elasticsearch global 、 filters 和 cardinality 聚合
1. 背景
此处将单记录一下 global 、 filters和cardinality的聚合操作。
2、解释
1、global
global聚合是全局聚合,是对所有的文档进行聚合,而不受查询条件的限制。
global 聚合器只能作为顶级聚合器,因为将一个 global 聚合器嵌入另一个桶聚合器是没有意义的。
比如: 我们有50个文档,通过查询条件筛选之后存在10个文档,此时我想统计总共有多少个文档。是50个,因为global统计不受查询条件的限制。
2、filters
定义一个多桶聚合,其中每个桶都与一个过滤器相关联。每个桶都会收集与其关联的过滤器匹配的所有文档。
比如: 我们总共有50个文档,通过查询条件筛选之后存在10个文档,此时我想统计 这10个文档中,出现info词语的文档有多少个,出现warn词语的文档有多少个。
3、cardinality
类似于 SQL中的 COUNT(DISTINCT(字段)),不过这个是近似统计,是基于 HyperLogLog++ 来实现的。
3、需求
我们有一组日志,每条日志都存在id和message2个字段。此时根据message字段过滤出存在info warn的日志,然后进行统计:
- 系统中总共有多少条日志(
global + cardinality) - info和warn级别的日志各有多少条(
filters)
4、前置条件
4.1 创建mapping
PUT /index_api_log
{
"settings": {
"number_of_shards": 1
},
"mappings": {
"properties": {
"message":{
"type": "text"
},
"id": {
"type": "long"
}
}
}
}
4.2 准备数据
PUT /index_api_log/_bulk
{"index":{"_id":1}}
{"message": "this is info message-01","id":1}
{"index":{"_id":2}}
{"message": "this is info message-02","id":2}
{"index":{"_id":3}}
{"message": "this is warn message-01","id":3}
{"index":{"_id":4}}
{"message": "this is error message","id":4}
{"index":{"_id":5}}
{"message": "this is info and warn message","id":5}
5、实现3的需求
5.1 dsl
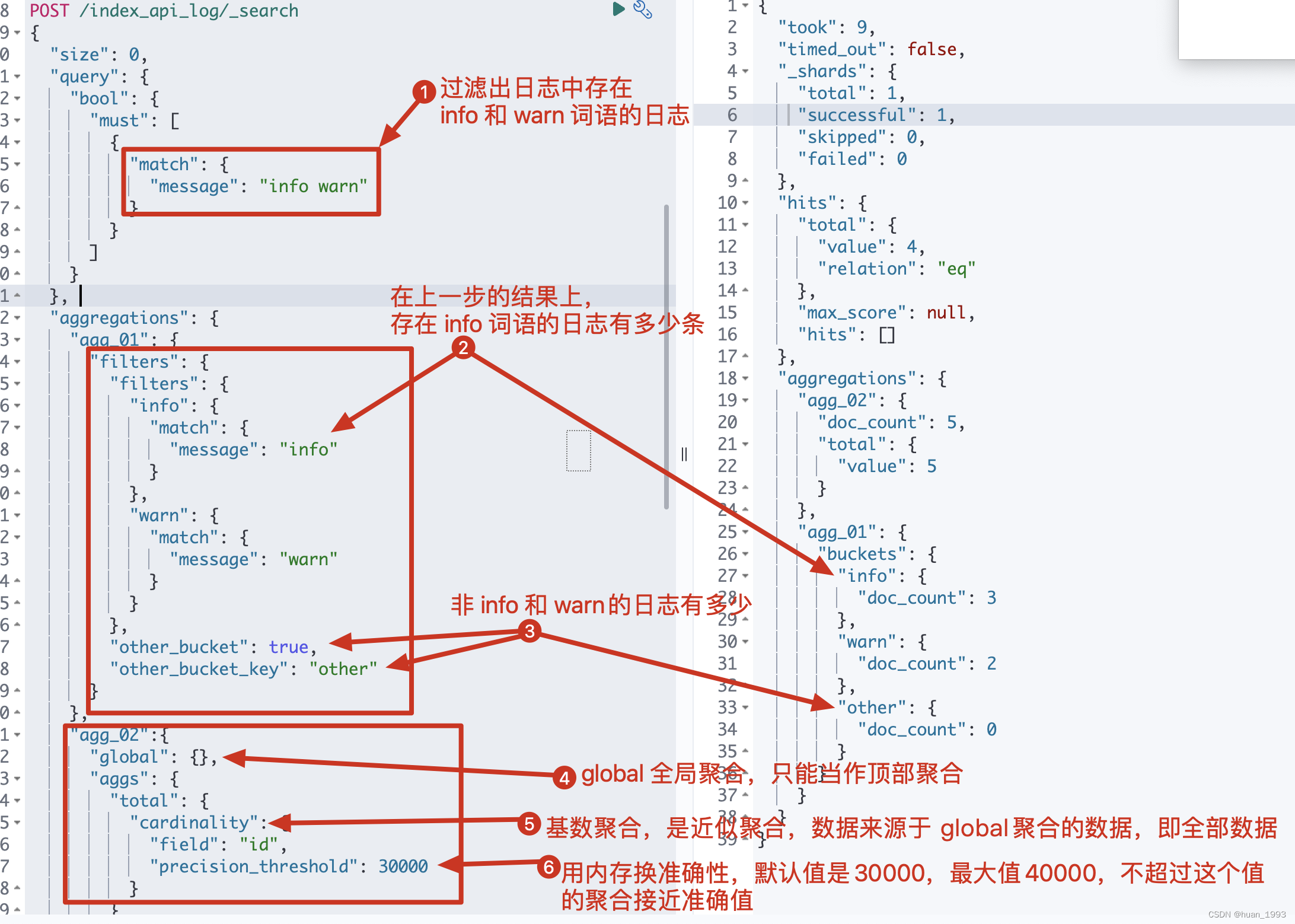
POST /index_api_log/_search
{
"size": 0,
"query": {
"bool": {
"must": [
{
"match": {
"message": "info warn"
}
}
]
}
},
"aggregations": {
"agg_01": {
"filters": {
"filters": {
"info": {
"match": {
"message": "info"
}
},
"warn": {
"match": {
"message": "warn"
}
}
},
"other_bucket": true,
"other_bucket_key": "other"
}
},
"agg_02":{
"global": {},
"aggs": {
"total": {
"cardinality": {
"field": "id",
"precision_threshold": 30000
}
}
}
}
}
}
5.2 java 代码
@Test
@DisplayName("global and filters and cardinality 聚合")
