Python 懂车帝综合口碑数据
| 本文所有教程及源码、软件仅为技术研究。不涉及计算机信息系统功能的删除、修改、增加、干扰,更不会影响计算机信息系统的正常运行。不得将代码用于非法用途,如侵立删! |
Python 懂车帝综合口碑数据
需求
懂车帝全系车型综合口碑 优点 缺点 统计数据
操作环境
- win10
- Google nexus5x(root)
- Python3.9
- Charles
需求分析
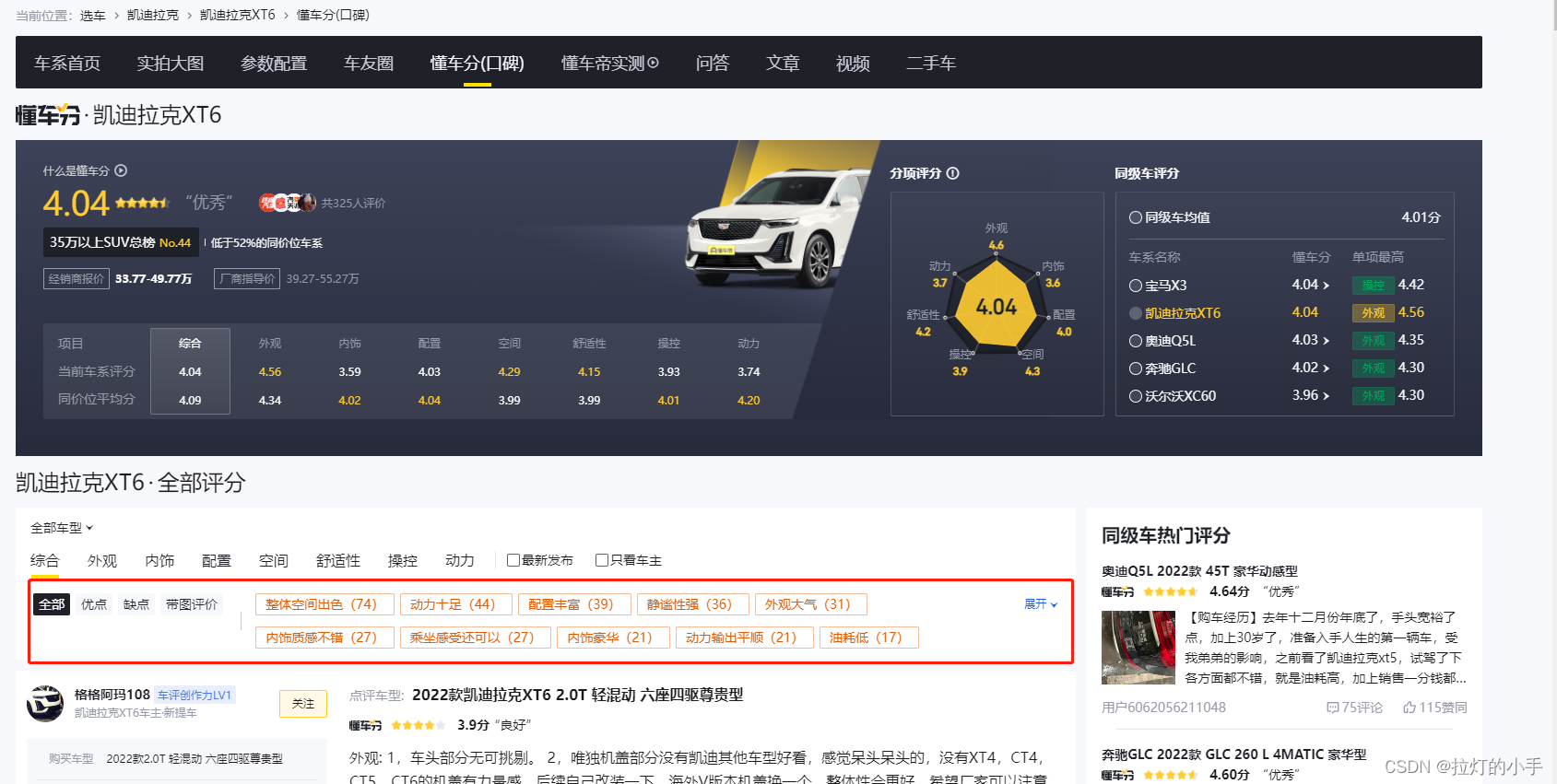
先来web端试下能否找到需要的数据接口,随便找个车型打开口碑页面F12查看Network

根据页面关键词搜索没有找到明显的数据接口,虽然说现在也可以使用request或者selenium直接在页面解析数据,但是毕竟这不是首选方案,还是从APP分析一下在决定用什么方案。
PS:手机环境、抓包环境的配置在这不在赘述,有兴趣的可参考之前的文章 APP抓包环境配置
下载懂车帝APP,并安装至手机

手机开启Postern,pc打开charles
至此抓包工作准备完成,打开懂车帝APP,随便找个车型进入懂车分页面

还是老套路先根据页面关键词搜索一波

明显看出来后两条数据不是需要的,前四条是同一个接口返回的,应该就是需要的数据,双击点进去看一下详细数据

初步查看和页面数据是一致的,看数据结构和具体的数值和页面中的数据很像,Charles界面太小,将数据拷贝至网页中解析,方便分析,分享一个常用的json数据在线解析网站
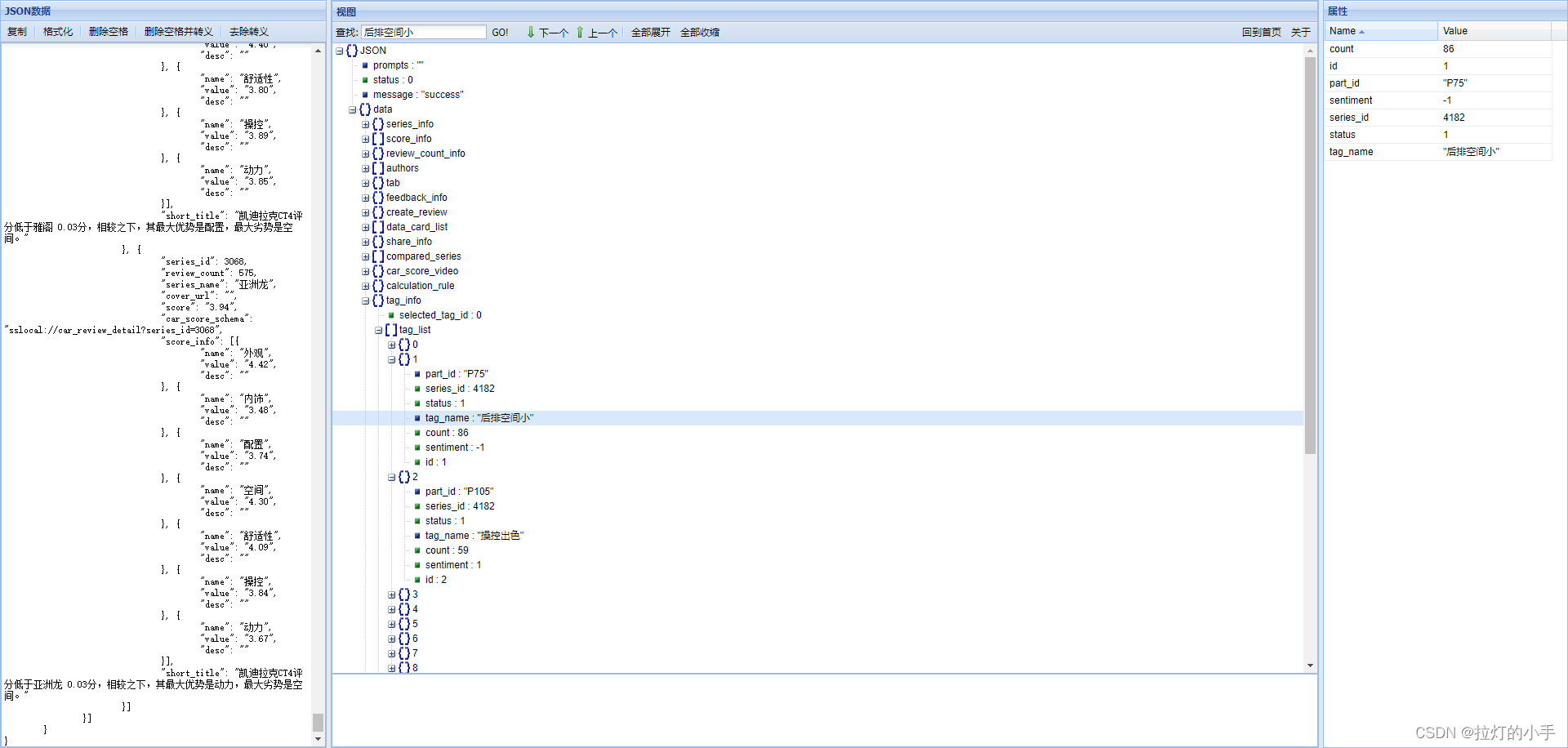
经过仔细对比页面中的数据,发现此接口就是我们需要的
综合口碑接口:
