云原生API网关全生命周期管理Apache APISIX探究实操
@
概述
定义
Apache APISIX官网地址 https://apisix.apache.org/ 最新版本3.2.0
Apache APISIX官网文档地址 https://apisix.apache.org/docs/apisix/getting-started/
Apache APISIX源码地址 https://github.com/apache/apisix
Apache APISIX 是一个动态、实时、高性能、可扩展的云原生 API 网关,提供了如负载均衡、动态上游、灰度发布(金丝雀发布)、服务熔断、身份认证、可观测性等丰富的流量管理功能。可以使用APISIX API Gateway来处理传统的南北向流量,也可以用来处理服务之间的东西向流量;还可以用作k8s入口控制器。
Apache APISIX是第一个包含内置低代码仪表板的开源API网关,它为开发人员提供了强大而灵活的UI;云原生时代,动态和可观测性成为衡量 API 网关的标准之一;Apache APISIX 自诞生之初就一直跟随着云原生的脚步前行。
备注:南北向流量可以简单理解客户端到服务端,也即是我们传统上使用Nginx;东西向流量更多的是后台微服务之间的通信。
NGINX 与 Kong 的痛点
在单体服务时代,使用 NGINX 可以应对大多数的场景,而到了云原生时代,NGINX 因为其自身架构的原因则会出现两个问题:
- 首先是 NGINX 不支持集群管理。几乎每家互联网厂商都有自己的 NGINX 配置管理系统,系统虽然大同小异但是一直没有统一的方案。
- 其次是 NGINX 不支持配置的热加载。很多公司一旦修改了配置,重新加载 NGINX 的时间可能需要半个小时以上。并且在 Kubernetes 体系下,上游会经常发生变化,如果使用 NGINX 来处理就需要频繁重启服务,这对于企业是不可接受的。
而 Kong 的出现则解决了 NGINX 的痛点,但是又带来了新的问题:
- Kong 需要依赖于 PostgreSQL 或 Cassandra 数据库,这使 Kong 的整个架构非常臃肿,并且会给企业带来高可用的问题。如果数据库故障了,那么整个 API 网关都会出现故障。
- Kong 的路由使用的是遍历查找,当网关内有超过上千个路由时,它的性能就会出现比较急剧的下降。
APISIX 的技术优势
而 APISIX 的出现则解决了上述所有问题,成为了云原生时代最完美的 API 网关。Apache APISIX 和 Kong相比在技术方面的主要优势大部分都是在底层模块上的优化和创新;在简单的 PoC 上并不一定能够体现出这些技术的优势,但在复杂的生产环境中,Apache APISIX 的这些优势将会造成巨大的差距。
- 无数据库依赖:在 APISIX 项目出现之前,也有非常多的商业 API 网关或开源 API 网关产品,但这些产品大多数都把 API 数据、路由、证书和配置等信息存放在一个关系型数据库中。网关作为一个基础中间件处理了所有来自客户端的流量,因此对于可用性的要求便会非常高。如果API 网关依赖了一个关系型数据库,也就意味着关系型数据库一旦出现了故障(比如宕机、丢失数据),API 网关也会因此受到影响,整个业务系统的可用性也会大打折扣。
- 高性能路由匹配算法和 IP 匹配算法:Apache APISIX 使用的是 RadixTree,它提供了 KV 存储查找的数据结构并对只有一个子节点的中间节点进行了压缩,因此它又被称为压缩前缀树;高效且支持模糊匹配的搜索数据结构。
特性
Apache APISIX的特性较多,下面只是列出部分特性和说明。
平台支持:APISIX 提供了平台级解决方案,不但支持裸机运行,也支持在 Kubernetes 中云原生使用。
众多协议支持:如TCP/UDP Proxy、Dubbo Proxy、Dynamic MQTT Proxy、gRPC proxy、HTTP(S) Forward Proxy等
全动态能力
- Apache APISIX提供了热更新和热插件,可以在不重新启动的情况下持续更新配置,节省了开发时间和压力。
- 健康检查:开启上游节点健康检查功能,负载均衡时自动过滤不健康节点,保证系统稳定。
- 断路器:智能跟踪不健康的上游服务。
- 流量分流:可以在不同的上游之间增量地引导流量的百分比。
精细化路由
- Apache APISIX Gateway提供了编写自己的自定义插件的能力,在平衡器阶段使用自定义负载平衡算法进行扩展,自定义路由算法用于对路由进行精细控制;支持全路径匹配和前缀匹配。
- 支持所有Nginx内置变量作为路由条件,可以使用cookie, args等作为路由条件来实现金丝雀发布,A/B测试。
- 支持自定义路由匹配功能。
安全
