Mybatis——一级缓存与二级缓存
关于Mybatis的学习主要参考了狂神的视频
一级缓存
(1).使用范围:从sqlSession会话开始到结束
(2).使用:默认打开,无法关闭
(3).测试使用(需要打开日志观察数据库的连接情况):
public static void Maintest(){
SqlSession sqlSession = Connection.getSqlSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
HashMap map = new HashMap();
map.put("UId","3180421016");
List<UserBean> userBeans = userMapper.queryByIf(map);
map.put("UName","关晨亮");
//userMapper.updateById(map);
System.out.println(userMapper.queryByIf(map).get(0).equals(userBeans.get(0)));
sqlSession.close();
}
//result:true,将结果集打印,可以看出两次结果集打印之间是没有再做数据库连接的
(4).缓存失效的4种情况:
sqlSession不同
public static void Maintest(){
SqlSession sqlSession1 = Connection.getSqlSession();
SqlSession sqlSession2 = Connection.getSqlSession();
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class);
UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class);
HashMap map = new HashMap();
map.put("UId","3180421016");
List<UserBean> userBeans = userMapper1.queryByIf(map);
System.out.println(userBeans);
sqlSession1.close();
System.out.println(userBeans.get(0).equals(userMapper2.queryByIf(map).get(0)));
sqlSession2.close();
}
sqlSession相同,两次查询操作之间存在增删改操作
public static void Maintest(){
SqlSession sqlSession = Connection.getSqlSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
HashMap map = new HashMap();
map.put("UId","3180421016");
List<UserBean> userBeans = userMapper.queryByIf(map);
map.put("UName","关晨亮");
userMapper.updateById(map);
System.out.println(userMapper.queryByIf(map).get(0).equals(userBeans.get(0)));
sqlSession.close();
} //result:false,将结果集打印,可以看出两次结果集打印之间是有再次做过数据库连接的
sqlSession相同,查询条件不同(此时缓存中没有相关数据)
public static void Maintest(){
SqlSession sqlSession1 = Connection.getSqlSession();
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class);
HashMap map = new HashMap();
map.put("UId","3180421016");
List<UserBean> userBeans = userMapper1.queryByIf(map);
System.out.println(userBeans);
map.put("UId","2");
userBeans = userMapper1.queryByIf(map);
System.out.println(userBeans);
sqlSession1.close();
}
//打开日志可以看到,发生了两次对于数据库的连接请求
通过session.clearCache()主动刷新缓存
