彻底学会Selenium元素定位
转载请注明出处️
作者:测试蔡坨坨
原文链接:caituotuo.top/63099961.html
你好,我是测试蔡坨坨。
最近收到不少初学UI自动化测试的小伙伴私信,对于元素的定位还是有些头疼,总是定位不到元素,以及不知道用哪种定位方式更好。
其实UI自动化测试的本质就是将手工测试的一系列动作转化成机器自动执行,可以简单概括为五大步骤:定位元素 - 操作元素 - 模拟页面动作 - 断言结果 - 生成报告。所以很多同学在学习时,都是以元素定位作为入门导向,好的开始就是成功的一半。因此,本篇将详细介绍Selenium八大元素定位方法,以及在自动化测试框架中如何对元素定位方法进行二次封装,最后会给出一些在定位元素时的经验总结。
注意:本文出现的代码示例均以 Python3.10 + Selenium4.5.0 为准,由于网上大多数教程都是Selenium3,Selenium4相比于Selenium3会有一些新的语法,如果你还不了解Selenium4,推荐先阅读往期文章「Selenium 4 有哪些不一样?」。
Selenium八大元素定位
所谓八大元素定位方式就是id、name、class_name、tag_name、link_text、partial_link_text、xpath、css_selector。
在介绍定位方式之前先来说一下定位工具,以Chrome浏览器为例,使用F12或右键检查进入开发者工具。
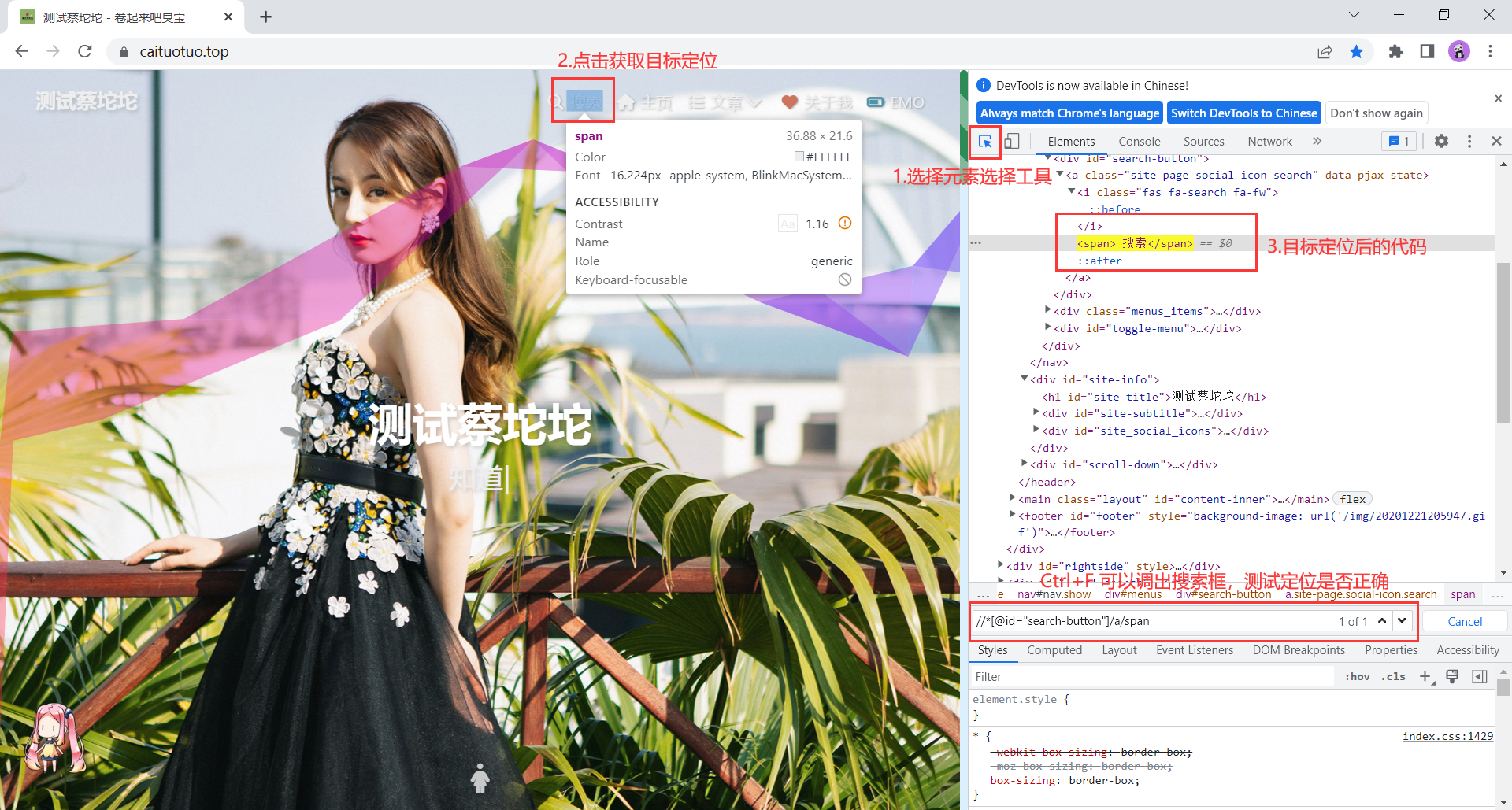
ID
通过元素的id属性定位,一般情况下id在当前页面中是唯一的。使用id选择器的前提条件是元素必须要有id属性。由于id值一般是唯一的,因此当元素存在id属性值时,优先使用id方式定位元素。
例如:下面的这个input标签的id属性值为kw
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">
语法:
driver.find_element(By.ID, "id属性值")
举栗:
# author: 测试蔡坨坨
# datetime: 2022/10/22 19:08
# function: id定位
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.find_element(By.ID, "kw").send_keys("测试蔡坨坨")
driver.find_element(By.ID, "su").click()
time.sleep(3)
driver.quit()
NAME
通过元素的name属性来定位。name定位方式使用的前提条件是元素必须有name属性。由于元素的name属性值可能存在重复,所以必须确定其能够代表目标元素唯一性后,方可使用。
当页面内有多个元素的特征值相同时,定位元素的方法执行时只会默认获取第一个符合要求的特征对应的元素。
例如:下面的这个input标签的name属性值为wd
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">
语法:
driver.find_element(By.NAME, "name属性值")
举栗:
# author: 测试蔡坨坨
# datetime: 2022/10/22 19:23
# function: name定位
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.find_element(By.NAME, "wd").send_keys("测试蔡坨坨")
driver.find_element(By.ID, "su").click()
time.sleep(3)
driver.quit()
CLASS_NAME
通过元素的class属性来定位,class属性一般为多个值。使用class定位方式的前提条件是元素必须要有class属性。
虽然方法名是class_name,但是我们要找的是class属性。
例如:下面这个input标签的class属性值为but1
<input class="but1" type="text" name="key" placeholder="请输入你要查找的关键字" value="">
语法:
driver.find_element(By.CLASS_NAME, "class属性值")
举栗:
# author: 测试蔡坨坨
# datetime: 2022/10/22 19:31
# function: class定位
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
# 打开电商网站
driver.get("http://127.0.0.1")
driver.maximize_window()
# 搜索框中输入 鞋子
driver.find_element(By.CLASS_NAME, "but1").send_keys("鞋子")
# 点击搜索
driver.find_element(By.CLASS_NAME, "but2").click()
注意:如果class name是一个复合类(存在多个属性值,每个属性值以空格隔开),则只能使用其中的任意一个属性值进行定位,但是不建议这么做,因为可能会定位到多个元素。
例如:下面这个标签的class属性值为bg s_btn btn_h btnhover
<input class="bg s_btn btn_h btnhover" type="text" name="key">
则只能使用复合类的任意一个单词去定位:
driver.find_element(By.CLASS_NAME,"bg") # 正确示范
driver.find_element(By.CLASS_NAME,"bg s_btn btn_h btnhover") # 错误示范 NoSuchElementException
TAG_NAME
通过元素的标签名称来定位,例如input标签、button标签、a标签等。
由于存在大量标签,并且重复性高,因此必须确定其能够代表目标元素唯一性后,方可使用。如果页面中存在多个相同标签,默认返回第一个标签元素。一般情况下标签重复性过高,要精确定位,都不会选择tag_name定位方式。
语法:
driver.find_element(By.TAG_NAME, "标签名称")
举栗:
driver.find_element(By.TAG_NAME, "input")
LINK_TEXT
定位超链接标签。只能使用精准匹配(即a标签的全部文本内容),该方法只针对超链接元素(a 标签),并且需要输入超链接的全部文本信息。
例如:下面这个a标签的全部文本内容为联系客服
<a href="http://XXX">联系客服</a>
语法:
driver.find_element(By.LINK_TEXT, "a标签的全部文本内容")
举栗:
# author: 测试蔡坨坨
# datetime: 2022/10/22 20:27
# function: link_text定位
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("http://127.0.0.1")
driver.maximize_window()
# 点击联系客服
driver.find_element(By.LINK_TEXT, "联系客服").click()
PARTIAL_LINK_TEXT
定位超链接标签,与LINK_TEXT不同的是它可以使用精准或模糊匹配,也就是a标签的部分文本内容,如果使用模糊匹配最好使用能代表唯一的关键词,如果有多个元素,默认返回第一个。
例如:下面这个a标签的全部文本内容为“联系客服”,模糊匹配就可以使用a标签的部分文本内容,比如联系、客服、联、服……
<a href="http://XXX">联系客服</a>
语法:
driver.find_element(By.PARTIAL_LINK_TEXT, "a标签的部分文本内容")
举栗:
# author: 测试蔡坨坨
# datetime: 2022/10/22 20:34
# function: partial_link_text定位器
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("http://127.0.0.1")
driver.maximize_window()
# 点击联系客服
driver.find_element(By.PARTIAL_LINK_TEXT, "联系").click()
XPATH
定义
XML Path Language 的简称,用于解析XML和HTML。(不仅可以解析XML还可以解析HTML,因为HTML与XML是非常相像的,XML多用于传输和存储数据,侧重于数据,HTML多用于显示数据并关注数据的外观)
Xpath策略有多种,无论使用哪一种策略,定位的方法都是同一个,不同策略只决定方法的参数的写法。
Xpath不仅可以用于Selenium,还适用于Appium,是一个万能的定位方式。