- 丰富的身份验证和授权支持。Apache APISIX Gateway提供了多个用于身份验证和API验证的安全插件,包括CORS、JWT、Key Auth、OpenID Connect (OIDC)、Keycloak等。
- IP黑白名单、Referer黑白名单。
- Anti-ReDoS(正则表达式拒绝服务):无需配置,内置防ReDoS策略。
- 防CSRF攻击。
运维友好
- 支持与多种工具和平台如Zipkin、SkyWalking、Consul、Nacos、Eureka、Zookeeper、Prometheus、HashiCorp Vault等集成。
- 通过使用APISIX Dashboard,运维人员可以通过友好且直观的 UI 配置 APISIX。
- 版本控制:支持操作回滚。
- 命令行:通过命令行启动/停止/重新加载APISIX。
高可扩展
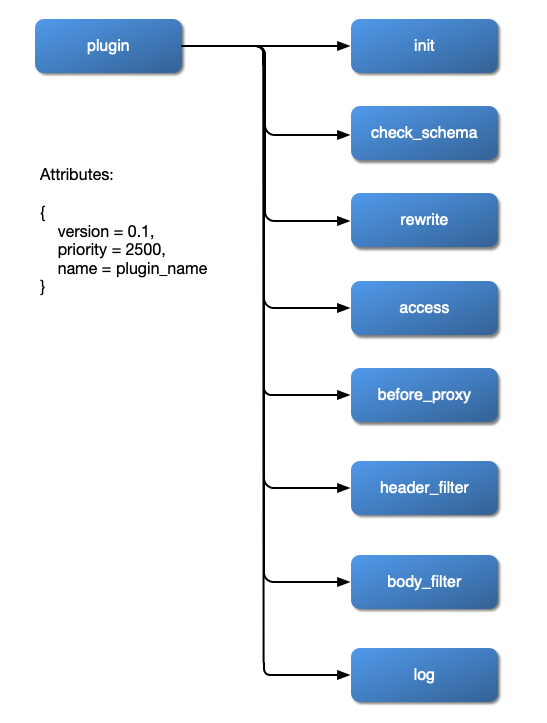
- 自定义插件:允许挂载常见阶段,如重写,访问,头过滤器,主体过滤器和日志。插件可用Java/Go/Python编写,也可用代理Wasm SDK编写。
- 自定义负载均衡算法:可以在均衡器阶段使用自定义负载均衡算法。
- 自定义路由:支持用户自行实现路由算法。
多语言支持:Apache APISIX是一个用于插件开发的多语言网关,并通过RPC和Wasm提供支持。
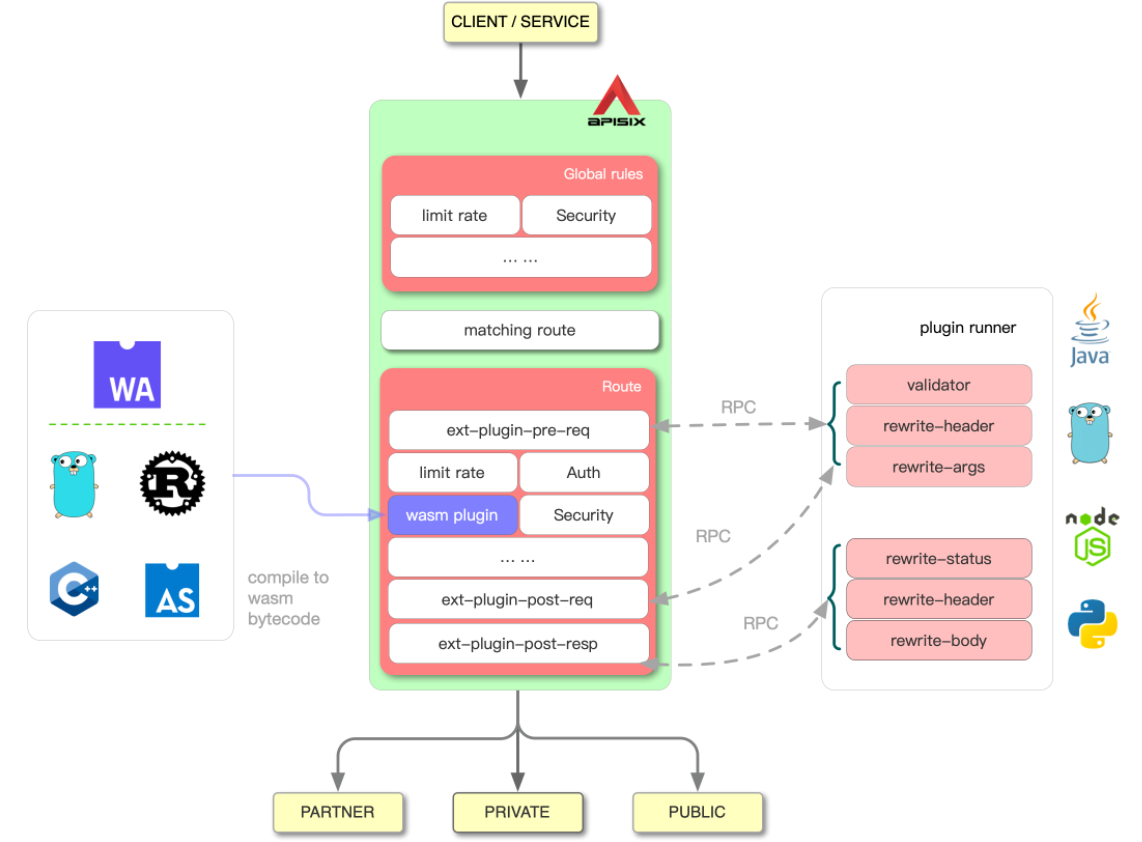
Serverless:支持与Lua函数、AWS Lambda、Azure Functions、Apache OpenWhisk等云服务集成。
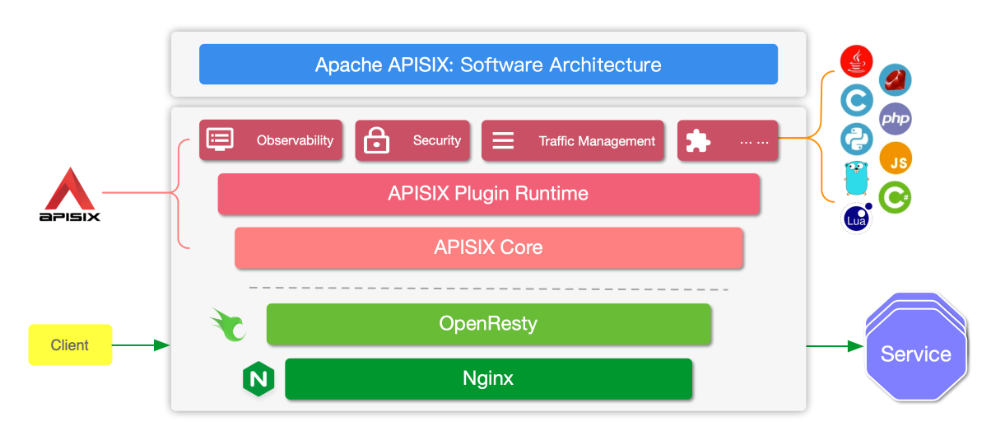
架构
Apache APISIX基于NGINX和etcd。与传统的API网关相比,APISIX具有动态路由、热加载插件等特性。
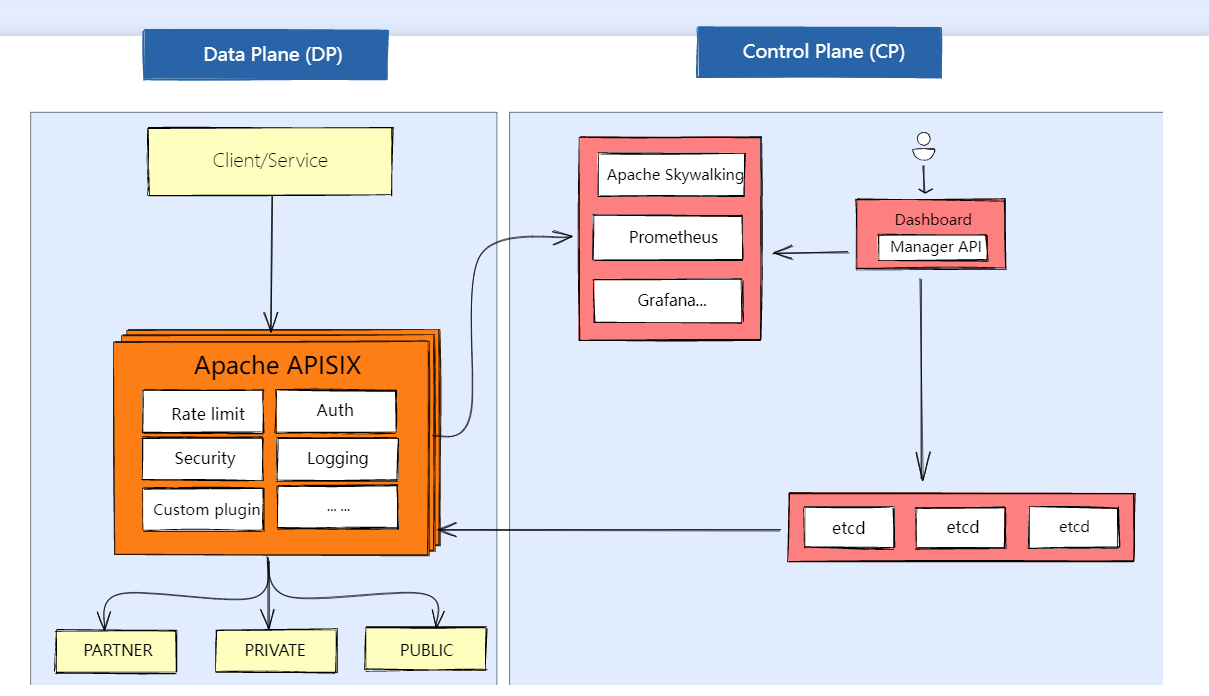
APISIX 的架构主要分成如下两部分“
- 数据面:真正去处理来自客户端请求的一个组件,去处理用户的真实流量,包括像身份验证、证书卸载、日志分析和可观测性等功能。数据面本身并不会存储任何数据,所以它是一个无状态结构。
- 控制面:APISIX 在控制面上并没有使用传统的类似于像 MySQL 去做配置存储,而是选择使用 etcd。这样做的好处在于:
- 与产品架构的云原生技术体系更统一
- 更贴合 API 网关存放的数据类型
- 能更好地体现高可用特性
- 拥有低于毫秒级别的变化通知
应用场景
APISIX 目标是统一代理基础设施,其核心为高性能代理服务,自身不绑定任何环境属性。当它演变为 Ingress、服务网格等产品时,都是外部服务与 APISIX 配合,变化的是外部程序而不是 APISIX 自身。
- Load Balancer 和 API 网关:针对传统的 LB 和 API 网关场景, APISIX 基于 NGINX + LuaJIT 实现天然具备高性能、安全等特性,并且原生支持了动态 SSL 证书卸载、SSL 握手优化等功能,在负载均衡的服务能力上也更优秀。从 NGINX 切换到 APISIX 不仅性能不会下降,而且可以享受到动态、统一管理等特性带来的管理效率的提升。
- 微服务网关:APISIX 目前支持多种语言编写扩展插件,可以解决东西向微服务 API 网关面临的主要问题——异构多语言和通用问题。内置支持的服务注册中心有 Nacos、etcd、Eureka 等,还有标准的 DNS 方式,可以平滑替代 Zuul、Spring Cloud Gateway、Dubbo 等微服务 API 网关。
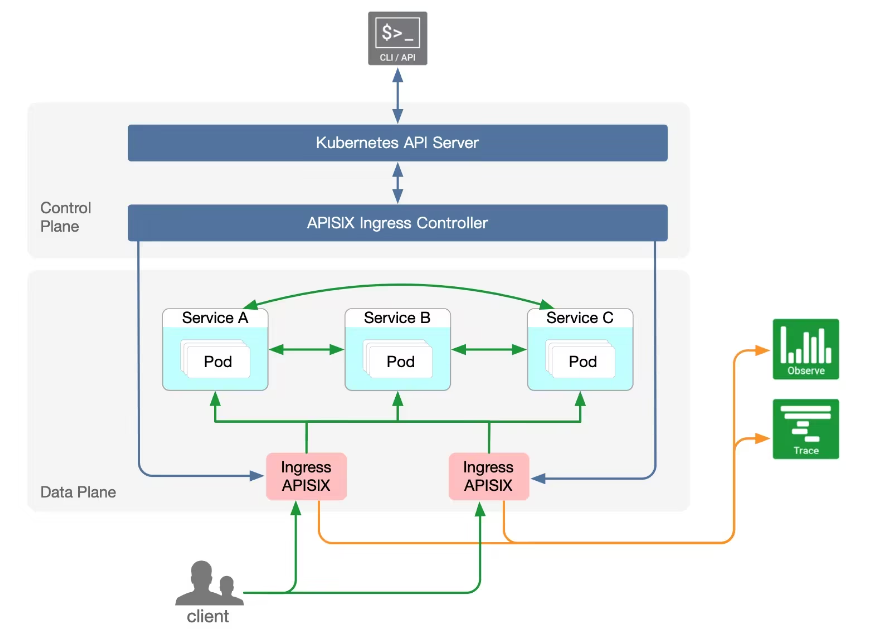
- Kubernetes Ingress: K8s 官方 Kubernetes Ingress Controller 项目主要基于 NGINX 配置文件的方式,所以在路由能力和加载模式上稍显不足,并且存在一些明显劣势。比如添加、修改任何 API 时,需要重启服务才能完成新 NGINX 配置的更新,但重启服务,对线上流量的影响是非常大的。而 APISIX Ingress Controller 则完美解决了上面提到的所有问题:支持全动态,无需重启加载。同时继承了 APISIX 的所有优势,还支持原生 Kubernetes CRD,方便用户迁移。
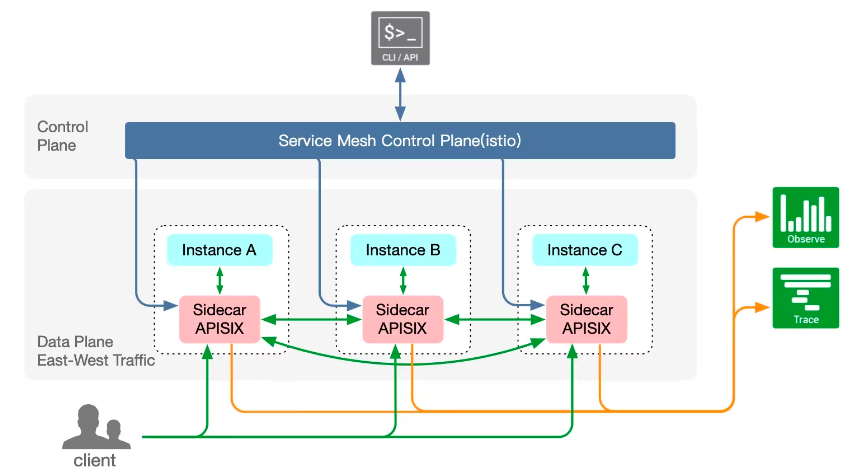
- 服务网格:APISIX 也提前基于云原生模式架构下的服务网格架构,通过调研和技术分析后,APISIX 已经支持了 xDS 协议,APISIX Mesh 就此诞生,在服务网格领域 APISIX 也拥有了一席之地。
主要概念
APISIX 主要分为两个部分:
