个节点,且previousNode()返冋根节点之后,再次调用它就会返回null
以下面的HTML片段为例
<div id="div1">
<p><b>Hello</b> world!</p>
<ul>
<li>List item 1</li>
<li>List item 2</li>
<li>List item 3</li>
</ul>
</div>
假设我们想要遍历<div>元素中的所有元素,那么可以使用下列代码
var div = document.getElementById("div1");
var iterator = document.createNodeIterator(div, NodeFilter.SHOW_ELEMENT, null, false);
var node = iterator.nextNode();
while(node !== null) {
console.log(node.tagName); //输出标签名
node = iterator.nextNode();
}
在这个例子中,第一次调用nextNode()返回<p>元素。因为在到达DOM子树末端时nextNode()返回null,所以这里使用了while语句在每次循环时检查对nextNode()的调用是否返回了null
如果只想返回遍历中遇到的<li>元素。只要使用一个过滤器即可,如下所示
var div = document.getElementById("div1");
var filter = function(node){
return node.tagName.toLowerCaee() == "li" ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP;
};
var iterator = document.createNodeIterator(div, NodeFilter.SHOW_ELEMENT, filter, false);
var node = iterator.nextNode();
while(node !== null) {
console.log(node.tagName);//输出标签名
node = iterator.nextNode();
}
在上面这个例子中,迭代器只会返回<li>元素
由于nextNode()和previousNode()方法都基于NodeIterator在DOM结构中的内部指针工作,所以DOM结构的变化会反映在遍历的结果中
TreeWalker
TreeWalker是NodeIterator的一个更高级的版本。除了包括nextNode()和previousNode()在内的相同的功能之外,这个类型还提供了下列用于在不同方向上遍历DOM结构的方法
parentNode():遍历到当前节点的父节点
firstChild():遍历到当前节点的第一个子节点
lastChild():遍历到当前节点的最后一个子节点
nextSibling():遍历到当前节点的下一个同辈节点
previousSibling():遍历到当前节点的上一个同辈节点
创建TreeWalker对象要使用document.createTreeWalker()方法,这个方法接受的4个参数与document.createNodelterator()方法相同:作为遍历起点的根节点、要显示的节点类型、过滤器和一个表示是否扩展实体引用的布尔值。由于这两个创建方法很相似,所以很容易用TreeWalker来代替NodeIterator,如下所示
var div = document.getElementById("div1");
var filter = function(node){
return node.tagName.toLowerCase() == "li"? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_SKIP;
}
var walker = document.createTreeWalker(div,NodeFilter.SHOW_ELEMENT, filter, false);
var node = walker.nextNode();
while(node !== null) {
console.log(node.tagName);//输出标签名
node = walker.nextNode();
}
在这里,filter可以返回的值有所不同。除了NodeFilter.FILTER_ACCEPT和NodeFilter.FILTER_SKIP之外,还可以使用NodeFilter.FILTER_REJECT。在使用NodeIterator对象时,NodeFilter.FILTER_SKIP与NodeFilter.FILTER_REJECT的作用相同:跳过指定的节点。但在使用TreeWalker对象时,NodeFilter.FILTER_SKIP会跳过相应节点继续前进到子树中的下一个节点,而NodeFilter.FILTER_REJECT则会跳过相应节点及该节点的整个子树。例如,将前面例子中的NodeFilter.FILTER_SKIP修改成NodeFilter.FILTER_REJECT,结果就是不会访问任何节点。这是因为第一个返回的节点是<div>,它的标签名不是"li",于是就会返回NodeFilter.FILTER_REJECT,这意味着遍历会跳过整个子树。在这个例子中,<div>元素是遍历的根节点,于是结果就会停止遍历
当然,TreeWalker真正强大的地方在于能够在DOM结构中沿任何方向移动。使用TreeWalker遍历DOM树,即使不定义过滤器,也可以取得所有<li>元素,如下所示
var div = document.getElementById("div1");
var walker = document.createTreeWalker(div, NodeFilter.SHOW_ELEMENT, null, false);
walker.firstChild();//转到<p>
walker.nextSibling();//转到<ul>
var node = walker.firstChild(); //转到第一个<li>
while(node !== null){
console.log(node.tagName);
node = walker.nextSibling();
}
因为我们知道<li>元素在文挡结构中的位置,所以可以直接定位到那里,即使用firstChild()转到<p>元素,使用nextSibling()转到<ul>元素,然后再使用firstchild()转到第一个<li>元素
[注意]此处TreeWalker只返回元素(由传入到createTreeWalker()的第二个参数决定)。因此,可以放心地使用nextSibling()访问每一个<li>元素,直至这个方法最后返回null
TreeWalker类型还有一个属性,名叫currentNode,表示任何遍历方法在上一次遍历中返回的节点。通过设置这个属性也可以修改遍历继续进行的起点,如下所示
var node = walker.nextNode();
console.log(node === walker.currentNode);//true
walker.currentNode = document.body; //修改起点
与NodeIterator相比,TreeWalker类型在遍历DOM时拥有更大的灵活性。由于IE8-浏览器中没有对应的类型和方法,所以使用遍历的跨浏览器解决方案非常少见
DOM遍历的更多相关文章
- JQuery总结:选择器归纳、DOM遍历和事件处理、DOM完全操作和动画 (转)
JQuery总结:选择器归纳.DOM遍历和事件处理.DOM完全操作和动画 转至元数据结尾 我们后台可能用到的页面一般都是用jquery取值赋值的,发现一片不错的文章 目录 JQuery总结一:选择器归 ...
