Python Json分别存入Mysql、MongoDB数据库,使用Xlwings库转成Excel表格
前情提要:将 [第5天] Python 爬虫基础 - 小能日记 (cnblogs.com) 的电影数据 data.json 数据通过xlwings库转换成excel表格,存入mysql,mongodb数据库中。
数据下载:2020_3/data.json
xlwings文档: xlwings中文文档
MongoDB资料:2020_3/MongoDB 实战.pdf
总共用时:2小时 (代码在最后面)
学习内容:python基础语法、xlwings库、mysql库、pymongo库、mongoDB数据库复习
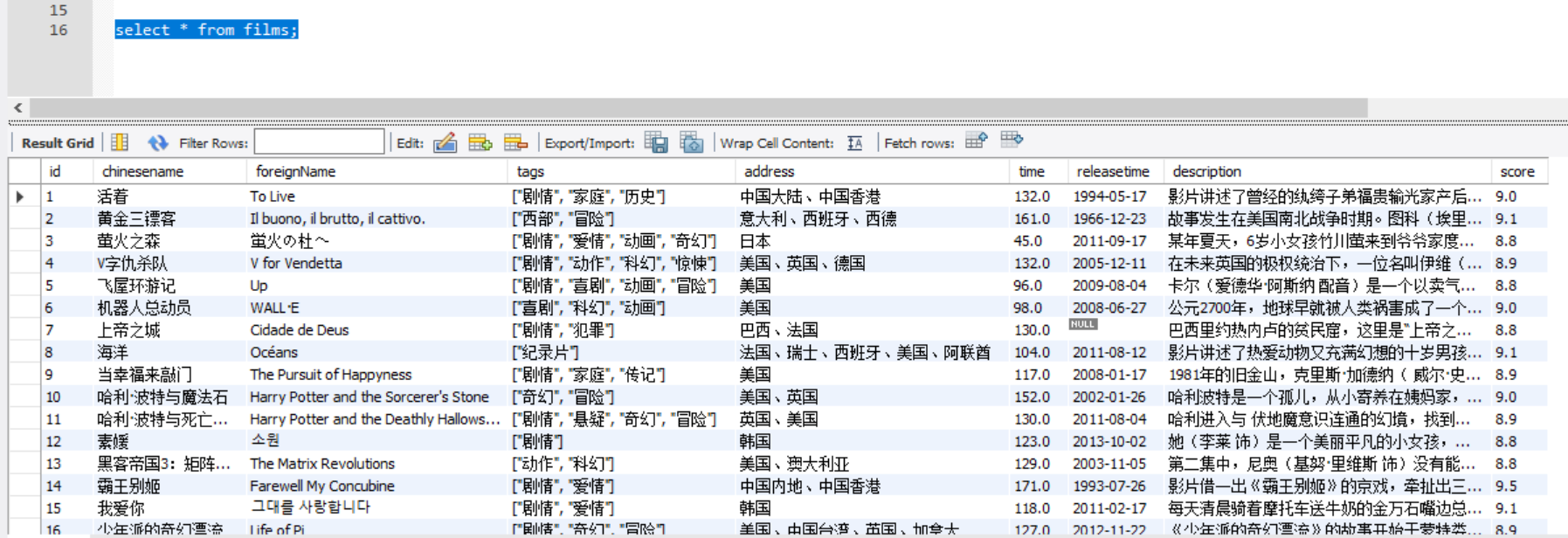
Excel表格

MYSQL
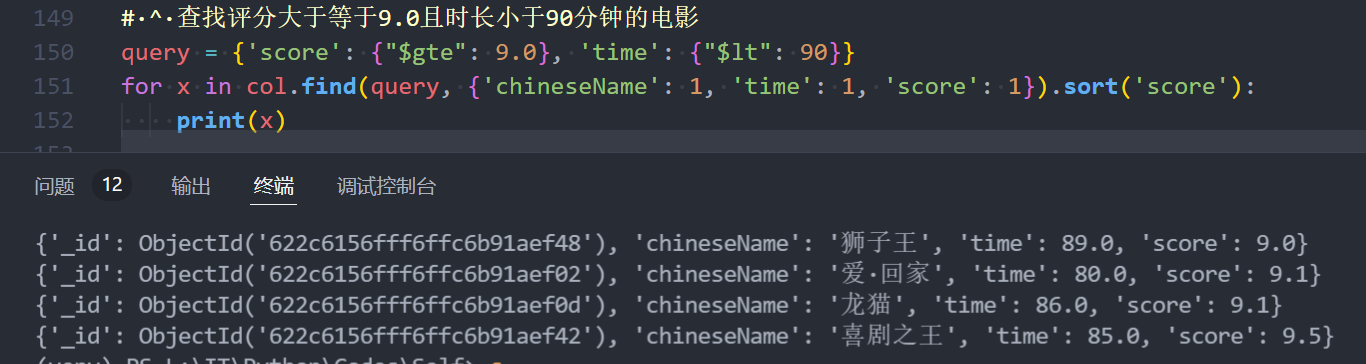
MongoDB
踩过的坑
1、‘gbk’ codec can’t decode byte 0xae
open(path+'/5_json/data.json',encoding = "utf-8")2、python 打开文件,保存文件时相对路径报错
import os
# ^ 获取当前py脚本文件夹路径
path = os.path.dirname(__file__)
# path + '/test.txt' 合并为绝对路径3、python中with...as的用法
晚点更
4、python中list与string的转换
(6条消息) python中list与string的转换_bufengzj的博客-CSDN博客_python str转list
晚点更
5、python mysql插入null数据
None if i['release'] == "" else i['release'],将想要存储为Null的值填为None
6、python 集合里不能放列表,可以放元组
我的代码
# pip install xlwings -i https://pypi.tuna.tsinghua.edu.cn/simple
# pip install pymongo -i https://pypi.tuna.tsinghua.edu.cn/simple
# pip install mysql-connector -i https://pypi.tuna.tsinghua.edu.cn/simple
import json
import xlwings as xw
import os
import mysql.connector
import pymongo
import sys
import requests
# ^ 获取当前py脚本文件夹路径
path = os.path.dirname(__file__)
# ^ 阿里云OSS读取数据集文件
content = requests.get("https://xiaonenglife.oss-cn-hangzhou.aliyuncs.com/static/cnblogs/2020_3/films_data.json")
if content.status_code != 200:
print("文件加载不成功")
sys.exit() # ^ 退出程序
f = open(path+'/data.json', 'w', encoding="utf-8")
f.write(content.text)
f.close()
# ^ 加载json文件
# WARN 'gbk' codec can't decode byte 0xae in position
file = open(path+'/data.json', 'r', encoding="utf-8")
# ^ json转换为字典数组
films = json.loads(file.read())
print(file)
filmArr = []
for i in films:
filmArr.append([ # ^ 不用 list() 因为给定了八个参数,list只要一个
i['chineseName'],
i['foreignName'],
'、'.join(list(str(s) for s in i['tags'])),
i['address'],
i['time'],
i['release'],
i['desc'],
i['score']
])
# ^ excel
wb = xw.Book()
sht = wb.sheets['sheet1']
sht.range('A1').value = ['中文名', '外语名', '类别', '出版地', '时长', '发行日期', '介绍', '评分']
sht.range('A2').value = filmArr
wb.save(path+'/优秀电影.xlsx')
# ^ mysql
sqlDB = mysql.connector.connect(
host="localhost",
user="root",
passwd="sql2008",