Xpath有一个缺点,就是速度比较慢,比CSS_SELECT要慢很多,因为Xpath是从头到尾一点一点去遍历。
绝对路径
从最外层元素到指定元素之间所有经过元素层级的路径 ,绝对路径是以/html根节点开始,使用 / 来分割元素层级的语法,比如:/html/body/div[2]/div/div[2]/div[1]/form/input[1](因为会有多个div标签,所以用索引的方式定位div[2],且XPath的下标是从1开始的,例如:/bookstore/bool[1]表示选取属于bookstore子元素的第一个book元素,除了用数字索引外,还可以用last()、position()函数来表达索引,例如:/bookstore/book[last()]表示选取属于bookstore子元素的最后一个book元素,/bookstore/book[last()-1]表示选取属于bookstore子元素的倒数第二个book元素,/bookstore/book[position()️]表示选取最前面的两个属于bookstore元素的子元素的book元素)
由于绝对路径对页面结构要求比较严格,因此不建议使用绝对路径。
语法:
driver.find_element(By.XPATH, "/html开头的绝对路径")
举栗:
# author: 测试蔡坨坨
# datetime: 2022/10/23 11:13
# function: xpath绝对路径
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
# 打开电商网站
driver.get("http://127.0.0.1")
driver.maximize_window()
# 绝对路径
# 搜索框输入 阿迪达斯
# XPath的下标是从1开始的
driver.find_element(By.XPATH, "/html/body/div[2]/div/div[2]/div[1]/form/input[1]").send_keys("阿迪达斯")
# 点击搜索
driver.find_element(By.XPATH, "/html/body/div[2]/div/div[2]/div[1]/form/input[2]").click()
driver.quit()
相对路径
匹配任意层级的元素,不限制元素的位置 ,相对路径是以 // 开始, // 后面跟元素名称,不知元素名称时可以使用 * 号代替,在实际应用中推荐使用相对路径。
语法:
driver.find_element(By.XPATH, "//input")
driver.find_element(By.XPATH, "//*")
举栗:
# author: 测试蔡坨坨
# datetime: 2022/10/23 12:35
# function: xpath相对路径
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
# 打开电商网站
driver.get("http://127.0.0.1")
driver.maximize_window()
# 相对路径
# XPath相对路径以 // 开头
# 搜索框输入 鞋子
driver.find_element(By.XPATH, "//input[@class='but1']").send_keys("鞋子")
# 点击搜索按钮
driver.find_element(By.XPATH, "//*[@class='but2']").click()
使用浏览器开发者工具直接复制xpath路径值(偷懒的方法,不推荐在学习的时候使用):
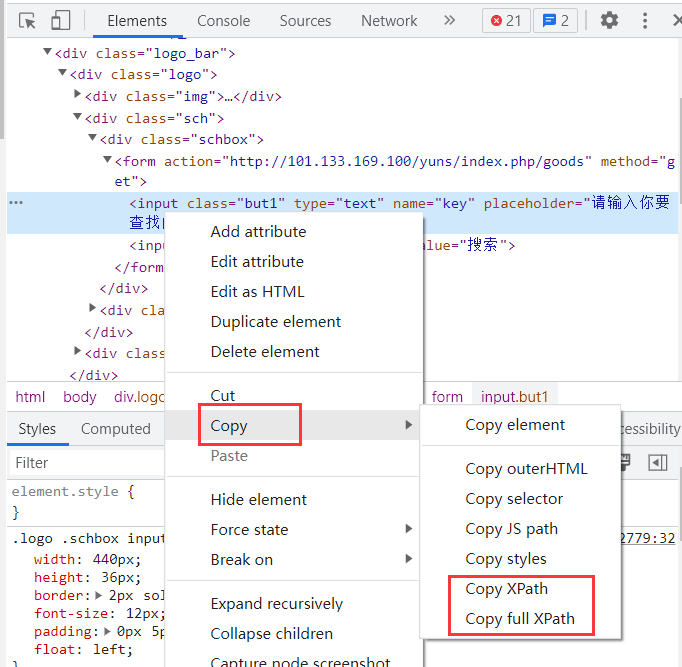
通过元素属性定位
单个属性
使用目标元素的任意一个属性和属性值(需保证唯一性)。
注意:
使用 XPath 策略,建议先在浏览器开发者工具中根据策略语法,组装策略值,测试验证后再放入代码中使用。
目标元素的有些属性和属性值可能存在多个相同特征的元素,需注意唯一性。
语法:
driver.find_element(By.XPATH, "//标签名[@属性='属性值']")
driver.find_element(By.XPATH, "//*[@属性='属性值']")
比如:下面这个input标签的placeholder属性的属性值为“请输入你要查找的关键字”
<input class="but1" type="text" name="key" placeholder="请输入你要查找的关键字">
