论文解读(PairNorm)《PairNorm: Tackling Oversmoothing in GNNs》
论文信息
论文标题:PairNorm: Tackling Oversmoothing in GNNs
论文作者:Lingxiao Zhao, Leman Akoglu
论文来源:2020,ICLR
论文地址:download
论文代码:download
1 Introduction
GNNs 的表现随着层数的增加而有所下降,一定程度上归结于 over-smoothing 问题,重复图卷积操作会使得节点表示最终变得不可区分。为缓解过平滑问题提出了 PairNorm, 一种归一化方法。
比较可惜的时,该论文在使用了 2022 年的 "Mask" 策略,可惜了实验做的不咋好。
2 Understanding oversmoothing
Definition
$\tilde{\mathbf{A}}_{\mathrm{sym}}=\tilde{\mathbf{D}}^{-1 / 2} \tilde{\mathbf{A}} \tilde{\mathbf{D}}^{-1 / 2}$
$\tilde{\mathbf{A}}_{\mathrm{rw}}=\tilde{\mathbf{D}}^{-1} \tilde{\mathbf{A}}$
2.1 The oversmoothing problem
2.1.1 Oversmoothing
GNN 性能下降的原因:
- 参数数量的增加;
- 梯度消失导致训练困难;
- 图卷积而造成的过平滑;
过平滑的考虑方法如下:当多次使用拉普拉斯平滑导致节点特征收敛到一个平稳点。假设 $\mathbf{x}_{\cdot j} \in \mathbb{R}^{n}$ 表示 $\mathbf{X}$ 的第 $j $ 列,对于任意 $\mathbf{x}_{\cdot j} \in \mathbb{R}^{n}$:
$\begin{array}{l}\underset{k \rightarrow \infty}{\text{lim}} \quad \tilde{\mathbf{A}}_{\mathrm{sym}}^{k} \mathbf{x}_{\cdot j} =\boldsymbol{\pi}_{j}\\ \text { and } \quad \frac{\boldsymbol{\pi}_{j}}{\left\|\boldsymbol{\pi}_{j}\right\|_{1}}=\boldsymbol{\pi}\end{array}$
其中,标准化解 $\pi \in \mathbb{R}^{n}$ 满足 $\boldsymbol{\pi}_{i}=\frac{\sqrt{\operatorname{deg}_{i}}}{\sum_{i} \sqrt{\operatorname{deg}_{i}}} \text{ for all } i \in[n]$。
Note:$\boldsymbol{\pi}$ 不依赖于节点特征矩阵,而是一个单纯依靠图结构度的函数。
2.1.2 Its Measurement
本文提出两种度量过平滑的方式:$\text{row-diff}$ 和 $\text{col-diff}$。
设 $\mathbf{H}^{(k)} \in \mathbb{R}^{n \times d}$ 为第 $k$ 个图卷积后的节点表示矩阵,即 $\mathbf{H}^{(k)}=\tilde{\mathbf{A}}_{\mathrm{sym}}^{k} \mathbf{X}$。设 $\mathbf{h}_{i}^{(k)} \in \mathbb{R}^{d}$ 为 $\mathbf{H}^{(k)}$ 的第 $i$ 行,$\mathbf{h}_{. i}^{(k)} \in \mathbb{R}^{n}$ 为 $\mathbf{H}^{(k)}$ 的第 $i$ 列。
$\text{row-diff}( \left.\mathbf{H}^{(k)}\right)$ 和 $\text{col-diff}( \left.\mathbf{H}^{(k)}\right)$ 的定义如下:
${\large \operatorname{row}-\operatorname{diff}\left(\mathbf{H}^{(k)}\right) =\frac{1}{n^{2}} \sum\limits _{i, j \in[n]}\left\|\mathbf{h}_{i}^{(k)}-\mathbf{h}_{j}^{(k)}\right\|_{2}} \quad\quad\quad(2)$
$\text{row-diff}$ 量化节点之间的成对距离,而 $\text{col-diff}$ 特征之间的成对距离。
2.2 Studying oversmoothing with SGC
GCN 过平滑可能由于层数增加导致的性能下降,即添加更多的层导致更多的参数(添加的线性层 存在 $\mathbf{W}^{(k)}$)容易导致过拟合。同样层数增加,容易存在反向传播梯度的消失(应该指的是参数多)。
将层数增加影响过平滑和 使用参数导致过拟合即反向传播梯度消失 解耦。本文使用 SGC ,一种简化的 GCN :去除图卷积层的所有投影参数和所有层间的非线性激活。SGC可写为:
$\widehat{\boldsymbol{Y}}=\operatorname{softmax}\left(\tilde{\mathbf{A}}_{\mathrm{sym}}^{K} \mathbf{X} \mathbf{W}\right) \quad\quad\quad(4) $
Note:SGC有一个固定数量的参数,不依赖于图卷积的数量(即层),也因此防止了过拟合和消失梯度问题的影响。
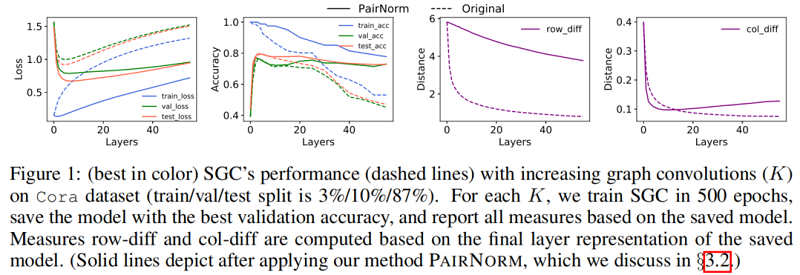
Figure 1 中的虚线说明了当增加层数( $K$ )时,SGC 在 Cora 数据集上的性能。训练(交叉熵)损失随着 $K$ 的增大而单调地增加,这可能是因为图卷积将节点表示与它们的邻居混合在一起,使它们变得不那么容易区分(训练变得更加困难)。另一方面,至多到 $K=4$,图卷积(即平滑)提高了泛化能力,减少了训练和验证/测试损失之间的差距,之后,过平滑开始影响性能。$\text{row-diff}$ 和 $\text{col-diff}$ 都随 $K$ 继续单调递减,为过平滑提供了支持证据。
3 Tackling oversmoothing
3.1 Proposed pairnorm
考虑图正则化最小二乘(GRLS):设 $\overline{\mathbf{X}} \in \mathbb{R}^{n \times d}$ 是节点表示矩阵,其中 $\overline{\mathbf{x}}_{i} \in \mathbb{R}^{d}$ 表示 $\overline{\mathbf{X}}$ 的第 $i$ 行,GRLS 问题为:
$\underset{\overline{\mathbf{x}}}{\text{min}} \sum\limits _{i \in \mathcal{V}}\left\|\overline{\mathbf{x}}_{i}-\mathbf{x}_{i}\right\|_{\tilde{\mathbf{D}}}^{2}+\sum\limits_{(i, j) \in \mathcal{E}}\left\|\overline{\mathbf{x}}_{i}-\overline{\mathbf{x}}_{j}\right\|_{2}^{2}\quad\quad\quad(5)$
其中:
- $\left\|\mathbf{z}_{i}\right\|_{\tilde{\mathbf{D}}}^{2}=\mathbf{z}_{i}^{T} \tilde{\mathbf{D}} \mathbf{z}_{i}$;
第一项可以看作是度加权最小二乘,第二个是一个图正则化项,度量新特征在图结构上的变化。
