Elasticserach学习笔记(一)
1.什么是Elasticserach?
一个由Java语言开发的全文搜索引擎,全文检索就是根据用户输入查询字符的片段,能查询出包含片段的数据,简单来说就是一个分布式的搜索与分析引擎,它可以完成分布式部署,结构化检索,以及数据分析功能,主要是应用在微服务系统中。
我们使用大白话简单的形式解释,举个例子,例如我们HR下发涨薪公告“今年统一涨工资,真的666666翻了”这段字符串存在数据库中,我们还有很多其他的公告,我们想快速找到关于涨工资的信息,我们在客户端输入"涨工资"或者"真翻了"系统能查询出来这一整段话,或者类似的字符串,如果你还觉得不够形象,相信使用过谷歌吧,你在谷歌输入随意你感兴趣的关键字,都会给你搜索到相关信息,这个就是全文检索。
2.Elasticserach的全局设计
我们需要从Elasticserach中查询数据,必须先将微服务系统的数据,同步到Elasticserach中,使它介于系统和数据库之间,作为一个缓冲区,用作对高并发全文检索查询提供支持,当然最主要的是可以利用它的全文检索和数据分析功能,按照上面介绍的业务场景,如果你有相关需求,你不想每次的查询都是直接去数据库中模糊匹配吧,这样做先不说设计是否正确,最起码模糊查询的性能是极低的,遇到并发量高直接对数据库是致命的威胁,所以选择合适的技术做合适的事。
1.写入数据方式
首先先看下面的图,在脑海中对写入数据到Elasticserach的过程有个简单的理解,然后再分析Elasticserach本身如何存储数据的

我们看到图片有几个关键字Document、In-memory buffer、cache、以及segment 这几部分正是组成Elasticserach写入数据流程的核心内容,那么我们来解析一下大致流程如下:
- Elasticserach首先不断的将数据
Document写入到In-memory buffer - 当满足一定条件后
In-memory buffer中的 Documents 会刷新到cache,默认是一秒钟一次,所以新写入的 Document 最慢 1 秒就可以在 cache 中被搜索到 - 在
cache中生成新的segment,这时候还没有写入磁盘,但是已经可以被读取了 - 从
cache将数据异步写入到磁盘
2.如何防止数据丢失
我们简单的分析了上面的步骤,知道了cache存储了供客户端写入和查询数据的支撑,但是弊端必然存在,如果缓存cache宕机数据就会丢失 ,所以为了防止数据丢失,就采用持久化的策略,将数据异步(fsync)写入到磁盘 中。
