基于 Apache Hudi + Presto + AWS S3 构建开放Lakehouse
认识Lakehouse
数据仓库被认为是对结构化数据执行分析的标准,但它不能处理非结构化数据。 包括诸如文本、图像、音频、视频和其他格式的信息。 此外机器学习和人工智能在业务的各个方面变得越来越普遍,它们需要访问数据仓库之外的大量信息。
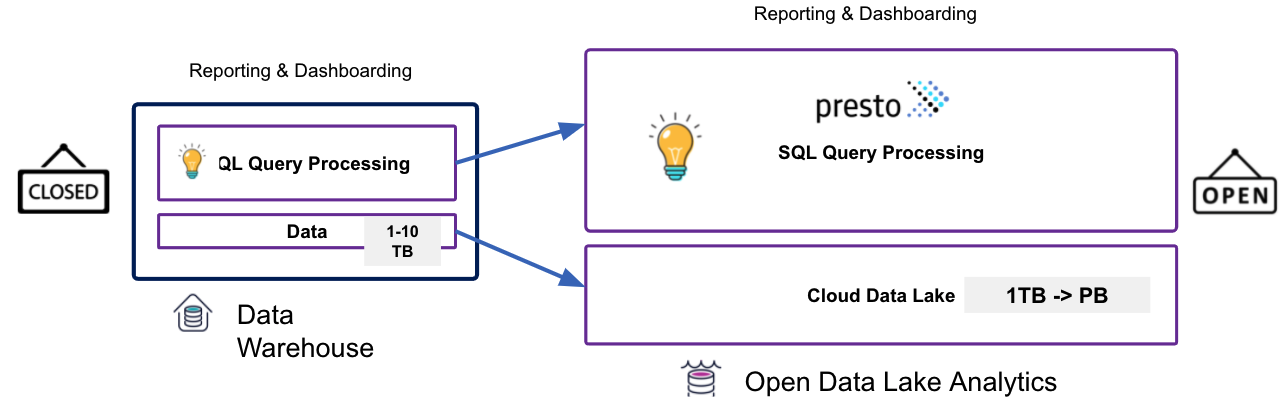
开放的Lakehouse
云计算发展引发了计算与存储分离,这利用了成本优势并能够灵活地存储来自多个来源的数据。 所有这一切都催生了开放Lakehouse的新数据平台架构。现在通过使用 Presto 和 Apache Hudi 等开源和开放格式技术解决了传统云数据仓库的局限性。
什么是Lakehouse
开放的Lakehouse 基于将仓库工作负载引入数据湖的概念。可以对不需要供应商锁定的技术和工具进行分析,包括许可、数据格式、接口和基础设施。包括四个关键要素:
- 开源——我们将为开放数据湖分析探索的技术在 Apache 2.0 许可下是完全开源的。这意味着将受益于最好的创新,不仅来自一个供应商,而是来自整个开源社区。
- 开放格式——它们不使用任何专有格式。事实上它支持大多数常见格式,如 JSON、Apache ORC、Apache Parquet 等。
- 开放接口——这些接口与行业标准 ANSI SQL 兼容,标准 JDBC/ODBC 驱动程序可用于连接任何报告/仪表板/笔记本工具。并且因为它是开源的,所以不断添加和扩展行业标准语言条款。
- 开放云——该技术栈与云无关,没有本地存储与容器对齐,可以在任何云上运行。
为什么选择Lakehouse
开放Lakehouse允许以较低的成本在中央存储库中整合结构化和半/非结构化数据,并消除运行 ETL 的复杂性。 这会带来高性能并减少运行分析的成本和时间。