public void test01() throws IOException {
SearchRequest request = SearchRequest.of(searchRequest ->
searchRequest.index("index_api_log")
// 查询 message 中存在 info 和 warn 的日志
.query(query -> query.bool(bool -> bool.must(must -> must.match(match -> match.field("message").query("info warn")))))
// 查询的结果不返回
.size(0)
// 第一个聚合
.aggregations("agg_01", agg ->
agg.filters(filters ->
filters.filters(f ->
f.array(
Arrays.asList(
// 在上一步query的结果中,将 message中包含info的进行聚合
Query.of(q -> q.match(m -> m.field("message").query("info"))),
// 在上一步query的结果中,将 message中包含warn的进行聚合
Query.of(q -> q.match(m -> m.field("message").query("warn")))
)
)
)
// 如果上一步的查询中,存在非 info 和 warn的则是否聚合到 other 桶中
.otherBucket(true)
// 给 other 桶取一个名字
.otherBucketKey("other")
)
)
// 第二个聚合
.aggregations("agg_02", agg ->
agg
// 此处的 global 聚合只能放在顶部
.global(global -> global)
// 子聚合,数据来源于所有的文档,不受上一步query结果的限制
.aggregations("total", subAgg ->
// 类似于SQL中的 count(distinct(字段)),是一个近似统计
subAgg.cardinality(cardinality ->
// 统计的字段
cardinality.field("id")
// 精度,默认值是30000,最大值也是40000,不超过这个值的聚合近似准确值
.precisionThreshold(30000)
)
)
)
);
System.out.println("request: " + request);
SearchResponse<String> response = client.search(request, String.class);
System.out.println("response: " + response);
}
5.3 运行结果
6、实现代码
7、参考文档
elasticsearch global 、 filters 和 cardinality 聚合的更多相关文章
- Elasticsearch 第六篇:聚合统计查询
h2.post_title { background-color: rgba(43, 102, 149, 1); color: rgba(255, 255, 255, 1); font-size: 1 ...
- 把 Elasticsearch 当数据库使:聚合后排序
使用 https://github.com/taowen/es-monitor 可以用 SQL 进行 elasticsearch 的查询.有的时候分桶聚合之后会产生很多的桶,我们只对其中部分的桶关心. ...
- Elasticsearch学习系列四(聚合搜索)
聚合分析 聚合分析是数据库中重要的功能特性,完成对一个查询的集中数据的聚合计算.如:最大值.最小值.求和.平均值等等.对一个数据集求和,算最大最小值等等,在ES中称为指标聚合,而对数据做类似关系型数据 ...
