Py2neo:一种快速导入百万数据到Neo4j的方式
Py2neo:一种快速导入百万数据到Neo4j的方式
Py2neo是一个可以和Neo4j图数据库进行交互的python包。虽然py2neo操作简单方便,但是当节点和关系达几十上百万时,直接创建和导入节点、关系的方式会越来越耗时。本文提供一个py2neo小技巧,通过简单的代码,能够以每秒1万节点/关系的速度快速将数据导入Neo4j。
本文目录
1、Neo4j与Py2neo
对于已构建知识图谱,通过可视化技术能够清晰、直观的呈现实体与实体之间的关系。Neo4j图数据库作为高性能和轻量级的知识存储与可视化工具,在实践中的应用越来越广泛。
Py2neo为python代码操作Neo4j提供了便利,简单好用,具体可访问其操作手册。
Neo4j官网
Py2neo手册
2、Py2neo常规导入节点/关系到Neo4j的方法
Py2neo导入知识图谱到Neo4j的一般方式是,利用Node和Relationship分别实例化节点和关系,然后利用Graph的create()方法创建相应的节点和关系,具体示例如下:
from py2neo import Graph, Node, Relationship
if __name__ == '__main__':
# 连接neo4j
graph = Graph("http://localhost:7474", auth=("neo4j", "123456"))
# 创建两个节点
node_1 = Node("py2neo", name="py2neo")
graph.create(node_1)
node_2 = Node("neo4j", name="neo4j")
graph.create(node_2)
# 创建两个节点之间的关系
relation = Relationship(node_1, "Subgraph()导入节点/关系就是快", node_2)
graph.create(relation)
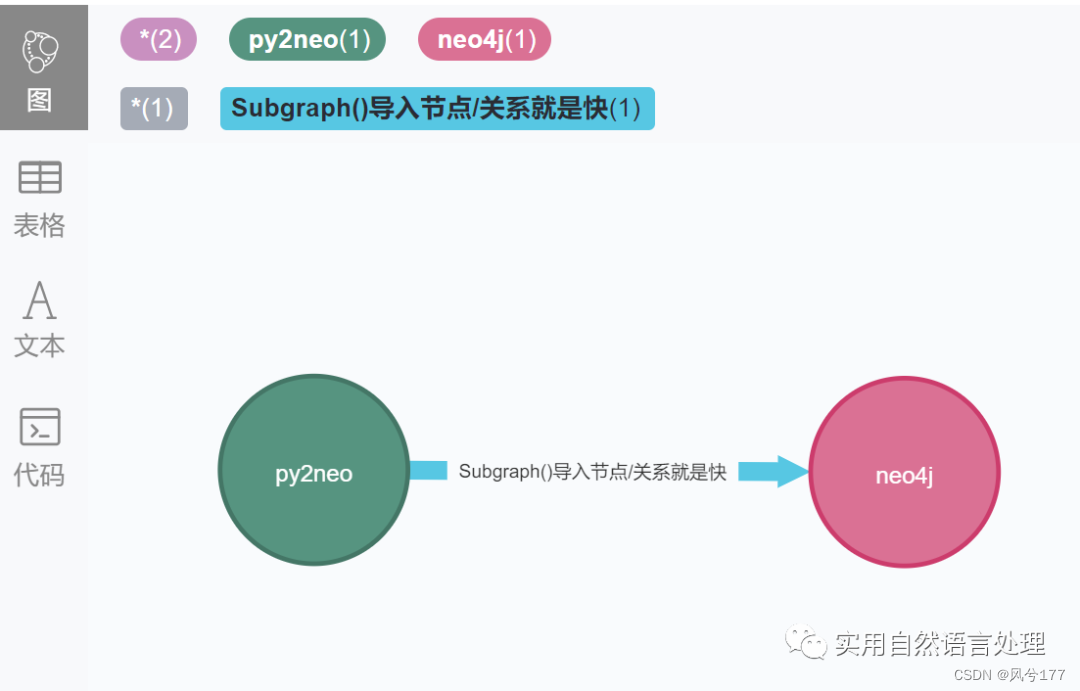
3、Py2neo快速导入节点/关系到Neo4j的方法
第2节中的方法对于少量数据速度尚可,但是不适合大数据量的情形。为此,可利用py2neo的Subgraph类构造子图,并在Transaction中批量创建节点和关系。此处详细文档可参考:详细文档
Py2neo批量创建节点/关系示例如下:
from py2neo import Graph, Subgraph, Node, Relationship
def batch_create(graph, nodes_list, relations_list):
"""
批量创建节点/关系,nodes_list和relations_list不同时为空即可
特别的:当利用关系创建节点时,可使得nodes_list=[]
:param graph: Graph()
:param nodes_list: Node()集合
:param relations_list: Relationship集合
:return:
"""
