用 Explain 命令分析 MySQL 的 SQL 执行
在上一篇文章《MySQL常见加锁场景分析》中,我们聊到行锁是加在索引上的,但是复杂的 SQL 往往包含多个条件,涉及多个索引,找出 SQL 执行时使用了哪些索引对分析加锁场景至关重要。
比如下面这样的 SQL:
mysql> delete from t1 where id = 1 or val = 1
其中 id 和 val 都是索引,那么执行时使用到了哪些索引,加了哪些锁呢?为此,我们需要使用 explain 来获取 MySQL 执行这条 SQL 的执行计划。
什么是执行计划呢?简单来说,就是 SQL 在数据库中执行时的表现情况,通常用于 SQL 性能分析、优化和加锁分析等场景,执行过程会在 MySQL 查询过程中由解析器,预处理器和查询优化器共同生成。
MySQL 查询过程
如果能搞清楚 MySQL 是如何优化和执行查询的,不仅对优化查询一定会有帮助,还可以通过分析使用到的索引来判断最终的加锁场景。
下图是MySQL执行一个查询的过程。实际上每一步都比想象中的复杂,尤其优化器,更复杂也更难理解。本文只给予简单的介绍。
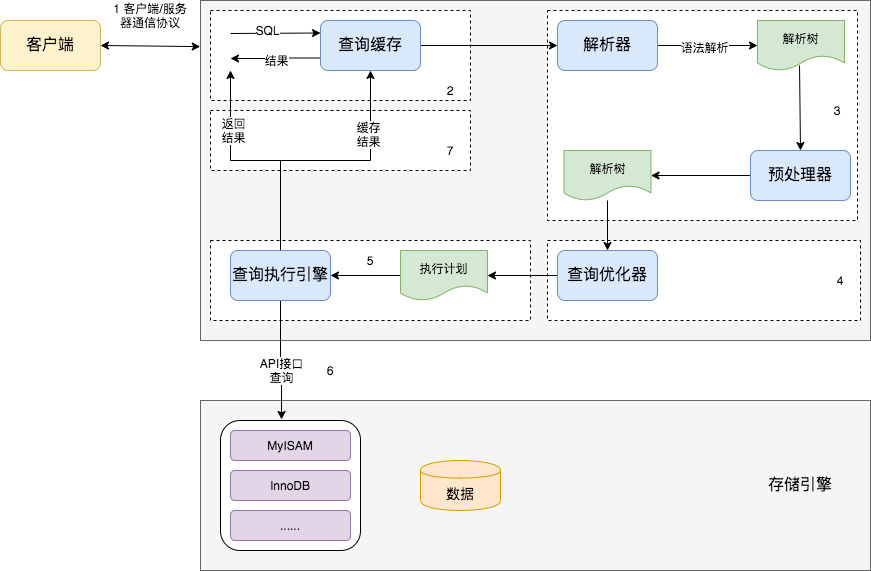
MySQL查询过程如下:
- 客户端发送一条查询给服务器。
- 服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果。否则进入下一阶段。
- 服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划。
- MySQL根据优化器生成的执行计划,再调用存储引擎的API来执行查询。
- 将结果返回给客户端。
执行计划
MySQL会解析查询,并创建内部数据结构(解析树),并对其进行各种优化,包括重写查询、决定表的读取顺序、选择合适的索引等。
用户可通过关键字提示(hint)优化器,从而影响优化器的决策过程。也可以通过 explain 了解 数据库是如何进行优化决策的,并提供一个参考基准,便于用户重构查询和数据库表的 schema、修改数据库配置等,使查询尽可能高效。
下面,我们依次介绍 explain 中相关输出参数,并以实际例子解释这些参数的含义。
