MYSQL实现排名函数RANK,DENSE_RANK和ROW_NUMBER
1. 排名分类
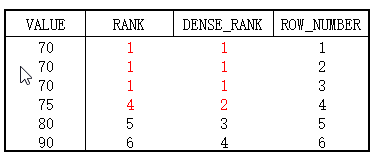
1.1 区别RANK,DENSE_RANK和ROW_NUMBER
- RANK并列跳跃排名,并列即相同的值,相同的值保留重复名次,遇到下一个不同值时,跳跃到总共的排名。
- DENSE_RANK并列连续排序,并列即相同的值,相同的值保留重复名次,遇到下一个不同值时,依然按照连续数字排名。
- ROW_NUMBER连续排名,即使相同的值,依旧按照连续数字进行排名。
区别如图:
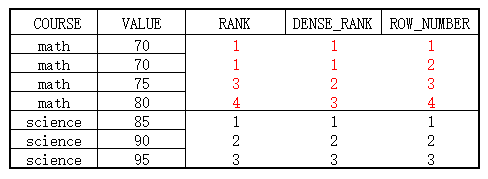
1.2 分组排名
将数据分组后排名,区别如图:
2. 准备数据
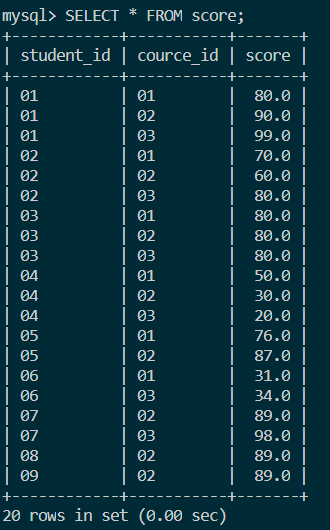
创建一张分数表,里面有字段:分数score,课程号course_id和学生号student_id。
执行如下SQL语句,进行导入数据。
create table score(
student_id varchar(10),
course_id varchar(10),
score decimal(18,1)
); insert into score values('01' , '01' , 80);
insert into score values('01' , '02' , 90);
insert into score values('01' , '03' , 99);
insert into score values('02' , '01' , 70);
insert into score values('02' , '02' , 60);
insert into score values('02' , '03' , 80);
insert into score values('03' , '01' , 80);
insert into score values('03' , '02' , 80);
insert into score values('03' , '03' , 80);
insert into score values('04' , '01' , 50);
insert into score values('04' , '02' , 30);
insert into score values('04' , '03' , 20);
insert into score values('05' , '01' , 76);
insert into score values('05' , '02' , 87);
insert into score values('06' , '01' , 31);
insert into score values('06' , '03' , 34);
insert into score values('07' , '02' , 89);
insert into score values('07' , '03' , 98);
insert into score values('08' , '02' , 89);
insert into score values('09' , '02' , 89);
查看数据:
3. 不分组排名
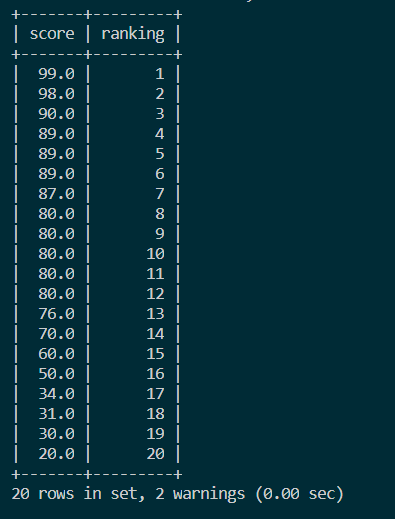
3.1 连续排名
- 使用
ROW_NUMBER实现:SELECT score,
ROW_NUMBER() OVER (ORDER BY score DESC) ranking
FROM score; - 使用
变量实现:SELECT s.score, (@cur_rank := @cur_rank + 1) ranking
FROM score s, (SELECT @cur_rank := 0) r
ORDER BY score DESC;
结果如图:
3.2 并列跳跃排名
- 使用
RANK实现:SELECT course_id, score,
