2019-02-08 Python学习之Scrapy的简单了解
今天遇到的问题和昨天差不多,一个Scrapy装了好久,anaconda卸了又装,pycharm卸了又装,环境变量配置一堆,依赖包下载一堆。查了一堆资料总算是搞好了。
Scripy:
先放个框架结构图(来自嵩天老师mooc)
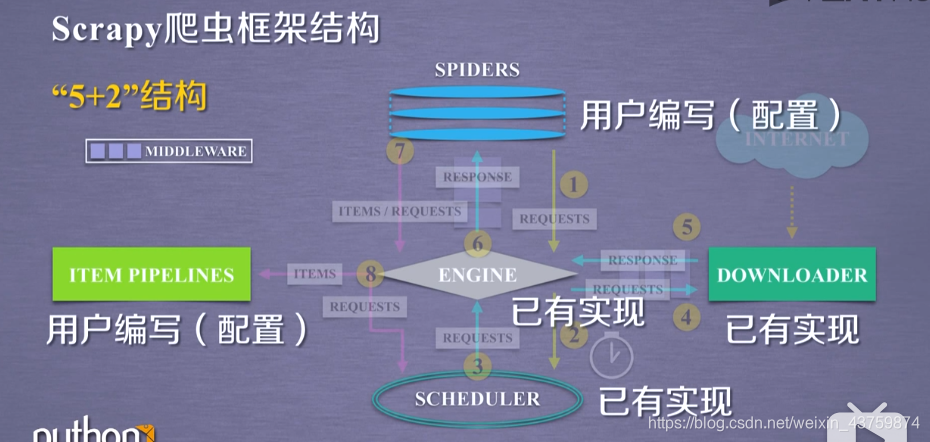
Scrapy 爬虫的使用步骤
- 创建一个工程和spider模板
- 编写spider
- 编写Item Pipeline
- 优化配置策略
两种风格的demospider写法:
class DemoSpider(scrapy.Spider):
name = 'demo'
#allowed_domains = ['python123.io']
start_urls = ['http://python123.io/ws/demo.html'] #启动时最开始的链接
def parse(self, response): #解析和操作的相关步骤
fname = response.url.split('/')[-1] #文件名叫demo.html(切片,得到最后一个)
with open(fname,'wb+') as f:
f.write(response.body)
self.log = ('saved file %s.'% fname)
class DemoSpider(scrapy.Spider):
name = "demo"
def start_requests(self):
urls = [
'http://python123.io/ws/demo.html'
]
for url in urls:
yield scrapy.Request(url=url,callback=self.parse)
def parse(self,response):
fname = response.url.split('/')[-1]
with open(fname,'wb') as f:
f.write(response.body)
self.log('Save file %s.' % fname)
几种类:
Request类
class scrapy.http.Request()
- Request对象生成一个HTTP请求
- 由Spider生成,由Downloader执行
属性和方法
.url 对应请求的url地址
.method 请求方法
.headers 字典类型风格的请求头
.body 请求内容主题
.meta 用户添加的扩展信息
.copy() 复制该响应
Response类
class scrapy.http.Request()
- Response对象表示一个http响应
- 由downloader生成,spider来处理
属性和方法
.urls Response对应的url地址
.status HTTP状态码
.headers Response对应的头部信息
.body Response对应的内容信息
.flags 一组标记
.request 产生Response类型对应的Request对象
.copy() 复制该响应
Item类
class scrapy.item.Item()
- Item对象表示一个从HTML页面中提取的信息内容
- 由Spider生成,由Item Pipeline进行处理
- Item类似字典类型,可以按照字典类型进行相关操作\
Scrapy爬虫提取信息的方法
BeautifulSoup
lxml
re
CSS selector
XPath selector
2019-02-08 Python学习之Scrapy的简单了解的更多相关文章
- 08 python学习笔记-随机生成大乐透号码(八)
1 #产生大乐透号码 2 #前区 1-32,5 后区 1-12,2 3 #1.前区从1-32中级取5个,后区再从1-12里面取2个 4 #01 02 03 04 5 def dlt(): #生成随机大 ...
- CF-1110 (2019/02/08)
CF-1110 A. Parity 快速幂的思想,考虑最后一位即可 #include <bits/stdc++.h> using namespace std; typedef long l ...
