森林野火故事2.0:一眼看穿!使用 Panel 和 hvPlot 可视化 ⛵

作者:韩信子@ShowMeAI
数据分析实战系列:https://www.showmeai.tech/tutorials/40
本文地址:https://www.showmeai.tech/article-detail/335
声明:版权所有,转载请联系平台与作者并注明出处
收藏ShowMeAI查看更多精彩内容
Panel 是 Python 中一个非常棒的可以用作制作数据仪表板的工具库,基于它可以轻松构建数据可视化看板。

在本篇内容中,ShowMeAI 综合 Python 可视化与呈现技能,使用 Panel 制作一个仪表盘看板,可以交互查看美国野火记录的信息。
导入工具库
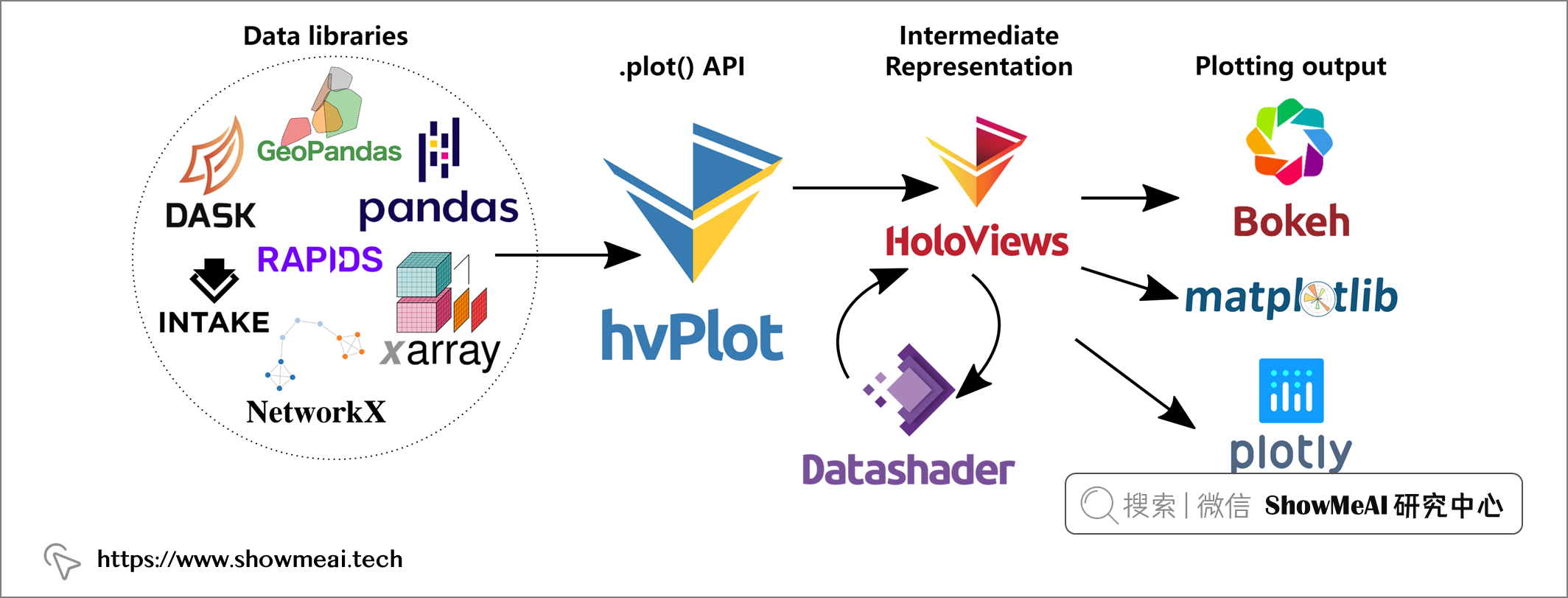
我们本次需要用到的工具库包括数据库工具、Python 数据处理工具、可视化工具和看板工具,我们先把这些工具库导入,代码如下:
# 数据库
import sqlite3
# 数据处理
import numpy as np
import pandas as pd
# 可视化与仪表盘
import holoviews as hv
import colorcet as cc
import panel as pn
from holoviews.element.tiles import EsriImagery
from datashader.utils import lnglat_to_meters
import hvplot.pandas
hv.extension('bokeh')
数据准备
用于本次可视化的数据集包含 1992 年至 2015 年间在美国发生的超过 180 万起野火。美国野火数据集可以在 ShowMeAI 的百度网盘地址下载。
实战数据集下载(百度网盘):公✦众✦号『ShowMeAI研究中心』回复『实战』,或者点击 这里 获取本文 [28]基于Panel和hvPlot的可视化交互看板实战案例 『美国野火 FPA_FOD_20170508.sqlite 数据集』
ShowMeAI官方GitHub:https://github.com/ShowMeAI-Hub
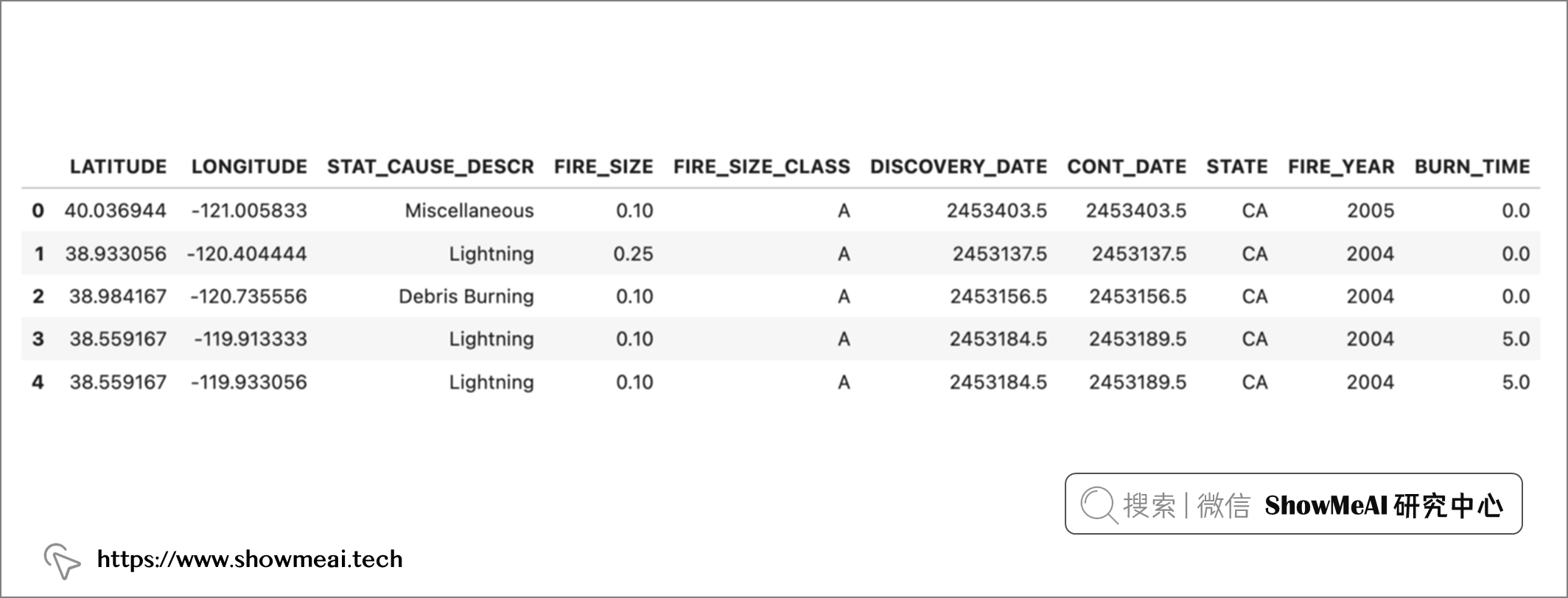
我们希望构建一个数据仪表板,帮助我们更好地了解导致这些野火的原因、发生地点等信息。我们导入数据并选出需要的信息,代码如下:
# 连接数据库
conn = sqlite3.connect('../data/FPA_FOD_20170508.sqlite')
# 选取信息:经纬度、原因描述、火势大小与等级、日期、所在州、年份 等
df = pd.read_sql_query("SELECT LATITUDE, LONGITUDE, STAT_CAUSE_DESCR, FIRE_SIZE, FIRE_SIZE_CLASS, DISCOVERY_DATE, CONT_DATE, STATE, FIRE_YEAR FROM fires", conn)
# 数据中有一些不在美国的记录,删除它们
df = df.loc[(df.loc[:,'STATE']!='AK') & (df.loc[:,'STATE']!='HI') & (df.loc[:,'STATE']!='PR')]
# 计算野火持续时间
df['BURN_TIME'] = df['CONT_DATE'] - df['DISCOVERY_DATE']
# 查看数据
df.head()
野火地图
我们先把所有历史火灾绘制成热度地图,这样我们可以直观看到空间分布。借助 hvPlot 可以很容易完成(它利用 Datashader 来栅格化我们的 180 万个点,使得它们更易于渲染)。
具体的代码如下:
map_tiles = EsriImagery().opts(alpha=0.5, width=700, height=480, bgcolor='black')
plot = df.hvplot(
'LONGITUDE',
'LATITUDE',
geo=True,
kind='points',
rasterize=True,
cmap=cc.fire,
cnorm='eq_hist',
colorbar=True).opts(colorbar_position='bottom', xlabel='', ylabel='')
map_tiles * plot
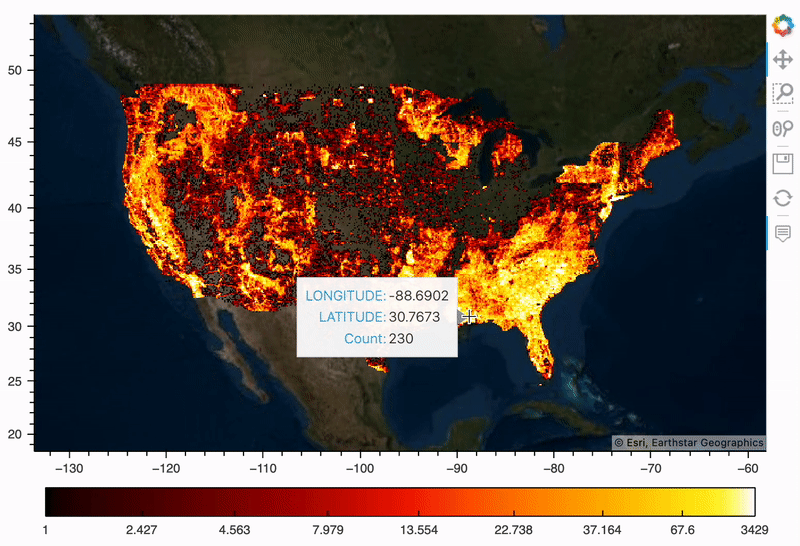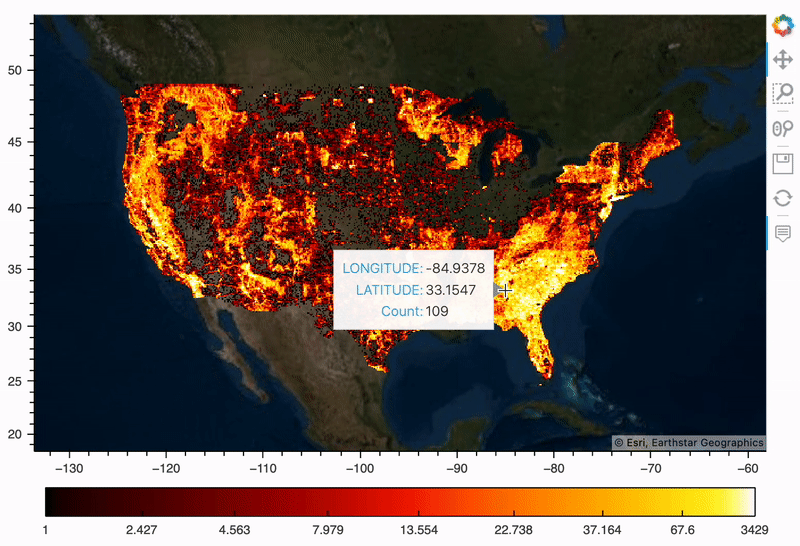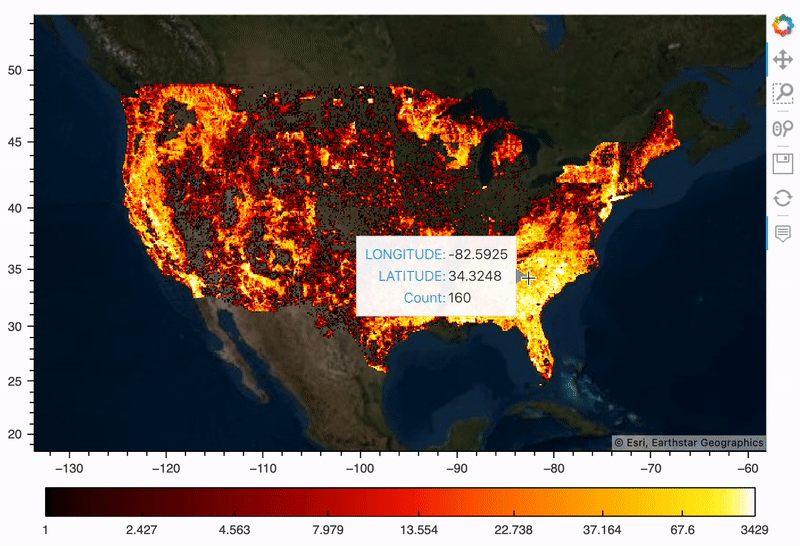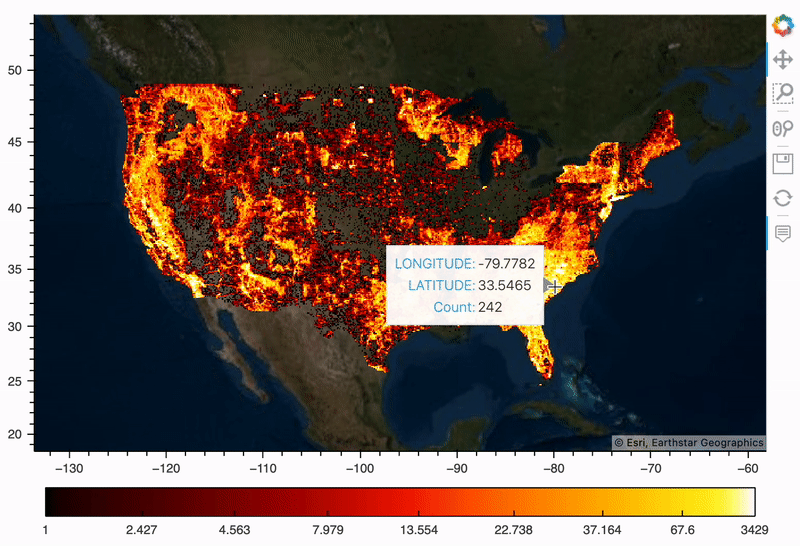 |