举栗:
# author: 测试蔡坨坨
# datetime: 2022/10/23 17:27
# function: 单个属性
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("http://127.0.0.1")
driver.maximize_window()
# 通过单个属性匹配
driver.find_element(By.XPATH, "//input[@placeholder='请输入你要查找的关键字']").send_keys("测试蔡坨坨")
多个属性
通过多个属性和属性值进行匹配,解决单个属性和属性值无法定位元素唯一性的问题。
多个属性可由多个 and 连接,每一个属性都要以 @ 开头,可以根据需求使用更多属性值。
语法:
driver.find_element(By.XPATH, "//标签名[@属性1='属性值1' and @属性2='属性值2']")
driver.find_element(By.XPATH, "//*[@属性1='属性值1' and @属性2='属性值2']")
比如:下面这个input标签的class属性的属性值为"but1",placeholder属性的属性值为"请输入你要查找的关键字"
<input class="but1" type="text" name="key" placeholder="请输入你要查找的关键字" value="">
举栗:
# author: 测试蔡坨坨
# datetime: 2022/10/23 17:38
# function: 多个属性匹配
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("http://127.0.0.1")
driver.maximize_window()
# 通过多个属性匹配
driver.find_element(By.XPATH, "//input[@class='but1' and @placeholder='请输入你要查找的关键字']").send_keys("测试蔡坨坨")
通过属性模糊匹配
通过属性值的部分内容进行匹配。
语法:
driver.find_element(By.XPATH, "//标签名[contains(@属性,'属性值的部分内容')]")
driver.find_element(By.XPATH, "//*[contains(@属性,'属性值的部分内容')]")
比如:下面这个input标签的placeholder属性的属性值为"请输入你要查找的关键字",模糊匹配就可以是"请输入"
<input class="but1" type="text" name="key" placeholder="请输入你要查找的关键字">
举栗:
# author: 测试蔡坨坨
# datetime: 2022/10/23 17:41
# function: contains模糊匹配
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("http://127.0.0.1")
driver.maximize_window()
# 通过contains模糊匹配属性值
driver.find_element(By.XPATH, "//input[contains(@placeholder,'请输入')]").send_keys("测试蔡坨坨")
starts-with属性值以XX开头
语法:
driver.find_element(By.XPATH, "//标签名[starts-with(@属性,'属性值的开头部分')]")
driver.find_element(By.XPATH, "//*[starts-with(@属性,'属性值的开头部分')]")
比如:下面这个input标签的placeholder属性的属性值以"请输入"开头
<input class="but1" type="text" name="key" placeholder="请输入你要查找的关键字">
举栗:
# author: 测试蔡坨坨
# datetime: 2022/10/23 18:01
# function: starts-with定位属性值以xxx开头的元素
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("http://127.0.0.1")
