mysql中innodb和myisam区别
前言
InnoDB和MyISAM是很多人在使用MySQL时最常用的两个表类型,这两个表类型各有优劣,5.7之后就不一样了。
1、事务和外键
● InnoDB具有事务,支持4个事务隔离级别,回滚,崩溃修复能力和多版本并发的事务安全,包括ACID。如果应用中需要执行大量的INSERT或UPDATE操作,
则应该使用InnoDB,这样可以提高多用户并发操作的性能
● MyISAM管理非事务表。它提供高速存储和检索,以及全文搜索能力。如果应用中需要执行大量的SELECT查询,那么MyISAM是更好的选择
2、全文索引
● Innodb不支持全文索引,如果一定要用的话,最好使用sphinx等搜索引擎。myisam对中文支持的不是很好
不过新版本的Innodb已经支持了
3、锁
● mysql支持三种锁定级别,行级、页级、表级;
● MyISAM支持表级锁定,提供与 Oracle 类型一致的不加锁读取(non-locking read in SELECTs)
● InnoDB支持行级锁,InnoDB表的行锁也不是绝对的,如果在执行一个SQL语句时MySQL不能确定要扫描的范围,InnoDB表同样会锁全表,注意间隙锁的影响
● 例如:update table set num=1 where name like “%aaa%”
4、存储
● MyISAM在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型, .frm文件存储表定义,数据文件的扩展名为.MYD, 索引文件的扩展名是.MYI
● InnoDB,基于磁盘的资源是InnoDB表空间数据文件和它的日志文件,InnoDB 表的大小只受限于操作系统文件的大小
● 注意:MyISAM表是保存成文件的形式,在跨平台的数据转移中使用MyISAM存储会省去不少的麻烦
5、索引
● InnoDB(索引组织表)使用的聚簇索引、索引就是数据,顺序存储,因此能缓存索引,也能缓存数据
● MyISAM(堆组织表)使用的是非聚簇索引、索引和文件分开,随机存储,只能缓存索引
6、并发
● MyISAM读写互相阻塞:不仅会在写入的时候阻塞读取,MyISAM还会在读取的时候阻塞写入,但读本身并不会阻塞另外的读
● InnoDB 读写阻塞与事务隔离级别相关
7、场景选择
MyISAM
● 不需要事务支持(不支持)
● 并发相对较低(锁定机制问题)
● 数据修改相对较少(阻塞问题),以读为主
● 数据一致性要求不是非常高
1.尽量索引(缓存机制)
2.调整读写优先级,根据实际需求确保重要操作更优先
3.启用延迟插入改善大批量写入性能
4.尽量顺序操作让insert数据都写入到尾部,减少阻塞
5.分解大的操作,降低单个操作的阻塞时间
6.降低并发数,某些高并发场景通过应用来进行排队机制
7.对于相对静态的数据,充分利用Query Cache可以极大的提高访问效率
8.MyISAM的Count只有在全表扫描的时候特别高效,带有其他条件的count都需要进行实际的数据访问
InnoDB
● 需要事务支持(具有较好的事务特性)
● 行级锁定对高并发有很好的适应能力,但需要确保查询是通过索引完成
● 数据更新较为频繁的场景
● 数据一致性要求较高
1.硬件设备内存较大,可以利用InnoDB较好的缓存能力来提高内存利用率,尽可能减少磁盘 IO
2.主键尽可能小,避免给Secondary index带来过大的空间负担
3.避免全表扫描,因为会使用表锁
4.尽可能缓存所有的索引和数据,提高响应速度
5.在大批量小插入的时候,尽量自己控制事务而不要使用autocommit自动提交
6.合理设置innodb_flush_log_at_trx_commit参数值,不要过度追求安全性
7.避免主键更新,因为这会带来大量的数据移动
8、其它细节
1)InnoDB 中不保存表的具体行数,注意的是,当count(*)语句包含 where条件时,两种表的操作是一样的
