凭借SpringBoot整合Neo4j,我理清了《雷神》中错综复杂的人物关系
原创:微信公众号
码农参上,欢迎分享,转载请保留出处。
哈喽大家好啊,我是Hydra。
虽然距离中秋放假还要熬过漫长的两天,不过也有个好消息,今天是《雷神4》上线Disney+流媒体的日子(也就是说我们稍后就可以网盘见了)~
了解北欧神话的小伙伴们应该知道,它的神话体系可以用一个字来形容,那就是『乱』!就像是雷神3中下面这张错综复杂的关系网,也只能算是其中的一支半节。
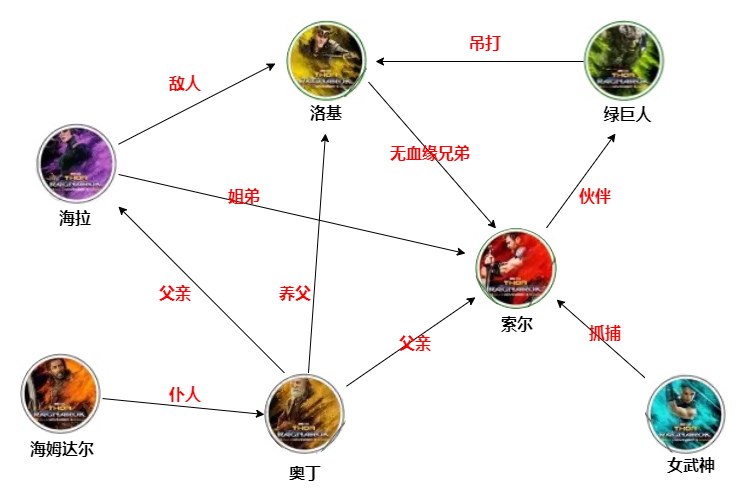
而我们在上一篇文章中,介绍了关于知识图谱的一些基本理论知识,俗话说的好,光说不练假把式,今天我们就来看看,如何在springboot项目中,实现并呈现这张雷神中复杂的人物关系图谱。
本文将通过下面几个主要模块,构建自然界中实体间的联系,实现知识图谱描述:
- 图数据库neo4j安装
- 简单CQL入门
- springboot整合neo4j
- 文本SPO抽取
- 动态构建知识图谱
Neo4j安装
知识图谱的底层依赖于关键的图数据库,在这里我们选择Neo4j,它是一款高性能的 nosql 图形数据库,能够将结构化的数据存储在图而不是表中。
首先进行安装,打开官网下载Neo4j的安装包,下载免费的community社区版就可以,地址放在下面:
需要注意的是,neo4j 4.x以上的版本都需要依赖 jdk11环境,所以如果运行环境是jdk8的话,那么还是老老实实下载3.x版本就行,下载解压完成后,在bin目录下通过命令启动:
neo4j console
启动后在浏览器访问安装服务器的7474端口,就可以打开neo4j的控制台页面:
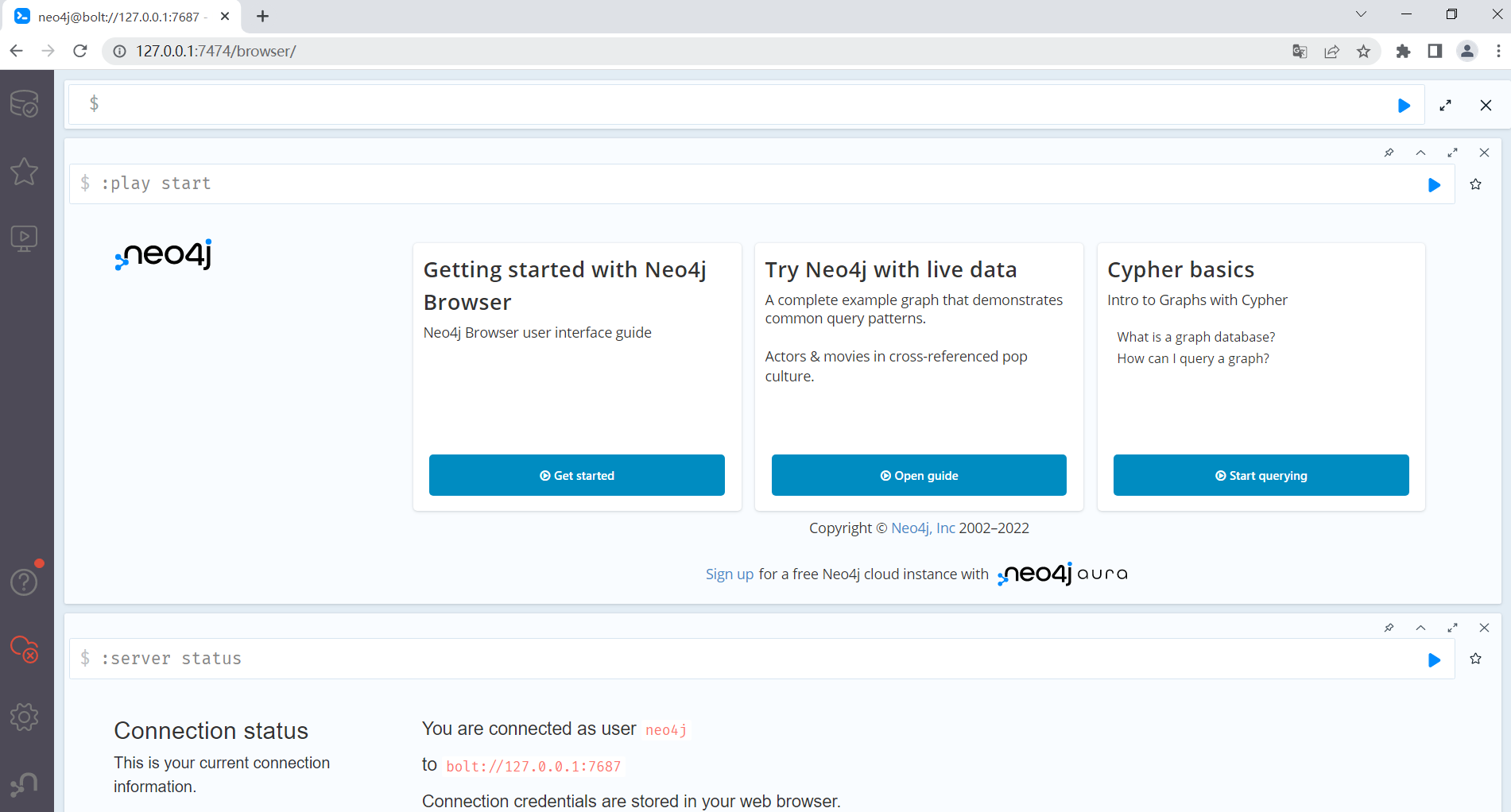
通过左侧的导航栏,我们依次可以查看存储的数据、一些基础查询的示例以及一些帮助说明。
而顶部带有$符号的输入框,可以用来输入neo4j特有的CQL查询语句并执行,具体的语法我们放在下面介绍。
简单CQL入门
就像我们平常使用关系型数据库中的SQL语句一样,neo4j中可以使用Cypher查询语言(CQL)进行图形数据库的查询,我们简单来看一下增删改查的用法。
添加节点
在CQL中,可以通过CREATE命令去创建一个节点,创建不含有属性节点的语法如下:
CREATE (<node-name>:<label-name>)
在CREATE语句中,包含两个基础元素,节点名称node-name和标签名称lable-name。标签名称相当于关系型数据库中的表名,而节点名称则代指这一条数据。
以下面的CREATE语句为例,就相当于在Person这张表中创建一条没有属性的空数据。
CREATE (索尔:Person)
而创建包含属性的节点时,可以在标签名称后面追加一个描绘属性的json字符串:
CREATE (
<node-name>:<label-name>
{
<key1>:<value1>,
…
<keyN>:<valueN>
}
)
用下面的语句创建一个包含属性的节点:
CREATE (洛基:Person {name:"洛基",title:"诡计之神"})
查询节点
在创建完节点后,我们就可以使用MATCH匹配命令查询已存在的节点及属性的数据,命令的格式如下:
MATCH (<node-name>:<label-name>)
通常,MATCH命令在后面配合RETURN、DELETE等命令使用,执行具体的返回或删除等操作。
执行下面的命令:
MATCH (p:Person) RETURN p
查看可视化的显示结果:
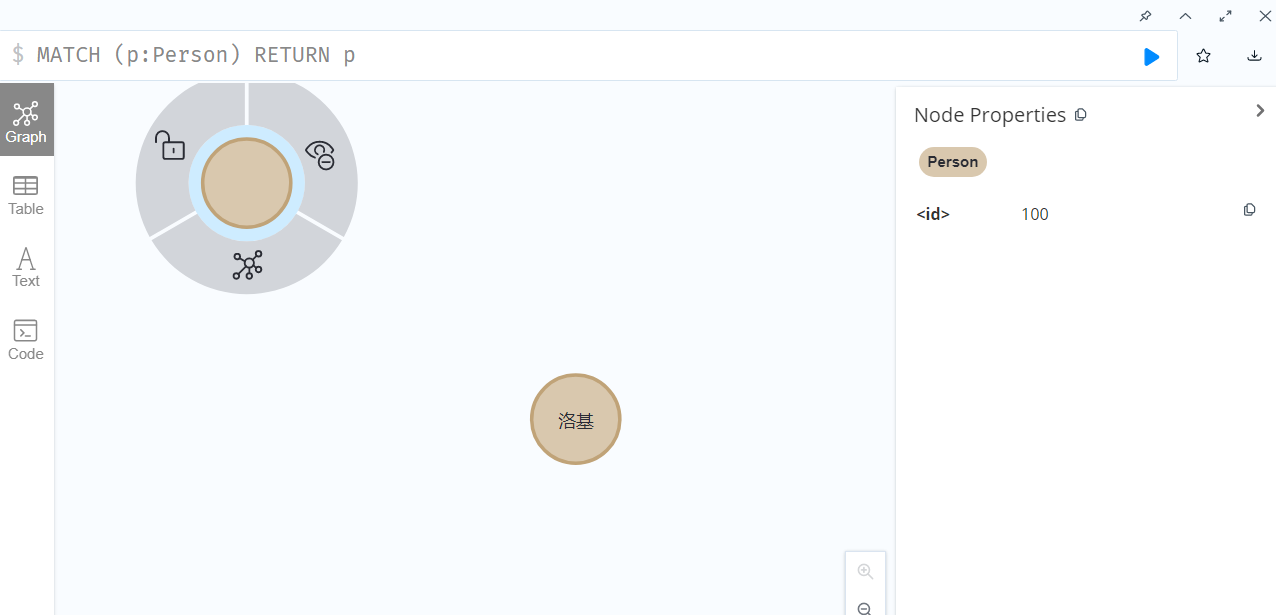
可以看到上面添加的两个节点,分别是不包含属性的空节点和包含属性的节点,并且所有节点会有一个默认生成的id作为唯一标识。
删除节点
接下来,我们删除之前创建的不包含属性的无用节点,上面提到过,需要使用MATCH配合DELETE进行删除。
MATCH (p:Person) WHERE id(p)=100
DELETE p
在这条删除语句中,额外使用了WHERE过滤条件,它与SQL中的WHERE非常相似,命令中通过节点的id进行了过滤。
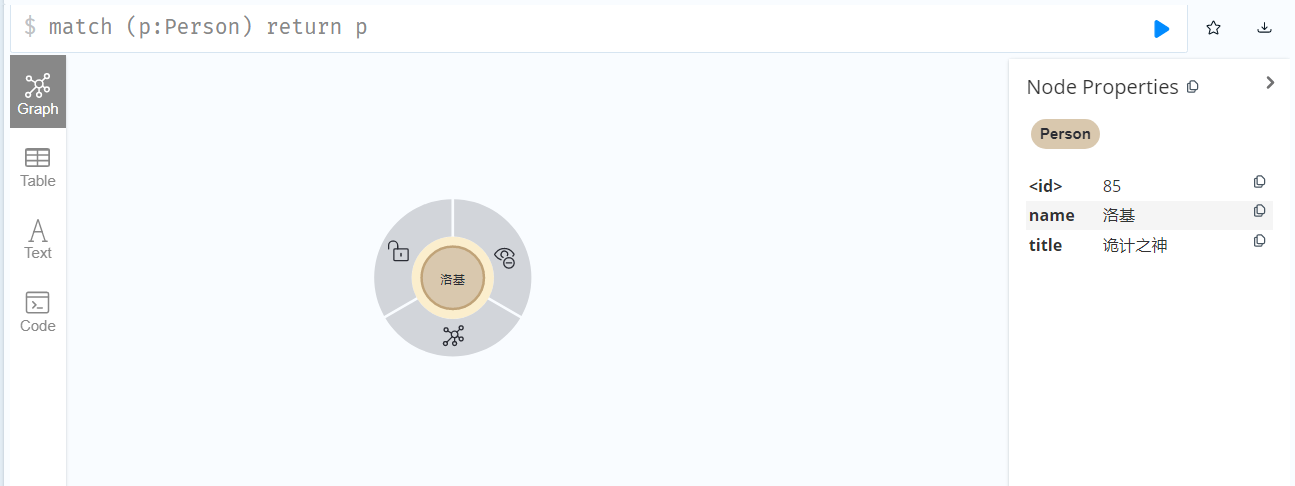
删除完成后,再次执行查询操作,可以看到只保留了洛基这一个节点:
添加关联
在neo4j图数据库中,遵循属性图模型来存储和管理数据,也就是说我们可以维护节点之间的关系。
在上面,我们创建过一个节点,所以还需要再创建一个节点作为关系的两端:
CREATE (p:Person {name:"索尔",title:"雷神"})
创建关系的基本语法如下:
CREATE (<node-name1>:<label-name1>)
- [<relation-name>:<relation-label-name>]
-> (<node-name2>:<label-name2>)
当然,也可以利用已经存在的节点创建关系,下面我们借助MATCH先进行查询,再将结果进行关联,创建两个节点之间的关联关系:
MATCH (m:Person),(n:Person)
WHERE m.name='索尔' and n.name='洛基'
CREATE (m)-[r:BROTHER {relation:"无血缘兄弟"}]->(n)
RETURN r
添加完成后,可以通过关系查询符合条件的节点及关系:
MATCH (m:Person)-[re:BROTHER]->(n:Person)
RETURN m,re,n
可以看到两者之间已经添加了关联:
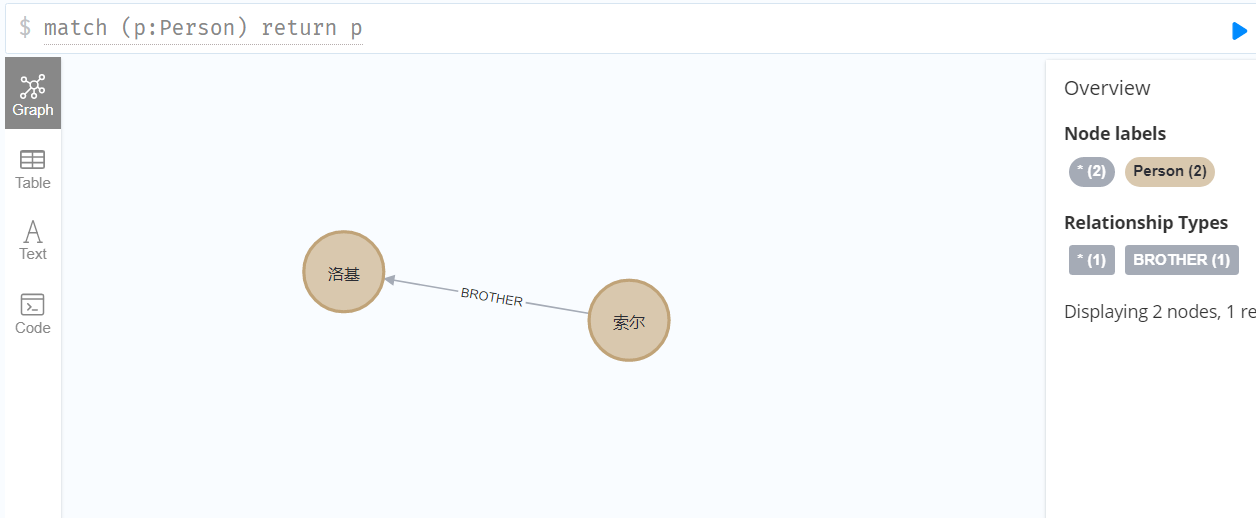
需要注意的是,如果节点被添加了关联关系后,单纯删除节点的话会报错,:
Neo.ClientError.Schema.ConstraintValidationFailed
Cannot delete node<85>, because it still has relationships. To delete this node, you must first delete its relationships.