简单的一组代码即可实现上述可视化结果,hvPlot 是一个非常棒的空间可视化工具库,它利用了其他 Holoviz 库——Holoviews、Geoviews、Datashader 和 Colorcet,所以可以极大简化创建大型数据集的交互式地图所需步骤。

带时间滑块的仪表板
Panel 的小部件让我们可以访问各种方法来操作和切分我们的数据子集可视化,例如对时间序列数据可切分:加入选择年份的滑块。
使用 Panel 制作这种仪表板,分为3个步骤:
- ① 定义一个小部件,例如用于选择年份或下拉列表的整数滑块。
- ② 定义一个绘图函数,将滑块中的年份值作为输入。
- ③ 布局和渲染我们的仪表板。
# 为时间序列构建滑动小组件
year = pn.widgets.IntSlider(name='Year Slider', width=300,
start=1992, end=2015, value=(1993),
step=1,value_throttled=(1993))
# 展示当前年份
@pn.depends(year.param.value_throttled)
def year_selected(year):
return '## Wildfires Across the US in {}'.format(year)
# 实际绘图函数
@pn.depends(year.param.value_throttled)
def plot_map(year):
year_df = df[df['FIRE_YEAR'] == year].copy()
plot = year_df.hvplot(
'LONGITUDE',
'LATITUDE',
geo=True,
kind='points',
rasterize=True,
cmap=cc.fire,
cnorm='eq_hist',
colorbar=True).opts(colorbar_position='bottom', xlabel='', ylabel='')
return map_tiles * plot
dashboard = pn.WidgetBox(pn.Column(pn.Row(year_selected, year),
pn.Row(pn.bind(plot_map, year)), align="start",
sizing_mode="stretch_width"))