select_type
查询数据的操作类型,有如下
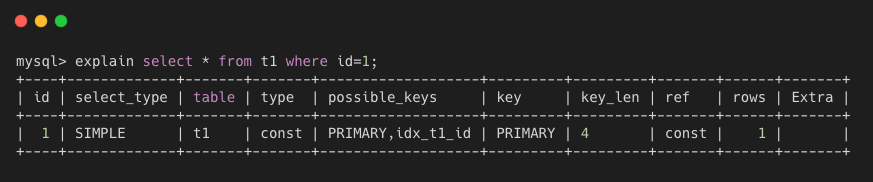
- simple 简单查询,不包含子查询或 union,如下图所示,就是最简单的查询语句。
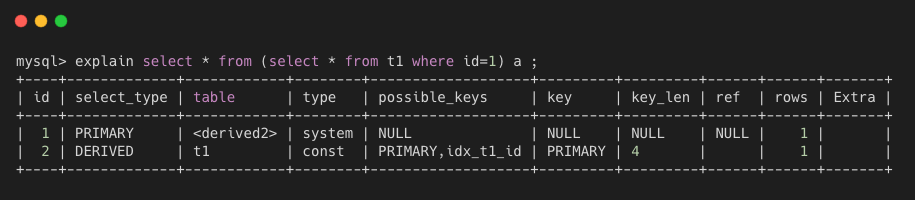
primary 是 SQL 中包含复杂的子查询,此时最外层查询标记为该值。
derived 是 SQL 中 from 子句中包含的子查询被标记为该值,MySQL 会递归执行这些子查询,把结果放在临时表。下图展示了上述两种类型。
- subquery 是 SQL 在 select 或者 where 里包含的子查询,被标记为该值。
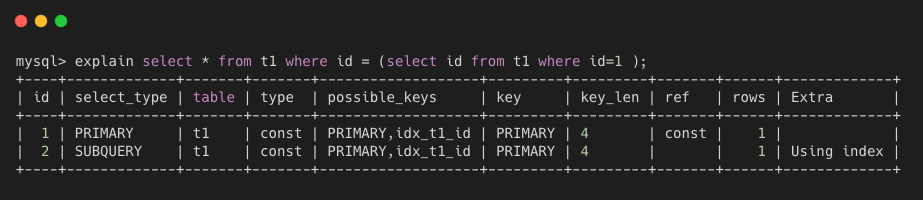
- dependent subquery:子查询中的第一个 select,取决于外侧的查询,一般是 in 中的子查询。
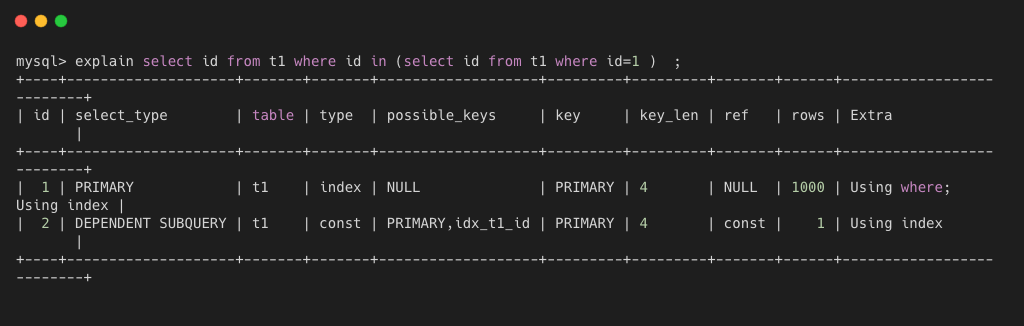
union 是 SQL 在出现在 union 关键字之后的第二个 select ,被标记为该值;若 union 包含在 from 的子查询中,外层select 被标记为 derived。
union result 从 union 表获取结果的 select。下图展示了 union 和 union result 的 SQL 案例。
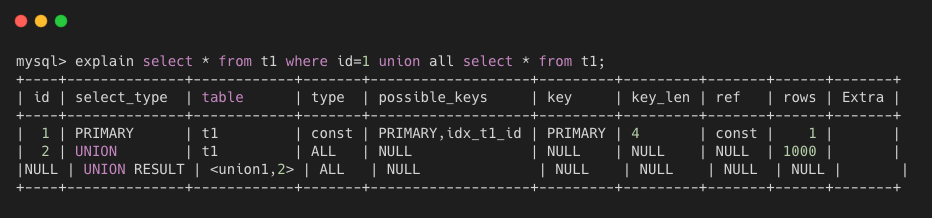
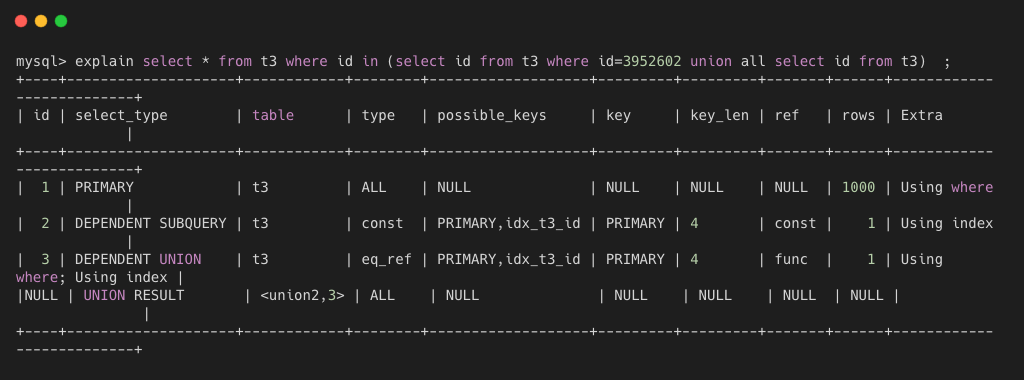
- dependent union 也是 union 关键字之后的第二个或者后边的那个 select 语句,和 dependent subquery 一样,取决于外面的查询。
type
表的连接类型,其性能由高到低排列为 system,const,eq_ref,ref,range,index 和 all。
- system 表示表只有一行记录,相当于系统表。如下图所示,因为 from 的子查询派生的表只有一行数据,所以 primary 的表连接类型为 system。
- const 通过索引一次就找到,只匹配一行数据,用于常数值比较PRIMARY KEY 或者 UNIQUE索引。