- ElasticSearch的高级复杂查询:非聚合查询和聚合查询
一.非聚合复杂查询(这儿展示了非聚合复杂查询的常用流程) 查询条件QueryBuilder的构建方法 1.1 精确查询(必须完全匹配上,相当于SQL语句中的“=”) ① 单个匹配 termQuery ...
- ElasticSearch入门系列(三)文档,索引,搜索和聚合
一.文档 在实际使用中的对象往往拥有复杂的数据结构 Elasticsearch是面向文档的,这意味着他可以存储整个对象或文档,然而他不仅仅是存储,还会索引每个文档的内容使之可以被搜索,在Elastic ...
- ElasticSearch 的 聚合(Aggregations)
Elasticsearch有一个功能叫做 聚合(aggregations) ,它允许你在数据上生成复杂的分析统计.它很像SQL中的 GROUP BY 但是功能更强大. Aggregations种类分为 ...
- ElasticSearch - 信息聚合系列之聚合过滤
摘要 聚合范围限定还有一个自然的扩展就是过滤.因为聚合是在查询结果范围内操作的,任何可以适用于查询的过滤器也可以应用在聚合上. 版本 elasticsearch版本: elasticsearch-2. ...
- elasticsearch聚合操作——本质就是针对搜索后的结果使用桶bucket(允许嵌套)进行group by,统计下分组结果,包括min/max/avg
分析 Elasticsearch有一个功能叫做聚合(aggregations),它允许你在数据上生成复杂的分析统计.它很像SQL中的GROUP BY但是功能更强大. 举个例子,让我们找到所有职员中最大 ...
- ElasticSearch 2 (33) - 信息聚合系列之聚合过滤
ElasticSearch 2 (33) - 信息聚合系列之聚合过滤 摘要 聚合范围限定还有一个自然的扩展就是过滤.因为聚合是在查询结果范围内操作的,任何可以适用于查询的过滤器也可以应用在聚合上. 版 ...
- ElasticSearch 2 (30) - 信息聚合系列之条形图
ElasticSearch 2 (30) - 信息聚合系列之条形图 摘要 版本 elasticsearch版本: elasticsearch-2.x 内容 聚合还有一个令人激动的特性就是能够十分容易地 ...
随机推荐
- 小程序uni-app发起网络异步请求
// uni.request({ // url: 'api/boxs/search', // // 使用监听函数防止this指向改变 // success: res => { // // 判断是 ...
- C语言下for循环的一点技巧总结
for循环是普遍应用与各种计算机语言的一种循环方式. 一般情况下, for循环规则:for(条件一:条件二:条件三) 条件一为满足条件,也就是条件一为1时,进入这个for循环.条件二为循环条件,也就是 ...
- 大数据技术之HBase原理与实战归纳分享-上
@ 目录 概述 定义 特点 数据模型 概述 逻辑结构 物理存储结构 数据模型 应用场景 基础架构 安装 前置条件 部署 启动服务 高可用 Shell操作 基础操作 命令空间 DDL DML 概述 定义 ...
- vue项目Eslint和prettier结合使用
一.eslint介绍--代码语法检查工具 Eslint是一个代码检查工具,用来检查你的代码语法是否符合指定的规范,ECMAScript标准 二.prettier插件--代码格式化工具 prettier ...
- [Thread] 多线程顺序执行
Join 主线程join 启动线程t1,随后调用join,main线程需要等t1线程执行完毕后继续执行. public class MainJoin { static class MyThread i ...
- JUC(8)Stream流式计算
文章目录 1.ForkJoin 1.ForkJoin ForkJoin 在JDK1.7 ,并执行任务!提高效率,大数据量 大数据:Map Reduce (把大任务拆分为小任务) ForkJoin特点: ...
- Vscode设置标签页多行显示
1.设置标签页多行展示的方法 文件–>首选项–>设置 2.勾选多行显示按钮 3.显示效果
- python基础爬虫,翻译爬虫,小说爬虫
基础爬虫: # -*- coding: utf-8 -*- import requests url = 'https://www.baidu.com' # 注释1 headers = { # 注释2 ...
- python批量依赖包操作
1.导出所有的python依赖 pip freeze > requirements.txt #requirements.txt 为自定名称,可以指定路径 2.自动安装所有依赖包 pip in ...
- MySQL 索引失效-模糊查询,最左匹配原则,OR条件等。
索引失效 介绍 索引失效就是我们明明在查询时的条件为索引列(包括自己新建的索引),但是索引不能起效,走的是全表扫描.explain 后可查看type=ALL. 这是为什么呢? 首先介绍有以下几种情况索 ...