RANK() OVER(ORDER BY score DESC)
FROM score; - 使用
变量和IF语句实现:SELECT s.score,
@rank_counter := @rank_counter + 1,
IF(@pre_score = s.score, @cur_rank, @cur_rank := @rank_counter) ranking,
@pre_score := s.score
FROM score s, (SELECT @cur_rank :=0, @pre_score := NULL, @rank_counter := 0) r
ORDER BY s.score DESC; - 使用
变量和CASE语句实现:SELECT s.score,
@rank_counter := @rank_counter + 1,
(
CASE
WHEN @pre_score = s.score THEN @cur_rank
WHEN @pre_score := s.score THEN @cur_rank := @rank_counter
END
) ranking
FROM score s, (SELECT @cur_rank :=0, @pre_score := NULL, @rank_counter := 0) r
ORDER BY s.score DESC;
结果如图:
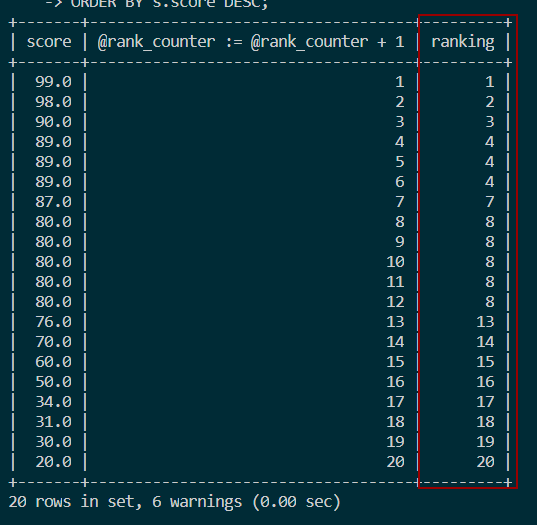
3.3 并列连续排名
- 使用
DENSE_RANK实现:SELECT course_id, score,
DENSE_RANK() OVER(ORDER BY score DESC) FROM score;
- 使用
变量和IF语句实现:SELECT s.score,
IF(@pre_score = s.score, @cur_rank, @cur_rank := @cur_rank + 1) ranking,
@pre_score := s.score
FROM score s, (SELECT @cur_rank :=0, @pre_score = NULL) r
ORDER BY s.score DESC;
- 使用
变量和CASE语句实现:SELECT s.score,
(
CASE
WHEN @pre_score = s.score THEN @cur_rank
WHEN @pre_score := s.score THEN @cur_rank := @cur_rank + 1
END
) ranking
FROM score s, (SELECT @cur_rank :=0, @pre_score = NULL) r
ORDER BY s.score DESC;结果如图:
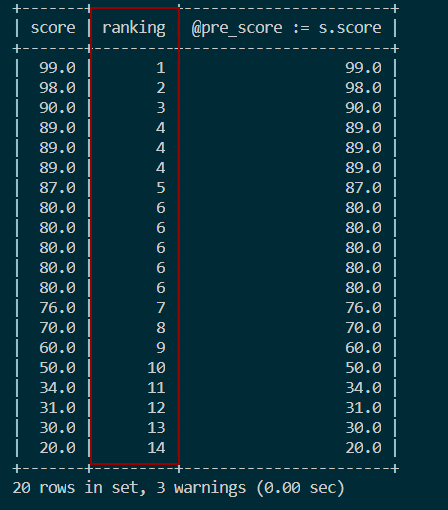
4. 分组排名
4.1 分组连续排名
- 使用
ROW_NUMBER实现:SELECT course_id, score,
ROW_NUMBER() OVER (PARTITION BY course_id ORDER BY score DESC) ranking FROM score;
- 使用
变量和IF语句实现:SELECT s.course_id, s.score,
IF(@pre_course_id = s.course_id, @cur_rank := @cur_rank + 1, @cur_rank := 1) ranking,
@pre_course_id := s.course_id
FROM score s, (SELECT @cur_rank := 0, @pre_course_id := NULL) r
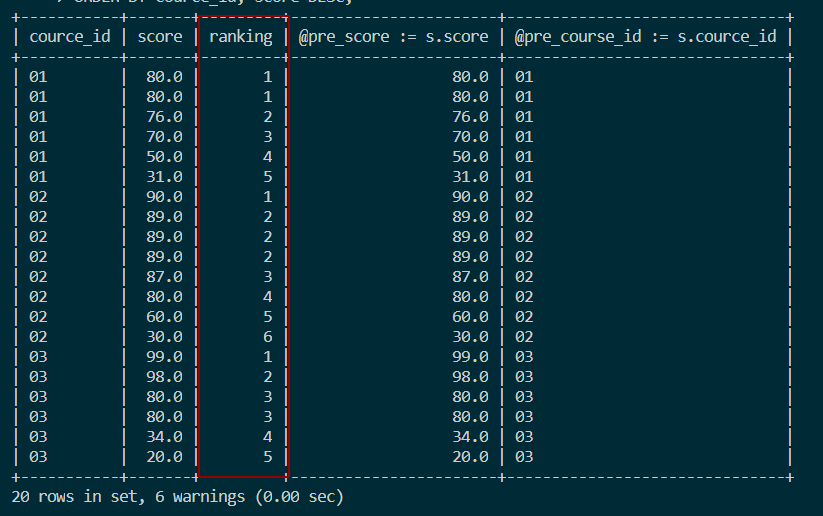
ORDER BY course_id, score DESC;结果如图:
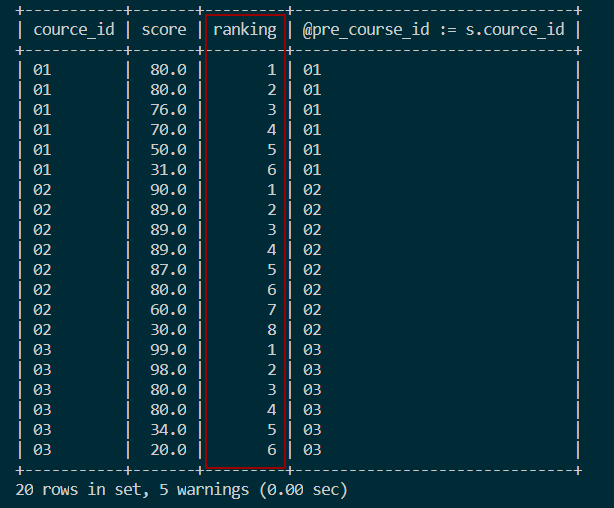
4.2 分组并列跳跃排名