- 将计算带入数据(存储计算分离)
- 治理/事务层的灵活性
- 存储结构化和半/非结构化数据的灵活性和低成本
- 每一层的灵活性——挑选最适合的工作负载/用例的技术
开放Lakehouse架构
现在让我们深入了解数据堆栈本身和不同的层并讨论每一层解决什么问题。
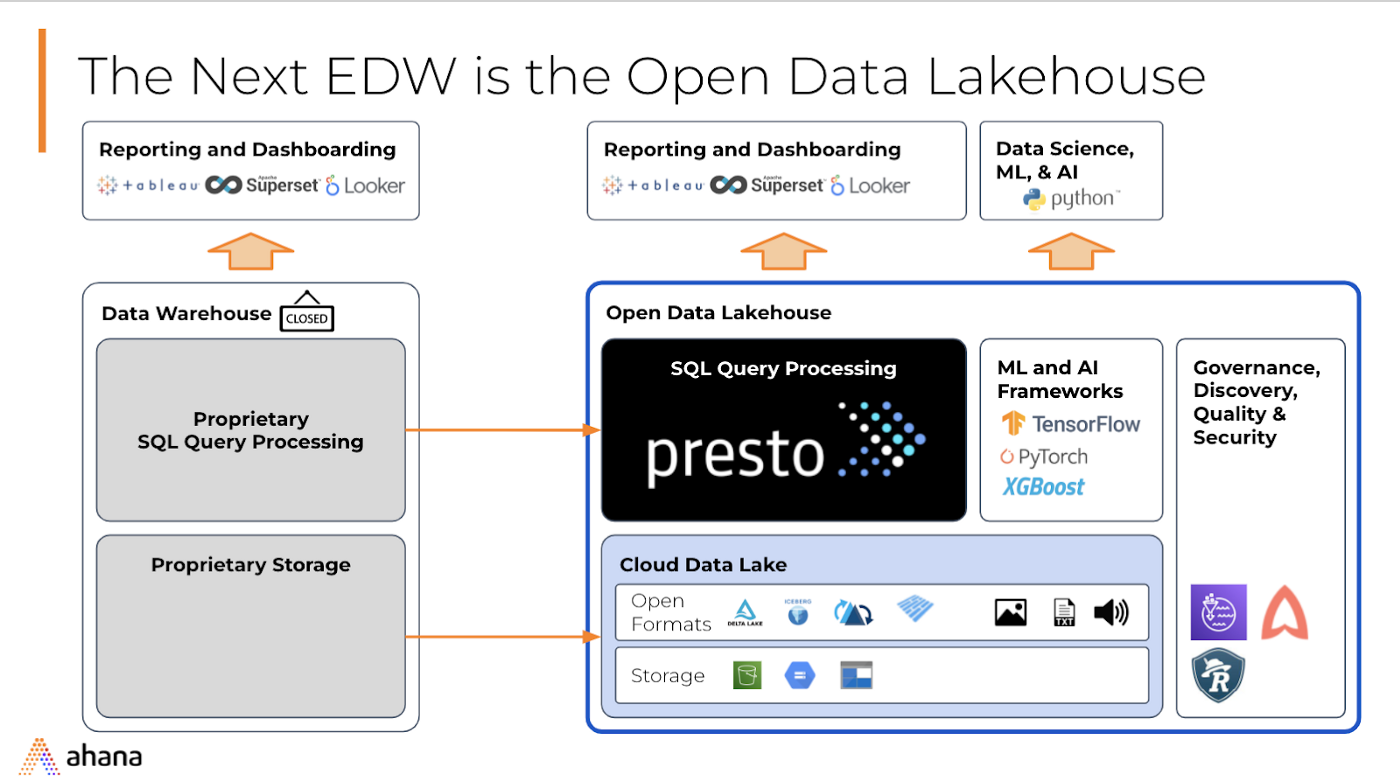
BI/应用工具——数据可视化、数据科学工具
可插拔的 BI/分析应用工具。 开放数据湖分析栈支持使用 JDBC/ODBC 驱动程序,因此可以根据用例和工作负载连接 Tableau、Looker、preset、jupyter notebook 等。
Presto — 数据湖的 SQL 查询引擎
Presto 是用于数据湖的并行分布式 SQL 查询引擎。它允许对大量数据湖上的数据进行交互式、即席分析。使用 Presto可以查询数据所在的位置,包括 AWS S3、关系数据库、NoSQL 数据库和一些专有数据存储等数据源。
Presto 专为具有内存执行的高性能交互式查询而构建,主要特征包括:
- 从 1 到 1000 个 Worker 的高可扩展性
- 支持广泛的 SQL 用例的灵活性
- 高度可插拔的架构,通过安全、事件监听器等的自定义集成,可以轻松扩展 Presto。
- 通过 Presto 连接器联合数据源,尤其是数据湖
- 使用 ANSI SQL 标准与现有 SQL 系统无缝集成

Presto 的完整部署有一个Coordinator和多个Worker。查询由客户端(如命令行界面 (CLI)、BI 工具或支持 SQL 的笔记本)提交给Coordinator。 Coordinator使用元数据和数据分布信息解析、分析和生成最优查询执行计划。 然后将该计划分发给Worker进行处理。 这种解耦存储模型的优势在于 Presto 可以提供所有已聚合到 S3 等数据存储层的数据的单一视图。
