TreeSet的两种实现方法:Comparable和Comparator(Java比较器)
Comparable与Comparator实际上是TreeSet集合的两种实现方式,用来实现对象的排序。下边介绍一下两种比较器的使用方法和区别。
- Comparable称为元素的自然顺序,或者叫做默认顺序。
- Comparator称为元素定制排序。
下边我们使用Student类来比较两个排序方法,类中有年龄和姓名两个属性。
(1)Comparable(让元素自身具备比较性,元素需要实现Comparable接口,覆盖compareTo方法)
※如果我们希望按照学生年龄排序,当学生年龄相等时按照姓名排序,可以使用Comparable接口。
※在JavaAPI中是这样对Comparable接口描述的:此接口强行对实现它的每个类的对象进行整体排序。这种排序被称为类的自然排序,类的 compareTo 方法被称为它的自然比较方法。
因此可以看出当我们希望对某个类排序时就需要将此类实现Comparable接口,同时覆写接口中的compareTo()方法。
※compareTo()方法默认比较方式:比较此对象与指定对象的顺序。如果该对象小于、等于或大于指定对象,则分别返回负整数、零或正整数。(下边举个栗子,)
package henu.scm;
public class Student implements Comparable{//该接口让该对象强行具有比较性
private String name;
private int age;
public Student(String name,int age) {
this.name = name;
this.age = age;
}
public int compareTo(Object obj) {
if(!(obj instanceof Student)) {
throw new RuntimeException("该类不是Student类");
}
Student stu = (Student)obj;
if(this.age > stu.age)
return 1;
else if(this.age == stu.age)
return this.name.compareTo(stu.name);
return -1;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String toString() {
return this.name + " " + this.age; }
}
※在上述Student类中我们实现了Comparable接口并且覆写了其compareTo()方法,在方法中我们首先判断传进来的类是不是Student类,如果不是则抛出异常。
※从代码中看出我们对两个Student类的年龄进行了判断,如果相等则返回1(此时年龄为正序从小到大),如果需要倒序则可以将大于号(>)改为小于号(<),即this.age < stu.age;
Java测试类代码如下:
package henu.scm;
import java.util.TreeSet;
public class compareTest {
public static void main(String[] args) {
TreeSet ts = new TreeSet<>();
Student s1 = new Student("lisi01",10);
Student s2 = new Student("lisi02",18);
Student s3 = new Student("lisi03",16);
Student s4 = new Student("lisi04",16);
ts.add(s1);ts.add(s2);ts.add(s3);ts.add(s4);//将Student类放入集合。
System.out.println(ts.toString());//输出集合
}
}
测试类结果为:[lisi01 10, lisi03 16, lisi04 16, lisi02 18]。
从结果可以看出传入的4个Student对象已按照年龄大小进行排序,同时年龄大小相等时按照姓名排序。(lisi03和lisi04)
※这里一个小问题:在Sutdent类的conpareTo()方法中,如果将年龄相等返回值改为else if(this.age == stu.age){return 0;}时(即年龄相等时返回0),想想这时会怎么样?
答案是只会存入lisi03,而lisi04不在TreeSet集合中,这是因为当返回0时,TreeSet会将比较的两个对象(lisi03和lisi04)看作是同一个相同对象,显然这不符合我们的要求,所以当年龄相同时我们需要再次比较姓名。如果姓名相同时,则两个对象才相同。
TreeSet保证元素唯一性的依据是:只要compareTo方法return 0时,就认定为当前的两个对象相同,因此只存入一个对象。
记住:当主要条件相同时一定要判断次要条件!!!
