NLP之TextRNN(预测下一个单词)
TextRNN
@
1.基本概念
1.1 RNN和CNN的区别
并非刚性地记忆所有固定⻓度的序列,⽽是通过隐藏状态来存储之前时间步的信息
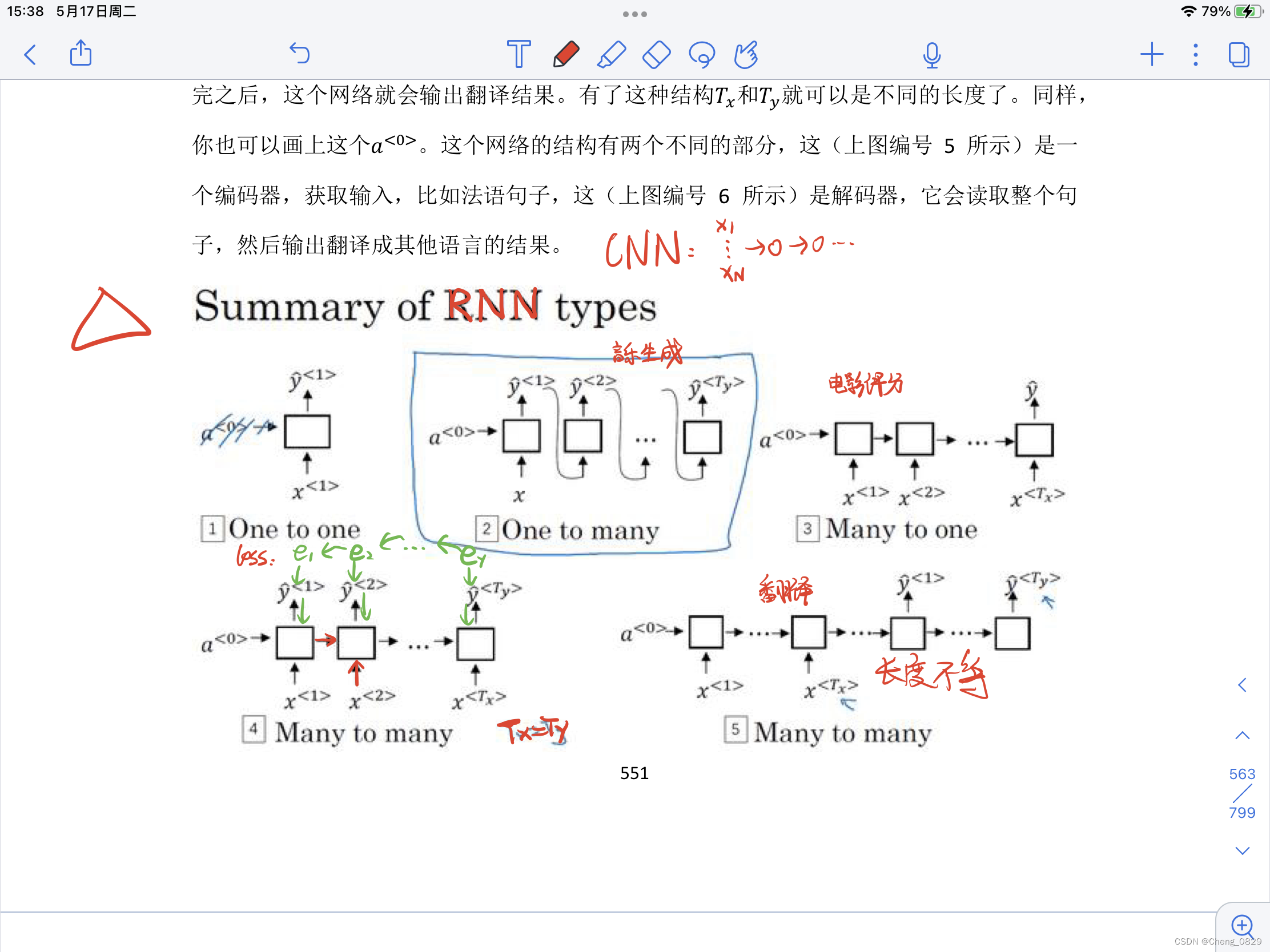
1.2 RNN的几种结构
