【SQL进阶】Day05:窗口函数
〇、概述
一、专用窗口函数
1、每类试卷得分前3名
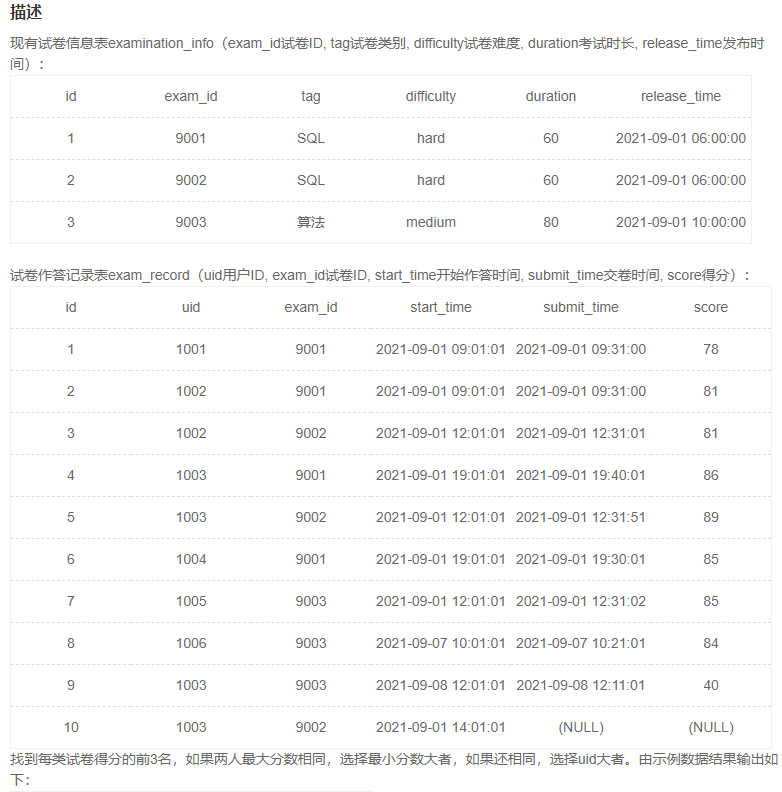

自己写出来的部分
SELECT
tag AS tid,
uid AS uid,
Rank AS ranking -- 如何确定排名
FROM examination_info ei
JOIN exam_record er
USING(exam_id)
GROUP BY tid
ORDER BY MIN(score) DESC,uid ASC
答案:
select u.tag tid,u.uid,u.ranking FROM
(SELECT *,
row_number() over (partition by t.tag order by t.max_score desc,t.min_score desc,t.uid desc) ranking
FROM
(SELECT i.tag,r.uid,max(r.score) max_score,min(r.score) min_score
from examination_info i
join exam_record r
on i.exam_id=r.exam_id
where r.score is not null
group by i.tag,r.uid
) t
) u
WHERE u.ranking<=3
或
SELECT tag,uid,ranking
FROM(
SELECT
tag,
uid,
row_number() OVER (PARTITION BY tag
ORDER BY tag, MAX(score) DESC, MIN(score) DESC, uid DESC)
AS ranking
FROM exam_record
JOIN examination_info USING(exam_id)
GROUP BY tag,uid
) new_examrecord
WHERE ranking < 4
学到:ROW_NUMBER() OVER( PATITION BY A ORDER BYB)
2、第二快/慢用时之差大于试卷时长一半的试卷
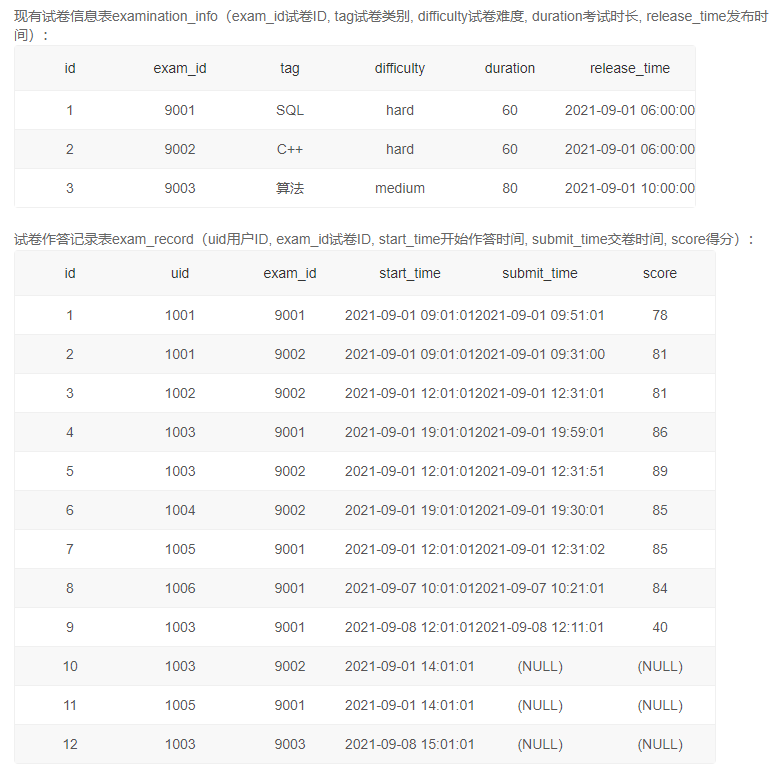

自己的想法
-- 查到快慢试卷
SELECT
er.exam_id,
-- ROW_NUMBER() OVER(PARTITION BY exam_id ORDER BY exam_id DESC)
-- 查询最大最小值