- APISIX 核心:包括 Lua 插件、多语言插件运行时(Plugin Runner)、Wasm 插件运行时等;
- 功能丰富的各种内置插件:包括可观测性、安全、流量控制等。
| 概念/组件 | 描述 |
|---|---|
| Route | 通过路由定义规则来匹配客户端请求,根据匹配结果加载并执行相应的插件,最后把请求转发给到指定的上游应用。 |
| Upstream | 上游的作用是按照配置规则对服务节点进行负载均衡,它的地址信息可以直接配置到路由或服务上。 |
| Admin API | 用户可以通过 Admin API 控制 APISIX 实例。 |
插件加载流程
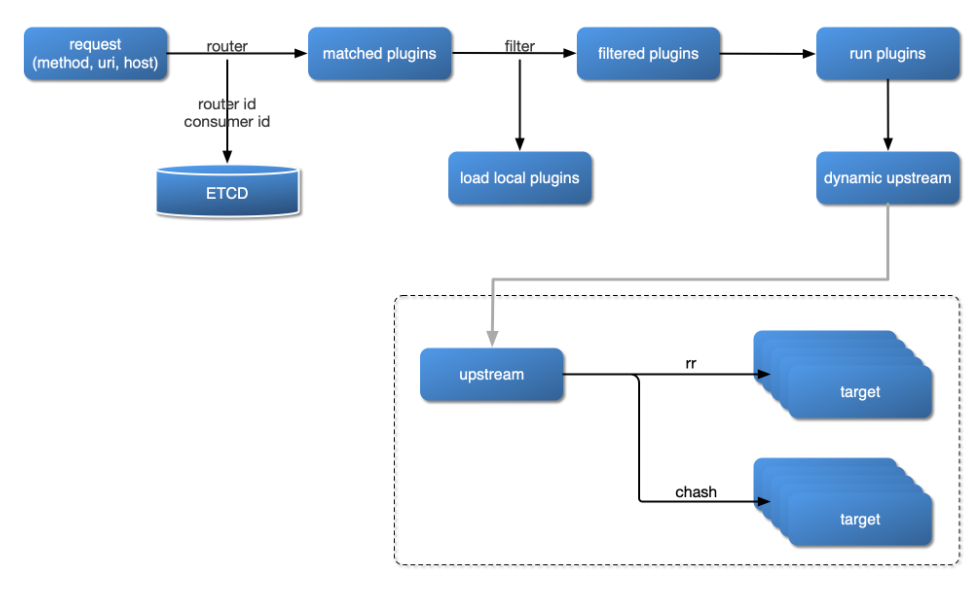
插件内部结构
部署
快速入门
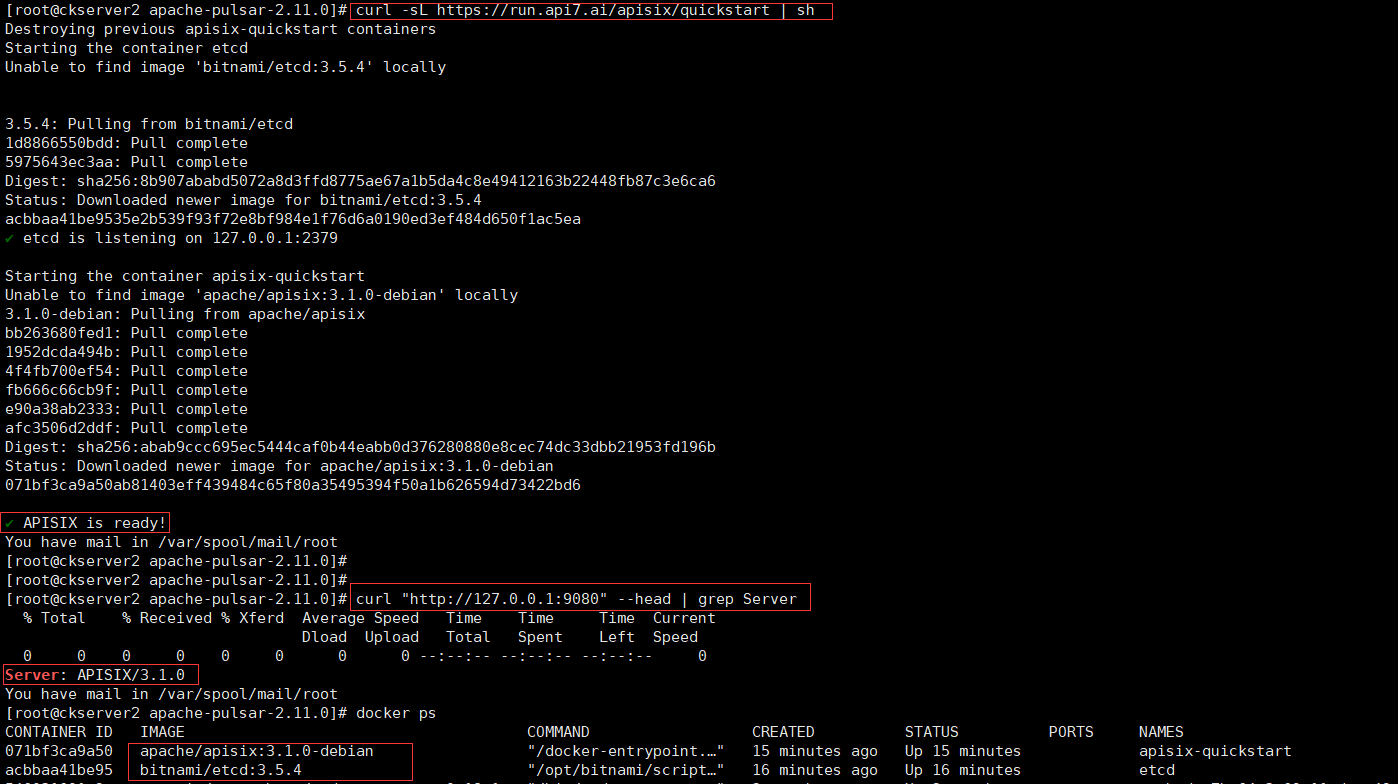
quickstart安装
# quickstart 脚本快速安装并启动,该命令在本地安装并运行了基于 Docker 的 APISIX 和 etcd 容器,其中 APISIX 采用 etcd 保存和同步配置信息。APISIX 和 etcd 容器使用 host 的 Docker 网络模式,因此可以从本地直接访问。
curl -sL https://run.api7.ai/apisix/quickstart | sh
# 请确保其他系统进程没有占用 9080、9180、9443 和 2379 端口。可以通过 curl 来访问正在运行的 APISIX 实例。比如,你可以发送一个简单的 HTTP 请求来验证 APISIX 运行状态是否正常。
curl "http://127.0.0.1:9080" --head | grep Server
Admin API创建路由
# 以httpbin.org这个简单的HTTP请求和响应服务作为演示,详细可以直接查阅http://httpbin.org/,使用httpbin.org测试接口来体验下,如果希望这个接口在本地运行,可采用docker部署,docker Run -p 80:80 kennethreitz/httpbin
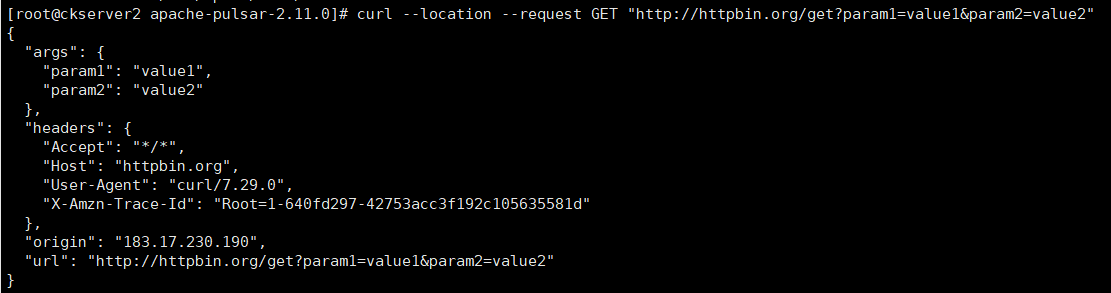
curl --location --request GET "http://httpbin.org/get?param1=value1¶m2=value2"
- 创建路由,使用 Admin API 创建一个 Route并与Upstream绑定,当一个请求到达 APISIX 时,APISIX 会将请求转发到指定的上游服务中。
curl "http://127.0.0.1:9180/apisix/admin/routes/1" -X PUT -d '
{
"methods": ["GET"],
"host": "mytest.com",
"uri": "/anything/*",
"upstream": {
"type": "roundrobin",
"nodes": {
"httpbin.org:80": 1
}
}
}'

# 当路由创建完成后,可以通过以下命令访问上游服务,该请求将被 APISIX 转发到 http://httpbin.org:80/anything/foo?arg=10
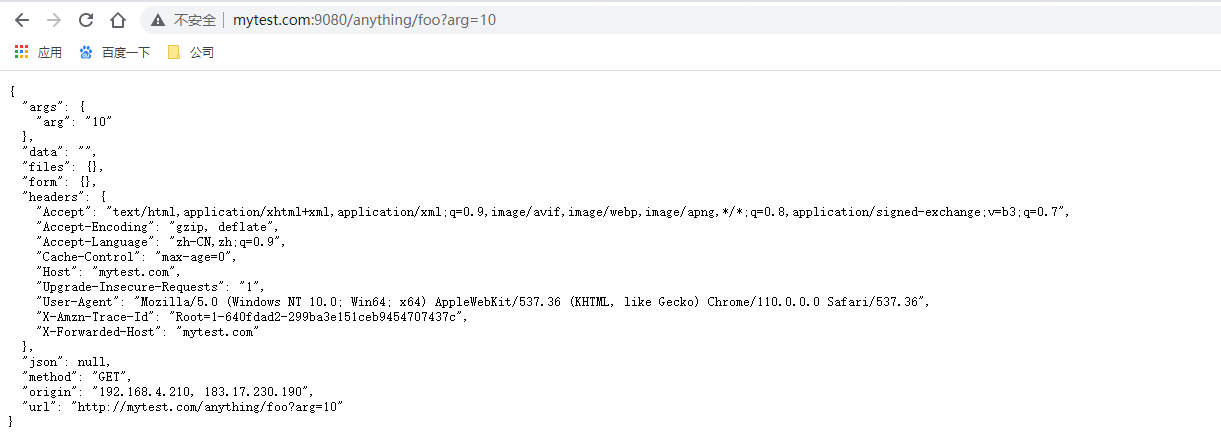
curl -i -X GET "http://127.0.0.1:9080/anything/foo?arg=10" -H "Host: mytest.com"

也可以配置hosts映射,然后在浏览器直接访问http://mytest.com:9080/anything/foo?arg=10
- 使用上游服务创建路由,可以通过下面命令创建一个上游,并在路由中使用它,而不是想上面示例直接将其配置在路由中
curl "http://127.0.0.1:9180/apisix/admin/upstreams/1" -X PUT -d '
{
"type": "roundrobin",
"nodes": {
"httpbin.org:80": 1
}
}'
然后在通过以下命令绑定到指定路由
curl "http://127.0.0.1:9180/apisix/admin/routes/1" -X PUT -d '
{
"uri": "/get",
"host": "httpbin.org",
"upstream_id": "1"
}'

可以通过下面命令访问上游服务,该请求将被 APISIX 转发到 http://httpbin.org:80/anything/foo?arg=10。
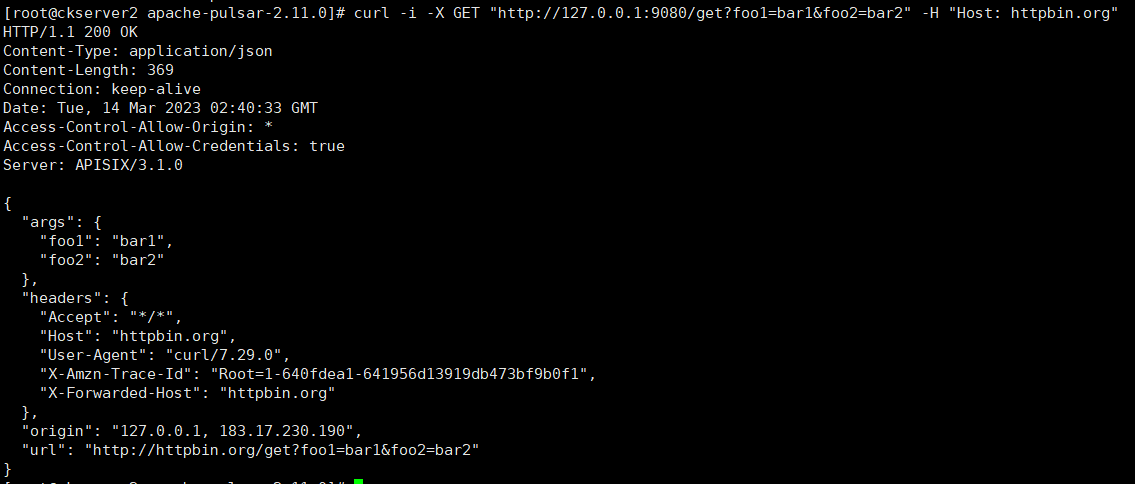
