Numpy库基础___五
Numpy数据存取
•NumPy的随机数函数
 a = np.random.rand(1,2,3)
a = np.random.rand(1,2,3)
print(a)
#[[[0.03339719 0.72784732 0.47527802]
# [0.6456671 0.65639799 0.01300073]]] a = np.random.randn(1,2,3)
print(a)
#[[[ 0.59115211 -0.40289048 1.34532466]
# [-0.04616715 -0.64066822 -1.09722129]]] a = np.random.randint(100,200,(3,4))
print(a)
#[[161 131 187 134]
# [156 114 104 180]
# [182 163 158 121]] #随机数种子,10是给定的种子值
np.random.seed(10)
a = np.random.randint(100,200,(3,4))
print(a)
#[[109 115 164 128]
# [189 193 129 108]
# [173 100 140 136]]
a = np.random.randint(100,200,(3,4))
print(a)
#[[184 199 152 144]
# [173 171 179 144]
# [133 105 197 143]] np.random.shuffle(a)
print(a)
#[[173 171 179 144]
# [133 105 197 143]
# [184 199 152 144]] b = np.random.permutation(a)
#[[173 171 179 144]
# [133 105 197 143]
# [184 199 152 144]]
print(b)
#[[133 105 197 143]
# [173 171 179 144]
# [184 199 152 144]] a = np.random.randint(100,200,(8,))
print(a)
#[131 195 130 165 177 107 197 132] b = np.random.choice(a,(3,2))
print(b)
#[[195 107]
# [177 197]
# [130 107]] b = np.random.choice(a,(3,2),replace=False)
#[[107 130]
# [197 132]
# [195 131]] #加权,元素出现次数越多,被抽取的概率越高
b = np.random.choice(a,(3,2),p=a/np.sum(a))
print(b)
#[[197 130]
# [131 130]
# [131 130]]
u = np.random.uniform(0,10,(3,4))
print(u)
#[[7.49328353 4.35990777 8.19266316 5.02229727]
# [2.21122875 9.61785352 9.90294149 2.44401573]
# [3.88367203 9.22037768 7.87306998 2.00241521]] u = np.random.normal(10,5,(3,4))
print(u)
#[[13.44007699 10.5502136 14.79616224 -2.17381553]
# [10.42238979 10.12351539 2.8561042 16.78322252]
# [11.90679396 6.75343566 8.01259211 14.96874378]] u = np.random.poission(2,(3,4))
print(u)
#[[4 0 1 2]
# [2 2 3 2]
# [0 0 2 3]]
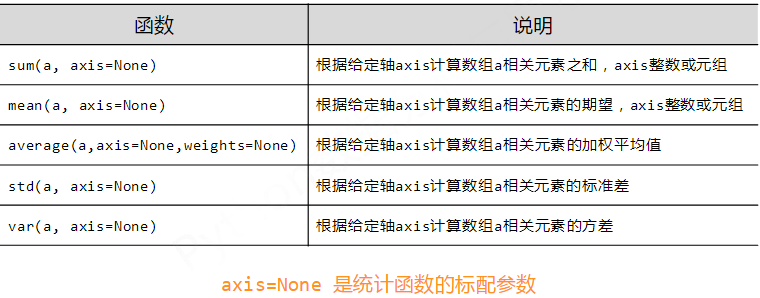
•NumPy的统计函数
a = np.arange(15).reshape(3,5)
print(a)
#[[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# [10 11 12 13 14]]
print(np.sum(a))
#105
print(np.sum(a,axis=0))
#[15 18 21 24 27]
print(np.sum(a,axis=1))
#[10 35 60] print(np.mean(a))
#7.0
print(np.mean(a,axis=0))
#[5. 6. 7. 8. 9.]
print(np.mean(a,axis=1))
#[ 2. 7. 12.] print(np.average(a))
#7.0
print(np.average(a,axis=0,weights=[1,2,3]))
#[ 6.66666667 7.66666667 8.66666667 9.66666667 10.66666667]
a = np.arange(12).reshape(3,4)
print(a)
#[[ 0 1 2 3]
# [ 4 5 6 7]
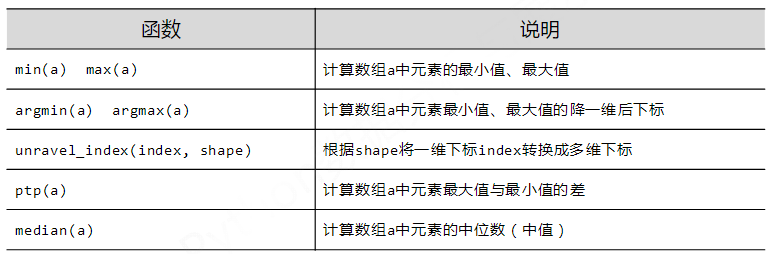
# [ 8 9 10 11]] print(np.min(a))
#0 print(np.max(a))
#11 print(np.argmin(a))
#0 print(np.argmax(a))
#11 print(np.unravel_index(10,(4,3)))
#(3,1) print(np.unravel_index(np.argmax(a),(4,3)))
#(3,2) print(np.ptp(a))
#11 print(np.median(a))
#5.5
•NumPy的梯度函数
- np.gradient(f):计算数组f中元素的梯度,当f为多维时,返回每个维度梯度
梯度:连续值之间的变化率,即斜率
X坐标轴连续三个x坐标对应的Y轴值:a,b,c其中b的梯度时(c-a)/2
a = np.random.randint(0,20,(5,))
print(a)
#[ 2 10 11 14 12] print(np.gradient(a))
#[ 8. 4.5 2. 0.5 -2. ]




Numpy库基础___五的更多相关文章
- Numpy库基础___四
Numpy数据存取 •数据的csv文件的存取 只能有效存取和读取一维和二维数据 a = np.arange(100).reshape(5,20) #用delimiter分割,默认为空格 np.save ...