public static void Maintest(){
SqlSession sqlSession1 = Connection.getSqlSession();
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class);
HashMap map = new HashMap();
map.put("UId","3180421016");
List<UserBean> userBeans = userMapper1.queryByIf(map);
System.out.println(userBeans);
sqlSession1.clearCache();
userBeans = userMapper1.queryByIf(map);
System.out.println(userBeans);
sqlSession1.close();
}
二级缓存
(1).简介
- 作用范围:整个namespace,也就是一个mapper
- 实现:不同的mapper查出的数据会放在对应的缓存(map)中
(2).使用:
- 在主配置文件中显式地开启二级缓存
<settings>
<!-- <setting name="logImpl" value="LOG4J"/>-->
<setting name="logImpl" value="STDOUT_LOGGING"/>
<setting name="cacheEnabled" value="true"/>
</settings>
- 在Mapper.xml中配置(为什么要开启readOnly会在后面解释)
<cache readOnly="true"/>
或
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
- 测试
public static void Maintest(){
SqlSession sqlSession1 = Connection.getSqlSession();
SqlSession sqlSession2 = Connection.getSqlSession();
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class);
UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class);
HashMap map = new HashMap();
map.put("UId","3180421016");
List<UserBean> userBeans = userMapper1.queryByIf(map);
sqlSession1.close();
System.out.println(userBeans.get(0).equals(userMapper2.queryByIf(map).get(0)));
sqlSession2.close();
}
/result:true
(3).注意
- 需要实体序列化
客户端访问了某个能开启会话功能的资源, web服务器就会创建一个与该客户端对应的HttpSession对象,每个HttpSession对象都要站用一定的内存空间。如果在某一时间段内访问站点的用户很多,web服务器内存中就会积累大量的HttpSession对象,消耗大量的服务器内存,即使用户已经离开或者关闭了浏览器,web服务器仍要保留与之对应的HttpSession对象,在他们超时之前,一直占用web服务器内存资源。
web服务器通常将那些暂时不活动但未超时的HttpSession对象转移到文件系统或数据库中保存,服务器要使用他们时再将他们从文件系统或数据库中装载入内存,这种技术称为Session的持久化。
将HttpSession对象保存到文件系统或数据库中,需要采用序列化的方式将HttpSession对象中的每个属性对象保存到文件系统或数据库中;将HttpSession对象从文件系统或数据库中装载如内存时,需要采用反序列化的方式,恢复HttpSession对象中的每个属性对象。所以存储在HttpSession对象中的每个属性对象必须实现Serializable接口
public class UserBean implements Serializable {
private String UId;
private String UName;
private int USet;
private int UAuth;
private String UPassword;
private int UState;
}
- 必须打开只读,否则两次比较的结果不同
只读的缓存会给所有调用者返回缓存对象的相同实例。 因此这些对象不能被修改。这就提供了可观的性能提升。而可读写的缓存会(通过序列化)返回缓存对象的拷贝。 速度上会慢一些,但是更安全,因此默认值是 false。