其实 Document在写入数据到In-memory buffer 时,此时Elasticserach会追加translog, 每隔 5s 会 fsync 到磁盘,当translog 累加变得越来越大,大到一定程度或者每隔一段时间,Elasticserach会执行 flush。
一般translog 每 5s 刷新一次磁盘,所以故障重启,可能会丢失 5s 的数据,可以通过配置文件来配置缩短写入磁盘的周期,translog 默认 30 分钟或者当数据太大,达到2G左右,会执行执行 flush 操作。
3.数据结构设计
在Elasticserach中有几个比较核心的概念
Dcoument就是数据在ES中的一种表现形式,以Json的格式存储 。Index(数据库)用于Document存储,数据在Elasticserach中的是以2进制的格式存储到一个个后缀为.fdt的文档中。Index(查询)表示文档 的索引,我们的Index索引是存储在后缀为.fdx的文档中,索引文件默认 是以Elasticserach的文档ID生成
通常Elasticserach接收到存储数据请求,首先会生成 一个索引fdx文件,然后再把具体数据存储到fdt文件中,索引和文档一一对应的关系 ,查找时根据索引快速找到文档数据,我们将这种关系称之为正排索引
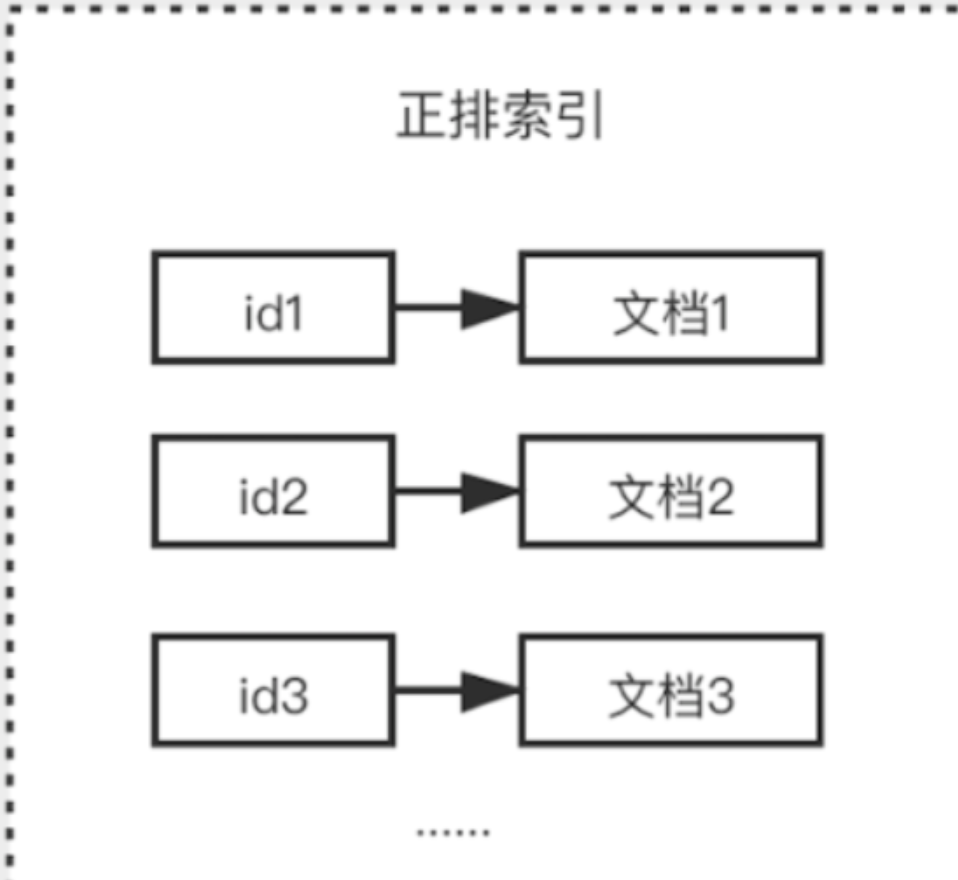
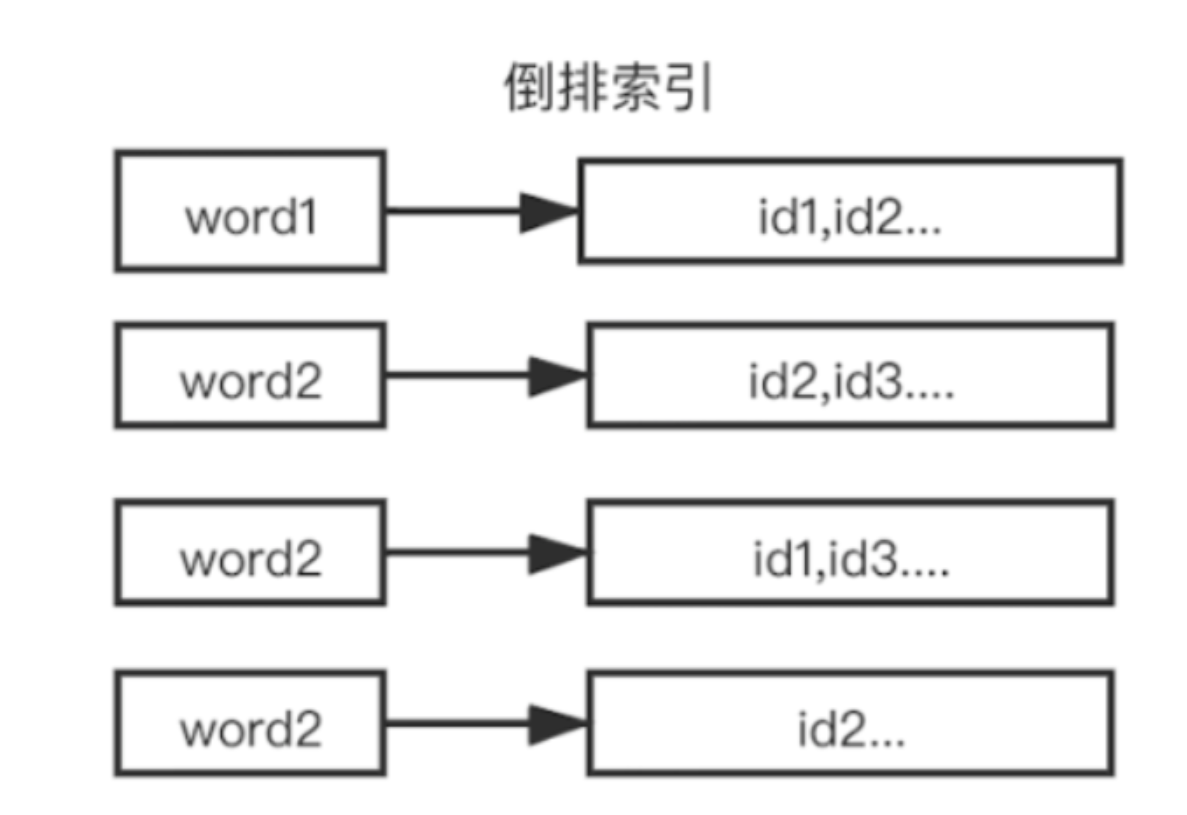
但是存在一些影响性能的问题 ,如果有成千上万的数据,要查询某个文档数据,就需要去循环找出对应的文档数据,随着数据量增大,对性能的损耗是相当严重的,所以就需要使用 倒排索引,,倒排索引指的是将文档内容中的单词作为索引,将包含该词的文档 ID 作为记录的结构。
3.搜索数据的原理
1.分词概念
在去分析 倒排索引之前我们需要了解什么是分词,简单的解释就是将一段话可能分为不同的关键词或关键字 ,也许你会好奇它是如何通过某种规则分词的,其实在全文检索中如何分词与分词器是密切相关的 ,后面我们会单独学习分词 。下面示例简单说明分词:
title:"搜索数据的原理";
//分词之后
搜索
数据
原理
搜索数据
数据的原理
2.倒排索引生成过程
我们通过一个简单的例子来说明倒排索引的生成过程,假设目前有2条数据
message:今年统一涨工资,真的666666翻了;
message:老板说,今年统一不涨工资;
1.正排索引会给 每一个Document进行 编号,作为 唯一标识
| 文档 id | 内容 |
|---|---|
| 1 | 今年统一涨工资,真的666666翻了 |
| 2 | 老板说 ,今年统一不涨工资 |