2)对于AUTO_INCREMENT类型的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中,可以和其他字段一起建立联合索引,
如果你为一个表指定AUTO_INCREMENT列,在数据词典里的InnoDB表句柄包含一个名为自动增长计数器的计数器,它被用在为该列赋新值。自动增长计数器仅被存储在主内中,
而不是存在磁盘
3)DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除
4)LOAD TABLE FROM MASTER操作对InnoDB是不起作用的,解决方法是首先把InnoDB表改成MyISAM表,导入数据后再改成InnoDB表,但是对于使用的额外的InnoDB特性(例如外键)的表不适用
5)如果执行大量的SELECT,MyISAM是更好的选择,如果你的数据执行大量的INSERT或UPDATE,出于性能方面的考虑,应该使用InnoDB表
9、为什么MyISAM会比Innodb 的查询速度快
InnoDB 在做SELECT的时候,要维护的东西比MYISAM引擎多很多
1)InnoDB 要缓存数据和索引,MyISAM只缓存索引块,这中间还有换进换出的减少
2)innodb寻址要映射到块,再到行,MyISAM记录的直接是文件的OFFSET,定位比INNODB要快
3)InnoDB 还需要维护MVCC一致;虽然你的场景没有,但他还是需要去检查和维护
MVCC ( Multi-Version Concurrency Control )多版本并发控制
InnoDB :通过为每一行记录添加两个额外的隐藏的值来实现MVCC,这两个值一个记录这行数据何时被创建,另外一个记录这行数据何时过期(或者被删除)。
但是InnoDB并不存储这些事件发生时的实际时间,相反它只存储这些事件发生时的系统版本号。这是一个随着事务的创建而不断增长的数字。
每个事务在事务开始时会记录它自己的系统版本号。每个查询必须去检查每行数据的版本号与事务的版本号是否相同。
让我们来看看当隔离级别是REPEATABLE READ时这种策略是如何应用到特定的操作的
SELECT InnoDB必须每行数据来保证它符合两个条件
1、InnoDB必须找到一个行的版本,它至少要和事务的版本一样老(也即它的版本号不大于事务的版本号)。
这保证了不管是事务开始之前,或者事务创建时,或者修改了这行数据的时候,这行数据是存在的。
2、这行数据的删除版本必须是未定义的或者比事务版本要大。这可以保证在事务开始之前这行数据没有被删除。
10、mysql性能
MyISAM最为人垢病的缺点就是缺乏事务的支持
InnoDB 的磁盘性能很令人担心
MySQL 缺乏良好的 tablespace
两种类型最主要的差别就是Innodb 支持事务处理与外键和行级锁.而MyISAM不支持.所以MyISAM往往就容易被人认为只适合在小项目中使用。
我作为使用MySQL的用户角度出发,Innodb和MyISAM都是比较喜欢的,但是从我目前运维的数据库平台要达到需求:99.9%的稳定性,
方便的扩展性和高可用性来说的话,MyISAM绝对是我的首选。
原因如下:
1、首先我目前平台上承载的大部分项目是读多写少的项目,而MyISAM的读性能是比Innodb强不少的。
2、MyISAM的索引和数据是分开的,并且索引是有压缩的,内存使用率就对应提高了不少。能加载更多索引,而Innodb是索引和数据是紧密捆绑的,
没有使用压缩从而会造成Innodb比MyISAM体积庞大不小。
3、从平台角度来说,经常隔1,2个月就会发生应用开发人员不小心update一个表where写的范围不对,导致这个表没法正常用了,
这个时候MyISAM的优越性就体现出来了,随便从当天拷贝的压缩包取出对应表的文件,随便放到一个数据库目录下,然后dump成sql再导回到主库,
并把对应的binlog补上。如果是Innodb,恐怕不可能有这么快速度,别和我说让Innodb定期用导出xxx.sql机制备份,