- 使用
RANK实现:SELECT course_id, score,
RANK() OVER(PARTITION BY course_id ORDER BY score DESC)
FROM score;
- 使用
变量和IF语句实现:SELECT s.course_id, s.score,
IF(@pre_course_id = s.course_id,
@rank_counter := @rank_counter + 1,
@rank_counter := 1) temp1,
IF(@pre_course_id = s.course_id,
IF(@pre_score = s.score, @cur_rank, @cur_rank := @rank_counter),
@cur_rank := 1) ranking,
@pre_score := s.score temp2,
@pre_course_id := s.course_id temp3
FROM score s, (SELECT @cur_rank := 0, @pre_course_id := NULL, @pre_score := NULL, @rank_counter := 1)r
ORDER BY s.course_id, s.score DESC;结果如图:
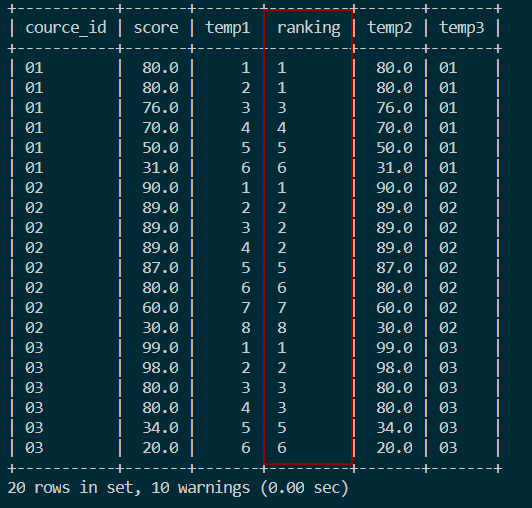
4.3 分组并列连续排名
- 使用
DENSE_RANK实现:SELECT course_id, score,
DENSE_RANK() OVER(PARTITION BY course_id ORDER BY score DESC)
FROM score;
- 使用
变量和IF语句实现:SELECT s.course_id, s.score,
IF(@pre_course_id = s.course_id,
IF(@pre_score = s.score, @cur_rank, @cur_rank := @cur_rank + 1),
@cur_rank := 1) ranking,
@pre_score := s.score,
@pre_course_id := s.course_id
FROM score s, (SELECT @cur_rank :=0, @pre_score = NULL, @pre_course_id := NULL) r
ORDER BY course_id, score DESC;可以将上述的IF条件提取出来:
SELECT s.course_id, s.score,
IF(@pre_score = s.score, @cur_rank, @cur_rank := @cur_rank + 1) temp1,
@pre_score := s.score temp2,
IF(@pre_course_id = s.course_id, @cur_rank, @cur_rank := 1) ranking,
@pre_course_id := s.course_id
FROM score s, (SELECT @cur_rank :=0, @pre_score = NULL, @pre_course_id := NULL) r
ORDER BY course_id, score DESC;结果如图:
MYSQL实现排名函数RANK,DENSE_RANK和ROW_NUMBER的更多相关文章
- sql server 排名函数:DENSE_RANK
一.需求 之前sql server 的排名函数用得最多的应该是RoW_NUMBER()了,我通常用ROW_NUMBER() + CTE 来实现分页:今天逛园,看到另一个内置排名函数还不错,自己顺便想了 ...
- Oracle排名函数(Rank)实例详解
这篇文章主要介绍了Oracle排名函数(Rank)实例详解,需要的朋友可以参考下 --已知:两种排名方式(分区和不分区):使用和不使用partition --两种计算方式(连续,不连续),对应 ...