优化问题的目标可认为是估计新的 “去噪” 特征 $\overline{\mathbf{x}}_{i}$ 离输入特征 $\mathbf{x}_{i}$ 不远,并且在图结构上很平滑。
理想情况下,希望获得对同一集群内的节点的平滑,但是避免平滑来自不同集群的节点。$\text{Eq.5}$ 中的目标通过图正则化项只优化第一个目标。因此,当重复应用卷积时,它容易出现过平滑。为规避这个问题并同时实现这两个目标,可以添加一个负项,如没有边连接对之间的距离之和如下:
$\underset{\overline{\mathbf{x}}}{\text{min}} \sum\limits _{i \in \mathcal{V}}\left\|\overline{\mathbf{x}}_{i}-\mathbf{x}_{i}\right\|_{\tilde{\mathbf{D}}}^{2}+\sum\limits_{(i, j) \in \mathcal{E}}\left\|\overline{\mathbf{x}}_{i}-\overline{\mathbf{x}}_{j}\right\|_{2}^{2}-\lambda \sum_{(i, j) \notin \mathcal{E}}\left\|\overline{\mathbf{x}}_{i}-\overline{\mathbf{x}}_{j}\right\|_{2}^{2}\quad\quad\quad(6)$
在本文中,没有提出了一个全新的图卷积算子,而是提出了一个通用的、有效的 “补丁”,称为 PAIRNORM,它可以应用于具有过平滑潜力的任何形式的图卷积。
设 $\tilde{\mathbf{X}}$(图卷积的输出)和 $\dot{\mathbf{X}}$ 分别为 PAIRNORM 的输入和输出。观察到图卷积 $\tilde{\mathbf{X}}=\tilde{\mathbf{A}}_{\text {sym }} \mathbf{X}$ 的输出实现了第一个目标 度加权,PAIRNORM 作为一个标准化层,在 $\tilde{\mathbf{X}}$ 上工作,以实现第二个目标,即保持未连接的对表示更远。具体来说,PAIRNORM 将 $\tilde{\mathbf{X}}$ 归一化,使总成对平方距离 $\operatorname{TPSD}(\dot{\mathbf{X}}):=\sum\limits_{i, j \in[n]}\left\|\dot{\mathbf{x}}_{i}-\dot{\mathbf{x}}_{j}\right\|_{2}^{2} $ 和 $\operatorname{TPSD}(\mathbf{X} )$ 一样:
实践中,不需要时刻关注 $\operatorname{TPSD}(\mathbf{X} )$ 的值,只需要在所有层使得 $\operatorname{TPSD}(\mathbf{X} )$ 保持一个恒定的常量 $C$。
同样地,规范化可以通过一个两步的方法来完成,其中 $\operatorname{TPSD}$ 被重写为
$\operatorname{TPSD}(\tilde{\mathbf{X}})=\sum\limits_{i, j \in[n]}\left\|\tilde{\mathbf{x}}_{i}-\tilde{\mathbf{x}}_{j}\right\|_{2}^{2}=2 n^{2}\left(\frac{1}{n} \sum\limits_{i=1}^{n}\left\|\tilde{\mathbf{x}}_{i}\right\|_{2}^{2}-\left\|\frac{1}{n} \sum\limits_{i=1}^{n} \tilde{\mathbf{x}}_{i}\right\|_{2}^{2}\right) \quad\quad\quad(8)$
$\text{Eq.8}$ 的第一项 表示节点表示的均方长度,第二项描述了节点表示的均值的平方长度。