因为我平台上最小的一个数据库实例的数据量基本都是几十G大小。
4、从我接触的应用逻辑来说,select count(*) 和order by 是最频繁的,大概能占了整个sql总语句的60%以上的操作,而这种操作Innodb其实也是会锁表的,
很多人以为Innodb是行级锁,那个只是where对它主键是有效,非主键的都会锁全表的。
5、还有就是经常有很多应用部门需要我给他们定期某些表的数据,MyISAM的话很方便,只要发给他们对应那表的frm.MYD,MYI的文件,
让他们自己在对应版本的数据库启动就行,而Innodb就需要导出xxx.sql了,因为光给别人文件,受字典数据文件的影响,对方是无法使用的。
6、如果和MyISAM比insert写操作的话,Innodb还达不到MyISAM的写性能,如果是针对基于索引的update操作,虽然MyISAM可能会逊色Innodb,
但是那么高并发的写,从库能否追的上也是一个问题,还不如通过多实例分库分表架构来解决。
7、如果是用MyISAM的话,merge引擎可以大大加快应用部门的开发速度,他们只要对这个merge表做一些select count(*)操作,
非常适合大项目总量约几亿的rows某一类型(如日志,调查统计)的业务表。
8、当然Innodb也不是绝对不用,用事务的项目如模拟炒股项目,我就是用Innodb的,活跃用户20多万时候,也是很轻松应付了,
因此我个人也是很喜欢Innodb的,只是如果从数据库平台应用出发,我还是会首选MyISAM。
9、另外,可能有人会说你MyISAM无法抗太多写操作,但是我可以通过架构来弥补,说个我现有用的数据库平台容量:
主从数据总量在几百T以上,每天十多亿 pv的动态页面,还有几个大项目是通过数据接口方式调用未算进pv总数,
(其中包括一个大项目因为初期memcached没部署,导致单台数据库每天处理 9千万的查询)。
而我的整体数据库服务器平均负载都在0.5-1左右。
11、MyISAM索引实现
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。如图:
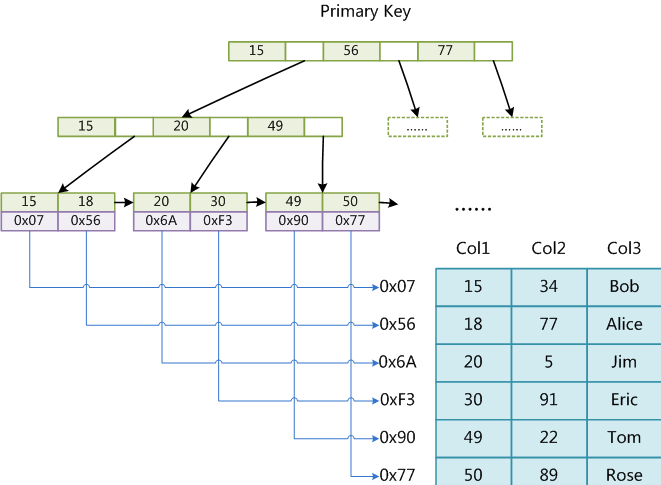
这里设表一共有三列,假设我们以Col1为主键,则上图是一个MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址。
在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。
如果我们在Col2上建立一个辅助索引,则此索引的结构如下图所示:
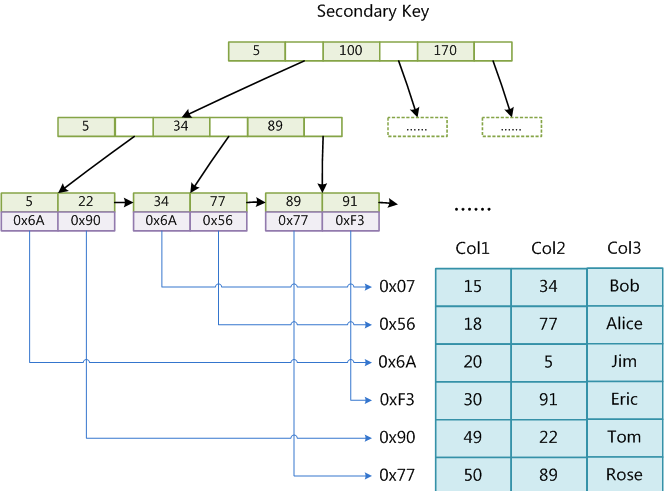
同样也是一颗B+Tree,data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,
如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
12、InnoDB索引实现
虽然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同。
表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,
因此InnoDB表数据文件本身就是主索引。
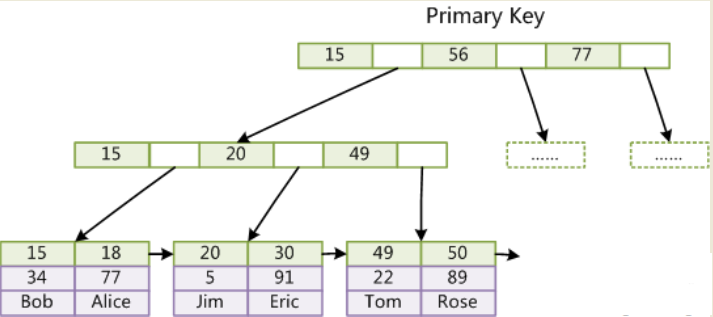
上图是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,
所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,
则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域。