curl -i -X GET "http://127.0.0.1:9080/get?foo1=bar1&foo2=bar2" -H "Host: httpbin.org"
RPM安装
安装etcd
APISIX使用etcd保存和同步配置,在安装APISIX之前需要安装etcd。
ETCD_VERSION='3.5.7'
wget https://github.com/etcd-io/etcd/releases/download/v${ETCD_VERSION}/etcd-v${ETCD_VERSION}-linux-amd64.tar.gz
tar -xvf etcd-v${ETCD_VERSION}-linux-amd64.tar.gz
cd etcd-v${ETCD_VERSION}-linux-amd64
cp -a etcd etcdctl /usr/bin/
nohup etcd >/tmp/etcd.log 2>&1 &
RPM安装
APISIX RPM安装适用于CentOS 7和CentOS 8
# 如果没有安装OpenResty,可运行以下命令同时安装OpenResty和APISI仓库yum install -y https://repos.apiseven.com/packages/centos/apache-apisix-repo-1.0-1.noarch.rpm# 如果安装了OpenResty,下面的命令将安装APISIX存储库:yum-config-manager --add-repo https://repos.apiseven.com/packages/centos/apache-apisix.repo# 安装APISIXyum install apisix# 还可以通过指定APISIX来安装特定版本的APISIXyum install apisix-3.1.0# 管理APISIX服务器,安装APISIX后,可以通过以下命令初始化配置文件和etcdapisix init# 检查配置文件是否争取apisix test

# 启动apisixapisix start# 正常关闭apisix,确保停止之前完成所有收到的请求apisix quit# 强制关闭apisix并丢弃所有请求apisix stop
配置apisix
更改配置文件,路径在/usr/local/apisix/conf/config.yaml
# 在启动APISIX时,通过使用--config或-c标志将路径传递给配置文件,APISIX将使用此配置文件中添加的配置,如果没有配置任何内容,则将退回到默认配置。apisix start -c <path to config file>
警告注意:
- APISIX的默认配置可以在conf/config-default.yaml中找到,这个文件不应该被修改,它与源代码绑定,只能通过上面提到的config.yaml更改配置。
- conf/nginx.conf文件是自动生成的,不可修改。
建议修改Admin API密钥以保证安全性,修改conf/config.yaml,修改后重启apisix
deployment: admin: admin_key - name: "admin" key: edd1c9f034335f136f87ad84b625c123 role: admin
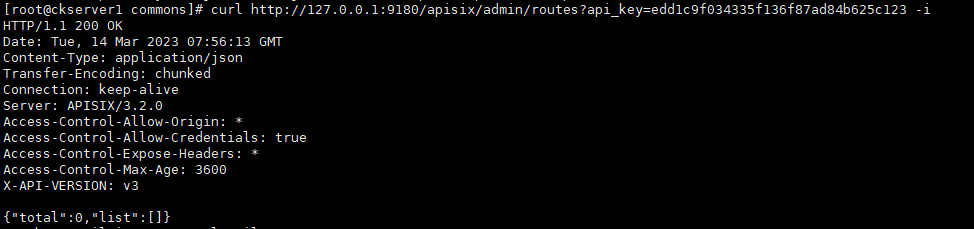
# 访问Admin API,你可以使用新的密码curl http://127.0.0.1:9180/apisix/admin/routes?api_key=edd1c9f034335f136f87ad84b625c123 -i
Docker安装
docker-compose安装
# docker
git clone https://github.com/apache/apisix-docker.git
# 进入目录
cd apisix-docker/example
# 可以查看和修改文件,这里将apisix-dashboard暴露本机端口改为19000
vim docker-compose.yml
# 使用docker-compose启动APISIX
docker-compose -p docker-apisix up -d
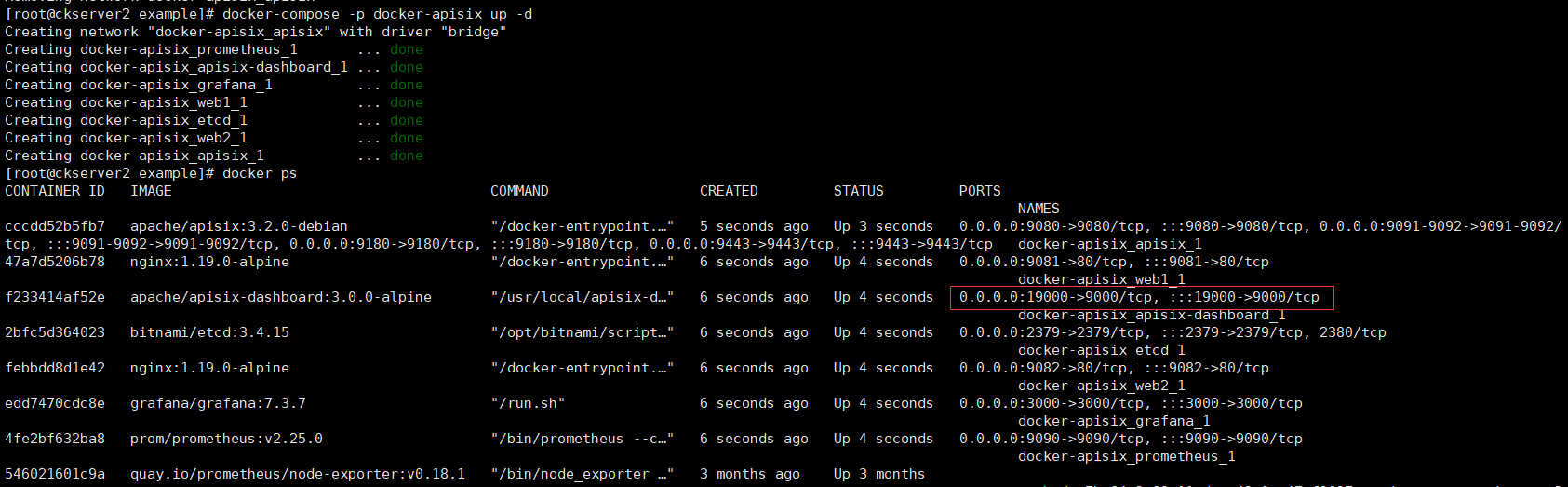
访问http://hadoop2:19000,输入用户名密码admin/admin即可登录成功(密码配置在docker-compose指定的配置文件dashboard_conf/conf.yaml中)
apisix-dashboard简单使用
仪表板
dashboard 可视化 WEB 控制台,可以很直观的进行 router 、upstream 等配置。登录后的首页即为仪表板,这是通过在iframe中引用监视器页面来支持它可以配置grafana的地址,比如配置http://grafanaip:3000,快捷操作grafana