2.生成倒排索引首先会对 字段内容进行分词,例如2个 Document包含 6、统一、工资,涨工资 、老板这些关键字。然后 按照关键词 来作为 索引,对应 文档的id建立链表,就能构成 倒排索引,有了倒排索引,就能快速、灵活地实现各类搜索需求。整个搜索过程中我们不需要做任何文本的模糊匹配。
| 6 | 1 |
|---|---|
| 统一 | 1,2 |
| 涨工资 | 1,2 |
| 老板 | 2 |
3.例如需要查询 “涨工资老板说”,通过 词倒排首先查询到文档 id 1,2,再通过“老板”找到文档id 2,然后 取交集 得到 id为2的 文档
4.我们在使用倒排索引,其中分词得到的单词是利用一个Term Dictionary的概念来存储的,一个分词就是一个 Term,它在文件中的变现形式是存储在后缀为.tim的文档中,而文档id是存储在Postings List的集合中,对应稳健表现形式是存储在后缀为.doc的文件中
5.此时我们应该考虑,按照这样存储,文档和分词的关系是1>N的 ,也就是说一个文档对应多个分词,例如1000条文档,可能对应2000条分词,甚至更多,取决于文档大小和分词精度,那我们在对大量的分词进行查找时,Cpu会将这些Term从磁盘加载到内存,由于磁盘预读一次最多加载4M大小数据,所以会分段加载多次,此时如果我只需要查询2个单词 ,是不是也要将所有的Term加载到内存呢 ,显然这样做是非常浪费性能的,那该如何解决呢?
6.其实Elasticserach为了解决上述问题,提高查询Term的效率 ,会在Term Dictionary之上再抽象出一层索引(Index)的策略,将Term索引文件存储,它在文件中表现形式存储在一个后缀为.tip的文件中,查询时根据索引找到Term单词,然后加载到内存中,在找到文档id,直到最终找到文档。
4.聚合场景
首先我们要知道什么是聚合,根据Google上说的聚合在信息科学中是指对有关的数据进行内容挑选、分析、归类,最后分析得到人们想要的结果,说白了就是做统计。
其实Elasticserach为了解决提高统计的效率和性能,在对数据统计存储方面做了一些对应的设计策略,我们知道在关系型数据库中,数据存储是以行为单位存储,而Elasticserach采用的是列式存储,列式存储有利于做聚合操作,我们书面化称为doc_values。
doc_values字段文件在实际文件中存储表现形式是以.fnm后缀文件存储,而doc_values值文件是以.tmd后缀文件存储
Elasticserach学习笔记(一)的更多相关文章
- Elasticserach学习笔记-01基础概念
本文系本人根据官方文档的翻译,能力有限.水平一般,如果对想学习Elasticsearch的朋友有帮助,将是本人的莫大荣幸. 原文出处:https://www.elastic.co/guide/en/e ...