NTH_VALUE(time_took, 2) OVER (PARTITION BY exam_id ORDER BY time_took DESC) as max2_time_took,
FROM exam_record er
JOIN examination_info ei
USING(exam_id) -- 从上表中查询第二快和第二慢的试卷时间之差 -- 从上表中选出时间之差小于dur/2的试卷id
答案:
选择出所有的时间(秒/60)
选择出满足条件的时间
选择出最终结果并排序
-- 步骤:先拼接,后选条件,最后选结果,每一步都要得到相应的数据
-- 最后选出符合条件的数据
-- 存在重复的现象
SELECT
exam_id,
duration,
release_time
FROM (
-- 再选出第二快和第二慢的试卷信息
SELECT
DISTINCT exam_id,
duration,
release_time,
NTH_VALUE(use_time,2) OVER(PARTITION BY exam_id ORDER BY use_time ASC) AS min_use_time,
NTH_VALUE(use_time,2) OVER(PARTITION BY exam_id ORDER BY use_time DESC) AS max_use_time
FROM (
-- 先两表join选出所有时间
SELECT
er.exam_id,
duration,
release_time,
TIMESTAMPDIFF(SECOND,start_time,submit_time)/60 AS use_time
FROM exam_record er
JOIN examination_info ei
USING(exam_id)
WHERE submit_time IS NOT NULL
) a
) b
WHERE
max_use_time IS NOT NULL
AND
min_use_time IS NOT NULL
AND
(max_use_time-min_use_time)>duration/2
ORDER BY exam_id DESC
3、连续两次作答试卷的最大时间窗
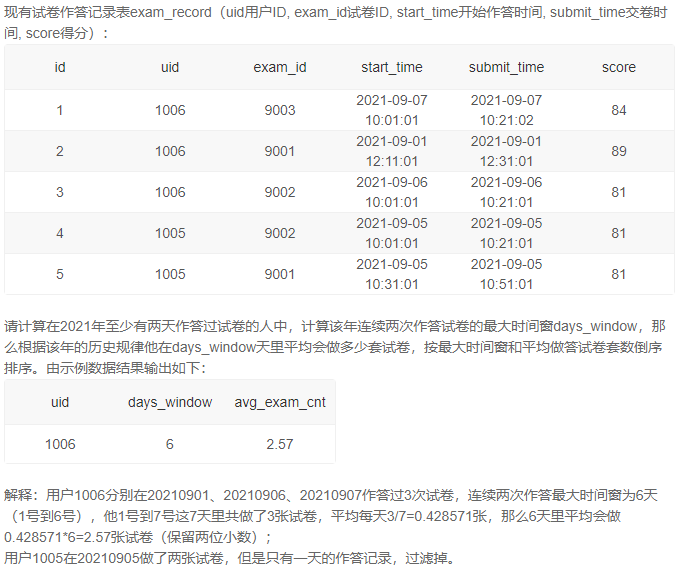
自己的想法
-- 在一张表中查询数据
-- 查询2021年至少有两天作答过试卷的人
-- 查询该年连续两次作答试卷的最大时间窗days_window
SELECT
uid,
days_window,
avg_exam_cnt
FROM ( )
做法1:【学习with a as(),b as ()】
-- 在一张表中查询数据 -- 查询该年连续两次作答试卷的最大时间窗days_window