※上边的Demo中我们解决了当年龄为主要条件,姓名为次要条件的对象排序,那么当我们想把姓名当作主要条件时又该怎么办呢?年龄为整型值是一个可比较类型,但是如果将姓名即字符串类型这个不可比较型的数据类型当作主要条件时使用comparable就力不从心了。此时我们就需要用到Comparator了。
(2)Comparator(让集合自身具备比较性)
※Comparator适用的两种场合:1、当元素自身不具备比较性时 2、或者具备的比较性不是所需要的时候
※如何让集合自身具备比较性呢?如果查阅JavaAPI可以发现TreeSet的其中一个构造方法可以传入一个Comparator(比较器),集合的比较规则就定义在比较器中。
Student.java中的代码不变(即使Student依然实现了comparable接口但不影响,后边为大家讲解原因),我们只需要再定义一个比较器类,这里为了方便就在主类中创建该类,代码如下:
package henu.scm; import java.util.Comparator;
import java.util.TreeSet; public class compareTest {
public static void main(String[] args) {
TreeSet ts = new TreeSet<>(new myComparator());
Student s1 = new Student("lisi01",10);
Student s2 = new Student("lisi02",6);
Student s3 = new Student("lisi03",30);
Student s4 = new Student("lisi04",18);
Student s5 = new Student("lisi04",16);
ts.add(s1);ts.add(s2);ts.add(s3);ts.add(s4);ts.add(s5);
System.out.println(ts.toString());
}
}
class myComparator implements Comparator{
@Override
public int compare(Object o1, Object o2) {
Student s1 = (Student)o1;
Student s2 = (Student)o2;
int temp = s1.getName().compareTo(s2.getName());//返回1或0或-1
if(temp == 0) {//如果名字相同则比较年龄
return new Integer(s1.getAge()).compareTo(new Integer(s2.getAge()));
}
return temp;
} }
※我们定义完比较器之后,将比较器传入TreeSet集合之后,集合自身就具备了比较性,并按照比较器规则对传入的元素进行比较。和Comparable一样也是返回0或1或-1。
上边当姓名相同时,我们对年龄进行了封装,封装成Integer对象(Integer对象也实现了comparable接口,自身具备比较性)之后就可以使用compareTo方法直接比较,不用再判断如果s1.getAge() > s2.getAge()等等。
※Comparator的Demo介绍完之后我们回到上边遗留的问题:Student明明实现了Comparable接口自身具备比较性,如果不修改代码会不会影响Comparator的功能呢?
细心的会发现当Comparable和Comparator同时存在时,Comparator的优先级别更高,所以即使不修改Student类也不影响比较器的实现。
※实现Comparator接口时,其中除了compare()还有另外一个equals()方法,对于该方法JavaAPI的描述是这样的(这里不再进行详解):
boolean equals(Object obj)指示某个其他对象是否“等于”此 Comparator。此方法必须遵守Object.equals(Object)的常规协定。此外,仅当 指定的对象也是一个 Comparator,并且强行实施与此 Comparator 相同的排序时, 此方法才返回 true。
因此,comp1.equals(comp2)意味着对于每个对象引用 o1 和 o2 而言,都存在 sgn(comp1.compare(o1, o2))==sgn(comp2.compare(o1, o2))。
注意,不 重写 Object.equals(Object) 方法总是 安全的。然而,在某些情况下,重写此方法可以允许程序确定两个不同的 Comparator 是否强行实施了相同的排序,从而提高性能。