subgraph = Subgraph(nodes_list, relations_list)
tx_ = graph.begin()
tx_.create(subgraph)
graph.commit(tx_)
if __name__ == '__main__':
# 连接neo4j
graph = Graph("http://localhost:7474", auth=("neo4j", "123456"))
# 批量创建节点
nodes_list = [] # 一批节点数据
relations_list = [] # 一批关系数据
# 如:实例化一个节点
node_1 = Node("中药名", name="白术")
nodes_list.append(node_1)
node_2 = Node("功能", name="健脾")
nodes_list.append(node_2)
# 创建两个节点之间的关系
relation = Relationship(node_1, "功能", node_2)
relations_list.append(relation)
node_3 = Node("功能", name="益气")
nodes_list.append(node_3)
relation2 = Relationship(node_1, "功能", node_3)
relations_list.append(relation2)
# 批量创建节点/关系
batch_create(graph, nodes_list, relations_list)
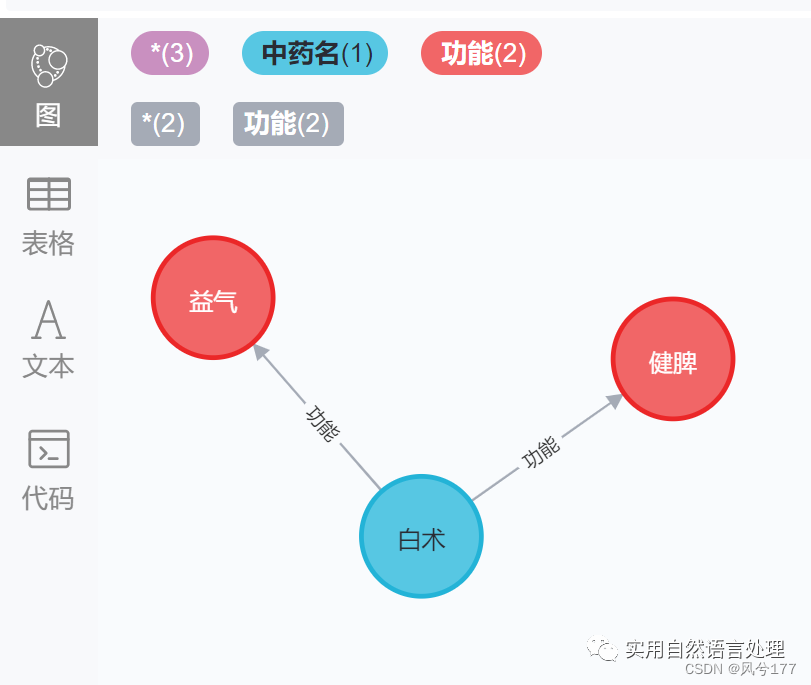
(哈哈哈:图与功能不匹)
该方法能够以每秒至少1万节点/关系的速度快速将数据导入Neo4j(其实可以更快速)。
4、Neo4j快速清库大量数据的方法
match (n) detach delete n
对于少量数据,在neo4j中可以利用上面一行命令删除,但是当节点和关系非常多的时候,该方法很耗时。经过实验,提供如下方法:即:在neo4j安装目录中分别找到data和transactions目录,然后在两个目录中分别删掉需要删除数据库名字的文件夹即可(特别的:删库需谨慎)。
总结
本文记录了一个py2neo快速导入知识图谱到neo4j的方法。

欢迎关注公众号:实用自然语言处理
原文首发于微信公众号:实用自然语言处理
Py2neo:一种快速导入百万数据到Neo4j的方式的更多相关文章
- MySQL 快速导入大量数据 资料收集
一.LOAD DATA INFILE http://dev.mysql.com/doc/refman/5.5/en/load-data.html 二. 当数据量较大时,如上百万甚至上千万记录时,向My ...
- Mysql使用存储过程快速添加百万数据
前言 为了体现不加索引和添加索引的区别,需要使用百万级的数据,但是百万数据的表,如果使用一条条添加,特别繁琐又麻烦,这里使用存储过程快速添加数据,用时大概4个小时. 创建一个用户表 CREATE TA ...