一对一,一对多,多对一,多对多(长度相等/不等)
多个输入时,由a和x生成y和下一个a, 这一过程可以用nn.GRU和nn.LSTM模块表示,即可使用门控制单元或长短记忆模型,因此BiLSTM也可看作BiRNN+LSTM(编程时,双向和单向的不同就是在nn.LSTM()中添加一个bidirectional=True)
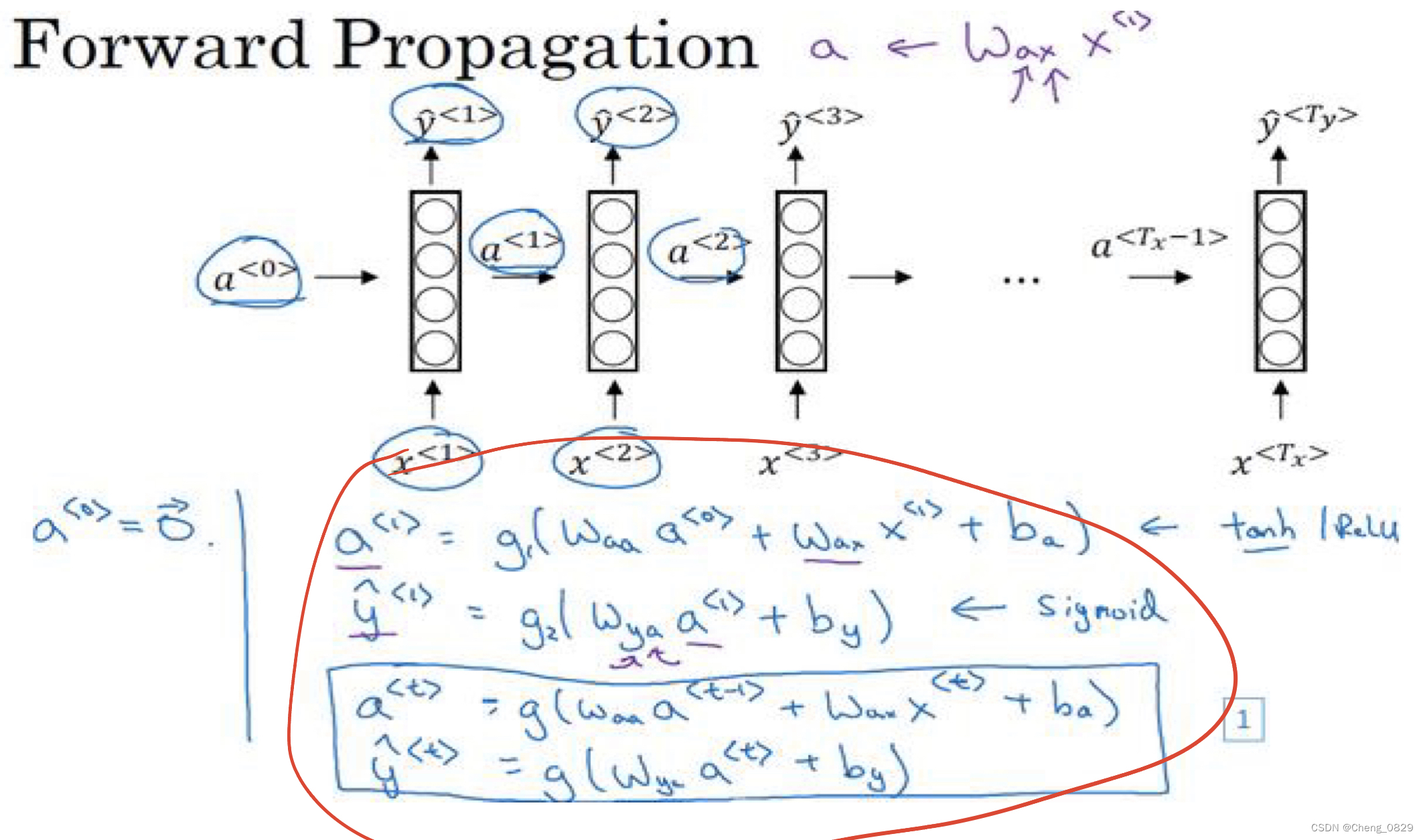
1.3 多对多的RNN
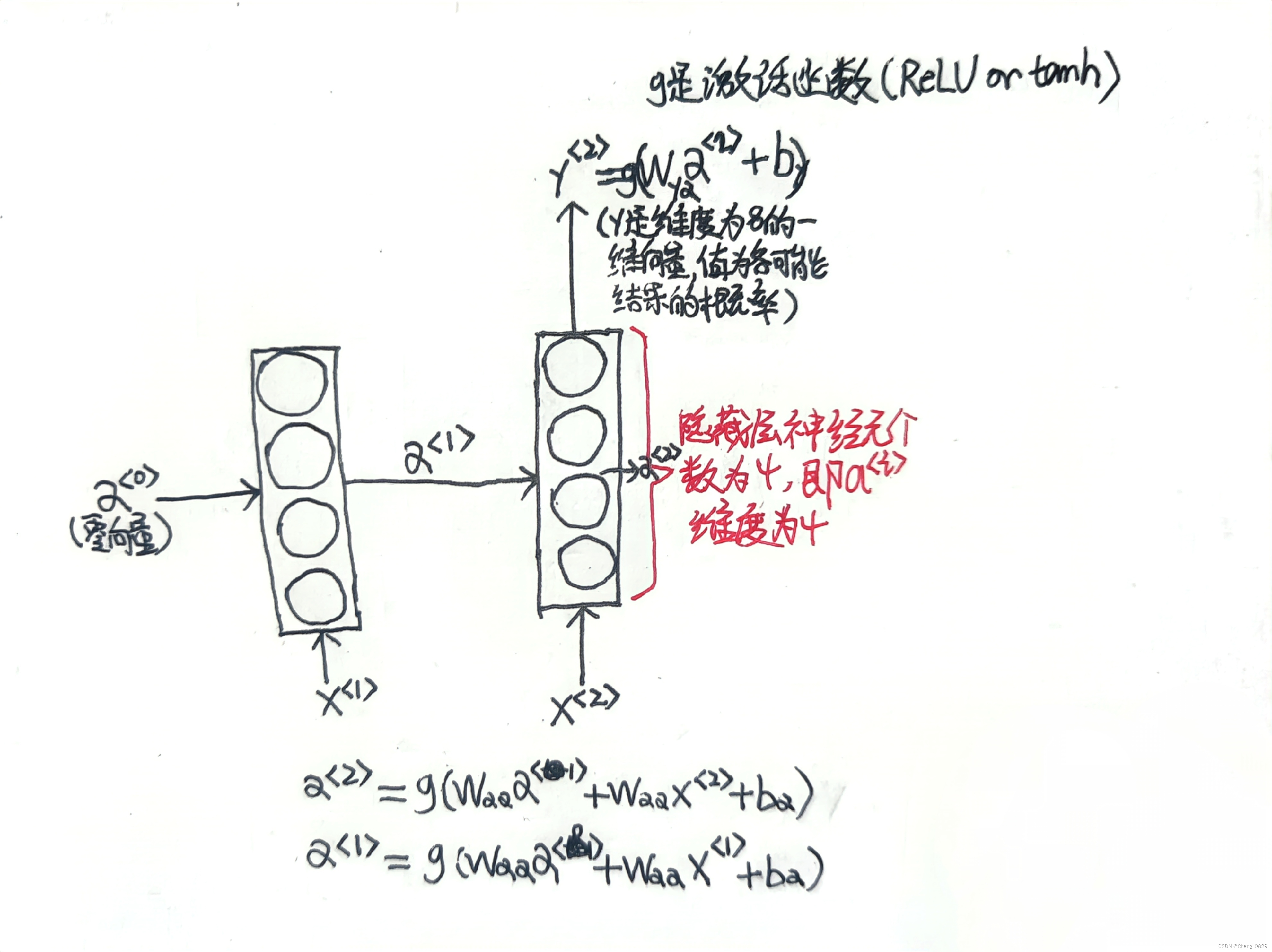
先输入零向量\(a^{<0>}\),然后前向传播,先计算激活值\(a^{<1>}\),然后计算\(y^{<1>}\).