https://*******/get_detail/?series_id=4182&car_id=0&only_owner=0&year_id=all&iid=2467735824764398&device_id=40011211486215&ac=wifi&channel=dcd-yd-11zh-and-74&aid=36&app_name=automobile&version_code=693&version_name=6.9.3&device_platform=android&os=android&ab_client=a1%2Cc2%2Ce1%2Cf2%2Cg2%2Cf7&ab_group=3167590%2C3577236%2C3333988&ssmix=a&device_type=Nexus+5X&device_brand=google&language=zh&os_api=27&os_version=8.1.0&manifest_version_code=693&resolution=1080*1794&dpi=420&update_version_code=6931&_rticket=1648907286543&cdid=f3163204-7faf-45d7-89c4-e82215c3216c&city_name=%E8%81%8A%E5%9F%8E&gps_city_name=%E8%81%8A%E5%9F%8E&selected_city_name&rom_version=27&longi_lati_type=1&longi_lati_time=1648907102913&content_sort_mode=0&total_memory=1.77&cpu_name=Qualcomm+Technologies%2C+Inc+MSM8992&overall_score=4.873&cpu_score=4.8872&host_abi=
对!你没看错,就是这么长,验证一下数据接口,在网页中直接请求一下这个url

这儿推荐安装一个网页json可视化的插件,这儿偷懒没装,在线解析了一下json数据,和Charles抓到的数据是一样,经过分析得知: series_id是车系id,修改此参数即可
获取全部车系id
获取车系id就很简单了,先拿到品牌id然后根据品牌id请求车系信息,注意这是一个post接口
def get_series(self, brand_id):
"""
获取品牌所有车系
brand_id:品牌id
"""
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'}
param = {
'offset': 0,
'limit': 1000,
'is_refresh': 1,
'city_name': '北京',
'brand': brand_id
}
response = requests.post(url=url, data=param, headers=headers)
rep_json = json.loads(response.text)
# print(response.text)
if rep_json['status'] == 'success':
return rep_json['data']['series']
else:
raise Exception("get car series has exception!")