with a as
( -- 查询2021年至少有两天作答过试卷的人
select uid
from exam_record
where year(submit_time) = 2021
group by 1
having count(distinct date(start_time)) >= 2
)
,b as
(
-- 取相关数据,具体到2021年的天(且至少两次作答)
select er.uid,er.exam_id,date(er.start_time) as day
from exam_record er
join a on er.uid = a.uid
where year(start_time) = 2021
)
,c as
(
-- 求窗口期
select uid,
datediff(day,lag(day,1) over(partition by uid order by day asc))+1 as days_window
from (select uid,day from b group by 1,2) t
)
,d as
(
-- 求平均
select uid,count(*)/(datediff(max(day),min(day))+1) as avg_exam
from b
group by 1
) -- 结果 注意:前面都要用start_time作为做题日期,而不是submit_time,否则会报错
select c.uid,max(c.days_window),round(max(c.days_window)*d.avg_exam,2) as avg_exam_cnt
from c join d on c.uid=d.uid
group by 1
order by 2 desc,3 desc
方案2:
SELECT uid, days_window, round(days_window*exam_cnt/diff_days, 2) as avg_exam_cnt
FROM (
-- 2.查询出days_window两次作答的最大时间窗以及相差的最大天数
SELECT uid,
count(start_time) as exam_cnt, -- 此人作答的总试卷数
DATEDIFF(max(start_time), min(start_time))+1 as diff_days, -- 最早一次作答和最晚一次作答的相差天数
max(DATEDIFF(next_start_time, start_time))+1 as days_window -- 两次作答的最大时间窗
FROM (