driver.maximize_window()
driver.find_element(By.XPATH, "//input[starts-with(@placeholder,'请输入')]").send_keys("测试蔡坨坨")
文本值定位
通过标签的文本值进行定位,定位文本值等于XX的元素,一般适用于p标签、a标签。
语法:
driver.find_element(By.XPATH, "//*[text()='文本信息']")
比如:下面这个a标签的文本信息为"免费注册"
<a href="http://127.0.0.1/register">免费注册</a>
举栗:
# author: 测试蔡坨坨
# datetime: 2022/10/23 17:41
# function: text()文本信息定位
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("http://127.0.0.1")
driver.maximize_window()
driver.find_element(By.XPATH, "//*[text()='免费注册']").click()
CSS_SELECTOR
通过CSS选择器语法定位元素。
适用于Selenium和Appium,但是需要注意的是,原生的app控件不支持CSS_SELECTOR,只支持Xpath。
Selenium框架官方推荐使用CSS定位,因为CSS定位效率高于XPATH。
CSS是一种标记语言,控制元素的显示样式,就必须找到元素,在CSS标记语言中找元素使用CSS选择器。
CSS的选择策略也多很多种,但是无论选择哪一种选择策略都是用同一种定位方法。
定位方法:
driver.find_element(By.CSS_SELECTOR, "CSS选择策略")
绝对路径
以html开始,使用 > 或 空格 分隔,与XPATH一样,CSS_SELECTOR的下标也是从1开始。
driver.find_element(By.CSS_SELECTOR, "html>body>div>div>div>div>form>input:nth-child(1)").send_keys("测试蔡坨坨") # 使用>分隔
driver.find_element(By.CSS_SELECTOR, "html body div div div div form input:nth-child(1)").send_keys("测试蔡坨坨") # 使用空格分隔
driver.find_element(By.CSS_SELECTOR, "html>body>div>div div div form input:nth-child(1)").send_keys("测试蔡坨坨") # 使用 空格 + > 分隔
相对路径
不以html开头,以CSS选择器开头,比如标id选择器、class选择器等。
举栗:
driver.find_element(By.CSS_SELECTOR, "input.but1").send_keys("测试蔡坨坨")
id选择器
语法:# 开头表示id选择器
driver.find_element(By.CSS_SELECTOR, "标签#id属性值")
举栗:
driver.find_element(By.CSS_SELECTOR, "i#cart_num").click()
class选择器
语法:. 开头表示class选择器,或者使用[class='class属性值']
如果具有多个属性值的class,则需要传入全部的属性值
driver.find_element(By.CSS_SELECTOR, ".class属性值")
driver.find_element(By.CSS_SELECTOR, "[class='class属性值']")
举栗:
driver.find_element(By.CSS_SELECTOR, ".but2").click()
driver.find_element(By.CSS_SELECTOR, "[class='but2']").click()
属性选择器
单个属性
语法:
driver.find_element(By.CSS_SELECTOR, "标签名[属性='属性值']")
driver.find_element(By.CSS_SELECTOR, "[属性='属性值']")
举栗:
driver.find_element(By.CSS_SELECTOR, "input[placeholder='请输入你要查找的关键字']").send_keys("测试蔡坨坨")