- [Java] 高效快速导入EXCEL数据
需求1.高效率的以excel表格的方式导入多条数据.2.以身份证号为唯一标识,如果身份证号已存在,则该条数据不导入. 分析刚开始的时候是传统的做法,解析excel数据,获取单个对象,判断身份证是否已存 ...
- Oracle中用exp/imp命令快速导入导出数据
from: http://blog.csdn.net/wangchunyu11155/article/details/53635602 [用 exp 数 据 导 出]: 1 将数据库TEST完全导出, ...
- mysql快速导入大量数据问题
今天需要把将近存有一千万条记录的*.sql导入到mysql中.使用navicate导入,在导入100万条之后速度就明显变慢了, 导入五百万条数据的时候用了14个小时,且后面的数据导入的越来越慢. 后来 ...
- 使用MySQL Migration Toolkit快速导入Oracle数据
近来笔者有项目需要将原有的Oracle数据库中的数据导入到MySQL中,经过试用发现MySQL GUI Tools中的MySQL Migration Toolkit可以非常方便快捷的将Oracle数据 ...
- mysql快速导入导出数据
--导入 select * from inhos_genoperation(表名) where UPLOAD_ORG_CODE='***' into outfile '/tmp/inhos_genop ...
- 快速导入Excel数据到mysql
首先利用mysql文件,导出csv文件, 然后,直接修改csv文件,然后导入csv文件
- python-几种快速了解函数及模块功能的方式
背景 在进行编程的时候经常要导入各种包的各种函数,但是很多包一下又不知道为什么要导入这个模块,所以想总结下有哪些方法可以让我们快速熟悉其中函数的作用. import numpy as np impor ...
- Oracle快速导入数据工具
sqlldr是oracle自带的快速导入批量数据的工具,常用于性能测试.考虑手工构造控制文件较为繁琐,因此使用脚本完成批量数据的自动导入. 基本知识 sqlldr命令语法 sqlldr dbname/ ...
随机推荐
- CentOS使用yum方式安装yarn和nodejs
# 使用epel-release.repo源安装的nodejs版本是6.17.1,有些前端项目使用的话会提示版本太低,具体下图 # 命令执行后的详细情况:curl -sL https://rpm.no ...
- Portainer 安装MySQL并开启远程访问
进入到 Portainer 页面,选择左边的 Containers 选项,单击上方的 Add container 按钮转到如图所示的页面: 1.在 Name 一栏中输入容器名字: 2.在 Image ...
- 使用Docker Compose部署SpringCloud项目docker-compose.yml文件示例
注意各组件之间的依赖关系 microservice-discovery-eureka: image: reg.itmuch.com/microservice-discovery-eureka port ...
- 改变一个数组内元素的位置,不通过splice方法。
这个数据 现在已经完成了,将本来在第一位的18代金券改到第31位,下面说一下怎么实现的. //currHotRightsTypeSorted这个是数据源头,legalRightsType这个是数据的分 ...
- 20_IO
IO框架 一. 流的概念 概念:内存与存储设备之间传输数据的通道 水借助管道传输:数据借助流传输 二. 流的分类 按方向[重点] 输入流:将<存储设备>中的内容读入到<内存>中 ...
- 使Squashfs可写的办法
yiyi@yiyi-HP-Pavilion-Notebook:~/Applications/Office2016$ pwd /home/yiyi/Applications/Office2016 yiy ...
- MyBatis之ResultMap的association和collection标签详解
一.前言 MyBatis 创建时的一个思想是:数据库不可能永远是你所想或所需的那个样子. 我们希望每个数据库都具备良好的第三范式或 BCNF 范式,可惜它们并不都是那样. 如果能有一种数据库映射模式, ...
- 云原生时代的DevOps平台设计之道
开发人员与运维人员是 IT 领域很重要的两大人群,他们都会参与到各种业务系统的建设过程中去.DevOps 是近年间火爆起来的一种新理念,这种理念被很多人错误的解读为"由开发人员(Dev)学习 ...
- RAID5 IO处理之写请求代码详解
我们知道RAID5一个条带上的数据是由N个数据块和1个校验块组成,其校验块由N个数据块通过异或运算得出,这样才能在任意一个成员磁盘失效时通过其他N个成员磁盘恢复出用户写入的数据.这也就要求RAID5条 ...
- Codeforces Round #826 (Div. 3) A-E
比赛链接 A 题解 知识点:模拟. 时间复杂度 \(O(n)\) 空间复杂度 \(O(n)\) 代码 #include <bits/stdc++.h> #define ll long lo ...