-- 1.通过LEAD查询出下一次作答的时间,并得到新的属性【窗口函数、uid分区】
SELECT uid, exam_id, start_time,
lead(start_time) over(partition by uid ORDER BY start_time) as next_start_time -- LEAD函数可以将连续的下次作答时间拼上
FROM exam_record
WHERE year(start_time)=2021
) as t_exam_record_lead
GROUP BY uid
) as t_exam_record_stat
WHERE diff_days>1
ORDER BY days_window DESC, avg_exam_cnt DESC
自己写出来的
-- 3、查询出最终结果
SELECT
uid,
days_window,
ROUND(num*days_window/min_max,2) AS avg_exam_cnt
FROM (
-- 2.查询出days_window两次作答的最大时间窗以及相差的最大天数
SELECT
uid,
COUNT(start_time) AS num,
DATEDIFF(MAX(start_time),MIN(start_time))+1 AS min_max, -- 最早最晚的时间差7
MAX(DATEDIFF(next_start_time,start_time))+1 AS days_window -- 最大时间窗6【大,小】
FROM (
-- 1.通过LEAD查询出下一次作答的时间,并得到新的属性【窗口函数、uid分区】
SELECT
uid,
exam_id,
start_time,
LEAD(start_time) OVER(PARTITION BY uid ORDER BY start_time ASC) AS next_start_time
FROM exam_record er
WHERE YEAR(start_time)=2021
) a
GROUP BY uid
) b
WHERE days_window>1
ORDER BY days_window DESC,avg_exam_cnt DESC
4、近三个月未完成试卷数为0的用户完成情况
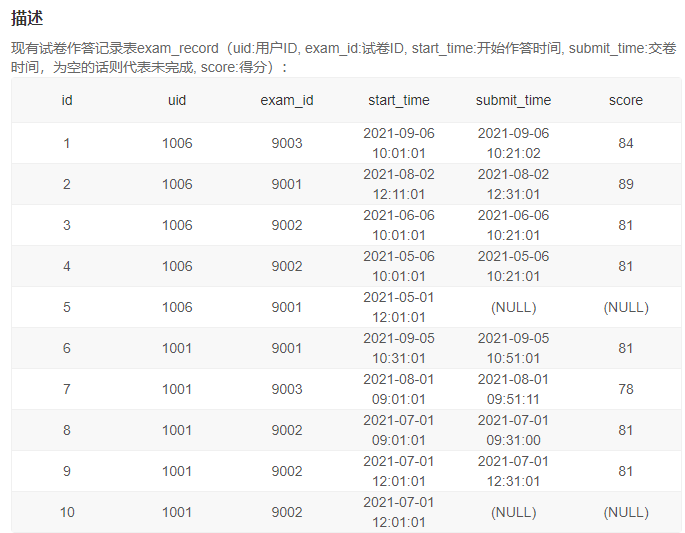

思路:
-- 找每个用户的试卷作答完成数
-- 找每个用户近三个有作答记录的月份,
-- 没有试卷是未完成状态的用户【所有试卷都完成count(a)=count(b)】
答案:dense_rank()进行排序
方式:先按日期排好序得到序号,再找前三个记录并查出来,再分组,找到全部完成的用户情况,通过聚合函数计算