- 玩转DOM遍历——用NodeIterator实现getElementById,getElementsByTagName方法
先声明一下DOM2中NodeIterator和TreeWalker这两类型真的只是用来玩玩的,因为性能不行遍历起来超级慢,在JS中基本用不到它们,除了<高程>上有两三页对它的讲解外,谷歌的 ...
- jQuery 源码分析(十九) DOM遍历模块详解
jQuery的DOM遍历模块对DOM模型的原生属性parentNode.childNodes.firstChild.lastChild.previousSibling.nextSibling进行了封装 ...
- DOM 遍历-同胞
在 DOM 树中水平遍历 有许多有用的方法让我们在 DOM 树进行水平遍历: siblings() next() nextAll() nextUntil() prev() prevAll() prev ...
- DOM遍历 - 后代
jQuery children() 方法 children() 方法返回被选元素的所有直接子元素. 该方法只会向下一级对 DOM 树进行遍历. 您也可以使用可选参数来过滤对子元素的搜索. 下面的例子返 ...
- DOM遍历-祖先
遍历 - 祖先 向上遍历 DOM 树 这些 jQuery 方法很有用,它们用于向上遍历 DOM 树: parent() parents() parentsUntil() jQuery parent() ...
- 5月25日-js操作DOM遍历子节点
一.遍历节点 遍历子节点 children();//获取节点的所有直接子类 遍历同辈节点 next(); prev(); siblings();//所有同辈元素 *find(); 从后代元素中查找匹配 ...
- DOM遍历查找结点
一.遍历API(2个) 1.深度优先原则遍历NodeIterator 节点迭代器 创建遍历API对象: var iterator=document.createNodeIterator(开始的父节点对 ...
- XML DOM 遍历Xml文档
1.xml文档内容: <?xml version="1.0" encoding="utf-8" ?> <bookstore> <b ...
随机推荐
- soot的安安装与使用
soot 工具是一个可以分析多种源代码的工具,可以进行插桩,最新版本可对android apk文件,进行相应的分析以往可以直接在eclipse里面在线安装. soot(A framework for ...
- MySQL远程登陆错误
远程连接 mySql数据库会提示10061.1045错误或 2003-Can’t connect to MySQL on ’192.168.1.2’(10061),这个原因是因为MySQL不准许远程连 ...
- STM8S STM8L引脚如何配置最低(转)
源:STM8S STM8L引脚如何配置功耗最低 STM8S无任何外围电路 单片机CAP接104电容 复位接上拉电阻,其它引脚全部悬空,利用以下程序测试电流如下:(以前也用STM8L做过类似实验,情况也 ...
- HUST 1601 Shepherd
间隔小的时候dp预处理,大的时候暴力..正确做法不会... dp[i][j]表示以i为开头,间隔为j的和,递推:dp[i][j] = dp[i + j][j] + a[i] 测试数据中间隔可能是0.. ...
- Android L(5.0)源码之图形与图像处理之简单图片——Bitmap
最近在研究android 5.0的gallery模块,学习了相关的知识点,准备写点博客总结一下,有时间了会补充完整
- ANSI标准
NSI:美国国家标准学会(AMERICAN NATIONAL STANDARDS INSTITUTE: ANSI)成立于1918年.当时,美国的许多企业和专业技术团体,已开始了标准化工作,但因彼此间没 ...
- UIAlertController 自定义输入框及KVO监听 分类: ios技术 2015-01-20 15:33 199人阅读 评论(1) 收藏
UIAlertController极大的灵活性意味着您不必拘泥于内置样式.以前我们只能在默认视图.文本框视图.密码框视图.登录和密码输入框视图中选择,现在我们可以向对话框中添加任意数目的UITextF ...
- OI队内测试——石门一
T1: 题目大意: 给你一个立方体,每个面上有些数字,给你一个数字K,你可以玩K轮游戏, 每轮你会将每个面上的数均分为4份,分给相邻的面,求K轮游戏后,上面的数字是 依次给你前.后.上.下.左.右的起 ...
- 刷新UITableView
[from]http://www.superqq.com/blog/2015/08/18/ios-development-refresh-uitableview/ UITableView对于iOS开发 ...
- MySQL-教学系统数据库设计
根据大学教学系统的原型,我构建出如下ER关系图,来学习搭建数据库: 上面共有五个实体,分别是学生,教师,课程,院系,行政班级: 1.其中学生和课程的关系是多对多,即一个学生可以选择多门课程,而一个课程 ...