<cache readOnly="true"/>
缓存优先放在以及会话中,当会话关闭后,缓存才会被转移到二级会话
public static void Maintest(){
SqlSession sqlSession1 = Connection.getSqlSession();
SqlSession sqlSession2 = Connection.getSqlSession();
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class);
UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class);
HashMap map = new HashMap();
map.put("UId","3180421016");
List<UserBean> userBeans = userMapper1.queryByIf(map);
System.out.println(userBeans);
System.out.println(userBeans.get(0).equals(userMapper2.queryByIf(map).get(0)));
sqlSession1.close();
sqlSession2.close();
}
//false,因为还没有关闭就开始比较了
public static void Maintest(){
SqlSession sqlSession1 = Connection.getSqlSession();
SqlSession sqlSession2 = Connection.getSqlSession();
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class);
UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class);
HashMap map = new HashMap();
map.put("UId","3180421016");
List<UserBean> userBeans = userMapper1.queryByIf(map);
System.out.println(userBeans);
sqlSession1.close();
System.out.println(userBeans.get(0).equals(userMapper2.queryByIf(map).get(0)));
sqlSession2.close();
}
//true,因为是会话关闭之后再比较的
对于查询(select),我们可以使用useCache来选择是否取消缓存;对于增删改,可以使用flushCache来选择是否取消更新缓存
缓存原理,这边用狂神的图来加深理解
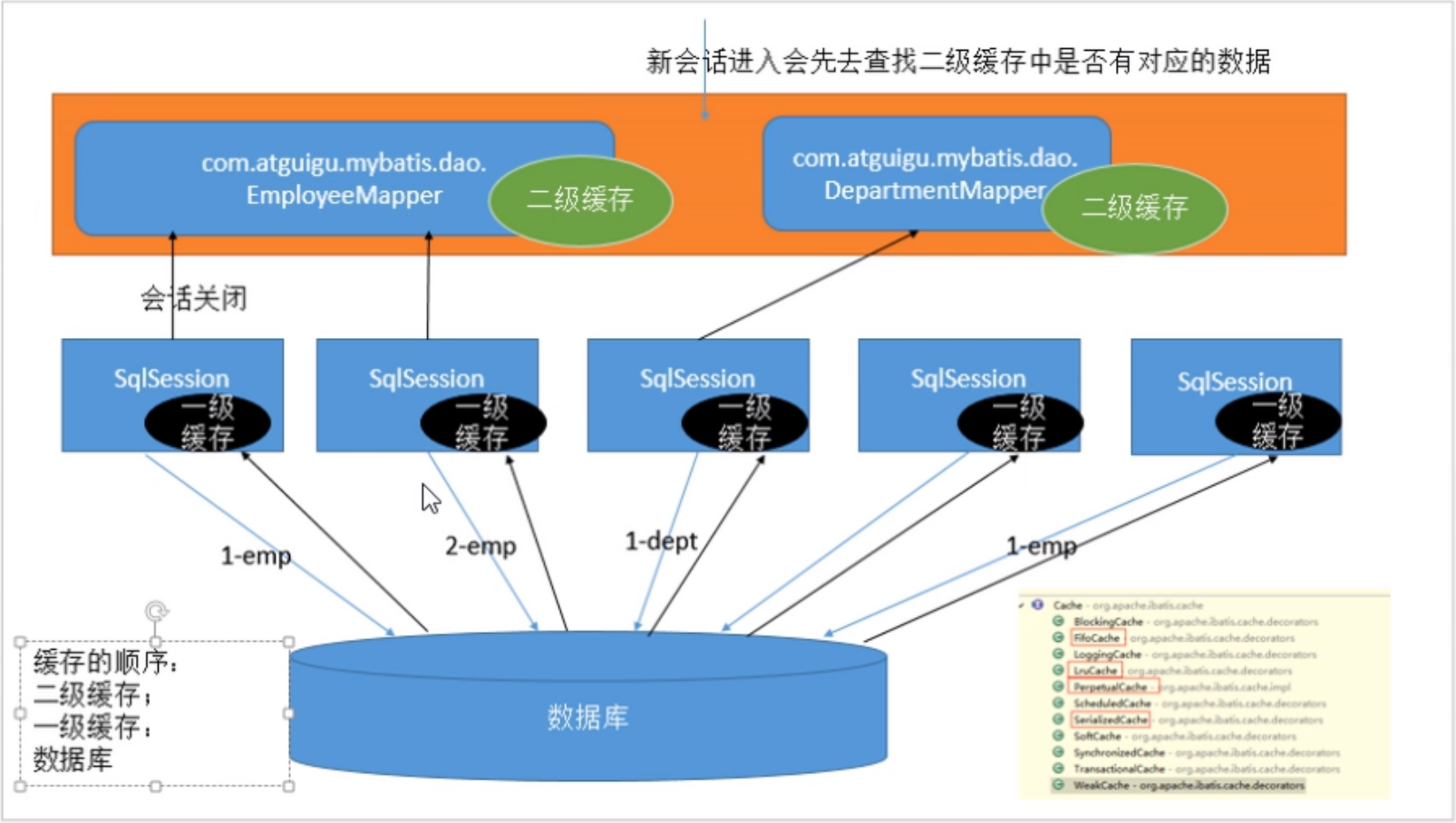
使用ehcache外部缓存
(1).导包
(2).写配置文件.xml
(3).在主配置文件中使用:设定cache标签的type属性
注:现在多用redis数据库
Mybatis——一级缓存与二级缓存的更多相关文章
- [原创]关于mybatis中一级缓存和二级缓存的简单介绍
关于mybatis中一级缓存和二级缓存的简单介绍 mybatis的一级缓存: MyBatis会在表示会话的SqlSession对象中建立一个简单的缓存,将每次查询到的结果结果缓存起来,当下次查询的时候 ...
- MyBatis 延迟加载,一级缓存,二级缓存设置
什么是延迟加载 resultMap中的association和collection标签具有延迟加载的功能. 延迟加载的意思是说,在关联查询时,利用延迟加载,先加载主信息.使用关联信息时再去加载关联信息 ...
- mybatis高级(3)_延迟加载_深度延迟_一级缓存_二级缓存
设置延迟加载需要在mybatis.xml中设置 注: 侵入式延迟加载为真时是延迟加载 侵入式延迟加载为假时是深度延迟加载 <!-- 延迟加载和深度延迟加载 --> <settings ...
- 9.Mybatis一级缓存和二级缓存
所谓的缓存呢?其实原理很简单,就是在保证你查询的数据是正确的情况下,没有去查数据库,而是直接查找的内存,这样做有利于缓解数据库的压力,提高数据库的性能,Mybatis中有提供一级缓存和二级缓存. 学习 ...
- 八 mybatis查询缓存(一级缓存,二级缓存)和ehcache整合
1 查询缓存 1.1 什么是查询缓存 mybatis提供查询缓存,用于减轻数据压力,提高数据库性能. mybaits提供一级缓存,和二级缓存.