- Numpy库基础___一
ndarray一个强大的N维数组对象Array •ndarray的建立(元素默认浮点数) 可以利用list列表建立ndarray import numpy as np list =[0,1,2,3] ...
- Numpy库基础___三
ndarray一个强大的N维数组对象Array •ndarray的操作 索引 a = np.arange(24).reshape((2,3,4)) print(a) #[[[ 0 1 2 3] # [ ...
- Numpy库基础___二
ndarray一个强大的N维数组对象Array •ndarray的变换 x.reshape(shape)重塑数组的shape,要求元素的个数一致,不改变原数组 x = np.ones((2,3,4), ...
- Numpy库的学习(五)
今天继续学习一下Numpy库,废话不多说,整起走 先说下Numpy中,经常会犯错的地方,就是数据的复制 这个问题不仅仅是在numpy中有,其他地方也同样会出现 import numpy as np a ...
- $python数据分析基础——初识numpy库
numpy库是python的一个著名的科学计算库,本文是一个quickstart. 引入:计算BMI BMI = 体重(kg)/身高(m)^2 假如有如下几组体重和身高数据,让求每组数据的BMI值: ...
- Python基础——numpy库的使用
1.numpy库简介: NumPy提供了许多高级的数值编程工具,如:矩阵数据类型.矢量处理,以及精密的运算库.专为进行严格的数字处理而产生. 2.numpy库使用: 注:由于深度学习中存在大量的 ...
- 数据分析与科学计算可视化-----用于科学计算的numpy库与可视化工具matplotlib
一.numpy库与matplotlib库的基本介绍 1.安装 (1)通过pip安装: >> pip install matplotlib 安装完成 安装matplotlib的方式和nump ...
- numpy库的学习笔记
一.ndarray 1.numpy 库处理的最基础数据类型是由同种元素构成的多维数组(ndarray),简称“数组”. 2.ndarray是一个多维数组的对象,ndarray数组一般要求所有元素类型相 ...
随机推荐
- SpringDataJpa打印Sql详情(含参数)
Spring Data Jpa打印Sql详情(带sql参数) 这里使用的是 log4jdbc,yml配置文件里的数据源配置也要做相应的修改 pom文件引入 <dependency> < ...
- 继承及属性查找+super()和mro()+多态
继承及属性查找+super()和mro()+多态 一. ★继承 1. 什么是继承? 继承就是新建类的一种方式,新建的类我们称为子类或者叫派生类,被继承的类我们称为父类或者基类 子类可以使用父类中的属性 ...
- 《PHP程序员面试笔试宝典》——什么是职场暗语?
本文摘自<PHP程序员面试笔试宝典> 文末有该书电子版下载. 随着求职大势的变迁发展,以往常规的面试套路因为过于单调.简明,已经被众多"面试达人"们挖掘出了各种&quo ...
- Solution -「CF 1025D」Recovering BST
\(\mathcal{Description}\) Link. 给定序列 \(\{a_n\}\),问是否存在一棵二叉搜索树,使得其中序遍历为 \(\{a_n\}\),且相邻接的两点不互素. ...
- C# 不区分大小写替换文本
C# .NET类库自带的str.Replace() 方法替换文本不能区分大小写.我们可以自己编写一个扩展方法,支持文本忽略大小写替换.以下扩展方法实现了使用正则表达式忽略大小写替换文本. public ...
- Intellij IDEA出现java.lang.ClassNotFoundException: com.mysql.jdbc.Driver处理办法
菜单-->File-->project structure-->Modules-->Dependencies-->添加MySQL的驱动包:mysql-connector- ...
- 五、MyBatis缓存初体验
缓存就是内存中的数据,常常来自对数据库查询结果的保存,使用缓存, 我们可以避免频繁的与数据库进行交互, 进而提高响应速度. 一级缓存初体验(session,默认打开) 同一查询执行两次以上:selec ...
- kafka在linux下安装
简介 Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据. 相关术语(参考百度百科) Broker Kafka集群包含一个或多个服务器,这种服务器被称为brok ...
- SQL SERVER 学习过程(一)
还记得以前在学校的学习过数据库SQL SERVER 2008 R2 的教程,从学校毕业出来后的哪家单位基本没怎么使用过数据库,现在也忘得差不多了 做些相关的练习熟悉熟悉 --创建数据库-- creat ...
- 【C# Task】 ValueTask/Task<TResult>
概要 1.如果异步方法的使用者使用 Task.WhenAll 或 Task.WhenAny,则在异步方法中使用 ValueTask<T> 作为返回类型可能会产生高昂的成本.这是因为您需要使 ...