这时,需要在删除节点时同时删除关联关系:
MATCH (m:Person)-[r:BROTHER]->(n:Person)
DELETE m,r
执行上面的语句,就会在删除节点的同时,删除它所包含的关联关系了。
那么,简单的cql语句入门到此为止,它已经基本能够满足我们的简单业务场景了,下面我们开始在springboot中整合neo4j。
SpringBoot整合Neo4j
创建一个springboot项目,这里使用的是2.3.4版本,引入neo4j的依赖坐标:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-neo4j</artifactId>
</dependency>
在application.yml中配置neo4j连接信息:
spring:
data:
neo4j:
uri: bolt://127.0.0.1:7687
username: neo4j
password: 123456
大家如果对jpa的应用非常熟练的话,那么接下来的过程可以说是轻车熟路,因为它们基本上是一个模式,同样是构建model层、repository层,然后在此基础上操作自定义或模板方法就可以了。
节点实体
我们可以使用基于注解的实体映射来描述图中的节点,通过在实体类上添加@NodeEntity表明它是图中的一个节点实体,在属性上添加@Property代表它是节点中的具体属性。
@Data
@NodeEntity(label = "Person")
public class Node {
@Id
@GeneratedValue
private Long id;
@Property(name = "name")
private String name;
@Property(name = "title")
private String title;
}
这样一个实体类,就代表它创建的实例节点的<label-name>为Person,并且每个节点拥有name和title两个属性。
Repository持久层
对上面的实体构建持久层接口,继承Neo4jRepository接口,并在接口上添加@Repository注解即可。
@Repository
public interface NodeRepository extends Neo4jRepository<Node,Long> {
@Query("MATCH p=(n:Person) RETURN p")
List<Node> selectAll();
@Query("MATCH(p:Person{name:{name}}) return p")
Node findByName(String name);
}
在接口中添加了个两个方法,供后面测试使用,selectAll()用于返回全部数据,findByName()用于根据name查询特定的节点。
接下来,在service层中调用repository层的模板方法:
@Service
@AllArgsConstructor