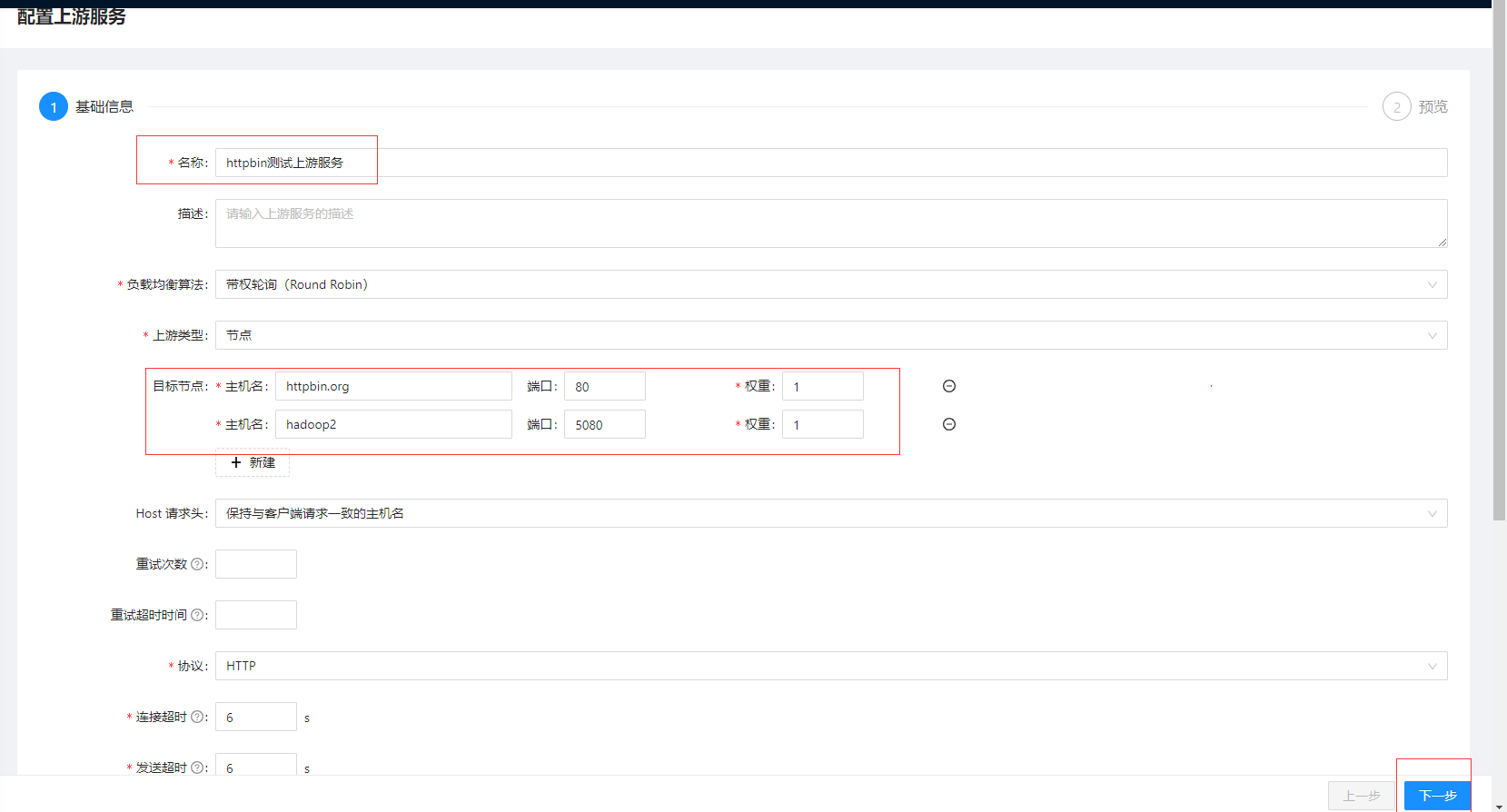
配置测试上游
# 现在本地搭建httpbin服务
docker run -p 5080:80 kennethreitz/httpbin
点击上游菜单,点击创建按钮,目标节点添加httpbin.org和上面我们刚部署内网httpbin,其他暂时默认,点击下一步然后提交。
配置测试路由
点击路由菜单,点击创建按钮,目标节点添加httpbin.org和上面我们刚部署内网httpbin,其他暂时默认,点击下一步然后提交。
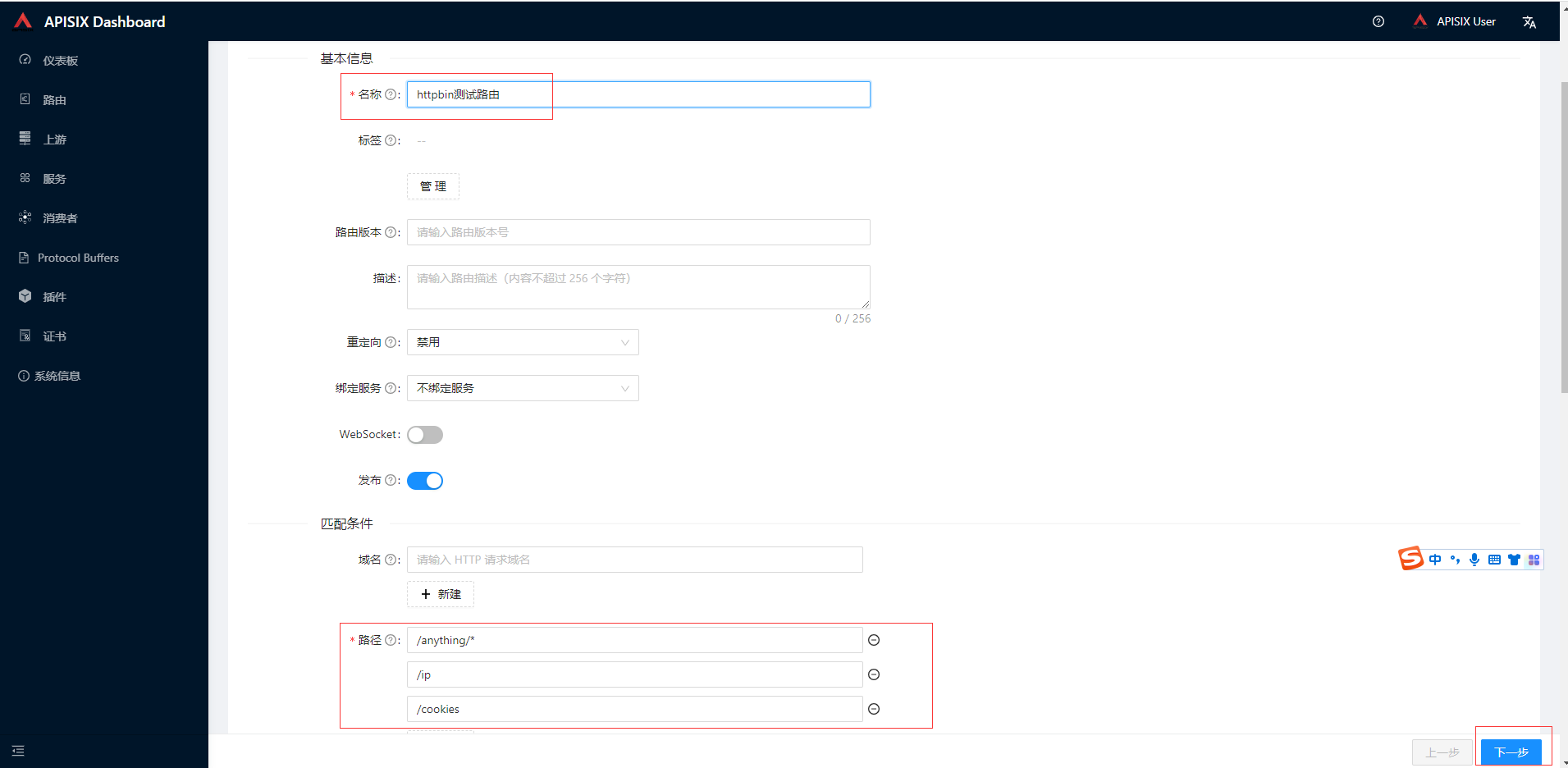
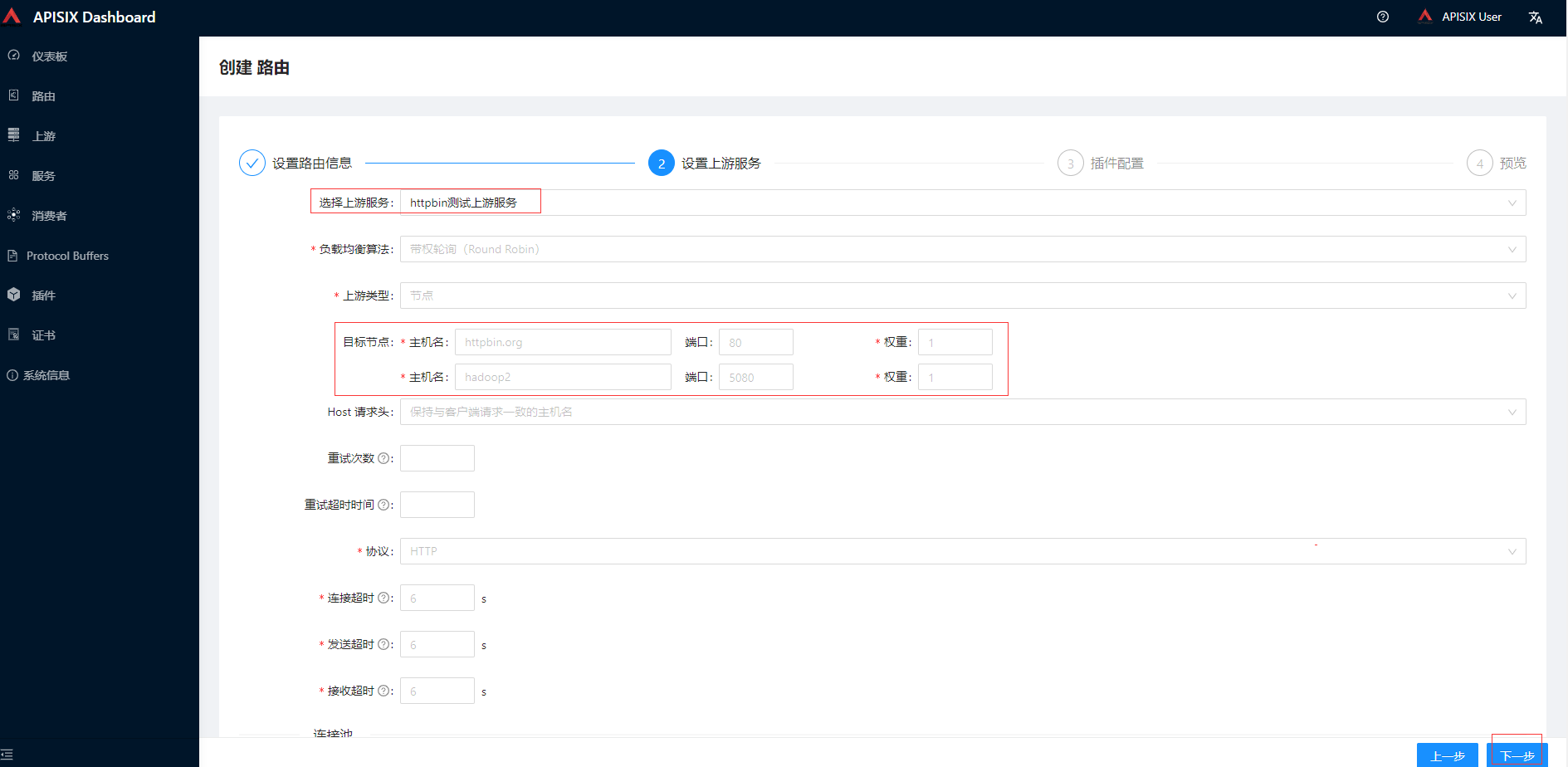
设置上游服务选择前面创建的,其他先保持默认,最后提交
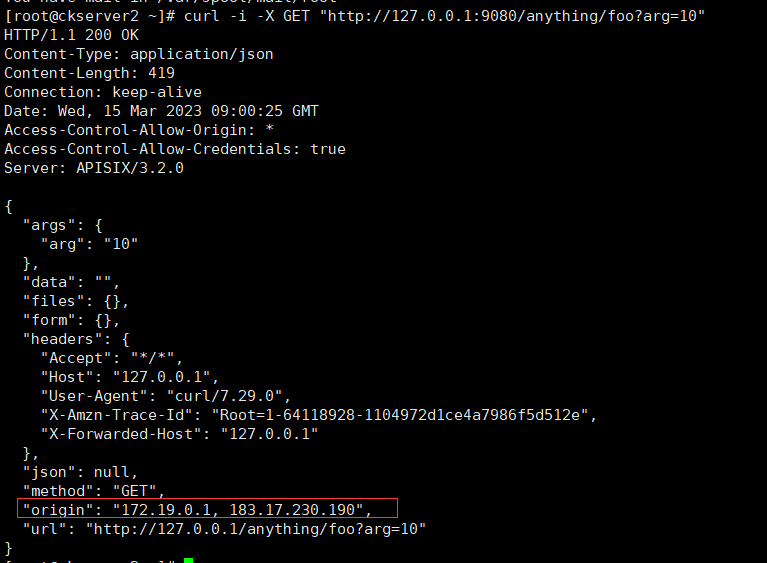
执行访问测试
curl -i -X GET "http://127.0.0.1:9080/anything/foo?arg=10"
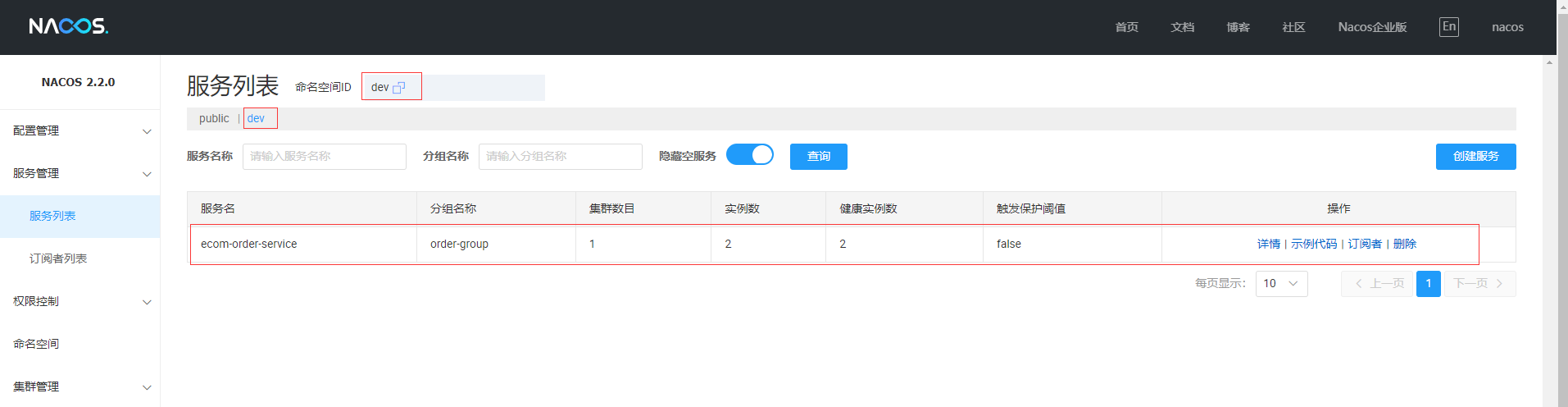
整合Nacos
- 先准备演示订单微服务并向Nacos注册,关于Nacos可翻看前面的文章
- 在apisix 的conf/config.yaml中添加以下配置,由于这里是用docker部署,路径在apisix-docker/example/apisix_conf
discovery:
nacos:
host:
- "http://nacos:nacos@192.168.3.113:8848"
prefix: "/nacos/v1/"
fetch_interval: 30 # default 30 sec
weight: 100 # default 100
timeout:
connect: 2000 # default 2000 ms
send: 2000 # default 2000 ms
read: 5000 # default 5000 ms
- 配置文件修改后重启apisix
docker-compose -p docker-apisix down
docker-compose -p docker-apisix up -d
- 在添加order上游,输入服务类型信息点击下一步和提交
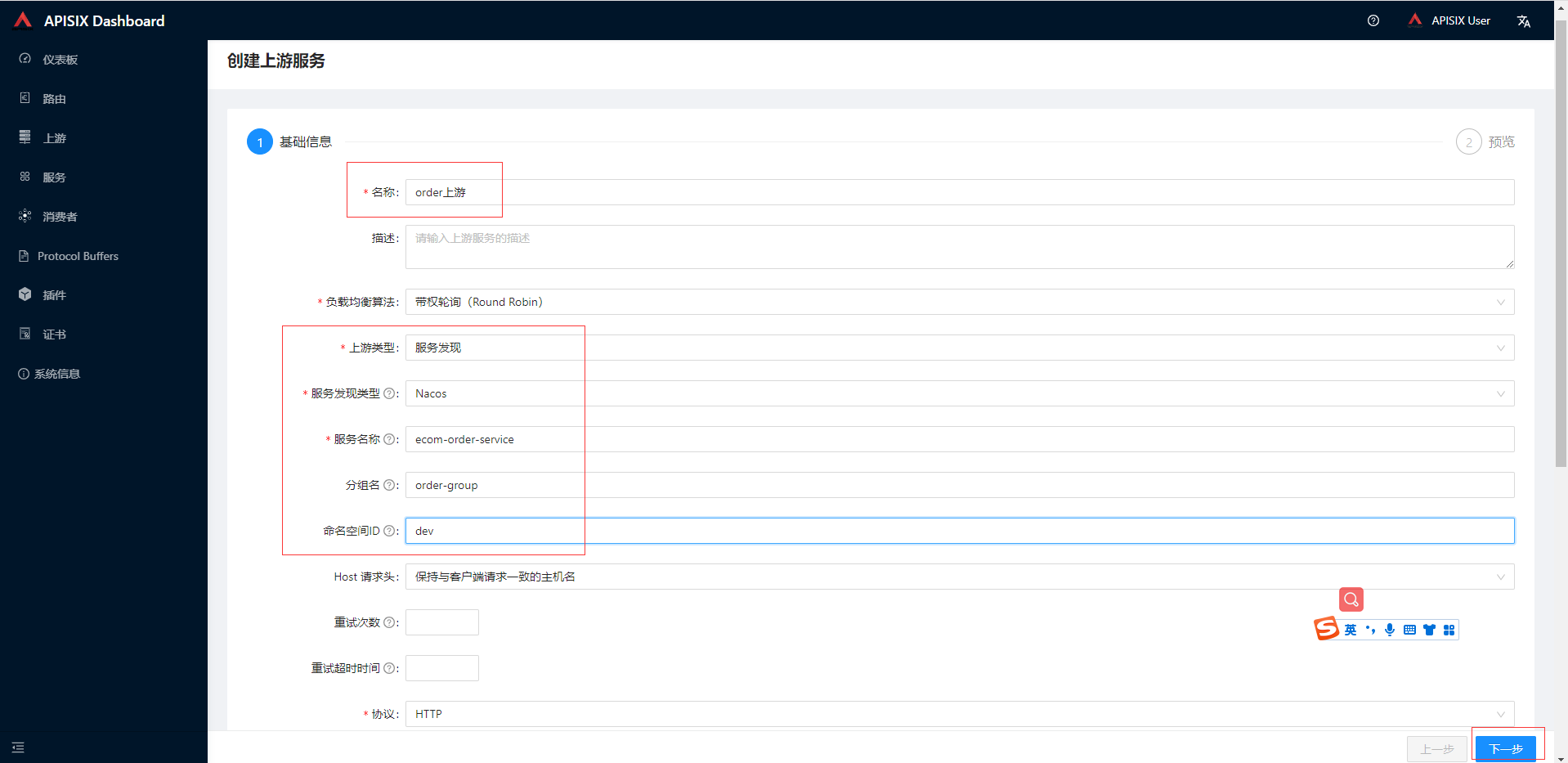
添加order路由,输入路径信息点击下一步
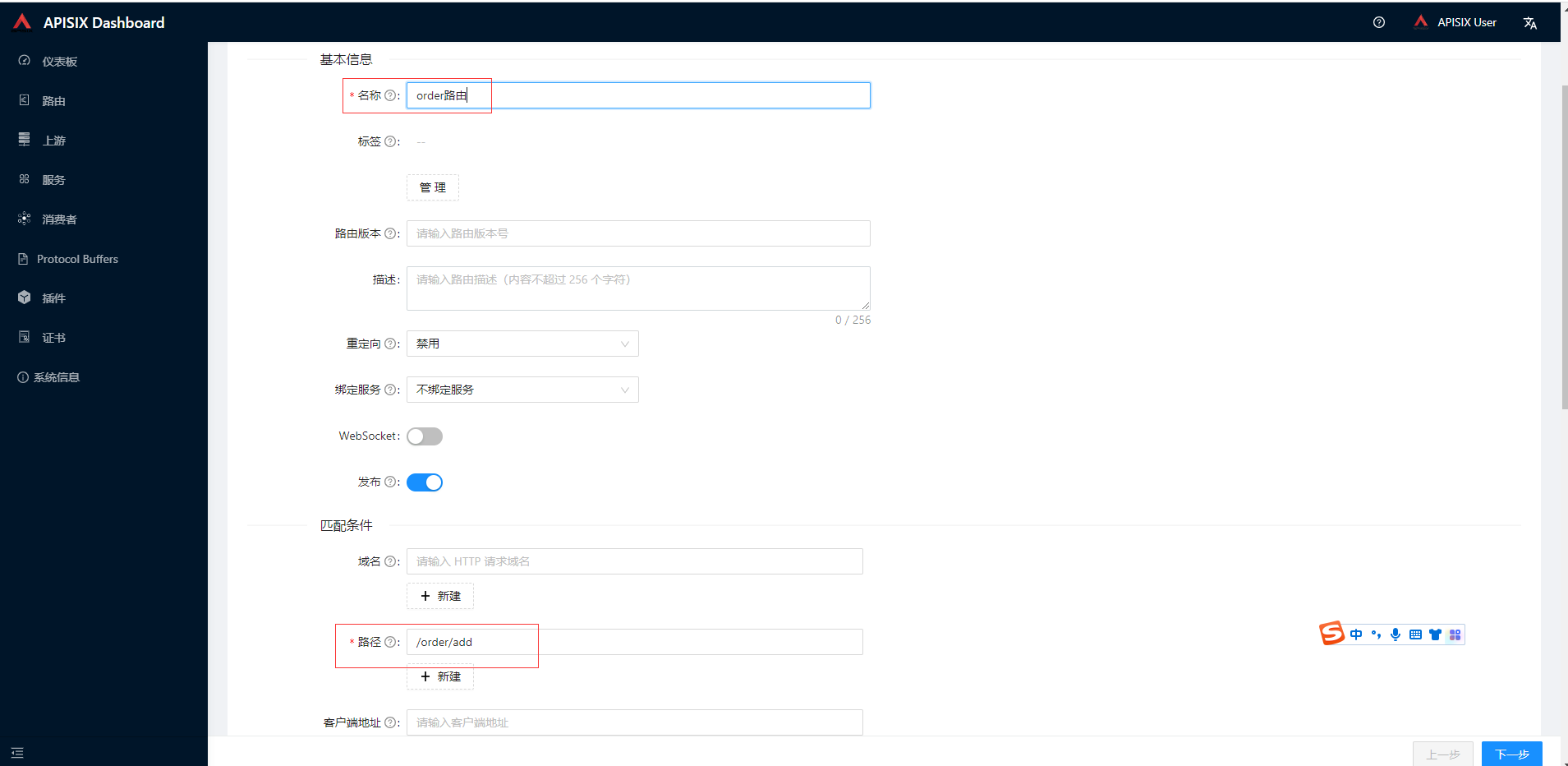
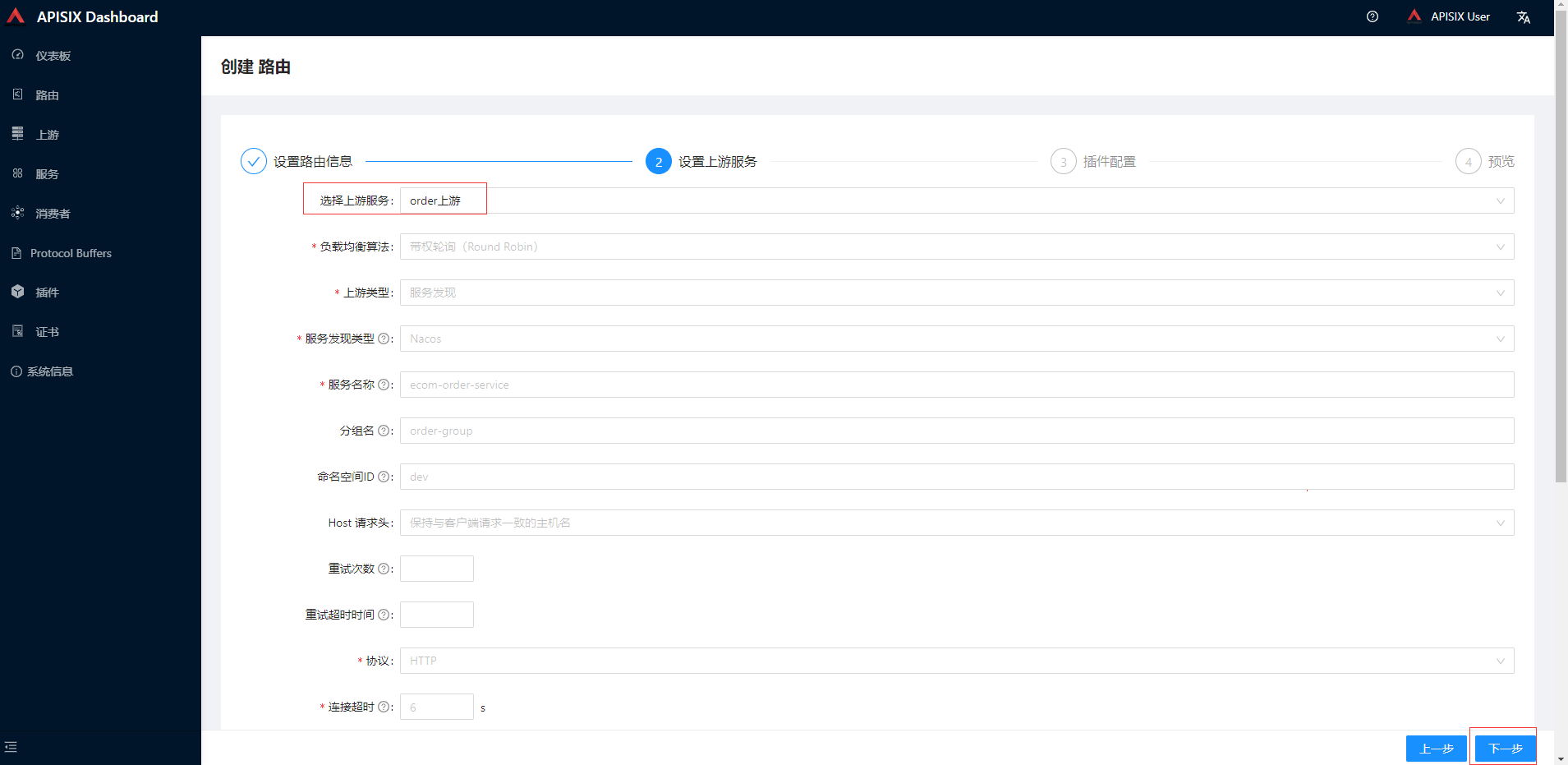
路由中选择前面添加order上游,其他默认最终提交
访问apisix监听地址,http://hadoop2:9080/order/add,最后成功返回订单微服务的接口数据

开启SkyWalking插件链路追踪
- 部署skywalking,详细可以翻看前面关于skywalking的文章
- 同样在配置文件添加以下配置
plugins:
- skywalking # 启用skywalking插件
plugin_attr:
skywalking: # 配置skywalking的属性
service_name: APISIX_GATEWAY
service_instance_name: "APISIX_INSTANCE_GATEWAY"
endpoint_addr: http://192.168.3.113:12800 # skywalking的地址,本机默认是这个,可自行修改
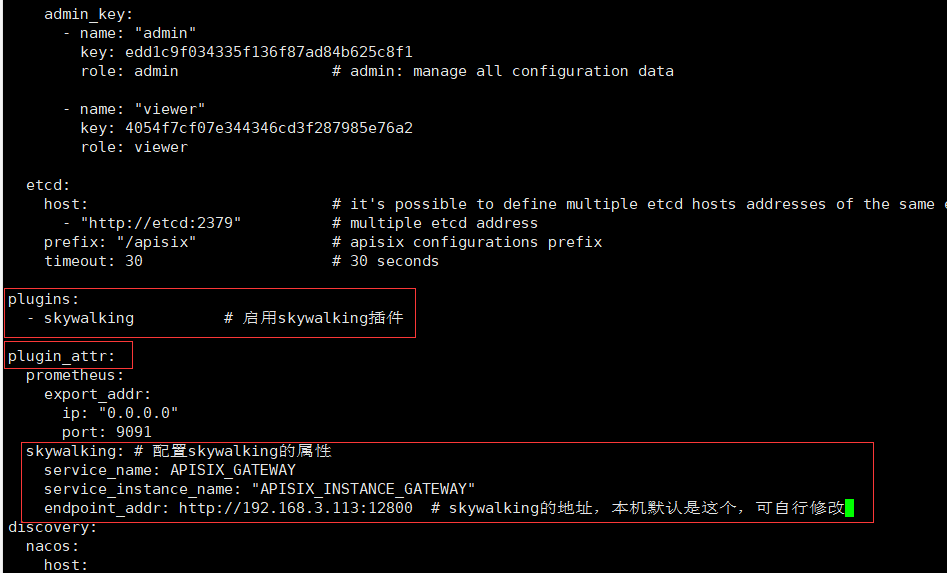
- 配置文件修改后重启apisix
- 在前面创建的order路由中开启SkyWalking插件,点击可观察性找到skywalking点击启动按钮
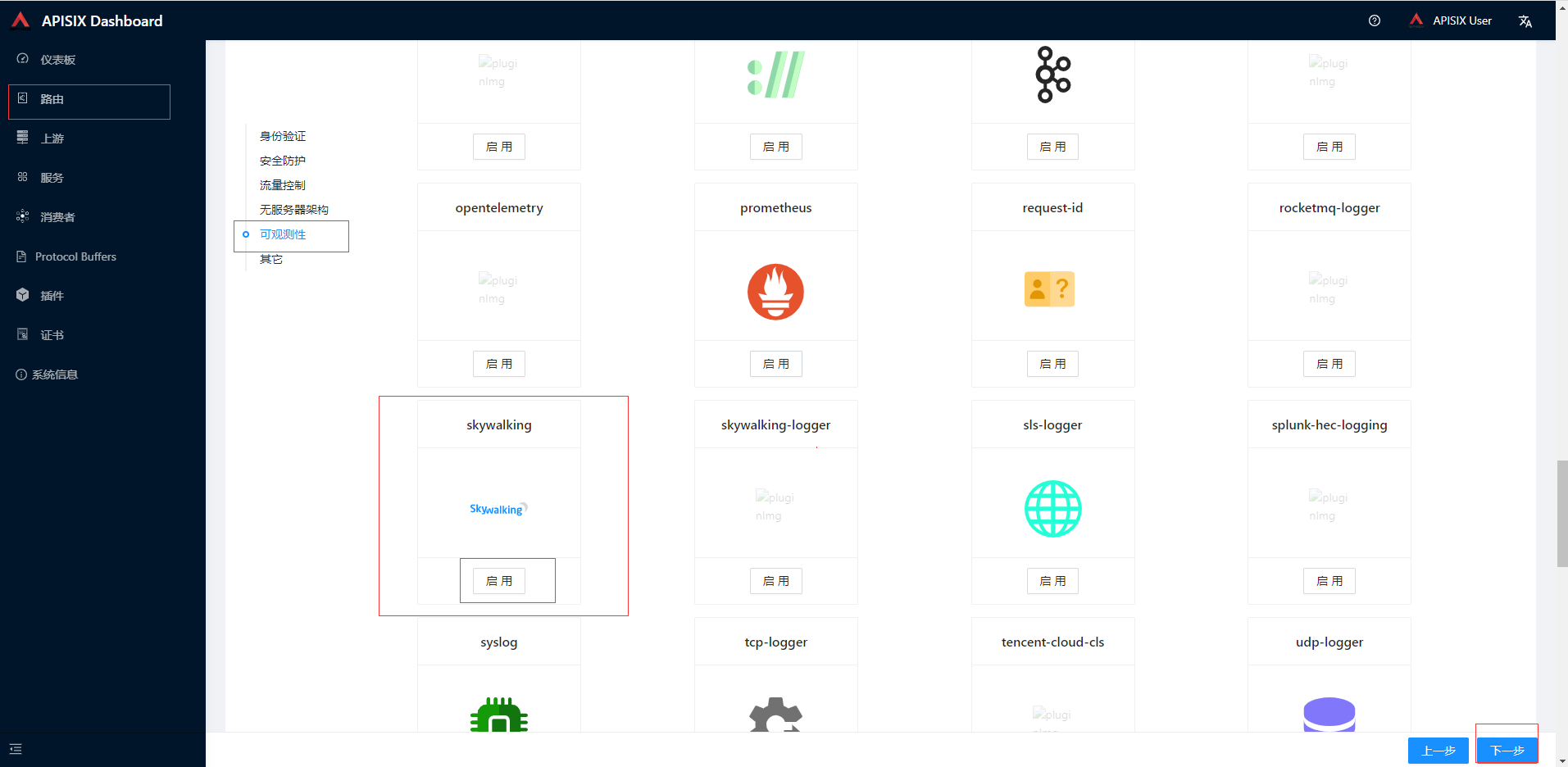
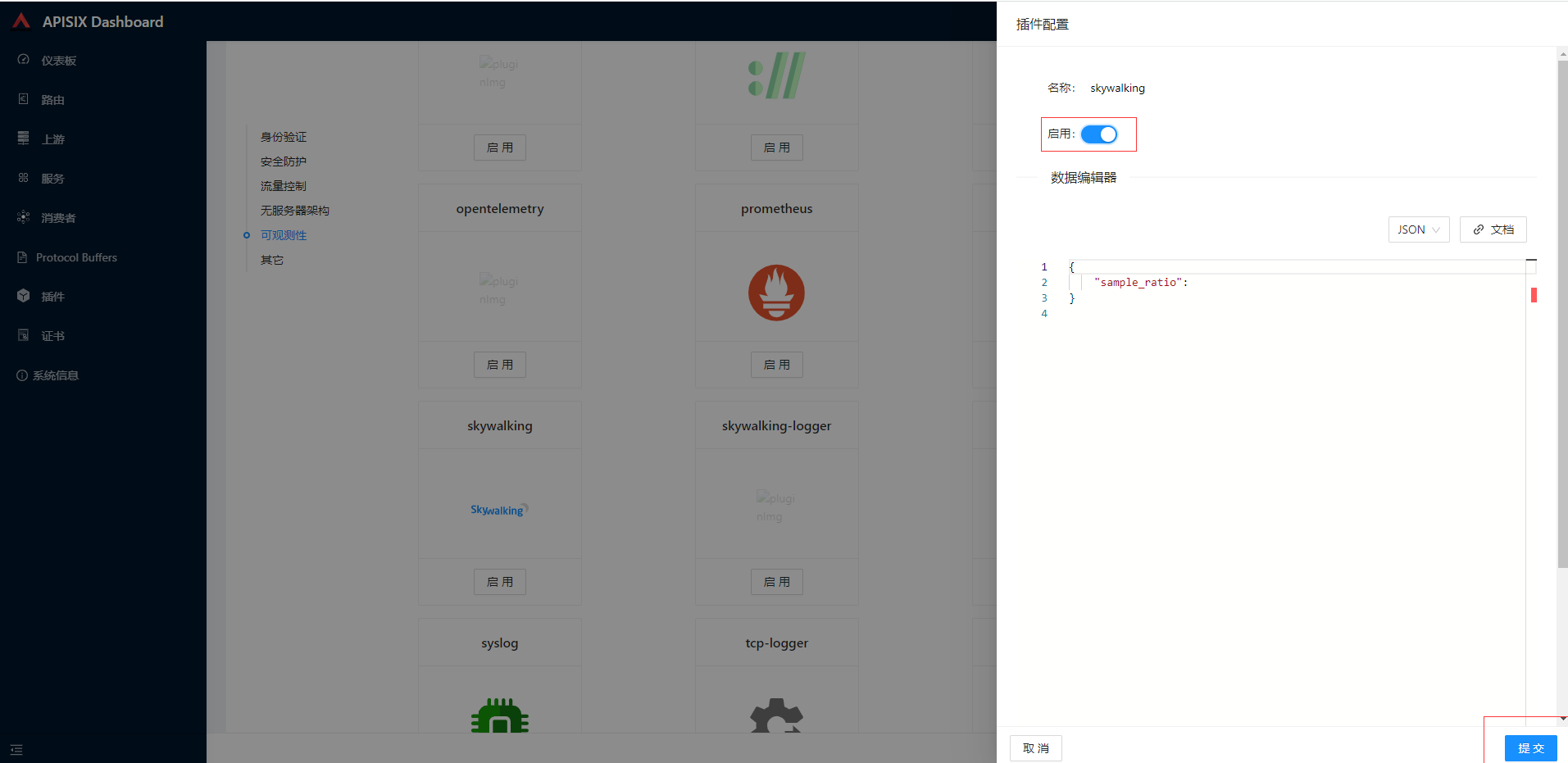
在弹出的页面的插件配置中点击启用按钮然后提交,然后一直下一步最后提交
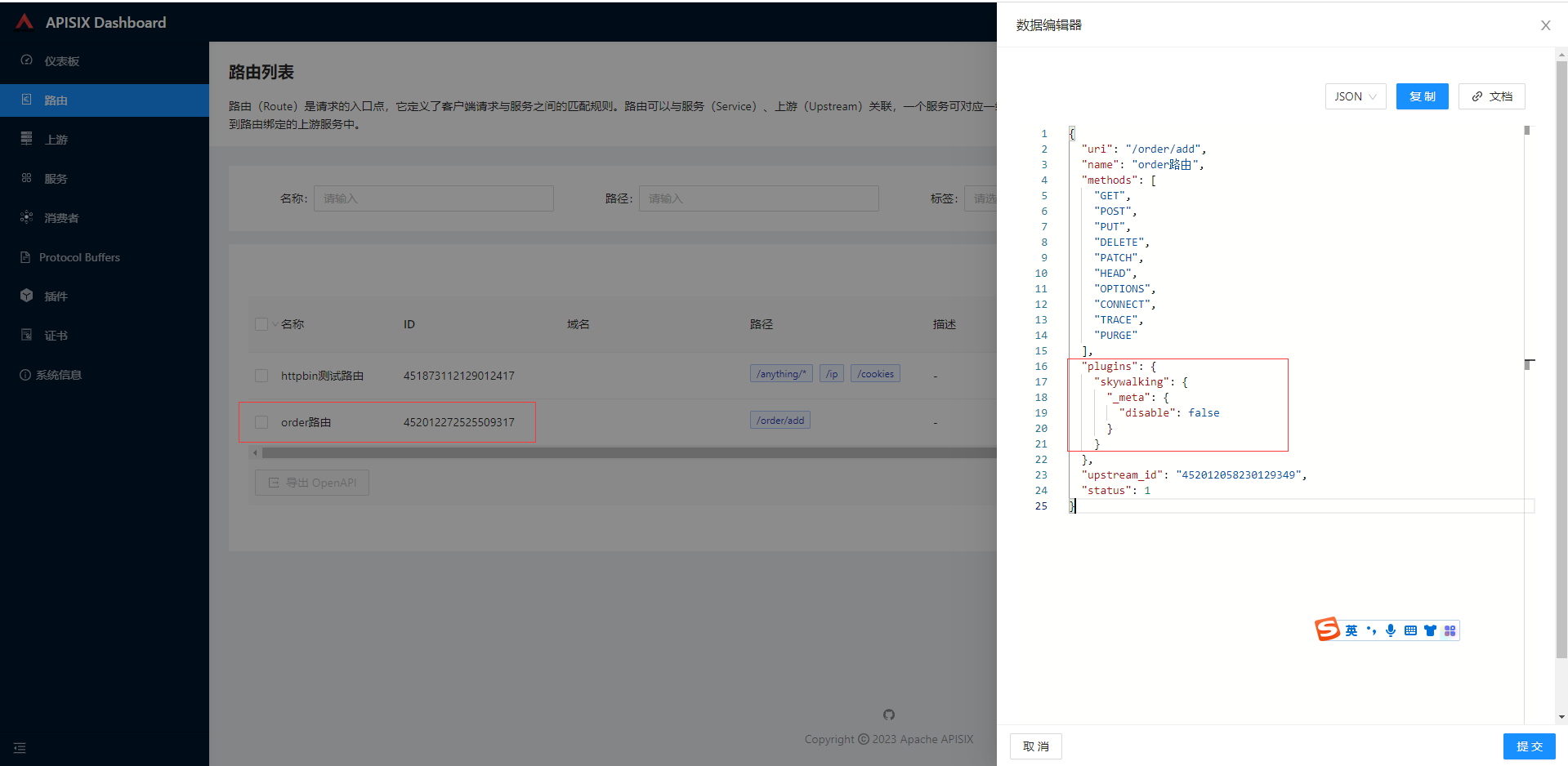
返回路由列表也可以通过操作-更多-查看,显示数据编辑器内容
- 在订单微服务中添加依赖
<dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm-toolkit-trace</artifactId>