为简化 $\text{Eq.8}$ 的计算,令每个 $\tilde{\mathbf{x}}_{i}$ 减去行均值 $\tilde{\mathbf{x}}_{i}^{c}=\tilde{\mathbf{x}}_{i}-\frac{1}{n} \sum\limits _{i}^{n} \tilde{\mathbf{x}}_{i}$,其中 $\tilde{\mathbf{x}}_{i}^{c}$ 表示中心表示。这种移动不会影响 $\operatorname{TPSD}$,并且驱动了项 $\left\|\frac{1}{n} \sum\limits _{i=1}^{n} \tilde{\mathbf{x}}_{i}\right\|_{2}^{2} $ 趋近 $0$。那么,计算 $\operatorname{TPSD}(\tilde{\mathbf{X}}) $ 可归结为计算 $\tilde{\mathbf{X}}^{c}$ 的 $F$ 范数的平方,并有 $\mathcal{O}(n d)$:
$\operatorname{TPSD}(\tilde{\mathbf{X}})=\operatorname{TPSD}\left(\tilde{\mathbf{X}}^{c}\right)=2 n\left\|\tilde{\mathbf{X}}^{c}\right\|_{F}^{2} \quad\quad\quad(9)$
$\text{Eq.9}$ 可以写成一个两步的、中心和规模的归一化过程:
$\tilde{\mathbf{x}}_{i}^{c}=\tilde{\mathbf{x}}_{i}-\frac{1}{n} \sum\limits _{i=1}^{n} \tilde{\mathbf{x}}_{i} \quad\quad\text{(Center)}\quad(10)$
缩放后,数据保持中心化 $\left\|\sum\limits _{i=1}^{n} \dot{\mathbf{x}}_{i}\right\|_{2}^{2}=0$ 。在 $\text{Eq.11}$ 中,$s$ 是一个超参数,它决定了 $C$。具体来说,
$\operatorname{TPSD}(\dot{\mathbf{X}})=2 n\|\dot{\mathbf{X}}\|_{F}^{2}=2 n \sum\limits_{i}\left\|s \cdot \frac{\tilde{\mathbf{x}}_{i}^{c}}{\sqrt{\frac{1}{n} \sum\limits_{i}\left\|\tilde{\mathbf{x}}_{i}^{c}\right\|_{2}^{2}}}\right\|_{2}^{2}=2 n \frac{s^{2}}{\frac{1}{n} \sum\limits_{i}\left\|\tilde{\mathbf{x}}_{i}^{c}\right\|_{2}^{2}} \sum\limits_{i}\left\|\tilde{\mathbf{x}}_{i}^{c}\right\|_{2}^{2}=2 n^{2} s^{2} \quad(12)$
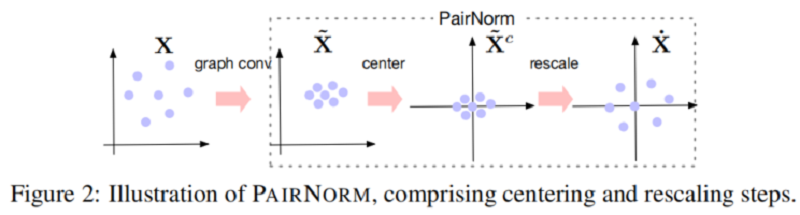
然后,$\dot{\mathbf{X}}:=\operatorname{PAIRNORM}(\tilde{\mathbf{X}})$ 拥有行均值为 $0$ (Center),和恒定的总成对平方距离 $C=2 n^{2} s^{2}$。在 Figure 2 中给出了一对范数的说明。PAIRNORM 的输出被输入到下一个卷积层。
本文还推导出 PAIRNORM 的变体,即通过替换 $\text{Eq.11}$ 的 $\sum\limits _{i=1}^{n}\left\|\tilde{\mathbf{x}}_{i}^{c}\right\|_{2}^{2} $ 为 $n\left\|\tilde{\mathbf{x}}_{i}^{c}\right\|_{2}^{2}$ ,本文称之为 PAIRNORM-SI ,此时所有的节点都有相同的 $L_{2}$ 范数 $s$ 。