public class NodeServiceImpl implements NodeService {
private final NodeRepository nodeRepository;
@Override
public Node save(Node node) {
Node save = nodeRepository.save(node);
return save;
}
}
前端调用save()接口,添加一个节点后,再到控制台用查询语句进行查询,可以看到新的节点已经通过接口方式被添加到了图中:
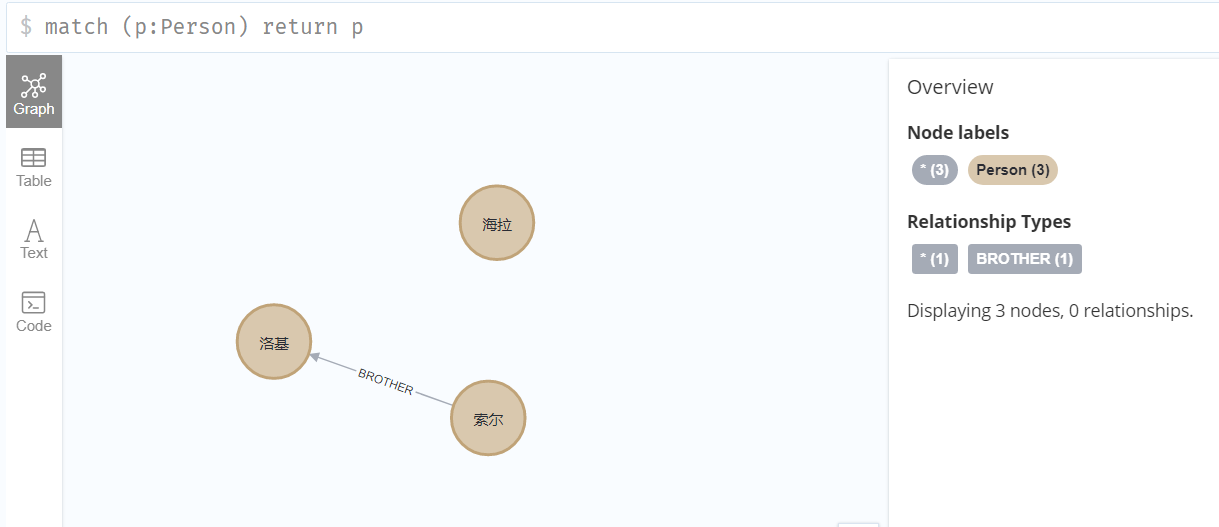
在service中再添加一个方法,用于查询全部节点,直接调用我们在NodeRepository中定义的selectAll()方法:
@Override
public List<Node> getAll() {
List<Node> nodes = nodeRepository.selectAll();
nodes.forEach(System.out::println);
return nodes;
}
在控制台打印了查询结果:
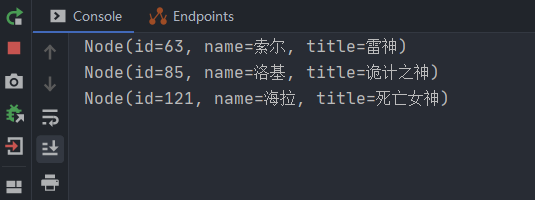
对节点的操作我们就介绍到这里,接下来开始构建节点间的关联关系。
关联关系
在neo4j中,关联关系其实也可以看做一种特殊的实体,所以可以用实体类来对其进行描述。与节点不同,需要在类上添加@RelationshipEntity注解,并通过@StartNode和@EndNode指定关联关系的开始和结束节点。
@Data
@RelationshipEntity(type = "Relation")
public class Relation {
@Id
@GeneratedValue
private Long id;
@StartNode
private Node startNode;
@EndNode
private Node endNode;
@Property
private String relation;
}
同样,接下来也为它创建一个持久层的接口:
@Repository
public interface RelationRepository extends Neo4jRepository<Relation,Long> {
@Query("MATCH p=(n:Person)-[r:Relation]->(m:Person) " +
"WHERE id(n)={startNode} and id(m)={endNode} and r.relation={relation}" +
"RETURN p")
List<Relation> findRelation(@Param("startNode") Node startNode,
@Param("endNode") Node endNode,
@Param("relation") String relation);
}
在接口中自定义了一个根据起始节点、结束节点以及关联内容查询关联关系的方法,我们会在后面用到。