\(a^{<1>}=g_1(W_{aa}a^{<0>}+W_{ax}x^{<1>}+b_a)\)
\(y^{<1>}=g_2(W_{ya}a^{<1>}+b_y)\)
1.4 RNN的多对多结构
1.5 RNN的多对一结构
从1.2 RNN的几种结构可以看到多对一RNN和多对多RNN的不同之处,但是在训练中仍然把多对一RNN当作多对多RNN训练,只是不使用最后训练出的\(y^{<1>}\)~\(y^{<t-1>}\)
1.6 RNN的缺点
如果训练非常深的神经网络,对这个网络做从左到右的前向传播和而从右到左的后向传播,会发现输出\(y^{<t>}\)很难传播回去,很难影响前面的权重,这样的梯度消失问题使得RNN常常出现局部效应,不擅长处理长期依赖的问题
和梯度爆炸不同的是,梯度爆炸会使得参数爆炸,很容易就发现大量的NaN参数,因此可以很快地进行梯度修剪;但是梯度消失不仅难以察觉,而且很难改正
2.实验
2.1 实验步骤
- 数据预处理,得到单词字典、样本数等基本数据
- 构建RNN模型,设置输入模型的嵌入向量维度和隐藏层α向量的维度
- 训练
- 代入数据,设置每个样本的时间步长度
- 得到模型输出值,取其中最大值的索引,找到字典中对应的单词,即为模型预测的下一个单词.
- 把模型输出值和真实值相比,求得误差损失函数,运用Adam动量法梯度下降
- 测试
2.2 算法模型
"""
Task: 基于TextRNN的单词预测
Author: ChengJunkai @github.com/Cheng0829
Email: chengjunkai829@gmail.com
Date: 2022/09/08
Reference: Tae Hwan Jung(Jeff Jung) @graykode
"""
import numpy as np
import torch, os, sys, time
import torch.nn as nn
import torch.optim as optim
'''1.数据预处理'''
def pre_process(sentences):
# 分词
word_sequence = " ".join(sentences).split()
# 去重
word_list = []
'''
如果用list(set(word_sequence))来去重,得到的将是一个随机顺序的列表(因为set无序),
这样得到的字典不同,保存的上一次训练的模型很有可能在这一次不能用
(比如上一次的模型预测碰见i:0,love:1,就输出dog:2,但这次模型dog在字典3号位置,也就无法输出正确结果)
'''
for word in word_sequence:
if word not in word_list:
word_list.append(word)
# 字典
word_dict = {w:i for i, w in enumerate(word_list)}
word_dict["''"] = len(word_dict)
number_dict = {i:w for i, w in enumerate(word_list)}
number_dict[len(number_dict)] = "''"
word_list.append("''")
num_words = len(word_dict) # 词库大小:8
# 本实验不采用随机抽样,所以batch_size等于样本数
batch_size = len(sentences) # 样本数:5
# print(word_dict)
# print(number_dict)
# print(word_list)
return word_sequence, word_list, word_dict, number_dict, num_words, batch_size
'''根据句子数据,构建词元的嵌入向量及目标词索引'''
def make_batch(sentences,mode='train'):
# 和Word2Vec的random_batch基本一致,区别在于不随机
input_batch = []
target_batch = []
for sen in sentences:
words = sen.split() # 分词
for i in range(len(words)):
if(words[i] not in word_list):
words[i] = "''"
if mode == 'train':
input = [word_dict[n] for n in words[:-1]] # 创建最后一个词之前所有词的序号列表
input_batch.append(np.eye(num_words)[input]) # 最后一个词之前所有词的嵌入向量
target = word_dict[words[-1]] # 每个目标词的序号
target_batch.append(target) # 记录每个目标词的序号
else:
input = [word_dict[n] for n in words] # 创建所有词的序号列表
input_batch.append(np.eye(num_words)[input]) # 所有词的嵌入向量
input_batch = torch.FloatTensor(np.array(input_batch))
target_batch = torch.LongTensor(np.array(target_batch))
input_batch = input_batch.to(device)
target_batch = target_batch.to(device)
return input_batch, target_batch
'''2.构建模型:多对一RNN(本实验结构图详见笔记)'''