Apache Hudi — 开放数据湖中的流式处理
传统数据仓库的一大缺点是保持数据更新。它需要构建数据集市/多维数据集,然后从源到目标集市进行连续 ETL,从而导致额外的时间、成本和数据重复。同样数据湖中的数据需要更新并保持一致,而无需运营开销。
开放 Lakehouse 分析栈中的事务层至关重要,尤其是随着数据量的增加以及必须更新数据的次数不断增加。使用像 Apache Hudi 这样的技术可以解决以下问题:
- 摄取增量数据
- 更改数据捕获,包括插入和删除
- 增量数据处理
- ACID 事务
Apache Hudi 代表 Hadoop Upserts Deletes Incrementals,是一个基于开源的事务层,具有由 Uber 开发的分析存储抽象。简而言之 Hudi 在数据湖中实现了原子性、一致性、隔离性和持久性 (ACID) 事务。 Hudi 使用开放文件格式 Parquet 和 Avro 进行数据存储和内部表格格式,称为 Copy-On-Write 和 Merge-On-Read。
它与 Presto 内置集成,因此可以查询存储在开放文件格式中的"hudi 数据集"。
Hudi数据管理
Hudi 有一种基于目录结构的表格式,并且该表将具有分区,这些分区是包含该分区的数据文件的文件夹。它具有支持快速更新插入的索引功能。 Hudi 有两种表类型,它们定义了数据的索引和布局方式,它们定义了基础数据如何暴露给查询。
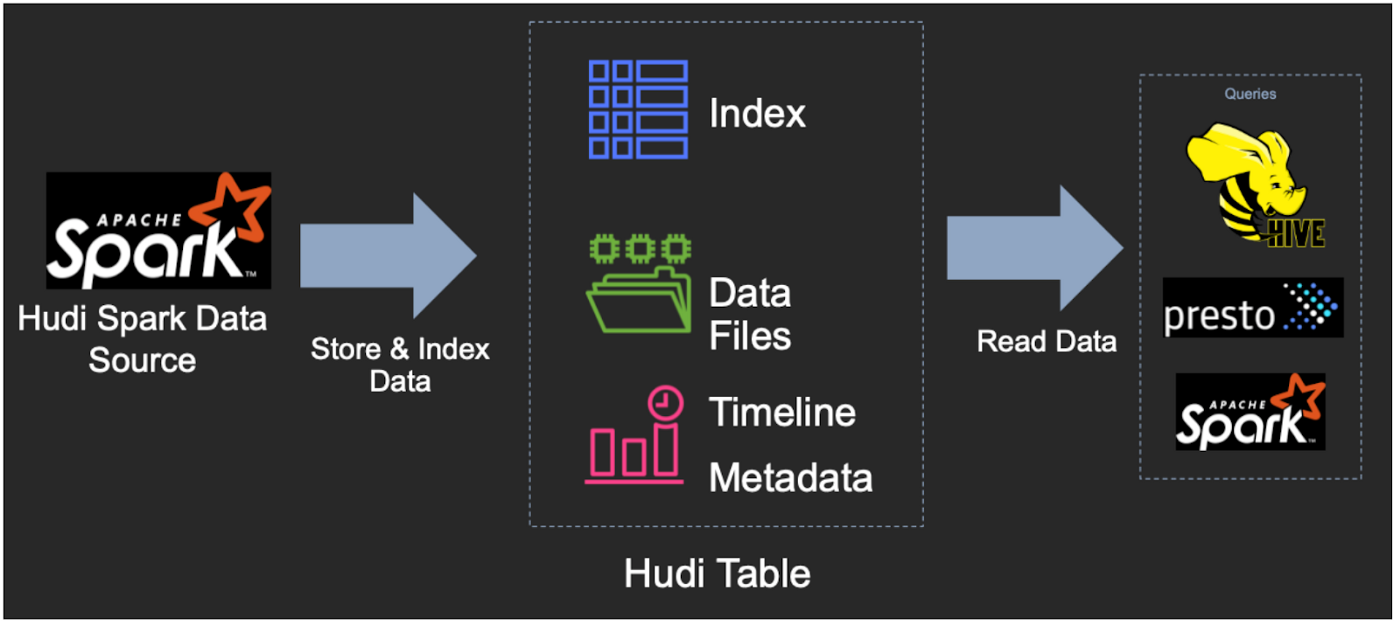