- python学习笔记(3)--turtle简单绘制
参考:大学生mooc 北京理工大学的python程序与设计课程 蟒蛇绘制代码如下: #pythonDraw.py import turtle turtle.setup(650,350,200,200) ...
- python学习笔记(excel简单操作)
现在的目标是设计一个接口自动化测试框架 用例写在excel里面 利用python自带的pyunit构建 之前已经安装好了处理excel的模块 这次简单的使用下 提前创建好excel文件 “testca ...
- Python学习笔记3:简单文件操作
# -*- coding: cp936 -*- # 1 打开文件 # open(fileName, mode) # 參数:fileName文件名称 # mode打开方式 # w 以写方式打开. ...
- Python学习-字典练习:简单通讯录
功能要求: 查询联系人,输入姓名,可以查询当前通讯录里面的联系人信息,若联系人存在,则输出联系人信息,若不存在,则告知 插入联系人,可以向通讯录中新建联系人,若联系人已经存在,则询问是否修改联系人信息 ...
- python 学习分享-实战篇简单的ftp
import socket import os import time import pickle Basedb = os.path.dirname(os.path.dirname(os.path.a ...
- VS2013中Python学习笔记[Django Web的第一个网页]
前言 前面我简单介绍了Python的Hello World.看到有人问我搞搞Python的Web,一时兴起,就来试试看. 第一篇 VS2013中Python学习笔记[环境搭建] 简单介绍Python环 ...
- Python学习基础笔记(全)
换博客了,还是csdn好一些. Python学习基础笔记 1.Python学习-linux下Python3的安装 2.Python学习-数据类型.运算符.条件语句 3.Python学习-循环语句 4. ...
随机推荐
- vscode格式化Vue出现的问题:单引号变双引号 格式化去掉分号
学习vue框架时,发现在使用vscode格式化vue代码时,出现单引号变成了双引号问题(导致和EsLint要求不一致),从而导致报错!!!!好坑啊!!! 解决方法如下 在文件根目录下创建 .prett ...
- php实用正则
1 Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$ 2 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z ...
- Jmeter执行多个sql查询语句
1.添加jdbc connection(注意标红部分) 2.添加jdbc request 3.查看结果树 本文主要向大家介绍了Oracle数据库之jmeter jdbc request 如何运行多个s ...
- JAVA WEB EL表达式注入
看猪猪侠以前的洞,顺便总结下: 一.EL表达式简介 EL 全名为Expression Language.EL主要作用: 1.获取数据 EL表达式主要用于替换JSP页面中的脚本表达式,以从各种类型的we ...
- Node.js躬行记(2)——文件系统和网络
一.文件系统 fs模块可与文件系统进行交互,封装了常规的POSIX函数.POSIX(Portable Operating System Interface,可移植操作系统接口)是UNIX系统的一个设计 ...
- WebSocket是什么,有什么作用和特点?
WebSocket是一种在单个TCP连接上进行全双工通信的协议. Websocket是基于HTTP协议的,或者说借用了HTTP的协议来完成一部分握手.具有持久化的特性 特点: 保持连接状态.与HTTP ...
- 【HIVE】数据分析HQL的编写方法/思路
SQL编写一般思路: 1)复杂的查询,先划分为小任务,以降低难度.分别实现各个小任务后,再进行汇总: 2)涉及多表时,先进行联表查询: 3)简单分组,一般只需要group by即可: 4)组内TopN ...
- Java实现 LeetCode 788 旋转数字(暴力)
788. 旋转数字 我们称一个数 X 为好数, 如果它的每位数字逐个地被旋转 180 度后,我们仍可以得到一个有效的,且和 X 不同的数.要求每位数字都要被旋转. 如果一个数的每位数字被旋转以后仍然还 ...
- (Java实现) 洛谷 P1028 数的计算
题目描述 我们要求找出具有下列性质数的个数(包含输入的自然数nn): 先输入一个自然数n(n≤1000),然后对此自然数按照如下方法进行处理: 不作任何处理; 在它的左边加上一个自然数,但该自然数不能 ...
- Java实现 LeetCode 349 两个数组的交集
349. 两个数组的交集 给定两个数组,编写一个函数来计算它们的交集. 示例 1: 输入: nums1 = [1,2,2,1], nums2 = [2,2] 输出: [2] 示例 2: 输入: num ...