auth_plugin='mysql_native_password' # ^ 验证方式必须要有
)
mycursor = sqlDB.cursor()
mycursor.execute("drop DATABASE if exists test")
mycursor.execute("CREATE DATABASE test")
sqlDB = mysql.connector.connect(
host="localhost",
user="root",
passwd="sql2008",
database="test",
auth_plugin='mysql_native_password'
)
mycursor = sqlDB.cursor()
mycursor.execute("drop table if exists films")
mycursor.execute("""
CREATE TABLE films(
id INT AUTO_INCREMENT PRIMARY KEY,
chinesename VARCHAR(255),
foreignName VARCHAR(255),
tags json,
address VARCHAR(255),
time decimal(5,1),
releasetime date,
description mediumtext,
score decimal(3,1)
)
""")
sql = "INSERT INTO films (chinesename, foreignName,tags,address,time,releasetime,description,score) VALUES (%s, %s,%s,%s,%s,%s,%s,%s)"
filmArr = [] # ^ 里面放元组
for i in films:
filmArr.append((
i['chineseName'],
i['foreignName'],
json.dumps(i['tags']),
i['address'],
i['time'],
None if i['release'] == "" else i['release'],
i['desc'],
i['score']
))
mycursor.executemany(sql, filmArr) # ^ 执行多条
sqlDB.commit() # ^ 修改数据库的时候必须加
print(mycursor.rowcount, "条数据被插入")
# ^ mongoDB
client = pymongo.MongoClient('mongodb://localhost:27017')
mongoDB = client['test'] # ^ 数据库
col = mongoDB['films'] # ^ 集合
col.drop() # ^ 删除集合
filmArr = []
for i in films:
filmArr.append(dict(
chineseName=i['chineseName'],
foreignName=i['foreignName'],
tags=i['tags'],
address=i['address'],
time=float(i['time']),
release=i['release'],
desc=i['desc'],
score=float(i['score'])
))
x = col.insert_many(filmArr)
# print(x.inserted_ids)
x = col.find_one()
print(x)
for x in col.find({}, {'chineseName': 1, 'time': 1, 'score': 1}).sort('score'):
print(x)
print('----------------------')
for x in col.find({}, {'chineseName': 1, 'time': 1, 'score': 1}).limit(5).sort('score', -1):
print(x)
print('----------------------')
# ^ 查找评分大于等于9.0且时长小于90分钟的电影
query = {'score': {"$gte": 9.0}, 'time': {"$lt": 90}}
for x in col.find(query, {'chineseName': 1, 'time': 1, 'score': 1}).sort('score'):
print(x)
点赞是一种积极的生活态度,喵喵喵!(疯狂暗示)
Python Json分别存入Mysql、MongoDB数据库,使用Xlwings库转成Excel表格的更多相关文章
- JSON文件存入MySQL数据库
目标:将不同格式的JSON文件存入MySQL数据库 涉及的点有: 1. java处理JSON对象,直接见源码. 2. java.sql.SQLException: Incorrect string v ...