例如,下图为定义在Col3上的一个辅助索引:
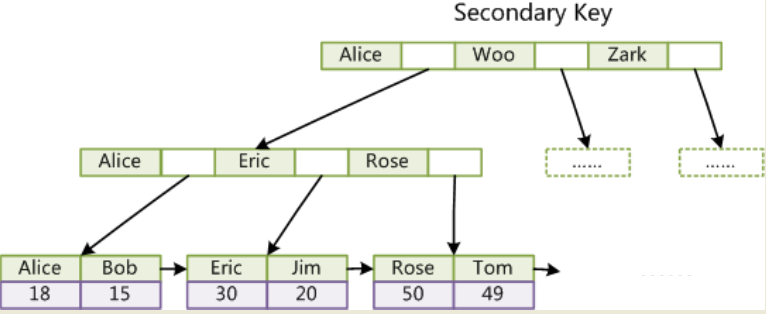
这里以英文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,
然后用主键到主索引中检索获得记录。
总结
InnoDB:
● InnoDB 给 MySQL 提供了具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
● InnoDB 提供了行锁(locking on row level),提供与 Oracle 类型一致的不加锁读取(non-locking read in SELECTs)。这些特性均提高了多用户并发操作的性能表现。
● 在InnoDB表中不需要扩大锁定(lock escalation),因为 InnoDB 的列锁定(row level locks)适宜非常小的空间。InnoDB 是 MySQL 上第一个提供外键约束(FOREIGN KEY constraints)的表引擎。
InnoDB 的设计目标是处理大容量数据库系统,它的 CPU 利用率是其它基于磁盘的关系数据库引擎所不能比的。
● 在技术上,InnoDB 是一套放在 MySQL 后台的完整数据库系统,InnoDB 在主内存中建立其专用的缓冲池用于高速缓冲数据和索引。
● InnoDB 把数据和索引存放在表空间里,可能包含多个文件,这与其它的不一样,举例来说,在 MyISAM 中,表被存放在单独的文件中。
● InnoDB 表的大小只受限于操作系统的文件大小,一般为 2 GB。InnoDB所有的表都保存在同一个数据文件 ibdata1 中(也可能是多个文件,或者是独立的表空间文件),
相对来说比较不好备份,可以拷贝文件或用navicat for mysql。
● 对于支持事务的InnoDB类型的表,影响速度的主要原因是AUTO COMMIT默认设置是打开的,而且程序没有显式调用BEGIN 开始事务,导致每插入一条都自动Commit,
严重影响了速度。可以在执行sql前调用begin,多条sql形成一个事物(即使autocommit打开也可以),将大大提高性能。
MyISAM
● 每张MyISAM 表被存放在三个文件 :frm 文件存放表格定义。 数据文件是MYD (MYData) 。 索引文件是MYI (MYIndex) 引伸。
● 因为MyISAM相对简单所以在效率上要优于InnoDB,小型应用使用MyISAM是不错的选择。
● MyISAM表是保存成文件的形式,在跨平台的数据转移中使用MyISAM存储会省去不少的麻烦。
● MyIASM是IASM表的新版本,有如下扩展:
1. 二进制层次的可移植性。
2. NULL列索引。
3. 对变长行比ISAM表有更少的碎片。
4. 支持大文件。
5. 更好的索引压缩。
6. 更好的键吗统计分布。
7. 更好和更快的auto_increment处理。
转载整理,如有不足,请见谅!
mysql中innodb和myisam区别的更多相关文章
- mysql中innodb和myisam的区别
InnoDB和MyISAM是很多人在使用MySQL时最常用的两个表类型,这两个表类型各有优劣,5.7之后就不一样了 1.事务和外键 InnoDB具有事务,支持4个事务隔离级别,回滚,崩溃修复能力和多版 ...
- Mysql中innodb和myisam
innodb和myisam两种存储引擎的区别 1.事务和外键 1)InnoDB具有事务,支持4个事务隔离级别,回滚,崩溃修复能力和多版本并发的事务安全,包括ACID.如果应用中需要执行大量的INSER ...
- MySQL中 InnoDB 和 MyISAM 小结
转:http://blog.csdn.net/ithomer/article/details/5136982 部分内容: InnoDB和MyISAM的差别 InnoDB和MyISAM是许多人在使用My ...