- Copy-On-Write (COW):数据以 Parquet 文件格式存储(列式存储),每次新的更新都会在写入期间创建一个新版本的文件。更新现有的一组行将导致为正在更新的行重写整个 parquet 文件。
- Merge-On-Read (MOR):数据以 Parquet 文件格式(列)和 Avro(基于行)文件格式的组合存储。更新记录到基于行的增量文件,直到压缩,这将产生新版本的列文件。
基于这两种表类型,Hudi 提供了三种逻辑视图,用于从数据湖中查询数据
- 读取优化——查询查看来自 CoW 表的最新提交数据集和来自 MoR 表的最新压缩数据集
- 增量——在提交/压缩后查询看到写入表的新数据。这有助于构建增量数据管道及其分析
- 实时——通过内联合并列式和基于行的文件,提供来自 MoR 表的最新提交数据
AWS S3 — 数据湖
数据湖是存储来自不同来源的数据的中心位置,例如结构化、半结构化和非结构化数据,以及 AWS S3 等对象存储的开放格式。
Amazon Simple Storage Service (Amazon S3) 是实现开放数据湖分析的事实上的集中式存储。
入门
如何使用 Presto 运行开放数据湖分析工作负载以在 S3 上查询 Apache Hudi 数据集
现在已经了解了栈的详细信息,是时候开始入门了。 这里将快速展示如何实际使用 Presto 在 S3 上查询 Hudi 数据集。
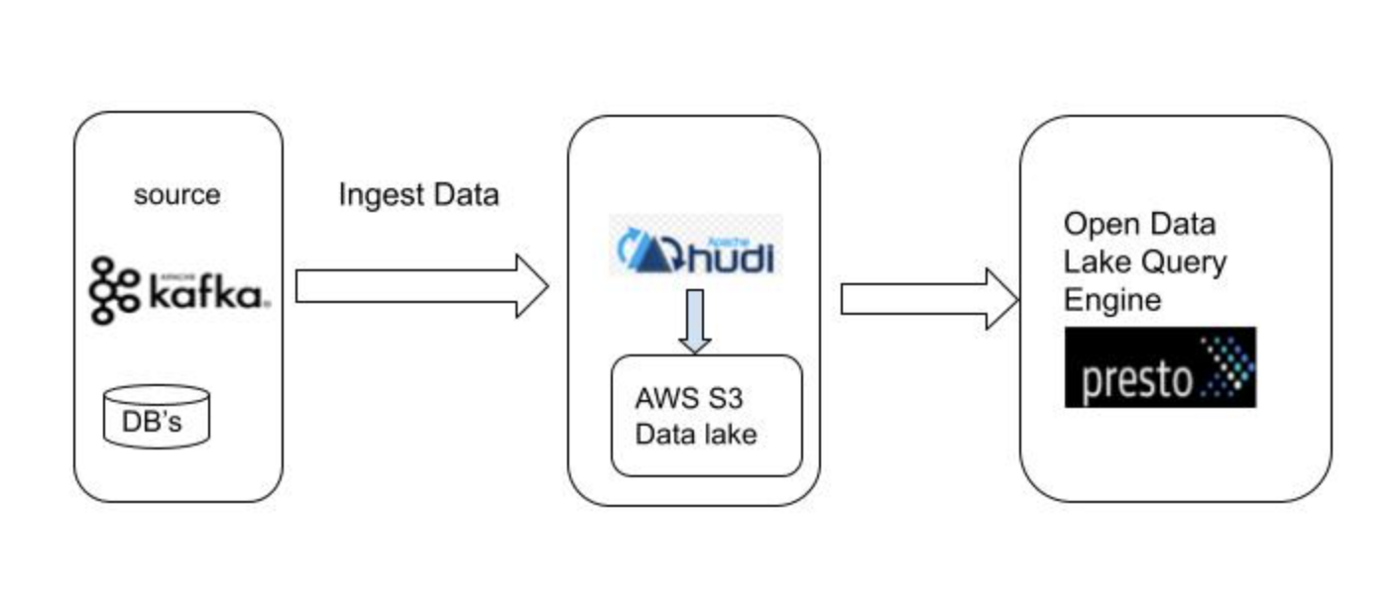
可以从不同来源(例如 Kafka 和其他数据库)在数据湖中摄取数据,通过将 Hudi 引入数据管道,将创建/更新所需的 Hudi 表,并且数据将基于表以 Parquet 或 Avro 格式存储输入 S3 数据湖。稍后 BI 工具/应用程序可以使用 Presto 查询数据,这将在数据更新时反映更新的结果。
结论