- 一款软件同时管理MySQL,MongoDB数据库
互联网应用开发日新月异,去年分布式应用都还大量使用springmvc+ zookeeper +dubbo,今年就被spring boot ,spring cloud微服务架构替换了,技术的更新换代太快 ...
- 孤荷凌寒自学python第五十八天成功使用python来连接上远端MongoDb数据库
孤荷凌寒自学python第五十八天成功使用python来连接上远端MongoDb数据库 (完整学习过程屏幕记录视频地址在文末) 今天是学习mongoDB数据库的第四天.今天的感觉是,mongoDB数据 ...
- 如何将存储在MongoDB数据库中的数据导出到Excel中?
将MongoDB数据库中的数据导出到Excel中,只需以下几个步骤: (1)首先,打开MongoDB安装目录下的bin文件夹,(C:\Program Files (x86)\MongoDB\Serve ...
- 办公室文员必备python神器,将PDF文件表格转换成excel表格!
[阅读全文] 第三方库说明 # PDF读取第三方库 import pdfplumber # DataFrame 数据结果处理 import pandas as pd 初始化DataFrame数据对象 ...
- Python自动化办公:将文本文档内容批量分类导入Excel表格
序言 (https://jq.qq.com/?_wv=1027&k=GmeRhIX0) 它来了,它又来了. 本文实现用Python将文本文件自动保存到Excel表格里面去. 需求 将锦江区.t ...
- 【python 2.7】python读取json数据存入MySQL
同上一篇,只是适配 CentOS+ python 2.7 #python 2.7 # -*- coding:utf-8 -*- __author__ = 'BH8ANK' import json im ...
- 【python 3.6】python读取json数据存入MySQL(二)
在网上找到一个包含全国各省市经纬度的json文件,也可以通过上次的办法,解析json关键字,构造SQL语句,插入数据库. JSON文件格式如下: [ { "name": " ...
- 【python 3.6】python读取json数据存入MySQL(一)
整体思路: 1,读取json文件 2,将数据格式化为dict,取出key,创建数据库表头 3,取出dict的value,组装成sql语句,循环执行 4,执行SQL语句 #python 3.6 # -* ...
随机推荐
- 嵌入式无操作系统下管理内存和队列(类UCOS II思想)
例子:存储日志,最多存128条,每条最大1MB. 内存方面 因为嵌入式不适合用动态内存,会产生碎片.这里我们用 u8 data[LOG_SIZE];开辟固定128MB的内存区,再对其分为128个1MB ...
- OpenCV开发笔记(七十四):OpenCV3.4.1+ffmpeg3.4.8交叉编译移植到海思平台Hi35xx平台
前言 移植opencv到海思平台,opencv支持对视频进行解码,需要对应的ffmpeg支持. Ffmpeg的移植 Ffmpeg的移植请参考之前的文章:<FFmpeg开发笔记(十): ...
- C# 将CSV转为Excel
CSV(Comma Separated Values)文件是一种纯文本文件,包含用逗号分隔的数据,常用于将数据从一个应用程序导入或导出到另一个应用程序.通过将CSV文件转为EXCEL,可执行更多关于数 ...
- Clickhouse上用Order By保证绝对正确结果但代价是性能
一些聚合函数的结果跟流入数据的顺序有关,CH文档明确说明这样的函数的结果是不确定的.这是为什么呢?让我们用explain pipeline来一探究竟. 以一个很简单的查询为例: select any( ...
- UVA1389 Hard Life (01分数规划+最大流)
UVA1389 Hard Life (01分数规划+最大流) Luogu 题目描述略 题解时间 $ (\frac{\Sigma EdgeCount}{\Sigma PointCount})_{max} ...
- python编程笔记--字符编码
ASCII码.Unicode.utf-8 ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电 ...
- String -- char[]互转
1.String --> char[] String str = "abc"; char[] chs = str.toCharArray(); 2.char[] --> ...
- python django对数据表的增删改查操作
新增操作:方式1:book = BookInfo(title='西游记',price=99)book.save() 方式2:BookInfo.objects.create(title='西游记',pr ...
- Spring对DAO的支持?
Spring对数据访问对象(DAO)的支持旨在简化它和数据访问技术如JDBC,Hibernate or JDO 结合使用.这使我们可以方便切换持久层.编码时也不用担心会捕获每种技术特有的异常.
- springMVC和struts2的区别有哪些?
(1)springmvc的入口是一个servlet即前端控制器(DispatchServlet),而struts2入口是一个filter过虑器(StrutsPrepareAndExecuteFilte ...