 |
更简单的构建方式
当我们的绘图只有一个小部件要显示时,有一种更简单的方式:我们可以改为使用.interactive制作我们的 DataFrame 和数据管道的交互式副本。
下面我们用一个示例来演示如何使用这个方法:这次我们的条件是『火灾的原因』,我们让地图只显示每个原因下的火灾。
select_cause = pn.widgets.Select(
options = df['STAT_CAUSE_DESCR'].value_counts().index.tolist(),
name = 'Cause')
# 动态交互
dfi = df.interactive
iplot = dfi[dfi['STAT_CAUSE_DESCR']==select_cause].hvplot(
'LONGITUDE',
'LATITUDE',
geo=True,
kind='points',
rasterize=True,
cmap=cc.fire,
cnorm='eq_hist',
colorbar=True).opts(colorbar_position='bottom', xlabel='', ylabel='', title='Wildfires by Cause from 1992-2015')
map_tiles.opts(level='underlay') * iplot
 |
组合仪表板
我们可以构建更强大的组合仪表盘,它让我们能够同时查看数据的多个维度信息。下面我们创建一些可视化图例,然后使用 Panel 将它们组合在一起。
火势大小
我们先绘制每个规模等级发生的火灾数量:野火按燃烧区域的大小进行分类,A 级最小,G 级最大。
@pn.depends(year.param.value_throttled)
def plot_class(year):
year_df = df[df['FIRE_YEAR'] == year].copy()
count_df = pd.DataFrame(year_df.groupby('FIRE_SIZE_CLASS').size(), columns=['Count'])
count_df['Fire Class'] = count_df.index
return count_df.hvplot.bar(x='Fire Class', y='Count', c='Fire Class', cmap='fire',