class TextRNN(nn.Module):
def __init__(self):
super().__init__()
'''nn.RNN(input_size, hidden_size, num_layers=1, bidirectional=False)
Args:
input_size : 嵌入向量维度
hidden_size : 隐藏层alpha维度(隐藏层的神经元个数)
num_layers=1 : 循环层数.设置num_aayers=2将意味着将两个RNN堆叠在一起,
其中第二个RNN接受第一个RNN的输出并计算最终结果(Default:1)
bidirectional: If ``True``, becomes a bidirectional RNN.(Default:False)
'''
'''nn.RNN:[嵌入向量维度, 隐藏层alpha维度]'''
# 即x的维度和α的维度
self.rnn = nn.RNN(input_size=num_words, hidden_size=hidden_size) # (8,4)
'''Weight:[隐藏层alpha维度, 嵌入向量维度]'''
self.Weight = nn.Linear(hidden_size, num_words, bias=False) # (4,8)
self.bias = nn.Parameter(torch.ones([num_words]))
'''每个样本输入的单词数和模型的时间步长度相等'''
def forward(self, X, hidden): # model(input_batch, hidden)
'''transpose(~) 矩阵转置
X(input_batch):[5,2,8] -> transpose -> [2,5,8]
'''
X = X.transpose(0,1) # 第0维和第1维转置
# X : [n_step, batch_size, num_words]
'''X:[输入序列长度(时间步长度),样本数,嵌入向量维度] -> [2,5,8]'''
'''hidden即为alpha'''
'''
RNN:(8,4) X:(2,5,8) hidden:(1,5,4) -> alpha_outputs:(2,5,4) alpha_t:(1,5,4)
alpha_t是最后一个时间步的输出 : [1,样本数,隐藏层alpha维度(隐藏层的神经元个数)] -> [1,5,4]
alpha_outputs存储所有时间步的输出,所以alpha_outputs[-1]和alpha_t值一样(除了前者[5,4]后者[1,5,4])
本实验为多对一,所以仅需alpha_t,若为多对多,则需要对alpha_outputs中每个alpha求y=W(alpha)+b
'''
alpha_outputs, alpha_t = self.rnn(X, hidden) # alpha_t:[batch_size, num_directions(=1)*hidden_size]
alpha_outputs = alpha_outputs.to(device)
# Weight:[隐藏层alpha维度, 嵌入向量维度] alpha_t:[1,样本数,隐藏层alpha维度]
# Weight:[4,8] alpha_t:[1,5,4] Weight(alpha_t):[5,8]
# Y_t:[样本数,各单词的概率] -> [5,8] 最大值所在索引即为预测的单词索引
# alpha_t[0]==alpha_outputs[-1]
'''既可以使用alpha_t[0],也可以使用alpha_outputs[-1]'''
Y_t = alpha_outputs[-1]
Y_t = self.Weight(Y_t) + self.bias # self.bias:(num_words,) (8,)
return Y_t
if __name__ == '__main__':
hidden_size = 4 # 隐藏层alpha维度(隐藏层的神经元个数)
device = ['cuda:0' if torch.cuda.is_available() else 'cpu'][0]
sentences = ["i like dog", "i love coffee", "i love coffee", "you love cloud", "i hate milk"]
'''1.数据预处理'''
word_sequence, word_list, word_dict, number_dict, num_words, batch_size = pre_process(sentences)
input_batch, target_batch = make_batch(sentences)
'''2.构建模型'''
model = TextRNN()
model.to(device)
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam动量梯度下降法
if os.path.exists('model_param.pt') == True:
# 加载模型参数到模型结构
model.load_state_dict(torch.load('model_param.pt', map_location=device))
'''3.训练'''
print('{}\nTrain\n{}'.format('*'*30, '*'*30))
loss_record = []
for epoch in range(1000):
optimizer.zero_grad() # 把梯度置零,即把loss关于weight的导数变成0