<version>8.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm-toolkit-logback-1.x</artifactId>
<version>8.14.0</version>
</dependency>
在logback-spring.xml添加打印skywalking链路日志信息
<configuration debug="false" scan="false">
<springProperty scop="context" name="spring.application.name" source="spring.application.name" defaultValue=""/>
<property name="log.path" value="logs/${spring.application.name}"/>
<!-- 彩色日志格式 -->
<property name="CONSOLE_LOG_PATTERN"
value="${CONSOLE_LOG_PATTERN:-%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}"/>
<!-- 彩色日志依赖的渲染类 -->
<conversionRule conversionWord="clr" converterClass="org.springframework.boot.logging.logback.ColorConverter"/>
<conversionRule conversionWord="wex"
converterClass="org.springframework.boot.logging.logback.WhitespaceThrowableProxyConverter"/>
<conversionRule conversionWord="wEx"
converterClass="org.springframework.boot.logging.logback.ExtendedWhitespaceThrowableProxyConverter"/>
<!-- Console log output -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
</encoder>
</appender>
<!-- Log file debug output -->
<appender name="debug" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log.path}/debug.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>${log.path}/%d{yyyy-MM, aux}/debug.%d{yyyy-MM-dd}.%i.log.gz</fileNamePattern>
<maxFileSize>50MB</maxFileSize>
<maxHistory>30</maxHistory>
</rollingPolicy>
<encoder>
<pattern>%date [%thread] %-5level [%logger{50}] %file:%line - %msg%n</pattern>
</encoder>
</appender>
<!-- Log file error output -->
<appender name="error" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log.path}/error.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>${log.path}/%d{yyyy-MM}/error.%d{yyyy-MM-dd}.%i.log.gz</fileNamePattern>
<maxFileSize>50MB</maxFileSize>
<maxHistory>30</maxHistory>
</rollingPolicy>
<encoder>
<pattern>%date [%thread] %-5level [%logger{50}] %file:%line - %msg%n</pattern>
</encoder>
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>ERROR</level>
</filter>
</appender>
<appender name="stdout" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.TraceIdPatternLogbackLayout">
<Pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%tid] [%thread] %-5level %logger{36} -%msg%n</Pattern>
</layout>
</encoder>
</appender>
<appender name="grpc" class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.log.GRPCLogClientAppender">
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.mdc.TraceIdMDCPatternLogbackLayout">
<Pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%X{tid}] [%thread] %-5level %logger{36} -%msg%n</Pattern>
</layout>
</encoder>
</appender>
<!--nacos 心跳 INFO 屏蔽-->
<logger name="com.alibaba.nacos" level="OFF">
<appender-ref ref="error"/>
</logger>
<!-- Level: FATAL 0 ERROR 3 WARN 4 INFO 6 DEBUG 7 -->
<root level="INFO">
<!-- <appender-ref ref="console"/>-->
<appender-ref ref="debug"/>
<appender-ref ref="error"/>
<appender-ref ref="stdout"/>
<appender-ref ref="grpc"/>
</root>
</configuration>
将agent.config 拷贝到订单微服务的resources目录下,库存微服务修改agent.config下面两个配置,详细查阅skywalking前面的文章
agent.service_name=${SW_AGENT_NAME:ecom-storage-service}
collector.backend_service=${SW_AGENT_COLLECTOR_BACKEND_SERVICES:192.168.3.113:11800}
# 启动jvm参数增加
-javaagent:F:\commoms\skywalking-agent\skywalking-agent.jar
-Dskywalking_config=F:\dev\simple-ecommerce\ecom-storage-service\src\main\resources\agent.config
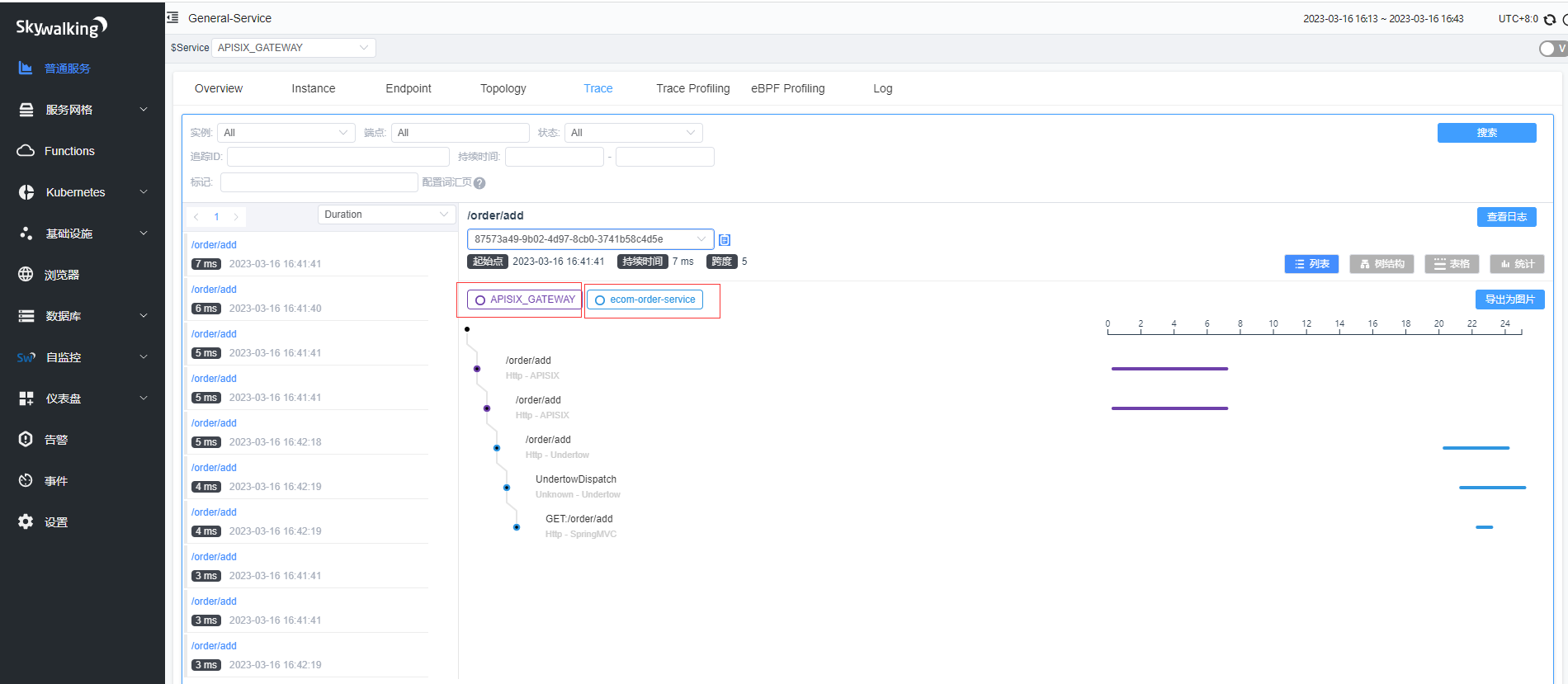
访问http://hadoop2:9080/order/add多次看下,在普通服务就可以看到订单微服务和APISIX_GATEWAY。
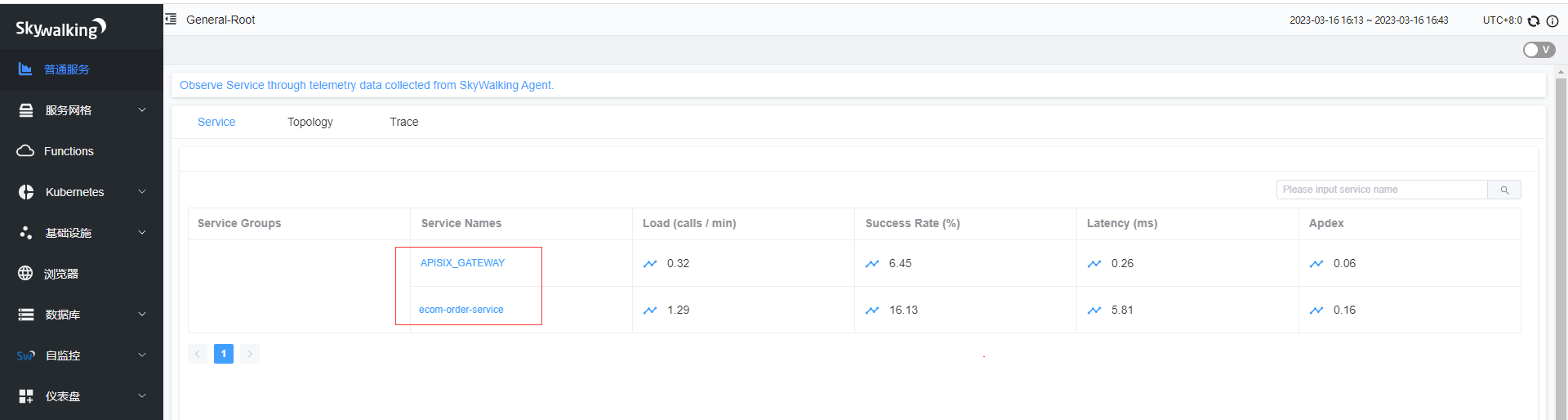
通过Trace可以看到日志链路经过了APISIX_GATEWAY和订单微服务,至此基本整合演示完毕
- 本人博客网站IT小神 www.itxiaoshen.com
云原生API网关全生命周期管理Apache APISIX探究实操的更多相关文章
- [转载]DevOps建立全生命周期管理
全生命周期管理(ALM)领域作为企业DevOps实践的总体支撑,应该说是DevOps领域中最为重要的实践领域,也是所有其他实践的基础设施.现在很多企业都非常重视CI/CD自动化工具的引入和推广,但是对 ...
- 微服务手册:API接口9个生命节点,构建全生命周期管理
互联网应用架构:专注编程教学,架构,JAVA,Python,微服务,机器学习等领域,欢迎关注,一起学习. 对于API,在日常的工作中是接触最多的东西,特别是我们软件这一行,基本就是家常便饭了,在百度百 ...
- 云原生 API 网关,gRPC-Gateway V2 初探
gRPC-Gateway 简介 我们都知道 gRPC 并不是万能的工具. 在某些情况下,我们仍然想提供传统的 HTTP/JSON API.原因可能从保持向后兼容性到支持编程语言或 gRPC 无法很好地 ...
- Uber三代API 生命周期管理平台实现 Uber
Uber三代API 生命周期管理平台实现 - InfoQ https://www.infoq.cn/article/H8Ml6L7vJGQz0efpWvyJ Uber 三代 API 生命周期管理平台实 ...