legend=False).opts(xlabel="Fire Size Class", ylabel="Number of Fires",
title="Wildfires in {} Grouped by Size Classification".format(year))
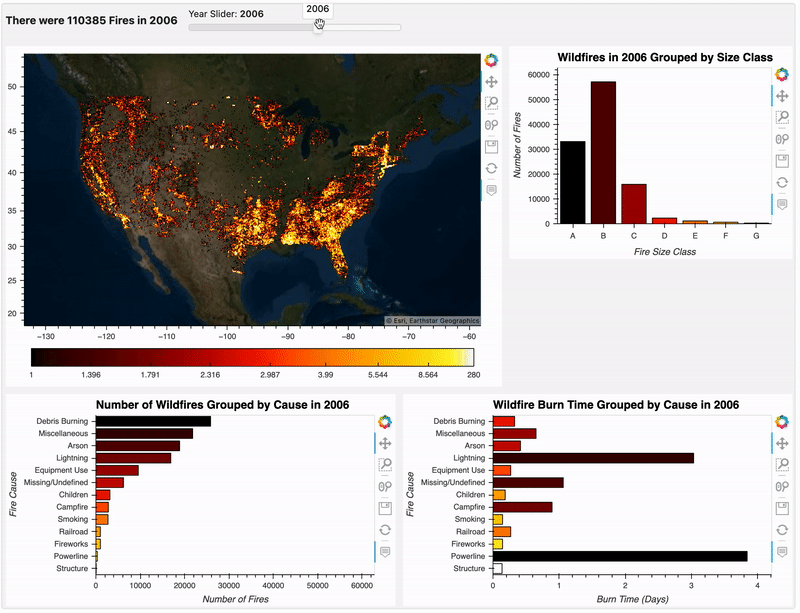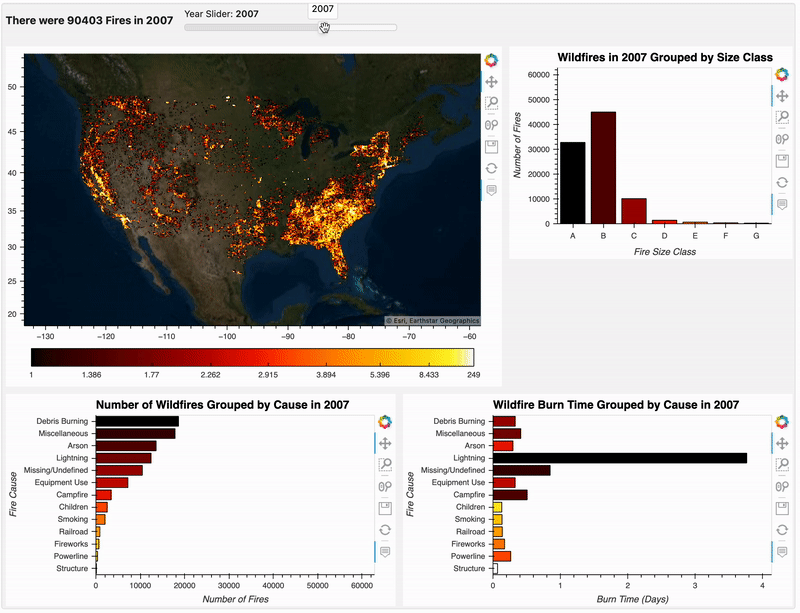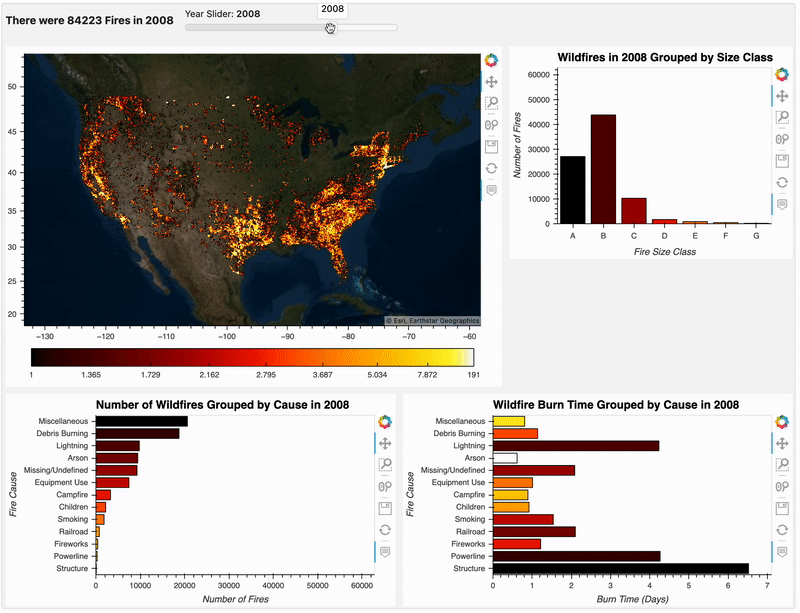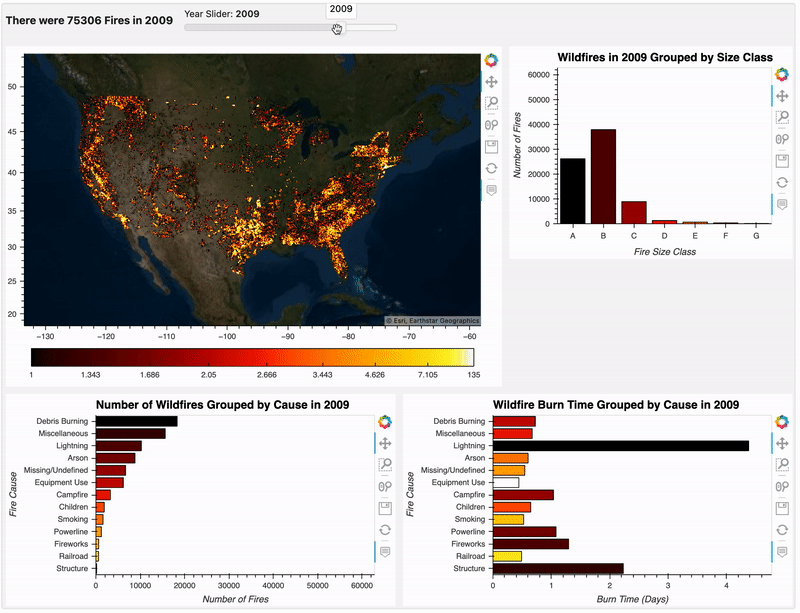
plot_class(2006)
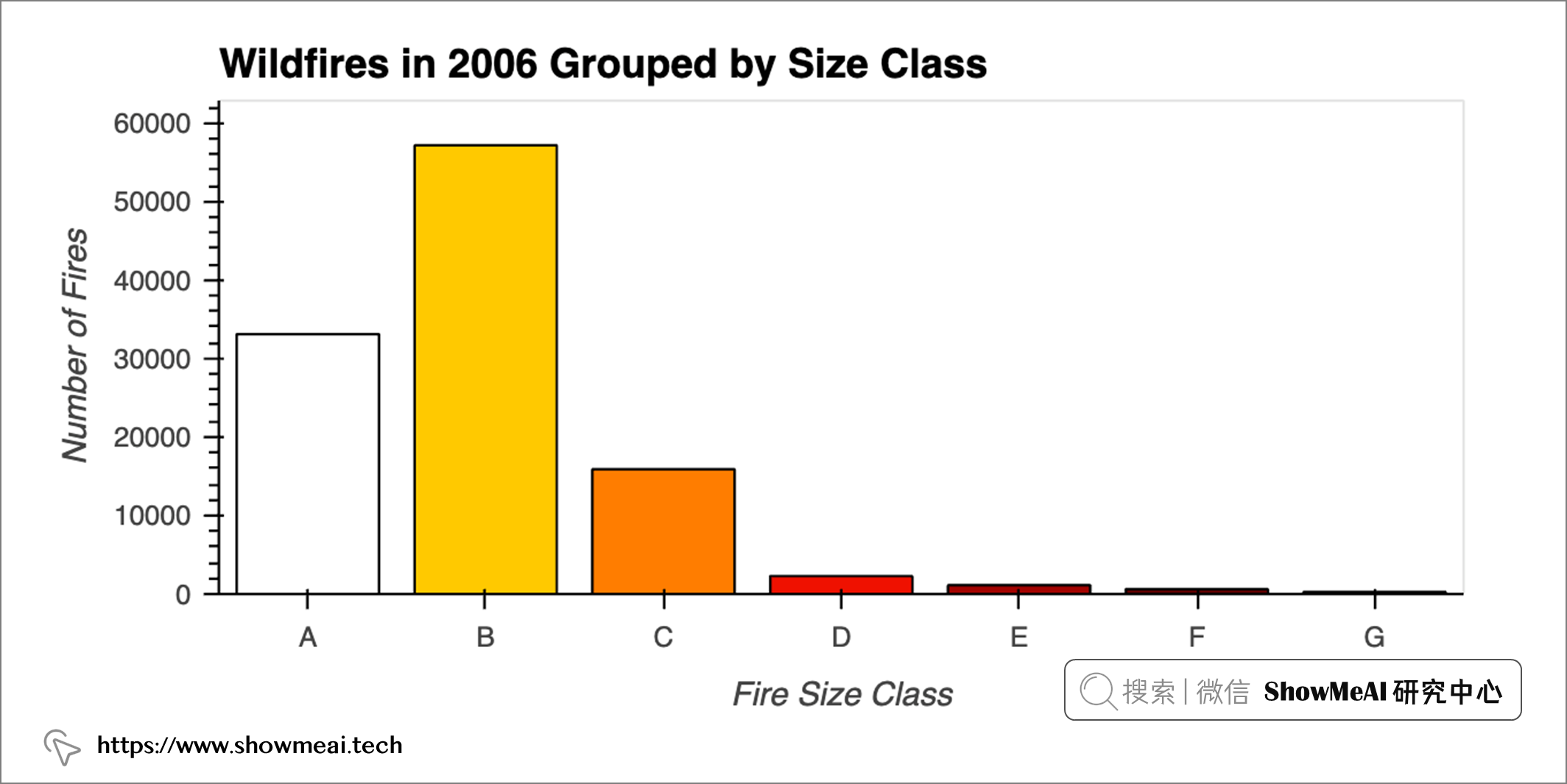
注意到上述绘图函数将『年份』作为参数,这样它可以在滑块值更改时对数据进行子集切分和呈现。拿到对应的数据子集后,我们把它按大小分类进行分组,并使用.size()计算每组的火灾次数。
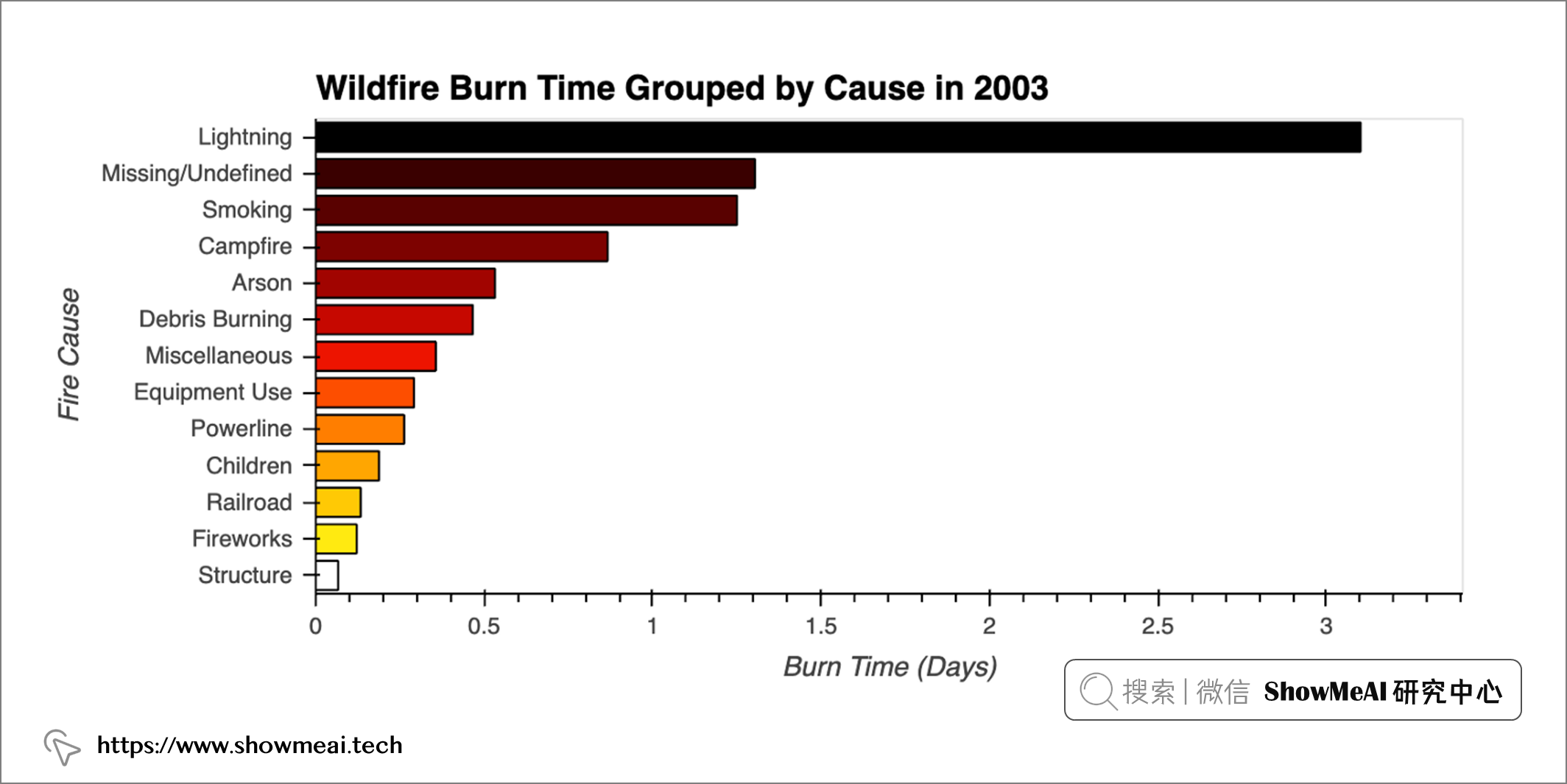
起火原因 & 持续时长
下面我们对『起火原因和对应的持续时长』进行分析可视化(注意,这里和上面的模块一样,也是传入年份作为参数,这样我们最后的组合绘图,可以有统一的数据子集切分方式)。
@pn.depends(year.param.value_throttled)
def plot_cause_burn(year):
year_df = df[df['FIRE_YEAR'] == year].copy()
caused_df = pd.DataFrame(year_df.groupby('STAT_CAUSE_DESCR')[['BURN_TIME']].mean().sort_values('BURN_TIME'))
caused_df['Fire Cause'] = caused_df.index
return caused_df.hvplot.barh(x='Fire Cause', y='BURN_TIME',
c='Fire Cause', cmap='fire_r', legend=False).opts(
ylabel="Burn Time (Days)",
title="Wildfire Burn time Grouped by Cause in {}".format(year))