eq_ref 唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配,常用于主键或唯一索引扫描。对于每个来自前边的表的行组合,从该表中读取一行。它是除了 const 类型外最好的连接类型。
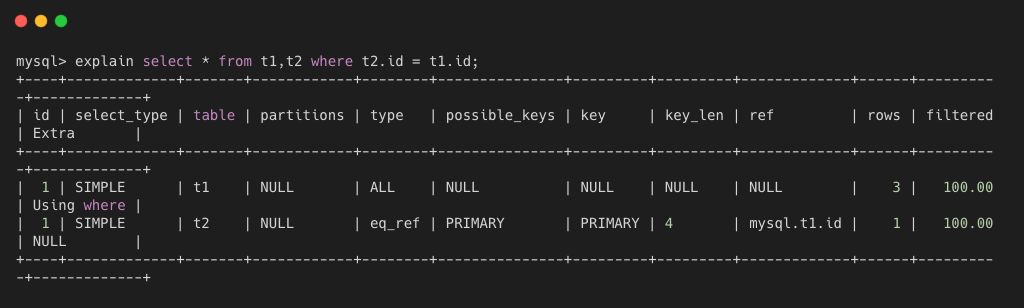
如下图所示,对表 t1 查询的 type 是 ALL,表示全表扫描,然后 t1 中每一行数据都来跟 t2.id 这个主键索引进行对比,所以 t2 表的查询就是 eq_ref。
- ref 非唯一性索引扫描,返回匹配某个单独值的所有行,和 eq_ref 的区别是索引是非唯一索引,具体案例如下所示。

- range 只检查给定范围的行,使用一个索引来选择行,当使用 =, between, >, <, 和 in 等操作符,并使用常数比较关键列时。如下图所示,其中 id 为唯一索引,而 val 是非唯一索引。
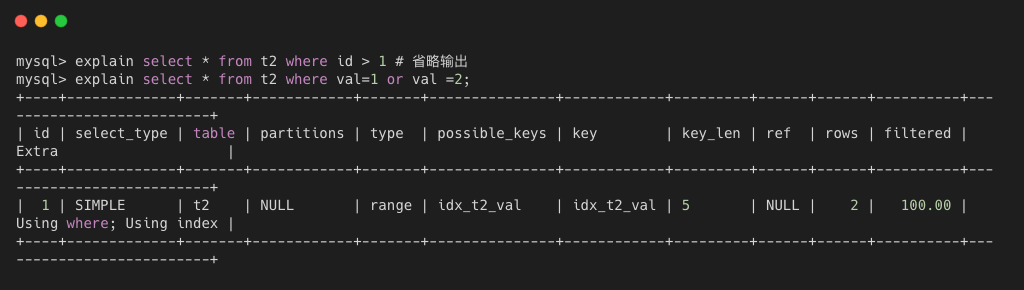
index 与 ALL 类型类似,唯一区别就是只遍历索引树读取索引值,比 ALL 读取所有数据行要稍微快一些,因为索引文件通常比数据文件小。这里涉及 MySQL 的索引覆盖
ALL 全表扫描,通常情况下性能很差,应该避免。
possible_keys,key 和 key_len
possible_key 列指出 MySQL 可能使用哪个索引在该表中查找。如果该列为 NULL,则没有使用相关索引。需要检查 where 子句条件来创建合适的索引提高查询效率。
key 列显示 MySQL 实际决定使用的索引。如果没有选择索引,则值为 NULL。
key_len 显示 MySQL 决定使用索引的长度。如果键为 NULL,则本列也为 NULL,使用的索引长度,在保证精确度的情况下,越短越好。因为越短,索引文件越小,需要的 I/O次数也越少。
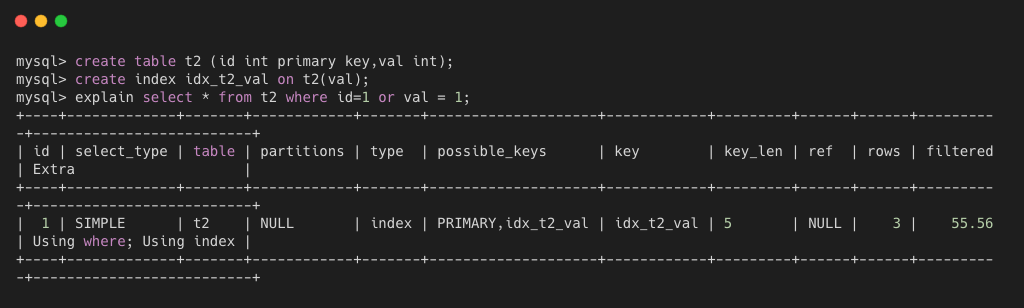
由上图可以看出,对于 select * from t2 where id = 1 or val = 1这个语句,可以使用 PRIMARY 或者 idx_t2_val 索引,实际使用了 idx_t2_val 索引,索引的长度为5。