driver.find_element(By.CSS_SELECTOR, "[placeholder='请输入你要查找的关键字']").send_keys("测试蔡坨坨")
多个属性
语法:注意与xpath的区别
driver.find_element(By.CSS_SELECTOR, "标签名[属性1='属性值1'][属性2='属性值2']")
举栗:
driver.find_element(By.CSS_SELECTOR, "input[name='key'][class='but1']").send_keys("测试蔡坨坨")
模糊匹配
driver.find_element(By.CSS_SELECTOR, "[属性^='开头的字母']") # 获取指定属性以指定字母开头的元素
driver.find_element(By.CSS_SELECTOR, "[属性$='结束的字母']") # 获取指定属性以指定字母结束的元素
driver.find_element(By.CSS_SELECTOR, "[属性*='包含的字母']") # 获取指定属性包含指定字母的元素
标签选择器
语法:
driver.find_element(By.CSS_SELECTOR, "标签名") # 例如:input、button
层级关系
父子层级关系:父层级策略 > 子层级策略 (也可以使用空格连接上下层级)
祖辈后代层级关系:祖辈策略 后代策略
> 与 空格 的区别:大于号必须为子元素,空格则不用
first-child
第一个子元素
<div class="help">
<a href="http://127.0.0.1">首页</a>
<a href="http://127.0.0.1/buy">我的订单</a>
<a href="http://127.0.0.1//help">联系客服</a>
</div>
driver.find_element(By.CSS_SELECTOR, ".help>a:first-child").click() # 首页
last-child
最后一个子元素
driver.find_element(By.CSS_SELECTOR, ".help>a:last-child").click() # 联系客服
nth-last-child()
倒序
driver.find_element(By.CSS_SELECTOR, ".help>a:nth-last-child(2)").click() # 我的订单
nth-child()
正序
driver.find_element(By.CSS_SELECTOR, ".help>a:nth-child(3)").click() # 联系客服
干儿子和亲儿子
若一个标签下有多个同级标签,虽然这些同级标签的 tag name 不一样,但是他们是放在一起排序的。
# author: 测试蔡坨坨
# datetime: 2022/10/23 20:20
# function: css_selector 不区分干儿子和亲儿子
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.maximize_window()
# css_selector 不区分干儿子和亲儿子,
# 若一个标签下有多个同级标签,虽然这些同级标签的tag name不一样,但是他们是放在一起排序的
# 打开百度,在搜索框中输入 测试蔡坨坨 ,点击百度一下
driver.find_element(By.CSS_SELECTOR, "form#form>span:nth-child(8)>input").send_keys("测试蔡坨坨")
driver.find_element(By.CSS_SELECTOR, "form#form>span:nth-child(9)>input").click()
元素定位二次封装
在之前的文章中我们介绍过UI自动化测试框架,可参考往期文章「五分钟搞懂 POM 设计模式」。
框架中的base_page模块对Selenium一些常用的API进行二次封装,其中就有对find_element的封装。
base_page.py:
class BasePage(object):
def __init__(self, driver):
self.logger = GetLogger().get_logger()
self.driver = driver