在实践中,发现 PAIRNORM 和 PAIRNORM-SI 对 SGC 都很有效,而 PAIRNORM-SI 对 GCN 和 GAT 提供了更好和更稳定的结果。GCN 和 GAT 需要更严格的归一化的原因可能是因为它们有更多的参数,更容易发生过拟合。在所有实验中,对SGC采用PAIRNORM,对 GCN 和 GAT 采用 PAIRNORM-SI。
Figure 1 中的实线显示了 SGC 性能, 与 “vanilla” 版本相比,随着层数的增加,我们在每个图卷积层之后使用 PAIRNORM。类似地,Figure 3 用于 GCN 和 GAT(在每个图卷积激活后应用PAIRNORM-SI)。请注意,PAIRNORM 的性能衰减要慢得多。

虽然 PAIRNORM 使更深层次的模型对过度平滑更稳健,但总体测试精度没有提高似乎很奇怪。事实上,文献中经常使用的基准图数据集需要不超过 $4$ 层,之后性能就会下降(即使是缓慢的)。
3.2 A case where deeper GNNs are beneficial
假设 $\mathcal{M} \subseteq \mathcal{V}_{u}$ 代表特征缺失子集,其中 $\forall m \in \mathcal{M}$,$\mathbf{x}_{m}=\emptyset $。本文设置 $p=|\mathcal{M}| /\left|\mathcal{V}_{u}\right|$ 代表缺失比例。将这种任务的变体称为具有缺失向量的半监督节点分类(SSNC-MV)。直观的说,需要更多的传播步骤才能恢复这些节点有效的特征表示。
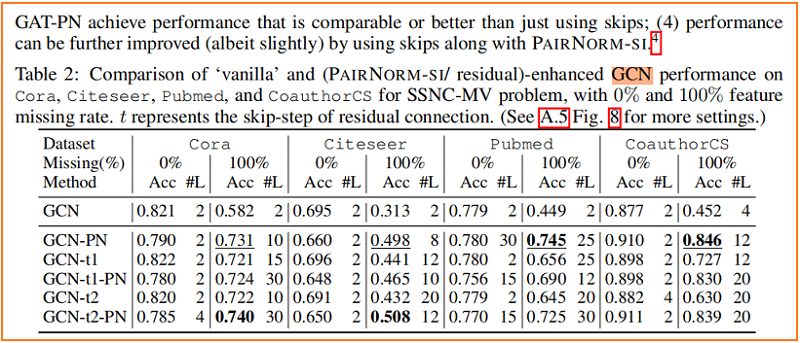
Figure 4 显示了随着层数的增加,SGC、GCN 和 GAT 模型在 Cora 上的性能变化,其中我们从所有未标记的节点中删除特征向量,即 $p=1$。与没有PAIRNORM 的模型相比,具有 PAIRNORM 的模型获得了更高的测试精度,它们通常会达到更多的层数。

4 Experiments
在本节中,我们设计了广泛的实验来评估在SSNC-MV设置下的SGC、GCN和GAT模型的有效性。
4.1 Experiment setup

4.2 Experiment results
节点分类


5 Conclusion
提出了一种有效防止过平滑问题的 成对范数 ,一种新的归一化层,提高了深度 GNNs 对过平滑的鲁棒性。
论文解读(PairNorm)《PairNorm: Tackling Oversmoothing in GNNs》的更多相关文章
- 论文解读(SR-GNN)《Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data》
论文信息 论文标题:Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data论文作者:Qi Zhu, ...
- 论文解读(KP-GNN)《How Powerful are K-hop Message Passing Graph Neural Networks》
论文信息 论文标题:How Powerful are K-hop Message Passing Graph Neural Networks论文作者:Jiarui Feng, Yixin Chen, ...
- 论文解读(ValidUtil)《Rethinking the Setting of Semi-supervised Learning on Graphs》
论文信息 论文标题:Rethinking the Setting of Semi-supervised Learning on Graphs论文作者:Ziang Li, Ming Ding, Weik ...
- itemKNN发展史----推荐系统的三篇重要的论文解读
itemKNN发展史----推荐系统的三篇重要的论文解读 本文用到的符号标识 1.Item-based CF 基本过程: 计算相似度矩阵 Cosine相似度 皮尔逊相似系数 参数聚合进行推荐 根据用户 ...