-- 3.分组选出全部都完成的完成数
SELECT
uid,
COUNT(start_time) AS exam_complete_cnt
FROM (
-- 2.选出近三条
SELECT
uid,
start_time,
submit_time
FROM (
-- 1.查询用户排序的作答记录
SELECT
uid,
start_time,
submit_time,
DENSE_RANK() OVER(PARTITION BY uid ORDER BY DATE_FORMAT(start_time,'%Y-%m') DESC) AS ranking
FROM exam_record er
) a
where ranking<=3
) b
GROUP BY uid
HAVING COUNT(start_time)=COUNT(submit_time)
ORDER BY exam_complete_cnt DESC,uid DESC
5、未完成率较高的50%用户近三个月答卷情况
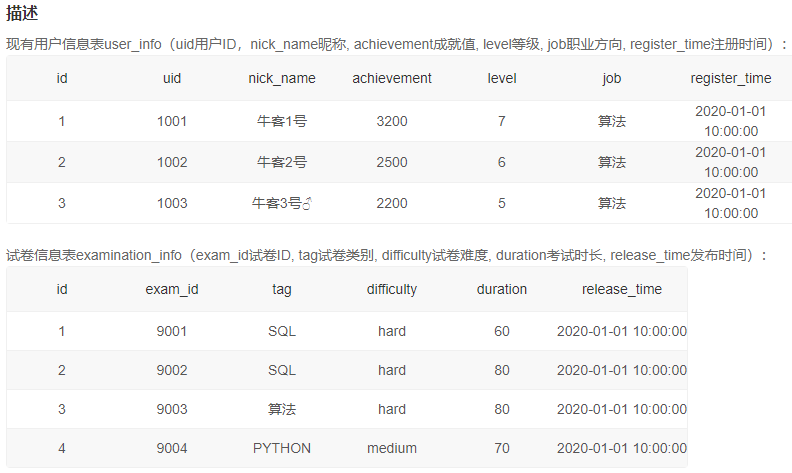
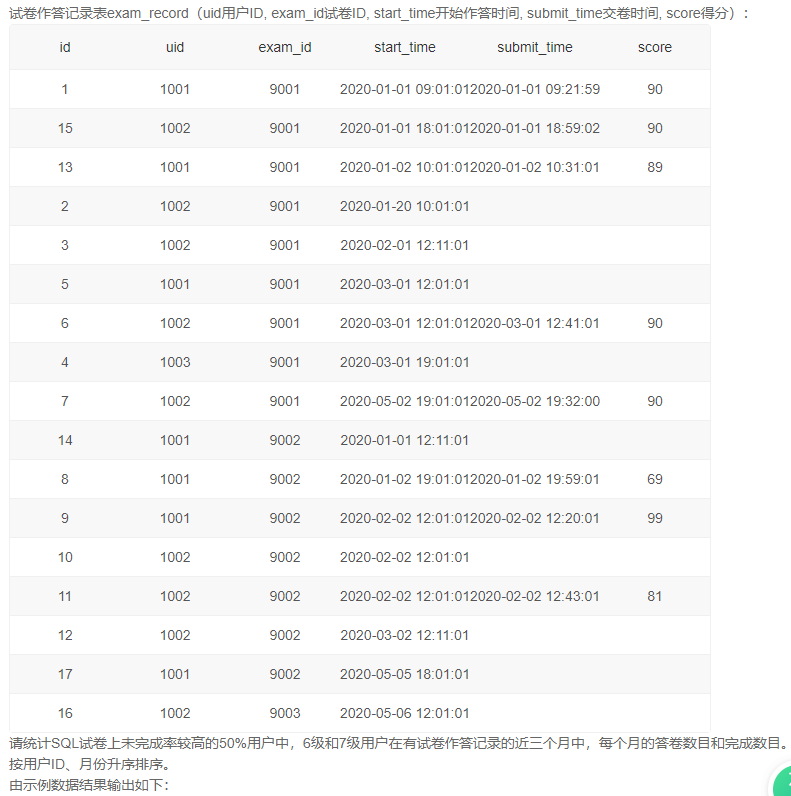
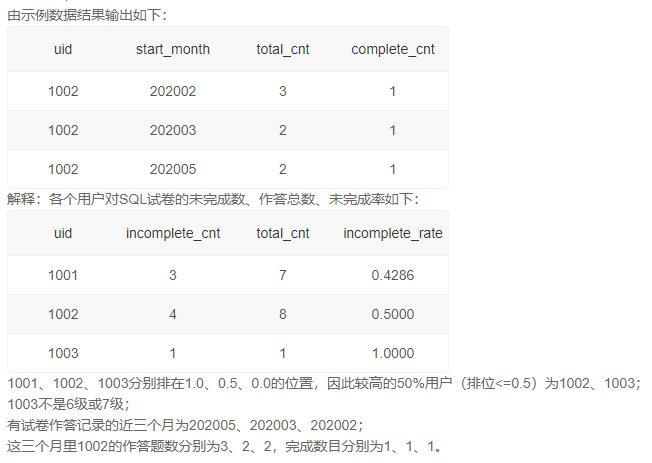
思路:
-- 0.分组统计每个用户的未完成数目和总作答数目group by
-- 1.统计SQL试卷的未完成率排名(前50%)
-- 2.统计有作答记录的近三个月信息【日期排序,近三个月】
-- 3.统计六级和七级用户和每个月的信息
答案:
select uid,
date_format(start_time, '%Y%m') as start_month,
count(start_time) as tatol_cnt,
count(score) as complete_cnt
from(
select uid, start_time, score,
dense_rank() over(partition by uid order by date_format(start_time, '%Y%m') desc) as recent_months
from exam_record
) recent_table
where recent_months <= 3
and uid in(
select incomplete_rate_table.uid
from(
select uid,
row_number() over(order by (incomplete_cnt / total_cnt) desc, uid desc) as incomplete_rank