获取车系综合口碑评分
def get_score(self, series_id):
"""
获取车系综合评分
series_id: 车系id
"""
response = self._parse_url(url).json()
tag_list = response.get('data').get('tab_info').get('tag_list')
data = list()
# 优点
merits = [i.get('tag_name')+"("+str(i.get('count'))+")" for i in tag_list if i.get('sentiment') == 1]
data.append(merits)
# 缺点
defects = [i.get('tag_name')+"("+str(i.get('count'))+")" for i in tag_list if i.get('sentiment') == -1]
data.append(defects)
return data
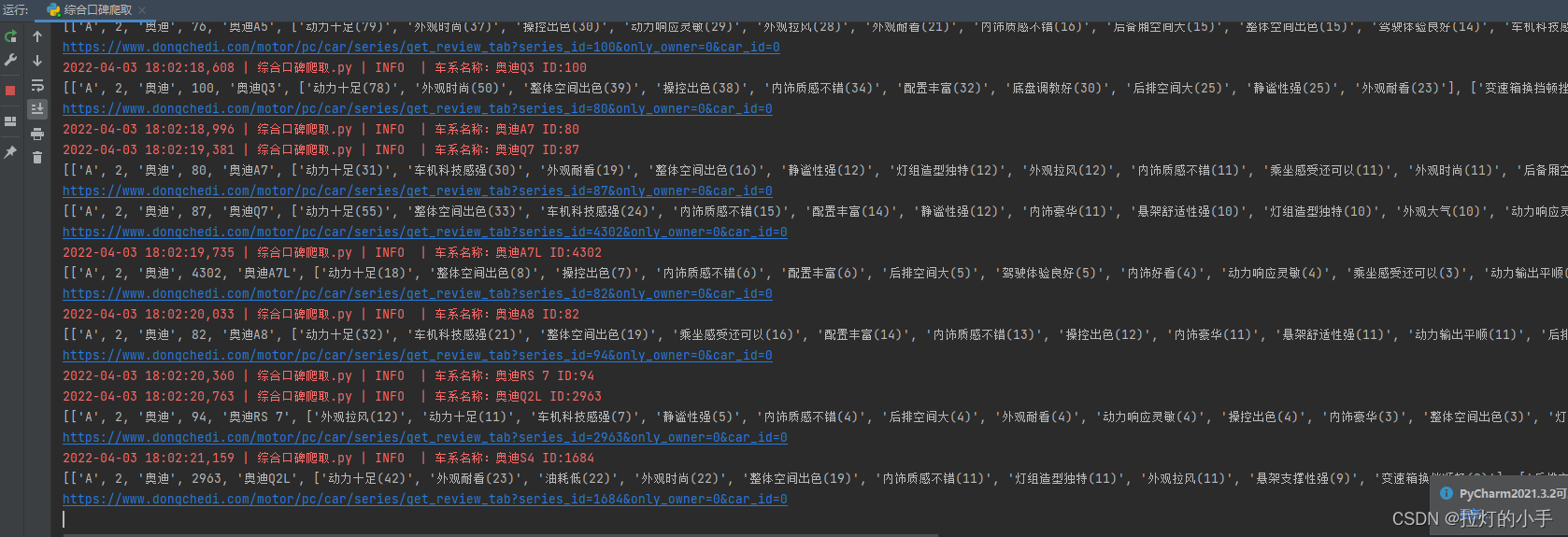
运行效果

资源下载
https://download.csdn.net/download/qq_38154948/85073968
| 本文仅供学习交流使用,如侵立删! |
Python 懂车帝综合口碑数据的更多相关文章
- 【原创】Python 懂车帝口碑爬虫
本文所有教程及源码.软件仅为技术研究.不涉及计算机信息系统功能的删除.修改.增加.干扰,更不会影响计算机信息系统的正常运行.不得将代码用于非法用途,如侵立删! 懂车帝综合口碑 需求 操作环境 win1 ...
- Python 懂车帝口碑分爬虫
本文所有教程及源码.软件仅为技术研究.不涉及计算机信息系统功能的删除.修改.增加.干扰,更不会影响计算机信息系统的正常运行.不得将代码用于非法用途,如侵立删! Python 懂车帝口碑分爬虫 需求 懂 ...
- Python 懂车帝全车系销量排行榜
本文所有教程及源码.软件仅为技术研究.不涉及计算机信息系统功能的删除.修改.增加.干扰,更不会影响计算机信息系统的正常运行.不得将代码用于非法用途,如侵立删! Python 懂车帝全车系销量排行榜 需 ...