开放 Lakehouse 分析栈因其简单性、灵活性、性能和成本而得到越来越广泛的应用。构成该栈的技术至关重要。 Presto 作为数据湖事实上的 SQL 查询引擎,以及 Hudi 的事务支持和变更数据捕获功能,使其成为数据湖分析的强大开源和开放格式解决方案,但缺少的组件是数据湖治理这允许更安全地在 S3 上运行查询。 AWS 最近推出了 Lake Formation,一种用于数据湖的数据治理解决方案和 Ahana,一种 Presto 的托管服务,将 Presto 与 AWS Lake Formation 无缝集成,以在 AWS S3 数据湖上运行交互式查询,并对数据进行细粒度访问。
基于 Apache Hudi + Presto + AWS S3 构建开放Lakehouse的更多相关文章
- 基于Apache Hudi在Google云构建数据湖平台
自从计算机出现以来,我们一直在尝试寻找计算机存储一些信息的方法,存储在计算机上的信息(也称为数据)有多种形式,数据变得如此重要,以至于信息现在已成为触手可及的商品.多年来数据以多种方式存储在计算机中, ...
- 基于 Apache Hudi 和DBT 构建开放的Lakehouse
本博客的重点展示如何利用增量数据处理和执行字段级更新来构建一个开放式 Lakehouse. 我们很高兴地宣布,用户现在可以使用 Apache Hudi + dbt 来构建开放Lakehouse. 在深 ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- 基于 Apache Hudi 极致查询优化的探索实践
摘要:本文主要介绍 Presto 如何更好的利用 Hudi 的数据布局.索引信息来加速点查性能. 本文分享自华为云社区<华为云基于 Apache Hudi 极致查询优化的探索实践!>,作者 ...