- HDD深圳站:全生命周期赋能开发者,华为引领应用生态升级
12月14日,由华为开发者联盟主办的HDD(HUAWEI Developer Day)于深圳举行.此次HDD主论坛,围绕打造应用全生命周期服务,介绍了华为在创新孵化.开发测试.应用分发和运营增长阶段的 ...
- Akka(2):Actor生命周期管理 - 监控和监视
在开始讨论Akka中对Actor的生命周期管理前,我们先探讨一下所谓的Actor编程模式.对比起我们习惯的行令式(imperative)编程模式,Actor编程模式更接近现实中的应用场景和功能测试模式 ...
- 详解服务器性能测试的全生命周期?——从测试、结果分析到优化策略(转载)
服务器性能测试是一项非常重要而且必要的工作,本文是作者Micheal在对服务器进行性能测试的过程中不断摸索出来的一些实用策略,通过定位问题,分析原因以及解决问题,实现对服务器进行更有针对性的优化,提升 ...
- 从大厂DevOps工具链部署,看现代产品的生命周期管理
目录 1. 认识DevOps 1.1. DevOps工具链 1.2. CI 持续集成(Continuous Integration) 1.3. CD(持续交付 & 持续部署) 1.4. Agi ...
- Elasticsearch7.X ILM索引生命周期管理(冷热分离)
Elasticsearch7.X ILM索引生命周期管理(冷热分离) 一.“索引生命周期管理”概述 Elasticsearch索引生命周期管理指:Elasticsearch从设置.创建.打开.关闭.删 ...
- Elasticsearch索引生命周期管理方案
一.前言 在 Elasticsearch 的日常中,有很多如存储 系统日志.行为数据等方面的应用场景,这些场景的特点是数据量非常大,并且随着时间的增长 索引 的数量也会持续增长,然而这些场景基本上只有 ...
随机推荐
- js字符串截取(获取指定字符后面的所有字符内容)
function getCaption(obj, text){ let index = obj.lastIndexOf(text) + text.length-1; obj = obj.substri ...
- Kubernetes--Ingress资源类型
Ingress资源类型 基于HTTP暴露的每个Service资源均可发布于一个独立的FQDN主机名之上,如 " www.ik8s.io " :也可发布于某主机上的URL路径之上,从 ...
- 2020-2021第一学期2024"DCDD"小组第十周讨论
2020-2021第一学期"DCDD"第十周讨论 小组名称:DCDD 小组成员:20202403孟凡斌.20202411陈书桓.20202416刘铭睿.20202420黄椿淇 照例 ...
- OOP前三次作业总结
一.前言 在开始OOP学习之前,我从未了解过什么是面向对象编程,想当然的认为OOP是像从前学习C一样的编程逻辑(即面向过程编程),但在真正开始学习OOP之后,我了解到了以往面向过程编程的局限性与不便利 ...
- luogu 1344
首先题意就是裸的最小割啦 然后考虑如何统计边数 这里有一个trick: 我们设定一个大于$m$的阈值,对于每条边的边权我们乘这个阈值+1后跑最小割,得到的答案除以阈值就是真正的最小割,取模阈值后就是最 ...
- token能放在cookie中吗
能. token一般是用来判断用户是否登录的, 它内部包含的信息有: uid(用户唯一的身份标识). time(当前时间的时间戳). sign(签名,token 的前几位以哈希算法压缩成的一定长度的十 ...
- vue+antd实现PDF预览(后端返回的是文件流)
操作步骤: 第一步:下载包 npm install --save vue-pdf 第二步:导入组件 第三步:使用pdf标签进行展示,showUrl指的是访问路径 第四步:定义要用到的变量 第五步: ...
- lightgbm与贷款违约预测项目
lightgbm histogram算法 将连续的浮点值离散成k个离散值,构造宽度为k的histogram leaf-wise生长策略 每次在所有叶子中找到分裂增益最大的一个叶子,一般也是数据量最大的 ...
- 项目实训 DAY 13
GraphCore学习成本太高/现有资料太少,决定放弃 PlotNN用python语言生成pdf(需求:png),且不能通过仅运行python程序实现,python内生成的是tex格式,还需要加一行命 ...
- mysql datetime和timestamp区别
datetime: 保存格式为YYYYMMDDHHMMSS的整数,与时区无关,存入什么值就是什么值,不会根据当前时区进行转换.mysql5.6.4中可以存储小数片段,最多小数点后6位,在mysql5. ...