创建关联
在service层中,创建提供一个根据节点名称构建关联关系的方法:
@Override
public void bind(String name1, String name2, String relationName) {
Node start = nodeRepository.findByName(name1);
Node end = nodeRepository.findByName(name2);
Relation relation =new Relation();
relation.setStartNode(start);
relation.setEndNode(end);
relation.setRelation(relationName);
relationRepository.save(relation);
}
通过接口调用这个方法,绑定海拉和索尔之间的关系后,查询结果:
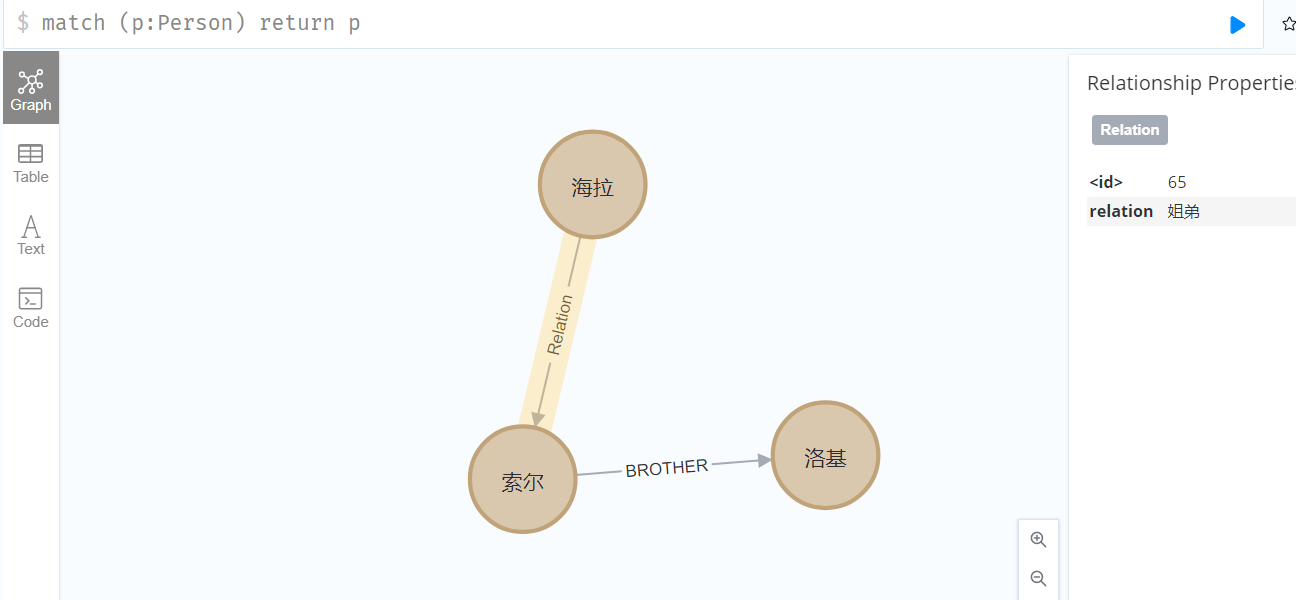
文本SPO抽取
在项目中构建知识图谱时,很大一部分场景是基于非结构化的数据,而不是由我们手动输入确定图谱中的节点或关系。因此,我们需要基于文本进行知识抽取的能力,简单来说就是要在一段文本中抽取出SPO主谓宾三元组,来构成图谱中的点和边。
这里我们借助Git上一个现成的工具类,来进行文本的语义分析和SPO三元组的抽取工作,项目地址:
这个项目虽然比较简单一共就两个类两个资源文件,但其中的工具类却能够有效帮助我们完成句子中的主谓宾的提取,使用它前需要先引入依赖的坐标:
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.2.4</version>
</dependency>
<dependency>
<groupId>edu.stanford.nlp</groupId>
<artifactId>stanford-parser</artifactId>
<version>3.3.1</version>
</dependency>
然后把这个项目中com.hankcs.nlp.lex包下的两个类拷到我们的项目中,把resources下的models目录拷贝到我们的resources下。
完成上面的步骤后,调用MainPartExtractor工具类中的方法,进行一下简单的文本SPO抽取测试:
public void mpTest(){
String[] testCaseArray = {
"我一直很喜欢你",
"你被我喜欢",
"美丽又善良的你被卑微的我深深的喜欢着……",
"小米公司主要生产智能手机",
"他送给了我一份礼物",
"这类算法在有限的一段时间内终止",
"如果大海能够带走我的哀愁",
"天青色等烟雨,而我在等你",
"我昨天看见了一个非常可爱的小孩"
};
for (String testCase : testCaseArray) {
MainPart mp = MainPartExtractor.getMainPart(testCase);