plot_cause_burn(2003)
起火原因 & 火灾数量
下面我们对『起火原因和对应的数量』进行分析可视化。
@pn.depends(year.param.value_throttled)
def plot_cause_count(year):
year_df = df[df['FIRE_YEAR'] == year].copy()
caused_df = pd.DataFrame(year_df.groupby('STAT_CAUSE_DESCR').size(), columns=['Count']).sort_values('Count')
caused_df['Fire Cause'] = caused_df.index
return caused_df.hvplot.barh(x='Fire Cause', y='Count',
c='Fire Cause', cmap='fire_r',
legend=False).opts(ylabel="Number of Fires",
title="Number of Wildfires Grouped by Cause in {}".format(year))
plot_cause_count(2003)
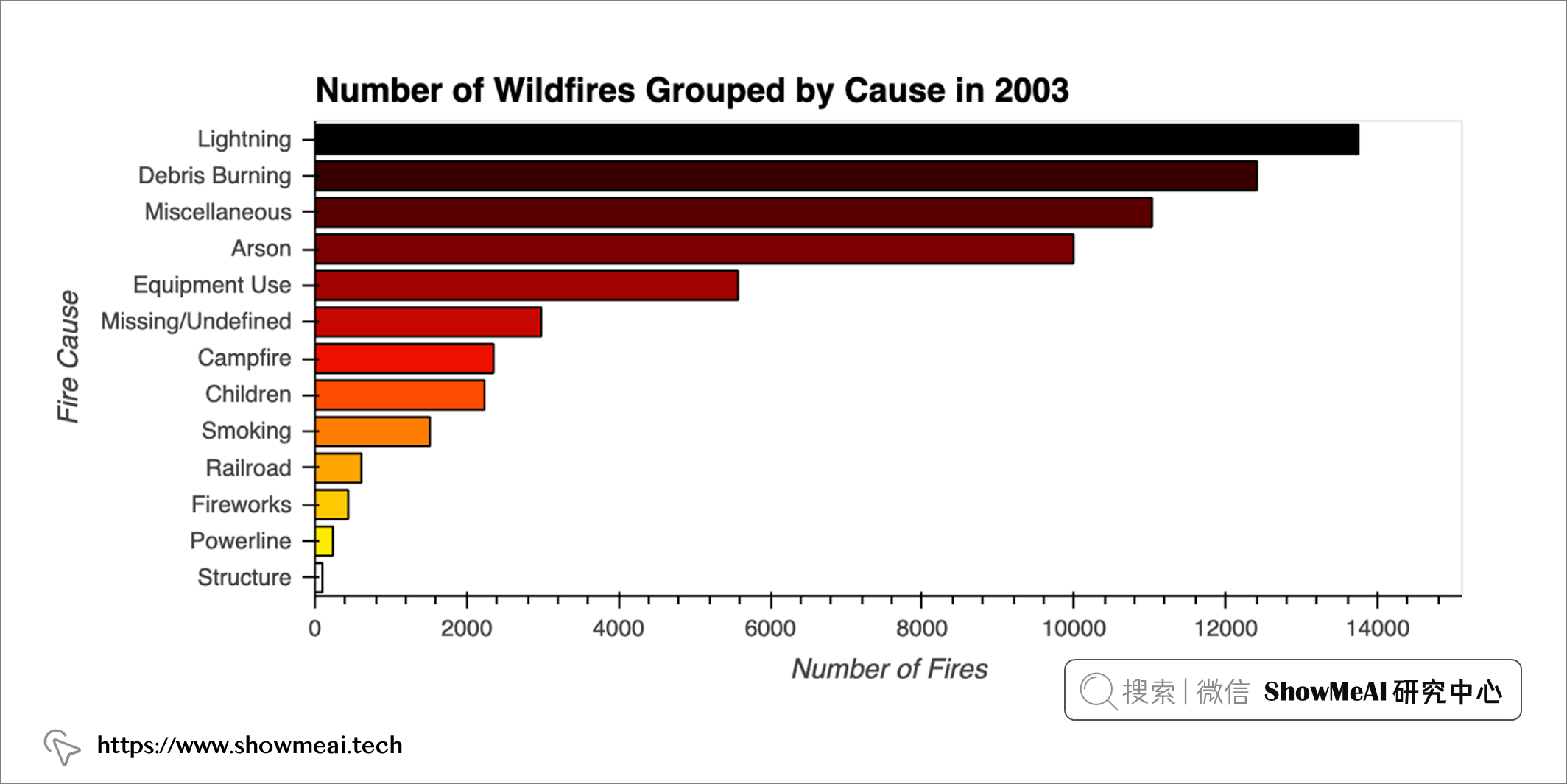
对比上图,我们可以看到一些有趣差异,例如:
- 吸烟带来第2燃烧时长的野火,而它在引发的野火总数中排名第9。
- 除了闪电之外,燃烧时间最长的火灾并不是最频繁发生的火灾。
这也解释了为什么野火难以扑灭,它们通常发生在更偏远的地方,很难及早控制。闪电、吸烟和营火都有可能在这些地区引发火灾,因为那里有大量木材可燃烧,而周围很少有人在早期发现迹象并报告烟雾。
也有一些年份看起来完全不同,例如 2006 年,电力线故障导致大火平均燃烧数天。如下图所示:
pn.Row(plot_cause_count(2006) , plot_cause_burn(2006), width=1000)
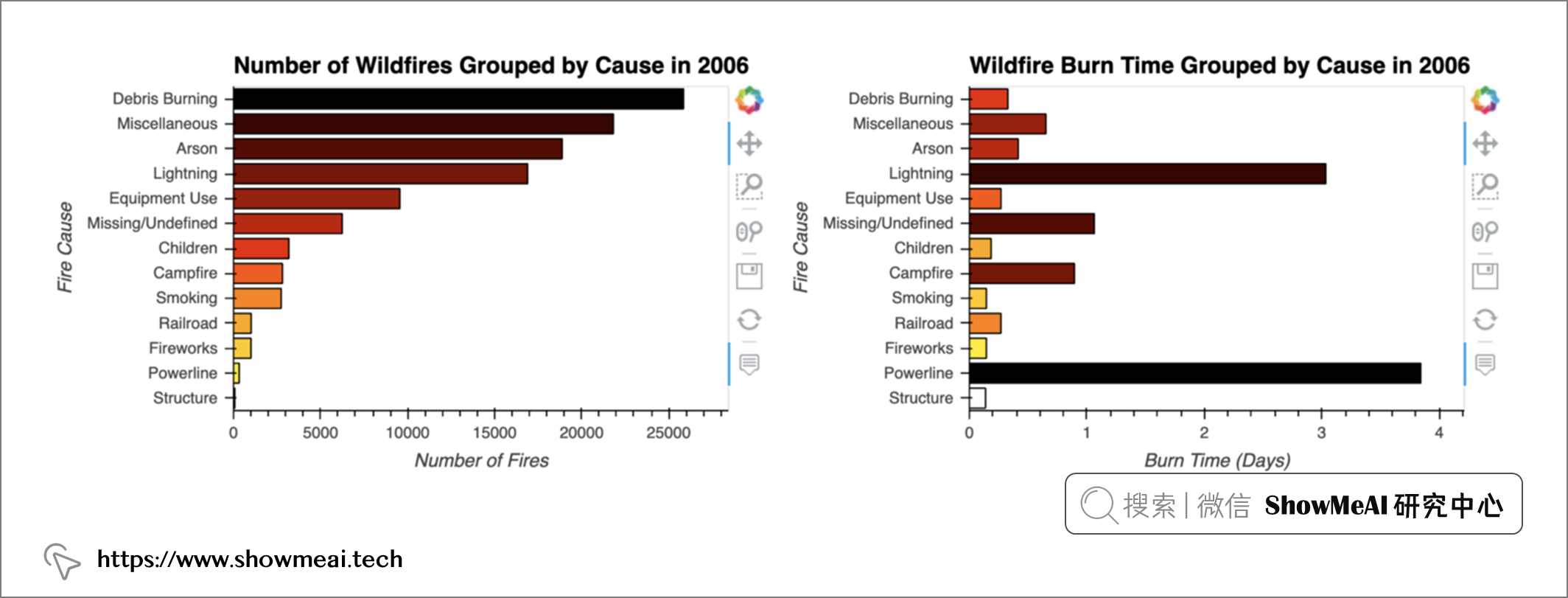
这里需要注意的是 Panel 和 hvPlot 如何识别这两个子图共享相同的 y 轴。
分析结果组装
现在我们已经从不同维度进行了分析,我们使用小部件把它们进行组合,使我们可以沿着时间轴动态选择和做一些数据探索,构建组合仪表板的代码如下:
plots_box = pn.WidgetBox(pn.Column(pn.Row(pn.bind(fire_count, year), year),
pn.Row(pn.bind(plot_map, year), pn.bind(plot_class, year)) ,
pn.Row(pn.bind(plot_cause_count, year), pn.bind(plot_cause_burn, year)), align="start",
width=800, sizing_mode="stretch_width"))
dashboard = pn.Row(plots_box, sizing_mode="stretch_width")
 |
上面只是截取的一些gif动图,大家快快实际操作一下吧!会有更清晰的认识。
总结
在本篇内容中 ShowMeAI 给大家讲解了使用 hvPlot 和 Panel 构建各种组合可视化看板仪表盘的方法,当我们需要进行数据探索和分析的时候,简单的一些数据分析可视化用 Pandas 和 Seaborn 等就可以快速完成,当我们需要一个交互式探索分析工具时,使用hvPlot 和 Panel 是一个非常棒的选择。
参考资料
- panel 文档:https://panel.holoviz.org/
- hvPlot 文档:https://hvplot.holoviz.org/
- holoviz 文档:https://holoviz.org/tutorial/index.html
- holoviews 文档:https://holoviews.org/gallery/index.html
- Geoviews 文档:https://geoviews.org/
- Datashader 文档:https://datashader.org/
- Colorcet 文档:https://colorcet.holoviz.org/
森林野火故事2.0:一眼看穿!使用 Panel 和 hvPlot 可视化 ⛵的更多相关文章
- 从密码到token, 一个授权的故事 auth2.0
1 美好的旧时光 我经常怀念三十年前那美好的旧时光, 工作很轻松, 生活很悠闲. 上班的时候偶尔有些HTTP的请求发到我这里, 我简单的看一下, 取出相对应的html文档,图片,发回去就可以了, 然后 ...