- CVPR2019 | Mask Scoring R-CNN 论文解读
Mask Scoring R-CNN CVPR2019 | Mask Scoring R-CNN 论文解读 作者 | 文永亮 研究方向 | 目标检测.GAN 推荐理由: 本文解读的是一篇发表于CVPR ...
- AAAI2019 | 基于区域分解集成的目标检测 论文解读
Object Detection based on Region Decomposition and Assembly AAAI2019 | 基于区域分解集成的目标检测 论文解读 作者 | 文永亮 学 ...
- Gaussian field consensus论文解读及MATLAB实现
Gaussian field consensus论文解读及MATLAB实现 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 一.Introduction ...
- zz扔掉anchor!真正的CenterNet——Objects as Points论文解读
首发于深度学习那些事 已关注写文章 扔掉anchor!真正的CenterNet——Objects as Points论文解读 OLDPAN 不明觉厉的人工智障程序员 关注他 JustDoIT 等 ...
- NIPS2018最佳论文解读:Neural Ordinary Differential Equations
NIPS2018最佳论文解读:Neural Ordinary Differential Equations 雷锋网2019-01-10 23:32 雷锋网 AI 科技评论按,不久前,NeurI ...
随机推荐
- Docker容器Nginx负载均衡配置、check及stub模块安装
Nginx是一款高性能的HTTP和反向代理.负载均衡web服务器.本次在Docker容器中部署三个tomcat,Nginx代理三个tomcat服务(以下称节点)来模拟实现负载均衡效果,配置check模 ...
- Elasticsearch学习系列一(部署和配置IK分词器)
Elasticsearch简介 Elasticsearch是什么? Elaticsearch简称为ES,是一个开源的可扩展的分布式的全文检索引擎,它可以近乎实时的存储.检索数据.本身扩展性很好,可扩展 ...
- Python-安装pycocotools错误记录
安装 pycocotools 时出现错误 fatal error: Python.h: No such file or directory 解决方式 apt-get install python3.8 ...
- labelimg使用指南
labelimg使用指南 From RSMX - https://www.cnblogs.com/rsmx/ 目录 labelimg使用指南 1. 确保已经安装了 Python 环境 2. 使用pip ...
- bat-使用bat安装jdk和配置环境变量
文件路径 @echo off Setlocal enabledelayedexpansion @REM vscode中自动开启延迟环境变量扩展, %~d0 cd %~dp0 @REM dir echo ...
- Jenkins + maven + svn 自动部署项目
1.安装Jenkins sudo wget -O /etc/yum.repos.d/jenkins.repo https://pkg.jenkins.io/redhat-stable/jenkins. ...
- C# / VB.NET 将Html转为Word
本文分享以C#程序代码为例,实现将Html文件转换Word文档的方法(附VB.NET代码).在实际转换场景中可参考本文的方法,转换前,请按照如下方法引用Word API的dll文件到Visual St ...
- Nacos 的安装与服务的注册
Nacos 的安装与服务的注册 我们都知道naocs是一个注册中心,那么注册中心是什么呢? 什么是注册中心? 它类似与一个中介角色(不收费的良心中介), 在微服务中起纽带的作用,它提供了服务和服务地址 ...
- Django定时任务Django-crontab的使用
在使用的django做测试平台时,,多多少少都会遇到需要定时任务的功能,比如定时执行任务,检查订单之类 的.可能是一段时间,比如每隔 10分钟执行一次,也可能是定点时间,比如 14:00 执行,也可能 ...
- JavaScript进阶知识点——函数和对象详解
JavaScript进阶知识点--函数和对象详解 我们在上期内容中学习了JavaScript的基本知识点,今天让我们更加深入地了解JavaScript JavaScript函数 JavaScript函 ...