System.out.printf("%s %s %s \n",
GraphUtil.getNodeValue(mp.getSubject()),
GraphUtil.getNodeValue(mp.getPredicate()),
GraphUtil.getNodeValue(mp.getObject()));
}
}
在处理结果MainPart中,比较重要的是其中的subject、predicate和object三个属性,它们的类型是TreeGraphNode,封装了句子的主谓宾语成分。下面我们看一下测试结果:
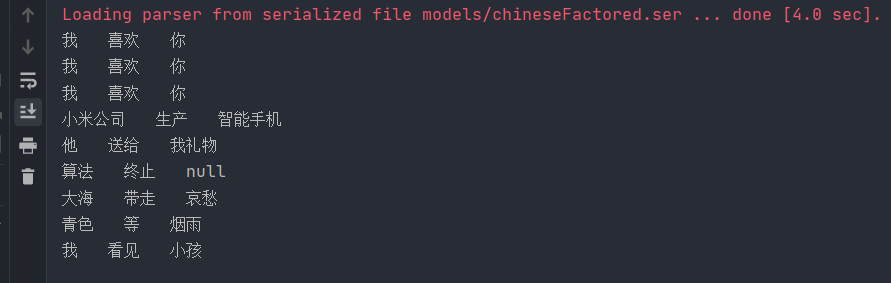
可以看到,如果句子中有明确的主谓宾语,那么则会进行抽取。如果某一项为空,则该项为null,其余句子结构也能够正常抽取。
动态构建知识图谱
在上面的基础上,我们就可以在项目中动态构建知识图谱了,新建一个TextAnalysisServiceImpl,其中实现两个关键方法。
首先是根据句子中抽取的主语或宾语在neo4j中创建节点的方法,这里根据节点的name判断是否为已存在的节点,如果存在则直接返回,不存在则添加:
private Node addNode(TreeGraphNode treeGraphNode){
String nodeName = GraphUtil.getNodeValue(treeGraphNode);
Node existNode = nodeRepository.findByName(nodeName);
if (Objects.nonNull(existNode))
return existNode;
Node node =new Node();
node.setName(nodeName);
return nodeRepository.save(node);
}
然后是核心方法,说白了也很简单,参数传进来一个句子作为文本先进行spo的抽取,对实体进行Node的保存,再查看是否已经存在同名的关系,如果不存在则创建关联关系,存在的话则不重复创建。下面是关键代码:
@Override
public List<Relation> parseAndBind(String sentence) {
MainPart mp = MainPartExtractor.getMainPart(sentence);
TreeGraphNode subject = mp.getSubject(); //主语
TreeGraphNode predicate = mp.getPredicate();//谓语
TreeGraphNode object = mp.getObject(); //宾语
if (Objects.isNull(subject) || Objects.isNull(object))
return null;
Node startNode = addNode(subject);
Node endNode = addNode(object);