# hidden : [num_layers(=1)*num_directions(=1), batch_size, hidden_size]
'''hidden:[层数*网络方向,样本数,隐藏层的维度(隐藏层神经元个数)] -> [1,5,4]'''
# α_0常以零向量输入
hidden = torch.zeros(1, batch_size, hidden_size).to(device) # (1,5,4)
'''input_batch:[样本数,输入序列长度(时间步长度), 嵌入向量维度] -> [5,2,8]'''
output = model(input_batch, hidden) # [batch_size, num_words]
loss = criterion(output, target_batch) # 将输出与真实目标值对比,得到损失值
loss.backward() # 将损失loss向输入侧进行反向传播,梯度累计
optimizer.step() # 根据优化器对W、b和WT、bT等参数进行更新(例如Adam和SGD)
if loss >= 0.01: # 连续30轮loss小于0.01则提前结束训练
loss_record = []
else:
loss_record.append(loss.item())
if len(loss_record) == 30:
torch.save(model.state_dict(), 'model_param.pt')
break
if ((epoch+1) % 100 == 0):
print('Epoch:', '%04d' % (epoch + 1), 'Loss = {:.6f}'.format(loss))
torch.save(model.state_dict(), 'model_param.pt')
'''4.测试'''
print('{}\nTest\n{}'.format('*'*30, '*'*30))
sentences = ["i like", "i hate", "you love", "you love my", "you"]
for sen in sentences: # 每个样本逐次预测,避免长度不同
hidden = torch.zeros(1, 1, hidden_size).to(device)
input_batch, target_batch = make_batch([sen], mode='predict')
# 代码功能时预测下一个单词,所以每个样本只生成一个单词
predict = model(input_batch, hidden) # [1,10] [1,dict_size]
predict = predict.data.max(1, keepdim=True)[1] #[1,1]
result = predict.squeeze().item() # tensor([[~]]) -> tensor(~) -> ~
print(sen + ' -> ' + number_dict[result])
'''
为什么训练集句子长度都是2,但是测试集可以不是?
make_batch的input_batch维度是[batch_size(样本数), n_step(样本单词数),n_class]
n_step是输入序列长度,之前疑惑为什么只有2个rnn单元,却可以输入其他个数的字母,
实际上,模型并没有把时间步作为一个超参数,也就是时间步随输入样本而变化,在训练集中,n_step均为2,
但是,在测试集中,三个单词都是分别作为样本集输入的,也就是时间步分别为2,2,2,3,1
最后在self.rnn(X, hidden)中,模型会自动根据X的序列长度,分配时间步
但由于是一次性输入一个样本集,所以样本集中各个样本长度必须一致,否则报错
因此必须把预测的sentences中各个句子分别放进容量为1的样本集单独输入
需要指出的是,由于模型训练的是根据2个单词找到最后以1个单词,训练的是2个时间步之间的权重,
所以如果长度不匹配,即使单词在训练集中,也不能取得好的结果,比如"you"的预测结果不是训练集中的"love"
'''
NLP之TextRNN(预测下一个单词)的更多相关文章
- NLP之Bi-LSTM(在长句中预测下一个单词)
Bi-LSTM @ 目录 Bi-LSTM 1.理论 1.1 基本模型 1.2 Bi-LSTM的特点 2.实验 2.1 实验步骤 2.2 实验模型 1.理论 1.1 基本模型 Bi-LSTM模型分为2个 ...
- cs224d 作业 problem set2 (三) 用RNNLM模型实现Language Model,来预测下一个单词的出现
今天将的还是cs224d 的problem set2 的第三部分习题, 原来国外大学的系统难度真的如此之大,相比之下还是默默地再天朝继续搬砖吧 下面讲述一下RNN语言建模的数学公式: 给出一串连续 ...
- NLP之TextLSTM(预测单词下一个字母)
LSTM 目录 LSTM 1.理论 1.1 LSTM与RNN 1.1.1 RNN的缺点 1.1.2 LSTM 1.2 LSTM基本结构 2.实验 2.1 实验步骤 2.2 算法模型 1.理论 1.1 ...
- Js判断一个单词是否有重复字母
今天上午刷到一道题,大体是写一个方法判断一个单词中是否有重复的字母(或者说一个字符串中是否有重复的字符).我的思路是一个字符一个字符地遍历,如果发现有重复的停止: function isIsogram ...
- 引爆公式让你的APP游戏成为下一个“爆款”
在2014年的移动互联网领域,“魔漫相机”是一款值得关注的产品.虽然没有腾讯.百度或阿里巴巴等大资源的支持,但是这款应用一上线就在中国市场发展迅猛,日下载量超过80万次,最高一日达300万次.类似的成 ...