def wait_ele_visible_(self, loc, loc_doc, times=3, poll_frequency=0.5):
"""
等待元素可见
:param loc: 元素定位
:param loc_doc: 元素描述
:param times: 最长等待时间
:param poll_frequency: 轮询频率,调用 until 或 until_not方法中的间隔时间,默认为0.5秒
:return:
"""
try:
@do_time
def fun():
WebDriverWait(self.driver, times, poll_frequency).until(EC.visibility_of_element_located(loc))
self.logger.info("等待【{}】元素【{}】出现,耗时:{}豪秒".format(loc_doc, loc, fun()))
except Exception:
self.logger.error("等待【{}】元素【{}】出现失败".format(loc_doc, loc))
raise
def find_element_(self, loc, loc_doc):
"""
查找元素
:param loc: 元素定位 例如:login_icon_loc = (By.ID, "sb_form_q")
:param loc_doc: 对元素的描述
:return:
"""
try:
self.logger.info("开始查找【{}】元素【{}】".format(loc_doc, loc))
self.wait_ele_visible_(loc, loc_doc)
return self.driver.find_element(*loc)
except Exception:
self.logger.error("查找【{}】元素【{}】失败".format(loc_doc, loc))
raise
元素定位总结
首先考虑id定位,id定位是效率最高的
一般情况下id属性在当前页面是唯一的。
在实际企业项目中,可能需要前端同学的配合,保证元素唯一属性命名规则。所有可操作元素,例如输入框、点击按钮等均需要加id字段,并且id字段的命名为元素含义的英文;若当前页面存在两个或多个一样的元素,则第二个开始命名为id=username2,以此类推;多层级元素一般最外层定义即可。
如果没有id,再选择xpath,一般使用相对路径
css_selector比xpath更加稳定
为什么说css_selector比xpath更稳定?因为我们通过Chrome浏览器的开发者工具可以看出蓝色线代表DOM出现,红色线代表图片等资源已加载完,如果用xpath定位元素,其实是在DOM出现的时候进行查找,而当你使用css_selector进行元素定位的时候,它会等待图片资源加载完成后进行查找,也就是红线的位置,所以css_selector比xpath更稳定,当你使用xpath定位不到元素时,不妨尝试使用css_selector。

tag_name使用频率最低
尽量不要用href属性、纯数字的属性(纯数字可能是个动态值)去定位
对于Toast提示框,很快消失的提示框,可以点击 开发者工具-sources中的暂停键 后再去定位
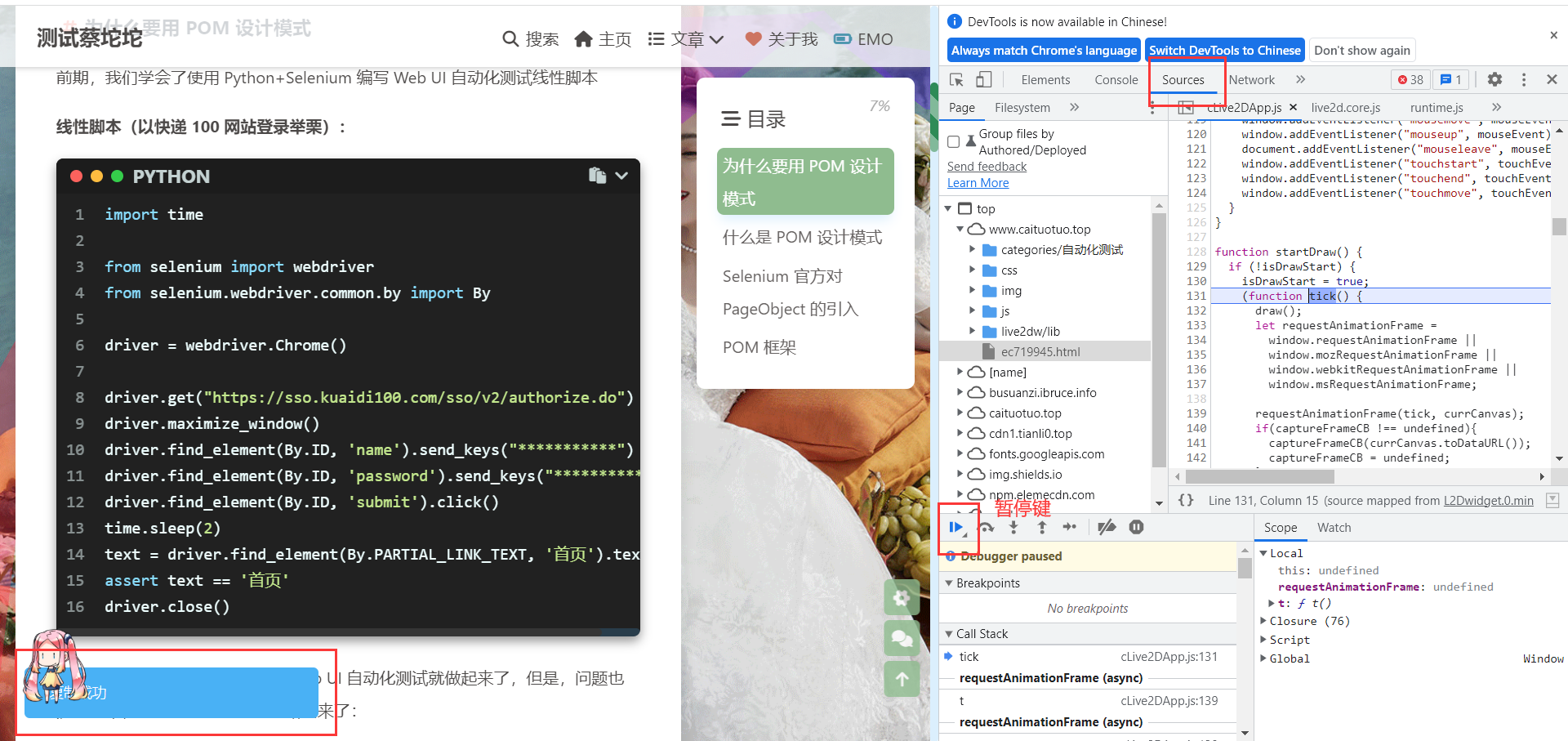
添加适当的等待时间,避免等待时间不够,元素还未加载出来
多窗口时需考虑窗口句柄是否还处在上一个窗口,导致无法定位新窗口的元素,是否需要切换窗口句柄
iframe/frame,这是个常见的定位不到元素的原因,frame中实际上是嵌入了另一个页面,而webdriver每次只能在一个页面识别,因此需要先定位到相应的frame,再对那个页面里的元素进行定位
如果使用xpath或css_selector,请在浏览器开发者工具中调试测试正确后再写入代码中
彻底学会Selenium元素定位的更多相关文章
- 自动化测试基础篇--Selenium元素定位
摘自https://www.cnblogs.com/sanzangTst/p/7457111.html 一.Selenium元素定位的重要性: Web自动化测试的操作:获取UI页面的元素,对元素进行操 ...
- Selenium3 + Python3自动化测试系列二——selenium元素定位
一.selenium元素定位 Selenium对网页的控制是基于各种前端元素的,在使用过程中,对于元素的定位是基础,只有准去抓取到对应元素 才能进行后续的自动化控制,我在这里将对selenium8种元 ...