String relationName = GraphUtil.getNodeValue(predicate);//关系词
List<Relation> oldRelation = relationRepository
.findRelation(startNode, endNode,relationName);
if (!oldRelation.isEmpty())
return oldRelation;
Relation botRelation=new Relation();
botRelation.setStartNode(startNode);
botRelation.setEndNode(endNode);
botRelation.setRelation(relationName);
Relation relation = relationRepository.save(botRelation);
return Arrays.asList(relation);
}
创建一个简单的controller接口,用于接收文本:
@GetMapping("parse")
public List<Relation> parse(String sentence) {
return textAnalysisService.parseAndBind(sentence);
}
接下来,我们从前端传入下面几个句子文本进行测试:
海拉又被称为死亡女神
死亡女神捏碎了雷神之锤
雷神之锤属于索尔
调用完成后,我们再来看看neo4j中的图形关系,可以看到海拉、死亡女神、索尔、锤这些实体被关联在了一起:
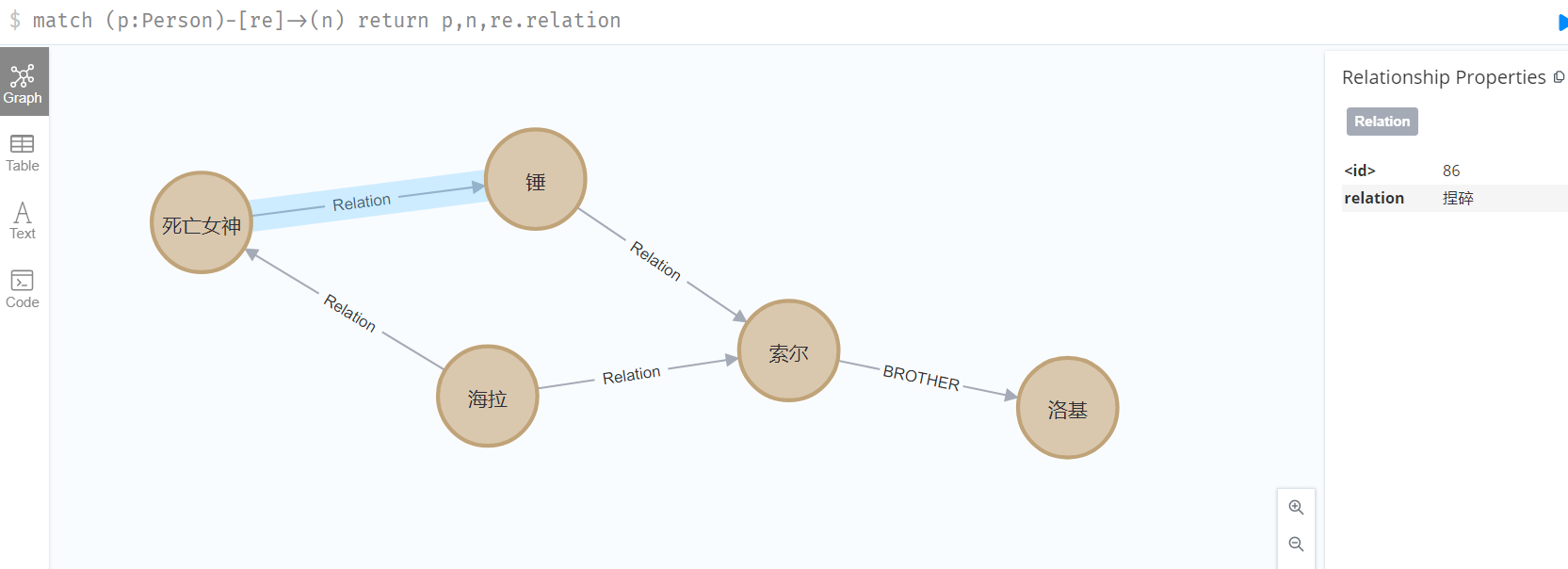
到这里,一个简单的文本处理和图谱创建的流程就被完整的串了起来,但是这个流程还是比较粗糙,之后还需要在下面几个方面继续优化:
- 当前使用的还是单一类型的节点和关联关系,后续可以在代码中丰富更多类型的节点和关联关系实体类
- 文中使用的文本spo抽取效果一般,如果应用于企业项目,那么建议基于更精确的nlp算法去做语义分析
- 当前抽取的节点只包含了实体的名称,不包含具体的属性,后续需要继续完善补充实体的属性
- 完善知识融合,主要是添加实体的指代消解以及属性的融合功能
总之,需要完善的部分还有不少,项目代码我也传到git上了,大家如果有兴趣可以看看,后续如果有时间的话我也会基于这个版本继续改进,公众号后台回复『neo』获取项目地址。
那么,这次的分享就到这里,我是Hydra,我们下篇再见。
作者简介,
码农参上,一个热爱分享的公众号,有趣、深入、直接,与你聊聊技术。欢迎添加好友,进一步交流。
凭借SpringBoot整合Neo4j,我理清了《雷神》中错综复杂的人物关系的更多相关文章
- SpringBoot整合SpringDataJPA及在页面yaml中显示
SpringBoot整合SpringDataJPA及在页面yaml中显示 1:创建对应的数据表 2:添加依赖 3:配置数据源 1:创建对应的数据表 CREATE TABLE `user` ( `id` ...