(3)总结两者的区别和联系
- comparable和comparator都是根据return的返回结果(0、-1、1)来判断两个比较元素的大小关系。
- 当返回结果为0时,认为两个元素相同,则只存入第一个元素。
- Comparable需要覆写compareTo()方法,Comparator需要覆写compare()方法。
- Comparable需要修改源代码即实现该接口的类,本例即为Student。而Comparator不需要修改Student类,用户可以在比较器中实现复杂的比较方法,只需要把比较器传给TreeSet即可。
- Comparable可以理解为"内部比较器",Comparator可以理解为"外部比较器"。
(4)补充:TreeSet集合比较的底层原理
※无论是使用Comparable还是使用Comparator来实现元素的比较,其最终底层排序原理是:二叉树排序。
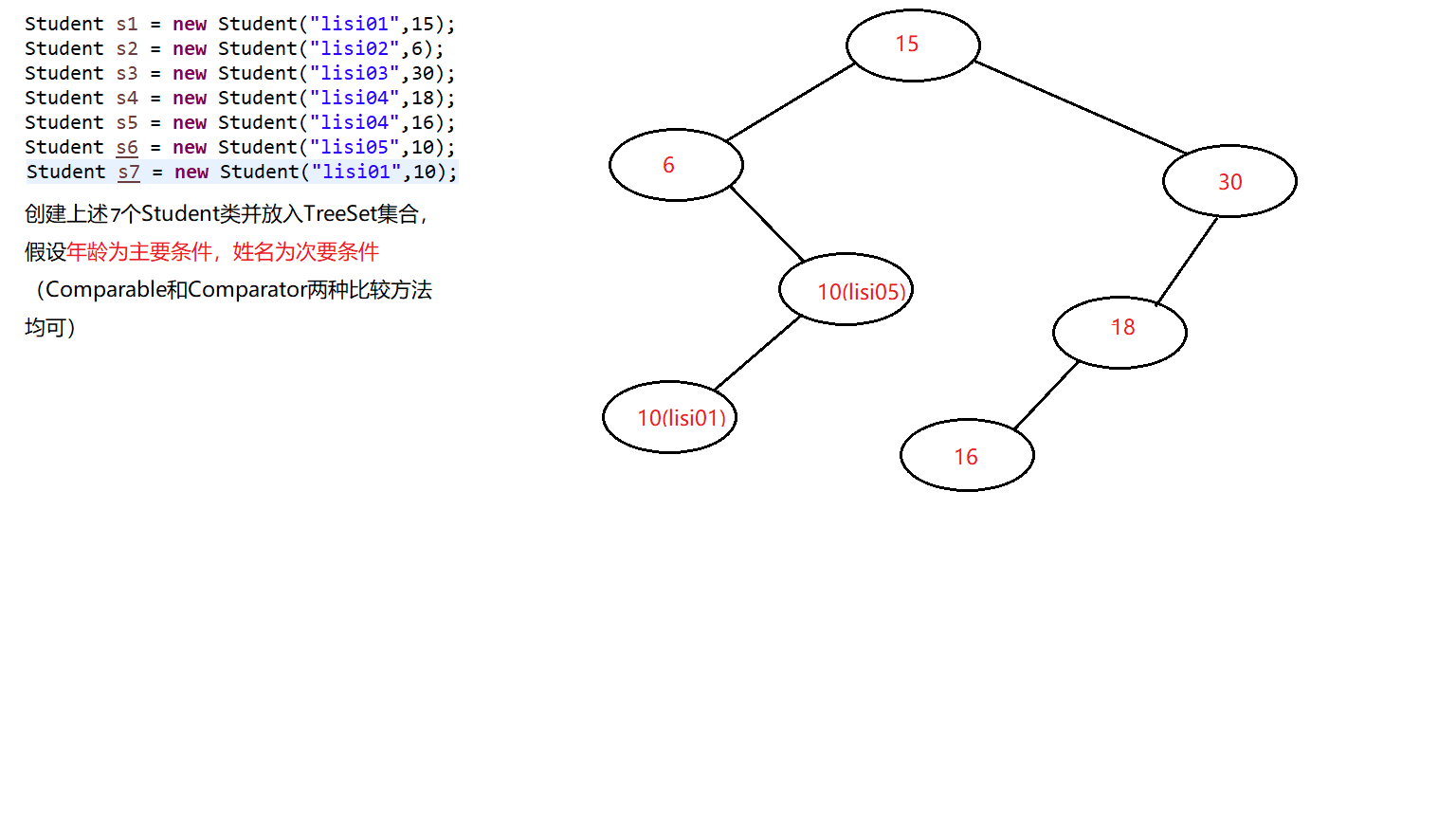
※上图中我们做了一个简单的排序Demo,二叉树构成步骤如下:
- 存入s1,将s1作为根节点。
- 存入s2,先判断主要条件(年龄),6小于15,放在根节点的左边。
- 存入s3,判读主要条件,30大于15,放在根节点右边。
- 存入s4,判断主要条件,18大于15,放在根节点右边,18又小于30,放在30的左边。
- 存入s5,判断主要条件...........
- 存入s6,判断主要条件,10小于15,放在根节点左边,10又大于6,放在6的右边。
- 存入s7,判断主要条件,10小于15,放在根节点左边,10又大于6,放在6的右边,10等于10(主要条件相等),比较次要条件,lisi05大于lisi01,所以10(lisi01)放在10(lisi05)的左边。
经过上述7个步骤我们就简单的模拟了一下TreeSet集合的底层排序原理。
※如果明白了底层二叉树原理:接下来简单思考一下如何使用TreeSet集合模拟栈(先进后出)和队列(先进先出)
首先栈是先进后出,那么我们可以让比较器直接返回-1,不做任何逻辑操作,即先进来的值永远小于后进来的值。
package henu.scm; import java.util.Comparator;
import java.util.TreeSet; public class compareTest {
public static void main(String[] args) {
TreeSet ts = new TreeSet<>(new myComparator());
Student s1 = new Student("lisi01",15);
Student s2 = new Student("lisi02",6);
Student s3 = new Student("lisi03",30);
Student s4 = new Student("lisi04",18);
Student s5 = new Student("lisi04",16);
ts.add(s1);ts.add(s2);ts.add(s3);ts.add(s4);ts.add(s5);
System.out.println(ts.toString());
}
}
class myComparator implements Comparator{
@Override
public int compare(Object o1, Object o2) {
return -1;
} }
上述结果为:[lisi04 16, lisi04 18, lisi03 30, lisi02 6, lisi01 15]
从结果可以看出来,lisi01,15先进去但是最后才输出。如果转换成二叉树的形式那么他是一个右二叉树(可以看作八的右半部分)。
栈的原理明白之后,队列就是将return返回结果改为1,即先进来的值永远大于后进来的值,如果转换成二叉树的形式那么他是一个左二叉树(可以看作八的左半部分)。
TreeSet的两种实现方法:Comparable和Comparator(Java比较器)的更多相关文章
- angular2系列教程(十)两种启动方法、两个路由服务、引用类型和单例模式的妙用
今天我们要讲的是ng2的路由系统. 例子
- git两种合并方法 比较merge和rebase
18:01 2015/11/18git两种合并方法 比较merge和rebase其实很简单,就是合并后每个commit提交的id记录的顺序而已注意:重要的是如果公司用了grrit,grrit不允许用m ...