- Uber基于Apache Hudi构建PB级数据湖实践
1. 引言 从确保准确预计到达时间到预测最佳交通路线,在Uber平台上提供安全.无缝的运输和交付体验需要可靠.高性能的大规模数据存储和分析.2016年,Uber开发了增量处理框架Apache Hudi ...
- 基于Apache Hudi和Debezium构建CDC入湖管道
从 Hudi v0.10.0 开始,我们很高兴地宣布推出适用于 Deltastreamer 的 Debezium 源,它提供从 Postgres 和 MySQL 数据库到数据湖的变更捕获数据 (CDC ...
- 字节跳动基于Apache Hudi构建EB级数据湖实践
来自字节跳动的管梓越同学一篇关于Apache Hudi在字节跳动推荐系统中EB级数据量实践的分享. 接下来将分为场景需求.设计选型.功能支持.性能调优.未来展望五部分介绍Hudi在字节跳动推荐系统中的 ...
- 基于 Apache Hudi 构建增量和无限回放事件流的 OLAP 平台
1. 摘要 在本博客中,我们将讨论在构建流数据平台时如何利用 Hudi 的两个最令人难以置信的能力. 增量消费--每 30 分钟处理一次数据,并在我们的组织内构建每小时级别的OLAP平台 事件流的无限 ...
- 基于Apache Hudi构建分析型数据湖
为了有机地发展业务,每个组织都在迅速采用分析. 在分析过程的帮助下,产品团队正在接收来自用户的反馈,并能够以更快的速度交付新功能. 通过分析提供的对用户的更深入了解,营销团队能够调整他们的活动以针对特 ...
随机推荐
- 函数式(Functional)接口
public class LambdaTest2 { @Test public void test1(){ happyTime(500, new Consumer<Double>() { ...
- 关于cpu体系架构的一些有趣的故事分享
从排查一次匪夷所思的coredump,引出各种体系架构的差异. 本文中的所有内容来自学习DCC888的学习笔记或者自己理解的整理,如需转载请注明出处.周荣华@燧原科技 1 背景 从全世界有记载的第一台 ...
- 线程池ThreadPoolExector核心ctl, execute, addWorker, reject源码分析
线程池核心方法execute()解析: public void execute(Runnable command) {//#1 if (command == null) throw new NullP ...
- java通过注解顺序通过映射导出excel
import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.ann ...
- 这样优化Spring Boot,启动速度快到飞起!
微服务用到一时爽,没用好就呵呵啦,特别是对于服务拆分没有把控好业务边界.拆分粒度过大等问题,某些 Spring Boot 启动速度太慢了,可能你也会有这种体验,这里将探索一下关于 Spring Boo ...
- 2022-7-25 第七组 pan小堂 多态
多态 多态是继封装.继承之后,面向对象的第三大特性. 现实事物经常会体现出多种形态,如学生,学生是人的一种,则一个具体的同学张三既是学生也是人,即出现两种形态. Java作为面向对象的语言,同样可以描 ...
- maven项目(引入依赖失败, pom.xml 报错\爆红)
引入项目过程中,idea引入磁盘的某个的maven项目 这里以springboot项目以例子,发现pom.xml 的依赖大面积爆红,springboot的版本依赖也报错了,然后发现下面有进度条在下载, ...
- python获取本机的安装所有应用( Windows)
Windows获取本机的安装所有应用 采用操作注册表的方式,理论上其他可通过操作注册表方式的动作均可 import winreg def get_window_software(hive, flag) ...
- Vue 引出声明周期 && 组件的基本使用
1 <!DOCTYPE html> 2 <html> 3 <head> 4 <meta charset="UTF-8" /> 5 & ...
- odoo14 入门解刨关联字段
Odoo中关联字段是用来绑定表与表之间主从关系的. 主从关系指: 首先必须要明白id的存在的意义,它具备"唯一"的属性,也就是表中所有记录中该字段的值不会重复. 假设表A存储是身份 ...