这些其实是我们分析加锁场景最为关心的字段,后续文章会具体讲解如何根据这些字段和其他工具一起判断复杂 SQL 到底加了哪些锁。
ref
ref 列表示使用其他表的哪个列或者常数来从表中选择行。如下图所示,从 t2 读取数据时,要判断 t2.id = t1.id,所以 ref 就是 mysql.t1.id
rows 和 filtered
rows 列显示 MySQL 认为它执行查询时必须检查的行数。
filtered 列表明了 SQL 语句执行后返回结果的行数占读取行数的百分比,值越大越好。MySQL 会使用 Table Filter 来读取出来的行数据进行过滤,理论上,读取出来的行等于返回结果的行数时效率最高,过滤的比率越多,效率越低。
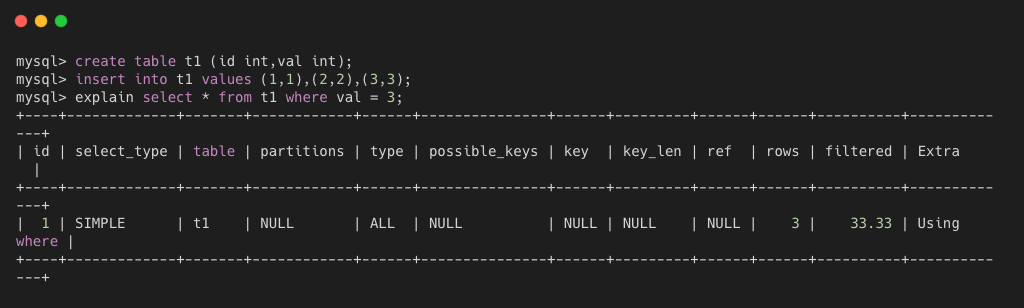
如上图所示,t1表中有三条数据,rows 为 3,表示所有行都要读取出来。根据 val = 3 这个 table filter 过滤,只返回一行数据,所以 filtered 比例为33.33%,
extra
包含不适合在其他列中显示但十分重要的额外信息。常见的值如下
using index 表示 select 操作使用了覆盖索引,避免了访问表的数据行,效率不错。
using where 子句用于限制哪一行。也就是读取数据后使用了 Table Filter 进行过滤。
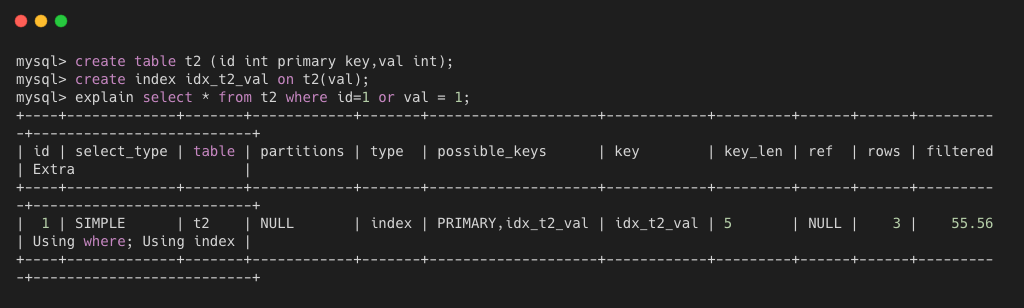
如下图所示,因为 id 和 val 都是有索引的,所以 select * 也是可以直接使用覆盖索引读取数据,所以 extra 中有 using index。而因为只使用 val 索引读取了3行数据,还是通过 where 子句进行过滤,filtered为 55%,所以 extra 中使用了 using where。
- using filesort MySQL 会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取,若出现该值,应该优化 SQL 语句。如下图所示,其中 val 列没有索引,所以无法使用索引顺序排序读取。