- ODPS 下一个map / reduce 准备
阿里接到一个电话说练习和比赛智能二选一, 真的很伤心, 练习之前积极老龄化的权利. 要总结ODPS下一个 写map / reduce 并进行购买预测过程. 首先这里的hadoop输入输出都是表的形式, ...
- C++ Primer 学习笔记_41_STL实践与分析(15)--先来看看算法【下一个】
STL实践与分析 --初窥算法[下] 一.写容器元素的算法 一些算法写入元素值.在使用这些算法写元素时一定要当心.必须.写入输入序列的元素 写入到输入序列的算法本质上是安全的--仅仅会写入与指定输入范 ...
- leetcode-58.最后一个单词的长度
leetcode-58.最后一个单词的长度 题意 给定一个仅包含大小写字母和空格 ' ' 的字符串,返回其最后一个单词的长度. 如果不存在最后一个单词,请返回 0 . 说明:一个单词是指由字母组成,但 ...
- 把握这两点,抢占下一个电商风口|2016最新中国电商App排名&研究报告
序言 电商,是随着中国互联网经济的持续发展所成长起来的.淘宝.京东这些电商从交易额和影响力上看都位列中国最为成功.最具话题性的互联网企业之中.尽管近几年中国经济有所放缓,但中国消费市场的增长速度仍有望 ...
随机推荐
- 开发了一个安卓小软件“CSV联系人导入导出工具”,欢迎测试
开发了一个安卓小软件"CSV联系人导入导出工具",欢迎测试.本软件可以帮你快速备份和恢复联系人,不用担心号码遗失,软件操作简单,使用方便. 下载地址: 百度网盘:https://p ...
- Apache DolphinScheduler使用规范与使用技巧分享
本次分享来源2021年9月4日杨佳豪同学,给大家带来的分享是基于 Apache DolphinScheduler 使用规范与使用技巧分享,分享的内容主要为以下五点: " DolphinSch ...
- 部署前后端为独立的 Docker 节点
在『服务器部署 Vue 和 Django 项目的全记录』一文中,介绍了在服务器中使用 Nginx 部署前后端项目的过程.然而,当 Web 应用流量增多时,需要考虑负载均衡.流量分发.容灾等情况,原生的 ...
- es5 es6 新增
es5的新特性 对于数组和字符串都进行了加强 map 遍历 es6的新特性 数组的增强 find 查找findIndex 查找下标 字符的增强 includes 是否包含 (包含返回true 不包含返 ...
- kubernetes网络排错思想
Overview 本文将引入一个思路:"在Kubernetes集群发生网络异常时如何排查".文章将引入Kubernetes 集群中网络排查的思路,包含网络异常模型,常用工具,并且提 ...
- Spring mvc源码分析系列--前言
Spring mvc源码分析系列--前言 前言 距离上次写文章已经过去接近两个月了,Spring mvc系列其实一直都想写,但是却不知道如何下笔,原因有如下几点: 现在项目开发前后端分离的趋势不可阻挡 ...
- Taurus.MVC 微服务框架 入门开发教程:项目部署:4、微服务应用程序发布到Docker部署(上)。
系列目录: 本系列分为项目集成.项目部署.架构演进三个方向,后续会根据情况调整文章目录. 开源地址:https://github.com/cyq1162/Taurus.MVC 本系列第一篇:Tauru ...
- 7个自定义定时任务并发送消息至邮箱或企业微信案例(crontab和at)
前言 更好熟悉掌握at.crontab定时自定义任务用法. 实验at.crontab定时自定义任务运用场景案例. 作业.笔记需要. 定时计划任务相关命令及配置文件简要说明 at 工具 由包 at 提供 ...
- [网鼎杯 2020 朱雀组]phpweb-1|反序列化
1.打开界面之后界面一直在刷新,检查源代码也未发现提示信息,但是在检查中发现了两个隐藏的属性:func和p,抓包进行查看一下,结果如下: 2.对两个参数与返回值进行分析,我们使用dat时一般是这种格式 ...
- EL&JSTL笔记------jsp
今日内容 1. JSP: 1. 指令 2. 注释 3. 内置对象 2. MVC开发模式 3. EL表达式 4. JSTL标签 5. 三层架构 JSP: 1. 指令 * 作用:用于配置JSP页面,导入资 ...