- Oracle 的开窗函数 rank,dense_rank,row_number
1.开窗函数和分组函数的区别 分组函数是指按照某列或者某些列分组后进行某种计算,比如计数,求和等聚合函数进行计算. 开窗函数是指基于某列或某些列让数据有序,数据行数和原始数据数相同,依然能曾现个体数据 ...
- 【MySQL】排名函数
https://www.cnblogs.com/shizhijie/p/9366247.html 排名函数 主要有rank和dense_rank两种 区别: rank在排名的时候,排名的键一样的时候是 ...
- rank,dense_rank和row_number函数区别
我对技术一般抱有够用就好的态度,一般在网上或者书上找了贴合的解决方案,放到实际中发现好用就行了,不再深究,等出了问题再说. 因此,我对Oracle中中形成有效序列的方法集中在rownum,row_nu ...
- SQL窗口函数RANK(),Dense_Rank(),row_number(),NTILE()
数据源 CREATE TABLE student( no int, ca ), name ), subject ), scorce int ); /* 数据 */ , ); , ); , ); , ) ...
- SQL2005四个排名函数(row_number、rank、dense_rank和ntile)的比较
排名函数是SQL Server2005新加的功能.在SQL Server2005中有如下四个排名函数: .row_number .rank .dense_rank .ntile 下面分别介绍一下这四个 ...
- ORACLE,DECODE函数和排名函数DENSE_RANK函数的使用
这几天写一个报表的页面,从很恶心的数据结构中做一个聚合函数的查询,结构大概是这个样子的: 所以有:对数据group by t.id,t.name.t.course 这样三层排序,然后用函数去取值. d ...
- SQLServer学习笔记<>.基础知识,一些基本命令,单表查询(null top用法,with ties附加属性,over开窗函数),排名函数
Sqlserver基础知识 (1)创建数据库 创建数据库有两种方式,手动创建和编写sql脚本创建,在这里我采用脚本的方式创建一个名称为TSQLFundamentals2008的数据库.脚本如下: ...
- 好用的排名函数~ROW_NUMBER(),RANK(),DENSE_RANK() 三兄弟
排名函数三兄弟,一看名字就知道,都是为了排名而生!但是各自有各自的特色!以下一个例子说明问题!(以下栗子没有使用Partition By 的关键字,整个结果集进行排序) RANK 每个值一个排名,同样 ...
随机推荐
- springcloud 和springboot版本对比
版本对应关系大版本对应: Spring Cloud Spring Boot Angel版本 兼容Spring Boot 1.2.x Brixton版本 兼容Spring Boot 1.3.x,也兼容S ...
- Web学习篇—Http协议
Http协议简介 h3 { background: rgba(0, 154, 205, 1); color: rgba(255, 255, 255, 1); border-radius: 6px; f ...
- protected virtual 使用
转载摘自:https://blog.csdn.net/qq_31116753/article/details/81203416 1.使用protected访问修饰符标记的方法或字段,只能在当前类及其子 ...
- React Developer插件报错Cannot read properties of undefined (reading ‘forEach‘)
安装了3.6的版本React Developer 启用插件后 报错 解决 https://www.crx4chrome.com/crx/3068/ 下载 下载好后,直接拖入扩展程序中
- 使用Mybatis plus xml 记录过程
<select id="selectByConditions" resultType="com.springboot.domain.DemoQueryModel&q ...
- .net code 3.0 获取配置文件 json 和 config 中的值
using Microsoft.Extensions.Configuration;using Microsoft.Extensions.FileProviders; using System.IO; ...
- WPF-窗体移动,最小化,最大化,关闭
1,按钮操作 public MainView() { InitializeComponent(); this.MaxHeight = SystemParameters.PrimaryScreenHei ...
- 记录一次antd升级到最新版本,与现有代码冲突导致的问题
背景:发版的前一夜,测试突然发现项目某个功能点击弹框会导致整个页面直接空白,立即提了个单要我赶紧修复.(内心真是一万个卧槽)本来准备不加班的.没办法,那只能解决.第一步就怀疑是不是谁动了代码,毕竟一两 ...
- IaaS--云虚拟机(三)(何恺铎《深入浅出云计算》笔记整理)
云虚拟机收费之省钱办法. [包年包月] 包年包月就是我们要提前预估好自己虚拟机的使用时间,比如半年.一年甚至三年,并提前支付相关款项的一种购买方式.这样的购买方式,通常能够给你带来较大幅度的折扣,帮你 ...
- 夸克开发板 FaceDetectOnTft.py 测试
① 连接usb 摄像头,执行 dmesg | grep -i video 查看设备识别情况 同时可看到 frame buffer 显示设备(自带的 tft LCD)名称 ② 摄像头识别的设备名为, / ...