- 两种Ajax方法
两种Ajax方法 Ajax是一种用于快速创建动态网页的技术,他通过在后台与服务器进行少量的数据交换,可以实现网页的异步更新,不需要像传统网页那样重新加载页面也可以做到对网页的某部分作出更新,现在这项技 ...
- mysql in 的两种使用方法
简述MySQL 的in 的两种使用方法: 他们各自是在 in keyword后跟一张表(记录集).以及在in后面加上字符串集. 先讲后面跟着一张表的. 首先阐述三张表的结构: s(sno,sname. ...
- C#中的两种debug方法
这篇文章主要介绍了C#中的两种debug方法介绍,本文讲解了代码用 #if DEBUG 包裹.利用宏定义两种方法,需要的朋友可以参考下 第一种:需要把调试方法改成debug代码用 #if DEBU ...
- Service的两种启动方法
刚才看到一个ppt,介绍service的两种启动方法以及两者之间的区别. startService 和 bindService startService被形容为我行我素,而bindService被形容 ...
- jQuery ajax调用后台aspx后台文件的两种常见方法(不是ashx)
在asp.net webForm开发中,用Jquery ajax调用aspx页面的方法常用的有两种:下面我来简单介绍一下. [WebMethod] public static string SayHe ...
- android studio gradle 两种更新方法更新
android studio gradle 两种更新方法更新 第一种.Android studio更新 第一步:在你所在项目文件夹下:你项目根目录gradlewrappergradle-wrapper ...
- iOS学习——UITableViewCell两种重用方法的区别
今天在开发过程中用到了UITableView,在对cell进行设置的时候,我发现对UITableViewCell的重用设置的方法有如下两种,刚开始我也不太清楚这两种之间有什么区别.直到我在使用方法二进 ...
随机推荐
- C#获取文件夹内文件包括子文件(递归)实例
这个在我工作上,写了一次工具项目,用上的. static ArrayList FileList = new ArrayList();//这个必须写在方法外, static ArrayList GetA ...
- HTTPie:替代 Curl 和 Wget 的现代 HTTP 命令行客户端
HTTPie 工具是现代的 HTTP 命令行客户端,它能通过命令行界面与 Web 服务进行交互. -- Magesh Maruthamuthu 大多数时间我们会使用 curl 命令或是 wget 命令 ...
- 模拟电磁曲射炮_H题 方案分析【2019年电赛】【刘新宇qq522414928】
请查看我的有道云笔记: 文档:电磁曲射炮分析.note链接:http://note.youdao.com/noteshare?id=26f6b6febc04a8983d5efce925e92e21
- ElasticSearch的高级复杂查询:非聚合查询和聚合查询
一.非聚合复杂查询(这儿展示了非聚合复杂查询的常用流程) 查询条件QueryBuilder的构建方法 1.1 精确查询(必须完全匹配上,相当于SQL语句中的“=”) ① 单个匹配 termQuery ...
- Go语言: 万物皆异步
来源:https://www.jianshu.com/p/62c0cd107da3 同步和异步.阻塞和非阻塞 首先要明确的是,同步(Synchronous)和异步(Asynchronous),阻塞(B ...
- The new SFCB broker fails to start with a SSL-related error: Failure setting ECDH curve name (secp22
# openssl ecparam -list_curves secp384r1 : NIST/SECG curve over a 384 bit prime field secp521r1 : NI ...
- 监控MySQL服务及httpd服务
一:监控MySQL服务 [root@server ~]# vim /usr/local/zabbix/etc/zabbix_agentd.conf PidFile=/tmp/zabbix_agentd ...
- 基于Atlas实现mysql读写分离
一.实验环境 主机名IP地址 master192.168.200.111 slave192.168.200.112 atlas192.168.200.113 主从复制不再赘述,链接地址:授权Atlas ...
- LVS DR模式实验
LVS DR模式实验 三台虚拟机,两个台节点机(Apache),一台DR实验调度机 一:关闭相关安全机制 systemctl stop firewalld iptables -F setenforce ...
- Condition的await()和signal()流程
介绍 Condition是j.u.c包下提供的一个接口. 可以翻译成 条件对象,其作用是线程先等待,当外部满足某一条件时,在通过条件对象唤醒等待的线程.ArrayBlockingQueue就是通过Co ...