- 一眼看穿👀JS基本概念
前段时间忙,好久没更新了,继续梳理基础知识这期总结的是JS的基本概念 标识符 所谓的标识符是指变量,函数属性的名字,或者函数的参数 第一个字符必须是一个字母,下划线(_)或者一个美元符号($),其他字 ...
- 一眼看穿flatMap和map的区别
背景 map和flatmap,从字面意思或者官网介绍,可能会给一些人在理解上造成困扰[包括本人],所以今天专门花时间来分析,现整理如下: 首先做一下名词解释---------------------- ...
- Superset 0.37 发布——颜值最高的数据可视化平台
Superset 0.37,增加可视化插件,行级权限控制 使用Superset已经有一段时间,其良好的体验与丰富的图表功能节省了大量的时间.但是对于权限,自定义图表,图表下载,报警邮件一直没有很好的支 ...
- ML—随机森林·1
Introduction to Random forest(Simplified) With increase in computational power, we can now choose al ...
- R语言︱机器学习模型评估方案(以随机森林算法为例)
笔者寄语:本文中大多内容来自<数据挖掘之道>,本文为读书笔记.在刚刚接触机器学习的时候,觉得在监督学习之后,做一个混淆矩阵就已经足够,但是完整的机器学习解决方案并不会如此草率.需要完整的评 ...
- 【FJWC 2019】 森林
[FJWC 2019] 森林 样例输入 0 5 1 0 0 2 样例输出 1 2 3 3 我们发现,答案就是直径加上直径上某个点出发,不经过其他直径上的点的最长链.这里的直径可以是任意一条直径. 首先 ...
- 机器学习回顾篇(12):集成学习之Bagging与随机森林
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 2022极端高温!机器学习如何预测森林火灾?⛵ 万物AI
作者:ShowMeAI编辑部 声明:版权所有,转载请联系平台与作者并注明出处 收藏ShowMeAI查看更多精彩内容 今年夏天,重庆北碚区山火一路向国家级自然保护区缙云山方向蔓延.为守护家园,数万名重庆 ...
- javascrit2.0完全参考手册(第二版) 第1章第1节 在XHTML文档中增加javascript
通常,向文档中增加script脚本使用<script>元素,在HTML中增加脚本的方式有4中: (1)放到<script></script>块中: (2)<s ...
随机推荐
- kingbaseES R3 集群修改data路径测试案例
案例说明: 默认KingbaseES R3集群部署后,数据存储目录(data)在/home/kingbase下,部署时不能更改:本案例是在部署完成后,迁移data目录到其他指定的存储位置. 数据库版本 ...
- 使用 Loki 收集 Traefik 日志
转载自:https://mp.weixin.qq.com/s?__biz=MzU4MjQ0MTU4Ng==&mid=2247492264&idx=1&sn=f443c92664 ...
- 重新安装kuboard后,原先配置的CI/CD命令都没了,需要重新创建
背景介绍 使用如下命令创建的kuboard服务,上一层用nginx设置代理,用域名访问使用的 docker run -d \ --restart=always \ --name=kuboard \ - ...
- Elasticsearch:ICU分词器介绍
ICU Analysis插件是一组将Lucene ICU模块集成到Elasticsearch中的库. 本质上,ICU的目的是增加对Unicode和全球化的支持,以提供对亚洲语言更好的文本分割分析. 从 ...
- 安装ceph (快速) 步骤二:存储集群
用 ceph-deploy 从管理节点建立一个 Ceph 存储集群,该集群包含三个节点,以此探索 Ceph 的功能. 创建一个 Ceph 存储集群,它有一个 Monitor 和两个 OSD 守护进程. ...
- gitlab备份和恢复
备份 生产环境下,备份是必需的.需要备份的文件有:配置文件和数据文件. 备份配置文件 配置文件包含密码等敏感信息,不要和数据文件放在一起. sh -c 'umask 0077; tar -cf $(d ...
- RDS MySQL内存管理
官方文档地址:https://help.aliyun.com/product/26090.html?spm=5176.7920929.1290474.7.2c6f4f7bACaToi 官方文档地址:h ...
- linux安装达梦数据库8
PS.本次测试只是为了项目需要,但是在部署和启动程序的时候发生了一系列的报错,由此记录下来为日后作参考 安装达梦数据库 1. 达梦数据库(DM8)简介 达梦数据库管理系统是武汉达梦公司推出的具有完全自 ...
- Autobus 方法记录
原题链接 [COCI2021-2022#4] Autobus 题目描述 在一个国家里有 \(n\) 座城市.这些城市由 \(m\) 条公交线路连接,其中第 \(i\) 条线路从城市 \(a_i\) 出 ...
- Hyperf使用ElasticSearch记录
Hyperf 安装 Elasticsearch 协程客户端 hyperf/elasticsearch 主要为 elasticsearch-php 进行了客户端对象创建的工厂类封装,elasticsea ...