- js学习笔记:webpack基础入门(一)
之前听说过webpack,今天想正式的接触一下,先跟着webpack的官方用户指南走: 在这里有: 如何安装webpack 如何使用webpack 如何使用loader 如何使用webpack的开发者 ...
- PHP-自定义模板-学习笔记
1. 开始 这几天,看了李炎恢老师的<PHP第二季度视频>中的“章节7:创建TPL自定义模板”,做一个学习笔记,通过绘制架构图.UML类图和思维导图,来对加深理解. 2. 整体架构图 ...
- PHP-会员登录与注册例子解析-学习笔记
1.开始 最近开始学习李炎恢老师的<PHP第二季度视频>中的“章节5:使用OOP注册会员”,做一个学习笔记,通过绘制基本页面流程和UML类图,来对加深理解. 2.基本页面流程 3.通过UM ...
- 2014年暑假c#学习笔记目录
2014年暑假c#学习笔记 一.C#编程基础 1. c#编程基础之枚举 2. c#编程基础之函数可变参数 3. c#编程基础之字符串基础 4. c#编程基础之字符串函数 5.c#编程基础之ref.ou ...
- JAVA GUI编程学习笔记目录
2014年暑假JAVA GUI编程学习笔记目录 1.JAVA之GUI编程概述 2.JAVA之GUI编程布局 3.JAVA之GUI编程Frame窗口 4.JAVA之GUI编程事件监听机制 5.JAVA之 ...
- seaJs学习笔记2 – seaJs组建库的使用
原文地址:seaJs学习笔记2 – seaJs组建库的使用 我觉得学习新东西并不是会使用它就够了的,会使用仅仅代表你看懂了,理解了,二不代表你深入了,彻悟了它的精髓. 所以不断的学习将是源源不断. 最 ...
- CSS学习笔记
CSS学习笔记 2016年12月15日整理 CSS基础 Chapter1 在console输入escape("宋体") ENTER 就会出现unicode编码 显示"%u ...
- HTML学习笔记
HTML学习笔记 2016年12月15日整理 Chapter1 URL(scheme://host.domain:port/path/filename) scheme: 定义因特网服务的类型,常见的为 ...
随机推荐
- CopyOnWriteArrayList 可以用于什么应用场景?
CopyOnWriteArrayList(免锁容器)的好处之一是当多个迭代器同时遍历和修改这 个列表时,不会抛出 ConcurrentModificationException.在 CopyOnWri ...
- 使用 Spring 框架的好处是什么?
轻量:Spring 是轻量的,基本的版本大约 2MB.控制反转:Spring 通过控制反转实现了松散耦合,对象们给出它们的依 赖,而不是创建或查找依赖的对象们.面向切面的编程(AOP):Spring ...
- 运筹学之"概率"和"累计概率"和"谁随机数"
概率 = 2/50 = 0.2 累计概率 = 上个概率加本次概率 案例1 概率=销量天数 / 天数 = 2 /100 = 0.02 累计概率 = 上个概率加本次概率 = 0.02 +0.03 = 0. ...
- js技术之循环for
案例:把所有单词以空格为分割并将首字母转为大写 <!DOCTYPE html><html lang="en"><head> <meta c ...
- display:inline-block两端对齐 实现列表
做一个ul li 列表类似这样的平时经常会用到 要是用浮动做还是比较简单的直接左右浮动,清除浮动就可以搞定了,因为最近用display:inline-block用的比较顺手,所以就尝试一下.通过tex ...
- CSS:两端对齐原理(text-align:justify)
我是一个小白我是一个小白我是一个小白喷我吧,哈哈 写样式的是时候经常会碰到字体两端对齐的效果,一般就网上找端css样式复制下就结束了,没有考虑过原理是啥贴下代码 <head> <me ...
- hive从入门到放弃(四)——分区与分桶
今天讲讲分区表和分桶表,前面的文章还没看的可以点击链接: hive从入门到放弃(一)--初识hive hive从入门到放弃(二)--DDL数据定义 hive从入门到放弃(三)--DML数据操作 分区 ...
- java中final变量的用法
4.4 final变量 final变量的数值不能在初始化之后进行改变(你希望a=3,有很多用到a的场合, 你当然不能在程序中就用3来代替a). 比如: final int h = 0; 想像有一 ...
- 字符串反转&说反话
题目描述 写出一个程序,接受一个字符串,然后输出该字符串反转后的字符串.(字符串长度不超过1000) 输入描述: 输入N个字符 输出描述: 输出该字符串反转后的字符串 示例1 输入 abcd 输出 d ...
- Qt QTableView 表格内添加控件
目录 Qt QTableView 表格内添加控件 1. QItemDelegate 2. setIndexWidget 3. setIndexWidget + setLayout Qt QTableV ...