翻译 - Kafka Streams 介绍(一)

资料
[原文地址](http://kafka.apache.org/11/documentation/streams/)
正文
卡夫卡流是一个用于构建应用程序和微服务的客户端库,其中输入和输出数据都存储在卡夫卡集群中。只需要在客户端部署标准的Java和Scala应用程序,既简单又可以利用卡夫卡的服务器端集群技术的优势。
使用 Kafka Streams 的理由
- 高度可伸缩的弹性,容错
- 部署到容器、vm、裸机、云
- 对于小型、中型和大型用例也同样可行
- 与卡夫卡的安全完全整合
- 标准的Java应用程序
- 只有一次处理语义
- 不需要单独的处理集群
- 在Mac,Linux,Windows上开发
Kafka Stream 使用案例
- 纽约时报利用Apache卡夫卡和卡夫卡的流,实时地将内容发布到各种应用程序和系统中,让读者可以使用它。
- Pinterest在很大程度上使用了Apache卡夫卡和卡夫卡的流平台,为他们的广告基础设施提供实时的预测预算系统。在卡夫卡的流中,预测比以往任何时候都更加准确。
- 作为欧洲领先的在线时尚零售商,Zalando将卡夫卡作为ESB(企业服务总线),帮助我们从单一的服务架构过渡到一个微型服务架构。使用卡夫卡来处理事件流,使我们的技术团队能够进行近乎实时的业务智能。
- 荷兰合作银行是荷兰最大的三家银行之一。它的数字神经系统,商业事件总线,是由Apache卡夫卡提供的。它被越来越多的金融流程和服务使用,其中之一是Rabo警报。该服务在金融事件中实时提醒客户,并使用卡夫卡流构建。
- LINE使用Apache卡夫卡作为我们服务之间相互通信的中心数据中心。每天产生数百亿条消息,用于执行各种业务逻辑、威胁检测、搜索索引和数据分析。LINE利用卡夫卡的流来可靠地转换和过滤主题,使消费者能够有效地使用子主题,同时由于其复杂而又最小的代码基础,保持了易于维护的可维护性。
- Trivago是一个全球性的酒店搜索平台。我们专注于重塑旅行者搜索和比较酒店的方式,同时让酒店广告商通过我们的网站和应用向广大的旅行者提供访问,从而扩大他们的业务。到2017年,我们将在190多个国家提供大约180万家酒店和其他住宿设施。我们使用卡夫卡、卡夫卡Connect和卡夫卡流,使我们的开发人员能够在公司中自由地访问数据。卡夫卡的流媒体提供了我们分析管道的部分内容,并提供了无穷无尽的选择,以探索和操作我们手头的数据来源。
Hello Kafka Streams
下面的代码例子实现了一个具有弹性、高度可伸缩、容错、有状态的WordCount应用程序,并准备在大规模生产中运行.
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.common.utils.Bytes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
import org.apache.kafka.streams.kstream.Materialized;
import org.apache.kafka.streams.kstream.Produced;
import org.apache.kafka.streams.state.KeyValueStore;
import java.util.Arrays;
import java.util.Properties;
public class WordCountApplication {
public static void main(final String[] args) throws Exception {
Properties config = new Properties();
config.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application");
config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-broker1:9092");
config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> textLines = builder.stream("TextLinesTopic");
KTable<String, Long> wordCounts = textLines
.flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split("\\W+")))
.groupBy((key, word) -> word)
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("counts-store"));
wordCounts.toStream().to("WordsWithCountsTopic", Produced.with(Serdes.String(), Serdes.Long()));
KafkaStreams streams = new KafkaStreams(builder.build(), config);
streams.start();
}
}
Run Kafka Streams Demo Application
本教程假设您正在重新开始,并且没有现成的卡夫卡或ZooKeeper服务。然而,如果你已经启动了卡夫卡和Zookeeper,你可以跳过前两步。
卡夫卡流是一个用于构建关键任务实时应用程序和微服务的客户端库,其中输入和/或输出数据存储在卡夫卡集群中。卡夫卡的流结合了写作的简单性,在客户端部署标准的Java和Scala应用程序,并利用了卡夫卡的服务器端集群技术,使这些应用程序具有高度可伸缩性、弹性、容错、分布式等功能。
这个快速启动的例子将演示如何在这个库中运行一个流媒体应用程序。下面是WordCountDemo示例代码的要点(转换为使用Java 8 lambda表达式便于阅读)。
// Serializers/deserializers (serde) for String and Long types
final Serde<String> stringSerde = Serdes.String();
final Serde<Long> longSerde = Serdes.Long();
// Construct a `KStream` from the input topic "streams-plaintext-input", where message values
// represent lines of text (for the sake of this example, we ignore whatever may be stored
// in the message keys).