- selenium元素定位之css选择器
在selenium元素定位时会用到css选择器选取元素,虽说xpath在定位元素时能解决大部分问题,但使用css选择器选取元素也是一种不错的选择. css相较与xpath选择元素优点如下: 表达式更加 ...
- selenium元素定位陷阱规避
为什么selenium可以在各个浏览器上运行?因为selenium在与各个浏览器驱动执行前,会先把脚本转化成webdriver, webdriver wire协议(一种json格式的协议),这样就与脚 ...
- python学习之——selenium元素定位
web自动化测试按步骤拆分,可以分为四步操作:定位元素,操作元素,获取返回结果,断言(返回结果与期望结果是否一致),最后自动出测试报告. 其中定位元素尤为关键,此篇是使用webdriver通过页面各个 ...
- selenium元素定位篇
Selenium webdriver是完全模拟用户在对浏览器进行操作,所有用户都是在页面进行的单击.双击.输入.滚动等操作,而webdriver也是一样,所以需要我们指定元素让webdriver进行单 ...
- python selenium 元素定位(三)
上两篇的博文中介绍了python selenium的环境搭建和编写的第一个自动化测试脚本,从第二篇的例子中看出来再做UI级别的自动化测试的时候,有一个至关重要的因素,那就是元素的定位,只有从页面上找到 ...
- selenium元素定位大全
要做自动化,首先要了解页面结构,要了解页面结构,就要了解页面元素的定位方法 在使用selenium webdriver进行元素定位时,通常使用findElement或findElements方法结合B ...
- selenium元素定位不到之iframe
我们在使用selenium的18中定位方式的时候,有时会遇到定位不上的问题,今天我们就来说说导致定位不上的其中一个原因---iframe 问题描述:通过firebug查询到相应元素的id或name等, ...
随机推荐
- Regular采样类定义和测试
这个算法是均匀采样算法,继承于Sampler类. 类声明: #pragma once #ifndef __REGULAR_HEADER__ #define __REGULAR_HEADER__ #in ...
- Docker 02 基本命令
参考源 https://www.bilibili.com/video/BV1og4y1q7M4?spm_id_from=333.999.0.0 https://www.bilibili.com/vid ...
- Canvas 线性图形(二):圆形
函数 arc(x, y, radius, startAngle, endAngle, counterclockwise) 参数名 描述 x.y 圆心坐标轴 radius 圆的半径 startAngle ...
- 【JDBC】学习路径3-密码登录&SQL注入攻击
最后再提醒一句,每次在测试JDBC程序的时候,一定要确保MySQL正在运行. 打开控制台(终端),输入mysql 如果没启动,则出现以下提示: Mac端启动MySQL数据库,需要在系统便好设置中启动. ...
- 简单创建一个SpringCloud2021.0.3项目(一)
目录 1. 项目说明 1. 版本 2. 用到组件 3. 功能 2. 新建父模块和注册中心 1. 新建父模块 2. 新建注册中心Eureka 3. 新建配置中心Config 4. 新建两个业务服务 1. ...
- helm安装csi-driver-smb-v1.9.0
Application version v1.9.0 Chart version v1.9.0 获取chart包 helm repo add csi-driver-smb https://raw.gi ...
- 【设计模式】Java设计模式 - 原型模式
[设计模式]Java设计模式 - 原型模式 不断学习才是王道 继续踏上学习之路,学之分享笔记 总有一天我也能像各位大佬一样 原创作品,更多关注我CSDN: 一个有梦有戏的人 准备将博客园.CSDN一起 ...
- C++ 由快排学习到的的随机数等知识
起: 力扣的912题 数组排序 ,想着先用快速排序来写写,在实际用c++编写的时候,有一些之前没注意到的细节问题造成了一些麻烦. 912. 排序数组 - 力扣(LeetCode) 快排思想 每次以数组 ...
- stm32fxx_hal_i2c.c解读之HAL_I2C_Mem_Write
HAL_I2C_Mem_Write()函数位于stm32fxx_hal_i2c.c文件的2432行,源代码对该函数的解释如下图 HAL_StatusTypeDef HAL_I2C_Mem_Write( ...
- 数论进阶 
数论进阶 扩展欧几里得算法 裴蜀定理(Bézout's identity) \(1\) :对于任意整数 \(a\),\(b\) ,存在一对整数 \(x\) ,\(y\) ,满足 \(ax+by=GCD ...