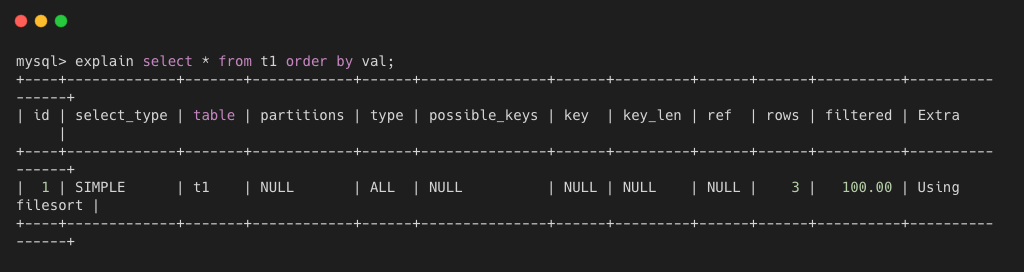
using temporary 使用临时表保存中间结果,比如,MySQL 在对查询结果排序时使用临时表,常用于 order by 和 group by,如果出现该值,应该优化 SQL。根据我的经验,group by 一个无索引列,或者ORDER BY 或 GROUP BY 的列不是来自JOIN语句序列的第一个表,就会产生临时表。
using join buffer 使用连接缓存。如下图所示,展示了连接缓存和临时表。关于连接缓存的内容,大家可以自行查阅,后续有时间在写文章解释。
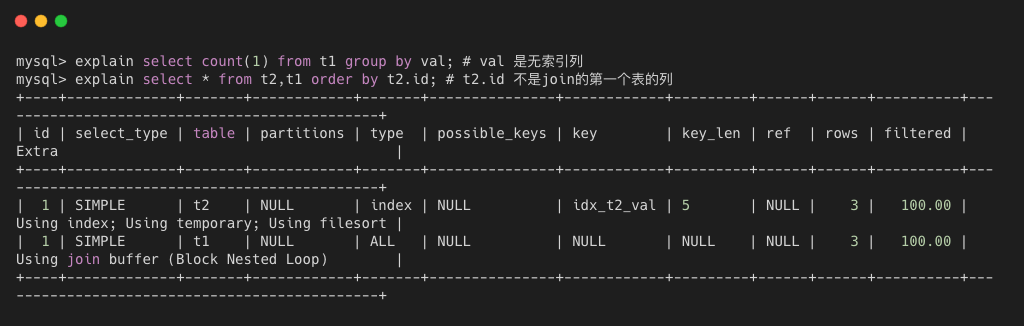
- distinct 发现第一个匹配后,停止为当前的行组合搜索更多的行
后记
通过 explain 了解到 SQL 的执行计划后,我们不仅可以了解 SQL 执行时使用的索引,判断加锁场景,还可以针对其他信息对 SQL 进行优化分析,比如将 type 类型从 index 优化到 ref 等。

用 Explain 命令分析 MySQL 的 SQL 执行的更多相关文章
- mysql中SQL执行过程详解与用于预处理语句的SQL语法
mysql中SQL执行过程详解 客户端发送一条查询给服务器: 服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果.否则进入下一阶段. 服务器段进行SQL解析.预处理,在优化器生成对应的 ...
- 精尽MyBatis源码分析 - MyBatis 的 SQL 执行过程(一)之 Executor
该系列文档是本人在学习 Mybatis 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释(Mybatis源码分析 GitHub 地址.Mybatis-Spring 源码分析 GitHub ...
- mysql数据库SQL执行分析,优化前必备分析
概述 一般我们在对mysql数据库做优化,肯定需要对慢sql去做分析才能开始优化,那么有什么分析的方法呢?下面通过对sql执行时间和执行情况来做分析. 一.SQL 执行时间分析 通过找到执行时间长的 ...