KStream<String, String> textLines = builder.stream("streams-plaintext-input",
Consumed.with(stringSerde, stringSerde);
KTable<String, Long> wordCounts = textLines
// Split each text line, by whitespace, into words.
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
// Group the text words as message keys
.groupBy((key, value) -> value)
// Count the occurrences of each word (message key).
.count()
// Store the running counts as a changelog stream to the output topic.
wordCounts.toStream().to("streams-wordcount-output", Produced.with(Serdes.String(), Serdes.Long()));
它实现了WordCount算法,它从输入文本中计算出一个单词的出现直方图。然而,与您之前可能看到的其他WordCount示例不同,WordCount演示应用程序的行为略有不同,因为它被设计为在无限的、无界的数据流中操作。类似于有界的变体,它是一个有状态的算法,可以跟踪和更新单词的计数。然而,由于它必须假定具有无限的输入数据,所以它会周期性地输出当前状态和结果,同时继续处理更多的数据,因为它不知道什么时候处理了“所有”输入数据。
作为第一步,我们将启动卡夫卡(除非你已经启动了),然后我们将准备输入数据到卡夫卡的主题,随后将由卡夫卡的流应用程序处理。
步骤1:下载代码
> tar -xzf kafka_2.11-1.1.0.tgz
> cd kafka_2.11-1.1.0
步骤2:启动卡夫卡服务器
先启动zookeeper
> bin/zookeeper-server-start.sh config/zookeeper.properties
> bin/kafka-server-start.sh config/server.properties
步骤3:准备输入主题并启动卡夫卡生产者
接下来,我们创建名为 streams-plaintext-input 的输入主题,以及名为 streams-wordcount-output 的输出主题:
> bin/kafka-topics.sh --create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--partitions 1 \
--topic streams-plaintext-input
Created topic "streams-plaintext-input".
> bin/kafka-topics.sh --create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--partitions 1 \
--topic streams-wordcount-output \
--config cleanup.policy=compact
Created topic "streams-wordcount-output".
> bin/kafka-topics.sh --zookeeper localhost:2181 --describe
Topic:streams-plaintext-input PartitionCount:1 ReplicationFactor:1 Configs:
Topic: streams-plaintext-input Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:streams-wordcount-output PartitionCount:1 ReplicationFactor:1 Configs:
Topic: streams-wordcount-output Partition: 0 Leader: 0 Replicas: 0 Isr: 0
步骤4:启动Wordcount应用程序
下面的命令启动WordCount演示应用程序:
> bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo
演示应用程序将从输入主题流-纯文本输入中读取,对每个读消息执行WordCount算法的计算,并不断地将其当前结果写到输出主题流-wordcount-输出。因此,除了日志条目之外,不会有任何STDOUT输出,因为结果会被写回卡夫卡。
报错提示: 默认 kafka-run-class.sh 会连接 127.0.0.1:9092 的broker , 如果broker不存在会报错:
[2018-04-08 10:12:19,883] WARN [StreamsKafkaClient clientId=] Connection to node -1 could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient).结局方案是启动一个监听9092 的broker即可.我这边之前是改了server.properties配置为9091了.