from(
select uid,
sum(if(score is null, 1, 0)) as incomplete_cnt,
count(start_time) as total_cnt
from exam_record
group by uid
) incomplete_cnt_table
) incomplete_rate_table join(
select count(distinct uid) as total_user
from exam_record
) t_u
join user_info
on incomplete_rate_table.uid = user_info.uid
where level >= 6
and incomplete_rank <= ceiling(total_user / 2)
)
group by uid, start_month
order by uid
6、试卷完成数同比2020年的增长率及排名变化
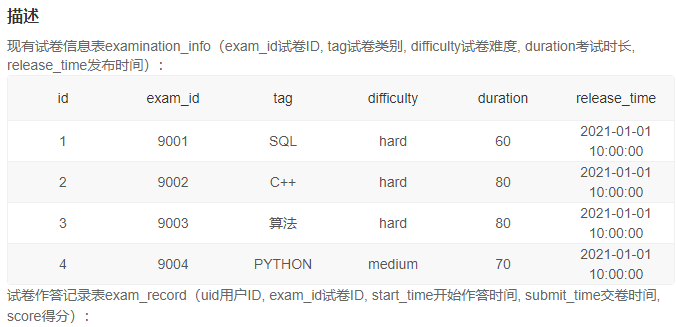
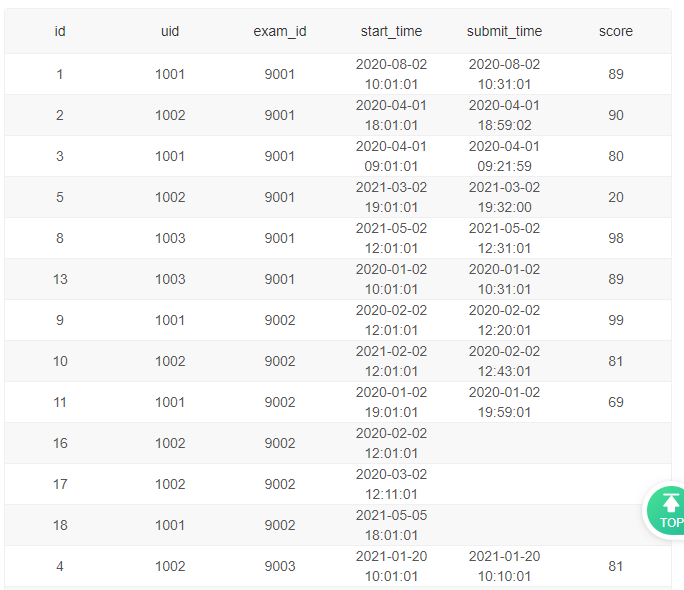
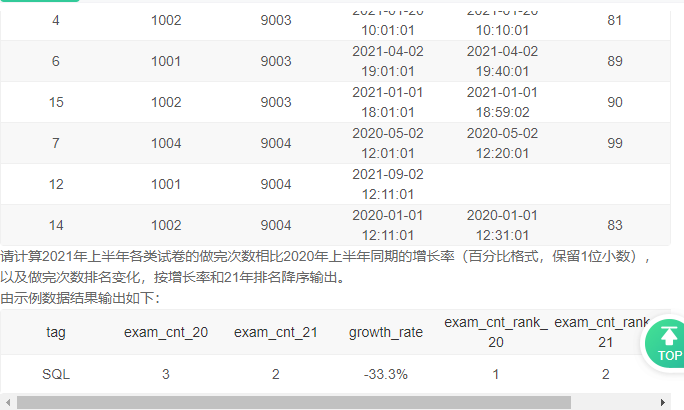
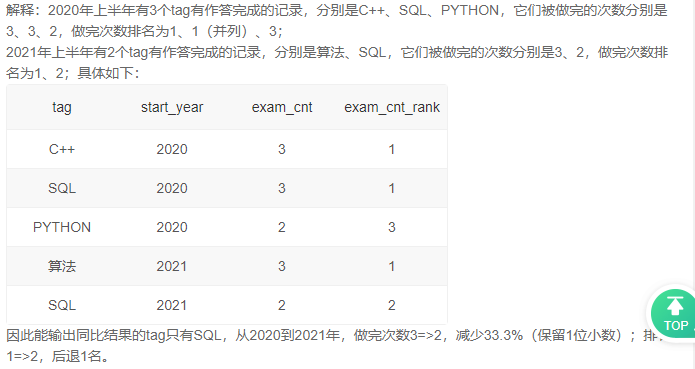
二、聚合窗口函数
【SQL进阶】Day05:窗口函数的更多相关文章
- 《SQL基础教程》+ 《SQL进阶教程》 学习笔记
写在前面:本文主要注重 SQL 的理论.主流覆盖的功能范围及其基本语法/用法.至于详细的 SQL 语法/用法,因为每家 DBMS 都有些许不同,我会在以后专门介绍某款DBMS(例如 PostgreSQ ...
- SQL优化之SQL 进阶技巧(上)
由于工作需要,最近做了很多 BI 取数的工作,需要用到一些比较高级的 SQL 技巧,总结了一下工作中用到的一些比较骚的进阶技巧,特此记录一下,以方便自己查阅,主要目录如下: SQL 的书写规范 SQL ...
- 详解SQL操作的窗口函数
摘要:窗口函数是聚集函数的延伸,是更高级的SQL语言操作,主要用于AP场景下对数据进行一些分析.汇总.排序的功能. 本文分享自华为云社区<GaussDB(DWS) SQL进阶之SQL操作之窗口函 ...
- pl/sql进阶--例外处理
在pl/sql的执行过程中发生异常时系统所作的处理称为一个例外情况(exception).通常例外情况的种类有三种: 1.预定义的oracle例外情况oracle预定义的例外情况大约有24个,对于这种 ...