- Python 爬取汽车之家口碑数据
本文仅供学习交流使用,如侵立删!联系方式见文末 汽车之家口碑数据 2021.8.3 更新 增加用户信息参数.认证车辆信息等 2021.3.24 更新 更新最新数据接口 2020.12.25 更新 添加 ...
- 手把手教你使用Python爬取西刺代理数据(下篇)
/1 前言/ 前几天小编发布了手把手教你使用Python爬取西次代理数据(上篇),木有赶上车的小伙伴,可以戳进去看看.今天小编带大家进行网页结构的分析以及网页数据的提取,具体步骤如下. /2 首页分析 ...
- Python抓取国家医疗费用数据:国家名、人均开销
前言 整个世界正被大流行困扰着,不同国家拿出了不同的应对策略,也取得了不同效果.这也是本文的脑洞来源,打算研究一下各国在医疗基础设置上的开支,对几个国家的医疗费用进行数据可视化. 由于没有找到最近一年 ...
- 【可视化分析案例】用python分析B站Top100排行榜数据
一.数据源 之前,我分享过一期爬虫,用python爬取Top100排行榜: 最终数据结果,是这样的: 在此数据基础上,做python可视化分析. 二.数据读取 首先,读取数据源: # 读取csv数据 ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 使用 Python 抓取欧洲足球联赛数据
Web Scraping在大数据时代,一切都要用数据来说话,大数据处理的过程一般需要经过以下的几个步骤 数据的采集和获取 数据的清洗,抽取,变形和装载 数据的分析,探索和预测 ...
随机推荐
- 通过python将阿里云DNS解析作为DDNS使用
通过python将阿里云DNS解析作为DDNS使用 脚本需要Python2.x运行 安装alidns python sdk sudo pip install aliyun-python-sdk-ali ...
- 词云图value传递数据不显示(已解决)
问题描述: 今天在做词云图时,虽然词云图能够展现出来,但是后台传递过来的数据(每个词出现的次数)却不显示. 错误原因: 错误的将tooltip写在了series内部,如图: 解决方案: 将toolti ...
- Python <算法思想集结>之初窥基础算法
1. 前言 数据结构和算法是程序的 2 大基础结构,如果说数据是程序的汽油,算法则就是程序的发动机. 什么是数据结构? 指数据在计算机中的存储方式,数据的存储方式会影响到获取数据的便利性. 现实生活中 ...
- Navicat破解激活流程
Navicat Navicat Premium 是一套数据库开发工具,让你从单一应用程序中同时连接 MySQL.MariaDB.MongoDB.SQL Server.Oracle.Postg ...
- ACM 刷题记录
HDU Multi-University Training Contest 题目来源 题目 知识点 时间复杂度 完成情况 2019 Contest8 A Acesrc and Cube Hyperne ...
- Spring IOC源码研究笔记(2)——ApplicationContext系列
1. Spring IOC源码研究笔记(2)--ApplicationContext系列 1.1. 继承关系 非web环境下,一般来说常用的就两类ApplicationContext: 配置形式为XM ...
- 设置C#启动进程但不显示命令行窗口
设置一下Process类型相关的配置属性即可,直接上代码. //记得引入命名空间 //using System.Diagnostics; //获得当前环境的基路径 string basePath = ...
- 如何优雅的使用MyBatis?
本文目录 什么是 MyBatis ? 映射器(mappers) typeAliases 类型别名减少类完全限制名的冗余 处理枚举类型 多行插入 重用 SQL 代码段,消除重复 字符串替换#{}和${ ...
- Windows家庭版-添加Hyper-V
新建一个hyper-v.cmd文件,内容为 pushd "%~dp0" dir /b %SystemRoot%\servicing\Packages\*Hyper-V*.mum & ...
- idea中一些常用的快捷键
ctrl+shift+alt:多行操作psvm:生成main()方法:fori:生成for循环:Ctrl+Alt+v:自动补齐返回值类型ctrl+o:覆写方法ctrl+i:实现接口中的方法ctrl+s ...