现在,我们可以在一个单独的终端中启动控制台生成器,以便为这个主题编写一些输入数据:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-plaintext-input
在单独的终端中查看输出:
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
步骤5:处理一些数据
现在,让我们通过输入一行文本,然后点击“Enter”,将一些消息写入到输入主题中。
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-plaintext-input
all streams lead to kafka
输出如下:
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
all 1
streams 1
lead 1
to 1
kafka 1
在这里,第一列是消息键,java.lang.String格式,表示正在计算的单词,第二列是消息值。java.lang.Long格式,代表这个词的最新计数。
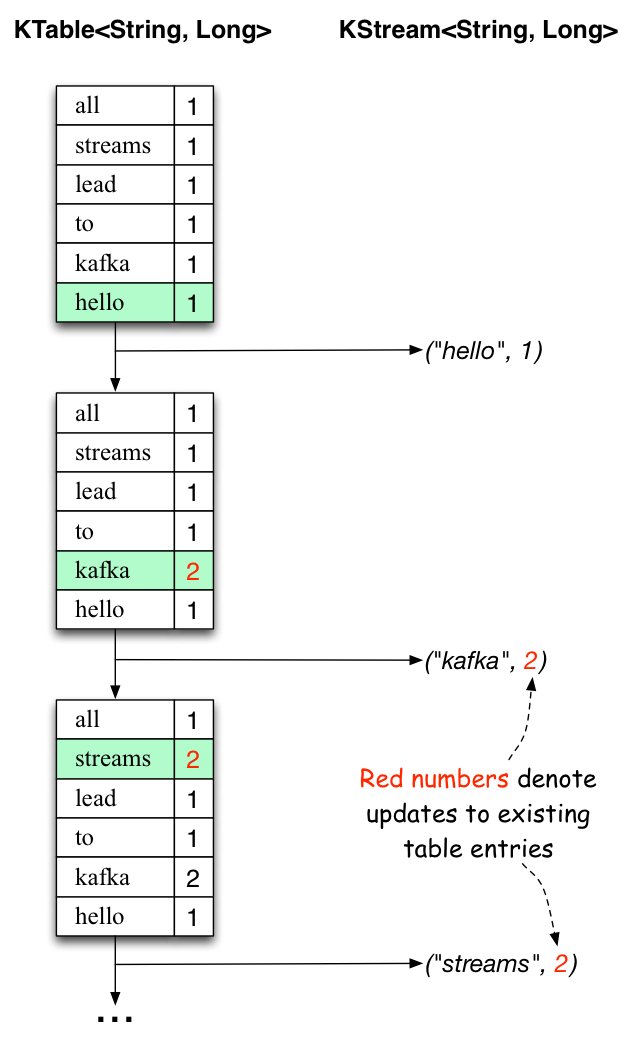
下面的两个图表说明了幕后的实际情况。第一列显示了KTable<String, Long>的当前状态的演变,它计算单词出现的count。第二列显示了从状态更新到KTable的变更记录,并将其发送到卡夫卡主题streams-wordcount-output。
(图片还是看原文吧,这里没有排版,不好分析)
http://kafka.apache.org/11/images/streams-table-updates-01.png
{kind=link}
http://kafka.apache.org/11/images/streams-table-updates-02.png
{kind=link}
首先第一行文本"all streams lead to kafka"开始处理.KTable构建时,每个新单词都会产生一个新的表条目(以绿色背景突出显示),相应的变更记录被发送到下游的KStream.
当第二个文本行“hello kafka streams”被处理时,我们第一次观察到,KTable中的现有条目正在被更新(单词 “kafka”和“streams”)。同样,变更记录也被发送到输出主题。
等等(我们跳过了如何处理第三行的说明)。这就解释了为什么输出主题有我们上面显示的内容,因为它包含了变更的完整记录。
以超出这个具体例子的范围看,卡夫卡流做的是table和changelog之间的对偶性(table= KTable , changelog stream=下游的 KStream):您可以发布表中的的每一个变化到流,如果你消费了从始至终整个变更流,你就可以重建表的内容。
步骤6:拆卸应用程序
现在,您可以通过Ctrl-C停止控制台消费者、控制台生产者、Wordcount应用程序、卡夫卡和ZooKeeper服务器。
Ctrl-Z 也可以终止Wordcount应用程序
Tutorial: Write a Kafka Streams Application
本节教程将告诉你如何头开始创建一个 Kafka Streams 应用程序.