- springboot整合neo4j
刚开始按网上博客搭建 spring boot 和 neo4j一直报sessionFactory找不到,直到下载了spring-data-neo4j的实例demo对比才搭建成功,而且用户名是neo4j, ...
- mybatis源码学习(四)--springboot整合mybatis原理
我们接下来说:springboot是如何和mybatis进行整合的 1.首先,springboot中使用mybatis需要用到mybatis-spring-boot-start,可以理解为mybati ...
- SpringBoot整合日志log4j2
SpringBoot整合日志log4j2 一个项目框架中日志都是必不可少的,随着技术的更新迭代,SpringBoot被越来越多的企业所采用.这里简单说说SpringBoot整合log2j2日志. 一. ...
- springboot整合图像数据库Neo4j
百度百科: Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中.它是一个嵌入式的.基于磁盘的.具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从 ...
- springboot整合springdata-jpa
1.简介 SpringData : Spring 的一个子项目.用于简化数据库访问,支持NoSQL 和 关系数据存储.其主要目标是使数据库的访问变得方便快捷. SpringData 项目所支持 No ...
- Springboot整合ElasticSearch进行简单的测试及用Kibana进行查看
一.前言 搜索引擎还是在电商项目.百度.还有技术博客中广泛应用,使用最多的还是ElasticSearch,Solr在大数据量下检索性能不如ElasticSearch.今天和大家一起搭建一下,小编是看完 ...
- Redis-基本概念、java操作redis、springboot整合redis,分布式缓存,分布式session管理等
NoSQL的引言 Redis数据库相关指令 Redis持久化相关机制 SpringBoot操作Redis Redis分布式缓存实现 Resis中主从复制架构和哨兵机制 Redis集群搭建 Redis实 ...
- spring-boot整合mybatis(1)
sprig-boot是一个微服务架构,加快了spring工程快速开发,以及简便了配置.接下来开始spring-boot与mybatis的整合. 1.创建一个maven工程命名为spring-boot- ...
随机推荐
- 从svn下载项目后出现 Error:java: Compilation failed: internaljava compiler error 解决办法
原因:出现这个问题的话,主要是因为导入的项目JDK版本与自己的不匹配. 解决方法如下: 最后,酱紫
- python 常用的数据类型
常用的数据类型 整数型 -> int 可以表示正数.负数.0 整数的不同进制的表示方法 十进制->默认的进制,无需特殊表示 二进制->以0b开头 八进制->以0o开头 十六进制 ...
- 《A Neural Algorithm of Artistic Style》理解
在美术中,特别是绘画,人类掌握了通过在图像的内容和风格间建立复杂的相互作用从而创造独特的视觉体验的技巧.到目前为止,这个过程的算法基础是未知的,也没有现存的人工系统拥有这样的能力.然而在视觉感知的其他 ...
- go-zero微服务实战系列(十一、大结局)
本篇是整个系列的最后一篇了,本来打算在系列的最后一两篇写一下关于k8s部署相关的内容,在构思的过程中觉得自己对k8s知识的掌握还很不足,在自己没有理解掌握的前提下我觉得也很难写出自己满意的文章,大家看 ...
- java geteway 手机返回数据
import lombok.extern.slf4j.Slf4j; import org.reactivestreams.Publisher; import org.springframework.c ...
- idea 内置tomcat jersey 跨服务器 上传文件报400错误
报错内容 com.sun.jersey.api.client.UniformInterfaceException: PUT http://.jpg returned a response status ...
- 分析 java.util.Hashtable 源码
概述 基于J11,该类已经淘汰,如果使用线程安全的则用 ConcurrentHashMap ,用线程不安全的则使用 HashMap .仅与HashMap进行比较 结构以及依赖关系 HashTable ...
- MATLAB复习资料——浙商大管工学院适用
包含12套复习卷,课堂PPT 下载链接:MATLAB练习模拟题库(12套).pdf - 蓝奏云 (lanzoub.com)
- jdbc 07: 解决sql注入
jdbc连接mysql,解决sql注入问题 package com.examples.jdbc.o7_解决sql注入; import java.sql.*; import java.util.Hash ...
- kubernetes 静态存储与动态存储
静态存储 Kubernetes 同样将操作系统和 Docker 的 Volume 概念延续了下来,并且对其进一步细化.Kubernetes 将 Volume 分为持久化的 PersistentVo ...