- myBatis学习(9):一级缓存和二级缓存
正如大多数持久层框架一样,MyBatis同样提供了一级缓存和二级缓存的支持 1. MyBatis一级缓存基于PerpetualCache的HashMap本地缓存,其存储作用域为 Session,默认情 ...
- mybatis 详解(九)------ 一级缓存、二级缓存
上一章节,我们讲解了通过mybatis的懒加载来提高查询效率,那么除了懒加载,还有什么方法能提高查询效率呢?这就是我们本章讲的缓存. mybatis 为我们提供了一级缓存和二级缓存,可以通过下图来理解 ...
- MyBatis从入门到放弃六:延迟加载、一级缓存、二级缓存
前言 使用ORM框架我们更多的是使用其查询功能,那么查询海量数据则又离不开性能,那么这篇中我们就看下mybatis高级应用之延迟加载.一级缓存.二级缓存.使用时需要注意延迟加载必须使用resultMa ...
- Mybatis第八篇【一级缓存、二级缓存、与ehcache整合】
Mybatis缓存 缓存的意义 将用户经常查询的数据放在缓存(内存)中,用户去查询数据就不用从磁盘上(关系型数据库数据文件)查询,从缓存中查询,从而提高查询效率,解决了高并发系统的性能问题. myba ...
- MyBatis 一级缓存,二级缓存,延迟加载设置
1 什么是延迟加载 resultMap中的association和collection标签具有延迟加载的功能. 延迟加载的意思是说,在关联查询时,利用延迟加载,先加载主信息.使用关联信息时再 ...
随机推荐
- MLlib学习——基本数据类型
数据类型--基于RDD的API 本地矢量 标记点 本地矩阵 分布式矩阵 RowMatrix(行矩阵) IndexedRowMatrix(索引行矩阵) CoordinateMatrix(坐标矩阵) Bl ...
- 垃圾陷阱 && [NOIP2014 提高组] 飞扬的小鸟
#include<bits/stdc++.h> using namespace std; int d,n,dp[1010]; struct node{int t,f,h;} a[1010] ...
- 关于基于GDAL库QT软件平台下C++语言开发使用说明
背景前提 地理空间数据抽象库(GDAL)是一个用于读取和编写栅格和矢量地理空间数据格式的计算机软件库,由开源地理空间基金会在许可的X / MIT风格免费软件许可下发布. 作为一个库,它为调用应用程序提 ...
- 《PHP程序员面试笔试宝典》——如何准备集体面试?
本文摘自<PHP程序员面试笔试宝典>. PHP面试技巧分享,PHP面试题,PHP宝典尽在"琉忆编程库". 集体面试也被称为群面.无领导小组面试.由于计算机发展至今,软件 ...
- Solution -「LOJ #150」挑战多项式 ||「模板」多项式全家桶
\(\mathcal{Description}\) Link. 给定 \(n\) 次多项式 \(F(x)\),在模 \(998244353\) 意义下求 \[G(x)\equiv\left\{ ...
- 今天你花里胡哨了吗 --- 定制属于自己的linux ssh迎宾信息
请开始你的表演 linux-oz6w:~ # cat << 'eof' > /etc/profile.d/ssh-login-info.sh #!/bin/sh # 输出一个图像 e ...
- Argo workflow 案例练习和配置详细解析
参数化 - parameters hello-world-parameters.yaml文件解析 apiVersion: argoproj.io/v1alpha1 kind: Workflow met ...
- Wireshark教程之数据包操作
实验目的 1.工具介绍 2.主要应用 实验原理 1.网络管理员用来解决网络问题 2.网络安全工程师用来检测安全隐患 3.开发人员用来测试执行情况 4.学习网络协议 实验内容 1.工具基本使用 2.快速 ...
- 【缓存】CPU高速缓存 之MESI 性协议 Gif 动画
CPU缓存架构 不同的CPU厂商的架构也有些不同,在这里只介绍流行的缓存架构 缓存一致性可以分为三个点: 在进程每个写入运算时都立刻采取措施保证资料一致性 每个独立的运算,假如它造成资料值的改变,所有 ...
- startActivityForResult跳转后回调数据
从AActivity向BActivity跳转后,关闭BActivity并向AActivity回调一些数据: 建立AActivity.java文件: 1 public class AActivity e ...