- SQL进阶随笔--case用法(一)
SQL进阶一整个是根据我看了pdf版本的整理以及自己的见解整理.后期也方便我自己查看和复习. CASE 表达式 CASE 表达式是从 SQL-92 标准开始被引入的.可能因为它是相对较新的技术,所以尽 ...
- 【SQL进阶】03.执行计划之旅1 - 初探
听到大牛们说执行计划,总是很惶恐,是对知识的缺乏的惶恐,所以必须得学习执行计划,以减少对这一块知识的惶恐,下面是对执行计划的第一讲-理解执行计划. 本系列[T-SQL]主要是针对T-SQL的总结. S ...
- Spark sql -- Spark sql中的窗口函数和对应的api
一.窗口函数种类 ranking 排名类 analytic 分析类 aggregate 聚合类 Function Type SQL DataFrame API Description Ranking ...
- pl/sql进阶一控制结构
在任何计算机语言(c,java,c#,c++)都有各种控制语句(条件语句,循环结构,顺序控制结构…),在pl/sql中也存在这样的控制结构. 在本部分学校完毕后,希望大家达到: 1)使用各种if语句 ...
- SQL优化之SQL 进阶技巧(下)
上文( SQL优化之SQL 进阶技巧(上) )我们简述了 SQL 的一些进阶技巧,一些朋友觉得不过瘾,我们继续来下篇,再送你 10 个技巧 一. 使用延迟查询优化 limit [offset], [r ...
- (一)《SQL进阶教程》学习记录--CASE
背景:最近用到统计之类的复杂Sql比较多,有种"提笔忘字"的感觉,看书练习,举一反三,巩固加强. (一) <SQL进阶教程>学习记录--CASE (二) <SQL ...
随机推荐
- Docker 容器默认root账号运行,很不安全!
文章转载自:https://mp.weixin.qq.com/s/AeZoEKZBWFYwyhgicpgD4Q
- 使用logstash读取MySQL数据传输到es,并且@timestamp字段采用MySQL中的字段时间--建议采用这个
MySQL中数据样式 ES中数据样式 input { jdbc { jdbc_connection_string => "jdbc:mysql://192.168.0.145:3306 ...
- vue基础之MV*和它们之间的不同
vue中的设计思想 vue中的设计思想主要是MV*模式,由最早的MVC(model-view-controller)框架,到后面的MVP(model-view-presenter),甚至到最后的MVV ...
- 拉格朗日插值优化DP
拉格朗日插值优化DP 模拟赛出现神秘插值,太难啦!! 回忆拉格朗日插值是用来做什么的 对于一个多项式\(F(x)\),如果已知它的次数为\(m - 1\),且已知\(m\)个点值,那么可以得到 \[F ...
- Azure Kubernetes(AKS)部署及查看应用资源
简介 上一篇文章讲解了如何使用Azure DevOps持续部署应用到Azure Kubernetes上.但是部署是否成功?会不会遇到什么问题?项目运行中是否会出现问题?我们该怎么样查看这些问题,并且对 ...
- Map中定义的方法:
添加.删除.修改操作: Object put(Object key,Object value):将指定key-value添加到(或修改)当前map对象中void putAll(Map m):将m中的所 ...
- 10.APIView视图
from rest_framework import status from rest_framework.response import Response from snippets.models ...
- Redis 先操作数据库和先删除缓存, 一致性分析
初始状态: 数据库和缓存中v=10 第一种,先删除缓存在操作数据库: 线程1准备更新数据库的值v=20,先删除缓存, 此时线程2进来, 缓存未命中,查询数据库v=10, 写入缓存v=10, cpu回到 ...
- 如何在bat中进入虚拟环境
很多情况下我们希望在项目中建立一个build.bat用于项目的自动构建,避免每次构建时都需要手动在控制台中输入命令. 例如对于 pyinstall 的项目,只需要如下的实现: pyinstaller ...
- 【笔记】CF1251E Voting 及相关
题目传送门 贪心: 一个人 \(i\) 要投票,两种情况:花钱,或当前的人数达到了 \(m_i\). 而当前达到 \(m_i\) 的话所有 \(m_j \le m_i\) 也就达到要求了. 所以考虑将 ...