- 通过explain分析低效的SQL执行计划
之前我们讲过如何开启慢查询日志,这个日志的最大作用就是我们通过设定超时阈值,在执行SQL语句中的消耗时间大于这个阈值,将会被记录到慢查询日志里面.DBA通过这个慢查询日志定位到执行缓慢的sql语句,以 ...
- explain命令---查看mysql执行计划
引言: 实际项目开发中,由于我们不知道实际查询的时候数据库里发生了什么事情,数据库软件是怎样扫描表.怎样使用索引的,因此,我们能感知到的就只有 sql语句运行的时间,在数据规模不大时,查询是瞬间的,因 ...
- MySql 的SQL执行计划查看,判断是否走索引
在select窗口中,执行以下语句: set profiling =1; -- 打开profile分析工具show variables like '%profil%'; -- 查看是否生效show p ...
- 如何分析Mysql慢SQL
内容摘要: 开启慢查询日志捕获慢SQL 使用explain分析慢SQL 使用show profile查询SQL执行细节 常见的SQL语句优化 一.开启慢查询日志捕获慢SQL ① 查询mysql是否开启 ...
- mysql的sql执行计划
实际项目开发中,由于我们不知道实际查询的时候数据库里发生了什么事情,数据库软件是怎样扫描表.怎样使用索引的,因此,我们能感知到的就只有 sql语句运行的时间,在数据规模不大时,查询是瞬间的,因此,在写 ...
- mysql的sql执行计划详解
实际项目开发中,由于我们不知道实际查询的时候数据库里发生了什么事情,数据库软件是怎样扫描表.怎样使用索引的,因此,我们能感知到的就只有 sql语句运行的时间,在数据规模不大时,查询是瞬间的,因此,在写 ...
随机推荐
- Jmeter基础-下载与安装
jmeter下载与安装 下载网址:http://jmeter.apache.org/download_jmeter.cgi windows点击下载zip文件 该版本需要JDK1.8及以上版本 免安装, ...
- 实验二、OpenCV图像滤波
一.题目描述 对下面的图片进行滤波和边缘提取操作,请详细地记录每一步操作的步骤. 滤波操作可以用来过滤噪声,常见噪声有椒盐噪声和高斯噪声,椒盐噪声可以理解为斑点,随机出现在图像中的黑点或白点:高斯噪声 ...
- centos 7 firewalld防火墙配置
1.查看firewall服务状态 systemctl status firewalld 2.查看firewall的状态 firewall-cmd --state 3.开启.重启.关闭.firewall ...
- Mysql数值类型,小数点后保留两个零
如有不足请帮忙留言区补充谢谢~ 一,数值类型保留小数点后两个0 在存入数据时,应客户需求数值类型,比如钱数,分数等等需要精确到小数点后几位. 800存入时显示为800.00 方法:在建表时直接定义此数 ...
- NO.4 CCS运行第一个demo(本地)
前面介绍了基本的SDK内容,这次主要是本地实际应用CCS实现程序的运行. 首先我们进入CCS,我简单介绍下界面: 界面很简洁,通俗易懂(怎么跟STM32IDE这么像) 由于我们还不会写程序,我们先导入 ...
- 一、CentOS6.8安装MySQL5.6
一.官网下载rpm安装包 https://dev.mysql.com/downloads/ 版本选中如图中红色框 二.卸载旧mysql 1.检查是否安装有mysql rpm -qa | grep -i ...
- 继承性与super的使用练习
练习1: Account: package com.aff.sup; public class Account { private int id;// 账号 private double balanc ...
- Spring Cloud 系列之 Apollo 配置中心(一)
背景 随着程序功能的日益复杂,程序的配置日益增多:各种功能的开关.参数的配置.服务器的地址等等. 对程序配置的期望值也越来越高:配置修改后实时生效,灰度发布,分环境.分集群管理配置,完善的权限.审核机 ...
- Rocket - util - MultiWidthFifo
https://mp.weixin.qq.com/s/CUnrpyQN5LRBR5bxC5u86A 简单介绍MultiWidthFifo的实现. 1. 基本介绍 实现一个输入宽度 ...
- jchdl - GSL实例 - LogicalLeft
https://mp.weixin.qq.com/s/WNm4bLWzZ0oWHWa7HQ6Y6w 逻辑左移,继承自Shifter类.只需要实现shift方法即可. 参考链接 https:// ...