- mysql中InnoDB与MyISAM的区别
两者的区别: 1. InnoDB支持事务,MyISAM不支持,对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条SQL语言放在begin和commit之间,组成 ...
- mysql 中 innoDB 与 MySAM
mysql 中 innoDB 与 MyISAM 的特点 --ENGINE = innodb 1.提供事务处理,支持行锁: 2.不加锁读取,增加并发读的用户数量和空间: 3. insert/update ...
- Mysql数据库中InnoDB和MyISAM的差别
Mysql数据库中InnoDB和MyISAM的差别 InnoDB和MyISAM是在使用MySQL最常用的两个表类型,各有优缺点,视具体应用而定.基本的差别为:MyISAM类型不支持事务处理等高级处理, ...
- MySQL中varchar与char区别
MySQL中varchar与char区别(转) MySQL中varchar最大长度是多少? 一. varchar存储规则: 4.0版本以下,varchar(20),指的是20字节,如果存放UTF8汉字 ...
- MySql中innodb存储引擎事务日志详解
分析下MySql中innodb存储引擎是如何通过日志来实现事务的? Mysql会最大程度的使用缓存机制来提高数据库的访问效率,但是万一数据库发生断电,因为缓存的数据没有写入磁盘,导致缓存在内存中的数据 ...
- MySQL中InnoDB锁不住表的原因
MySQL中InnoDB锁不住表是因为如下两个参数的设置: mysql> show variables like '%timeout%'; +-------------------------- ...
随机推荐
- vue 点击事件唤醒QQ
window.location.href = 'http://wpa.qq.com/msgrd?v=3&uin=QQ号' window.location.href = 'http://wpa. ...
- 洛谷 P2392 kkksc03考前临时抱佛脚, dp / 深搜
题目链接 P2392 kkksc03考前临时抱佛脚 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 题目 dp代码 #include <iostream> #includ ...
- 基于 Redis 分布式锁
1.主流分布式锁实现方案 基于数据库实现分布式锁 基于缓存(redis 等) 基于 Zookeeper 2.根据实现方式分类 : 类 CAS 自旋式分布式锁:询问的方式,类似 java 并发编程中的线 ...
- jsp第一周作业
环境搭建,运行出来一个JSP页面,显式hello 英文字母表 <%@ page language="java" import="java.util.*" ...
- JavaWeb和WebGIS学习笔记(七)——MapGuide Open Source安装、配置以及MapGuide Maestro发布地图——超详细!目前最保姆级的MapGuide上手指南!
JavaWeb和WebGIS学习笔记(七)--MapGuide Open Source安装.配置以及MapGuide Maestro发布地图 超详细!目前最保姆级的MapGuide上手指南! 系列链接 ...
- python的一些练习题
1.目前工作上有一堆的ip地址,ip是ok的,但是需要找出来不在这里面的其他ip import os a = list() with open('ip.txt','r') as f: #print(f ...
- PowerDotNet平台化软件架构设计与实现系列(13):应用监控平台
本文再写一篇和具体业务逻辑几乎无关的公共服务应用监控平台.PowerDotNet自研的应用监控平台系统,是服务治理的重要拼图,和服务治理平台配合使用效果更好. 监控开源产品非常丰富,站在巨人的肩膀上, ...
- 攻防世界-MISC:pure_color
这是攻防世界高手进阶区的第六题,题目如下: 点击下载附件一,得到一张空白的png图片 用StegSolve打开,然后点击箭头(如下图所示) 多点击几次,即可得到flag 所以,这道题的flag如下: ...
- ucore lab7 同步互斥机制 学习笔记
管程的设计实在是精妙,初看的时候觉得非常奇怪,这混乱的进程切换怎么能保证同一时刻只有一个进程访问管程?理清之后大为赞叹,函数中途把前一个进程唤醒后立刻把自己挂起,完美切换.后一个进程又在巧妙的时机将自 ...
- 五三想休息,今天还学习,图解二叉树的层序遍历BFS(广度优先)模板,附面试题题解
壹 ❀ 引 我在从JS执行栈角度图解递归以及二叉树的前.中.后遍历的底层差异一文中,从一个最基本的数组遍历引出递归,在掌握递归的书写规则后,又从JS执行栈角度解释了二叉树三种深度优先(前序.中序后序) ...