创建 一个 Maven Project
mvn archetype:generate \
-DarchetypeGroupId=org.apache.kafka \
-DarchetypeArtifactId=streams-quickstart-java \
-DarchetypeVersion=1.1.0 \
-DgroupId=streams.examples \
-DartifactId=streams.examples \
-Dversion=0.1 \
-Dpackage=myapps
你可以自定义groupid , artifactid 和 package , 执行后效果如下:
> tree streams.examples
streams-quickstart
|-- pom.xml
|-- src
|-- main
|-- java
| |-- myapps
| |-- LineSplit.java
| |-- Pipe.java
| |-- WordCount.java
|-- resources
|-- log4j.properties
pom.xml 文件中定义了所需要的依赖.我们因为是要从头开始.所以先删除代码部分内容:
> cd streams-quickstart
> rm src/main/java/myapps/*.java
第一个流应用 : Pipe (数据管道)
首先创建一个 Pipe.java:
package myapps;
public class Pipe {
public static void main(String[] args) throws Exception {
}
}
注意上面的代码并未贴出 import 语句,这个IDE编译器会自动装入.
第一步就是创建配置属性,标识应用程序以便于和其他流应用区分开.然后设置一个初始化连接到Kafka的集群的主机端口.
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-pipe");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); // assuming that the Kafka broker this application is talking to runs on local machine with port 9092
此外,还需要设置序列化和反序列的类:
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
接下来,我们将定义Streams应用程序的计算逻辑。在卡夫卡的流中,这种计算逻辑被定义为连接处理器节点的拓扑。我们可以使用拓扑构建器来构造这样的拓扑,
final StreamsBuilder builder = new StreamsBuilder();
然后设置一个输入流的主题:
KStream<String, String> source = builder.stream("streams-plaintext-input");
现在,就可以从输入流主题中源源不断的获取数据,处理完成后发送到输出流中:
builder.stream("streams-plaintext-input").to("streams-pipe-output");
我们可以通过以下步骤来检查构建器所创建的拓扑结构:
final Topology topology = builder.build();
System.out.println(topology.describe());
编译运行:将会生成如下信息:
> mvn clean package
> mvn exec:java -Dexec.mainClass=myapps.Pipe
Sub-topologies:
Sub-topology: 0
Source: KSTREAM-SOURCE-0000000000(topics: streams-plaintext-input) --> KSTREAM-SINK-0000000001
Sink: KSTREAM-SINK-0000000001(topic: streams-pipe-output) <-- KSTREAM-SOURCE-0000000000
Global Stores:
none
有了 拓扑结构和属性配置后,就可以构造一个KafkaStream对象:
final KafkaStreams streams = new KafkaStreams(topology, props);
一旦调用 start()方法,流处理就会一直执行直到调用close().我们可以注册一个JVM钩子来在程序关闭的时候终止流处理程序:
final CountDownLatch latch = new CountDownLatch(1);
// attach shutdown handler to catch control-c
Runtime.getRuntime().addShutdownHook(new Thread("streams-shutdown-hook") {
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try {
streams.start();
latch.await();
} catch (Throwable e) {
System.exit(1);
}
System.exit(0);
完整的代码如下:
package myapps;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class Pipe {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-pipe");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
final StreamsBuilder builder = new StreamsBuilder();
builder.stream("streams-plaintext-input").to("streams-pipe-output");
final Topology topology = builder.build();
final KafkaStreams streams = new KafkaStreams(topology, props);
final CountDownLatch latch = new CountDownLatch(1);
// attach shutdown handler to catch control-c
Runtime.getRuntime().addShutdownHook(new Thread("streams-shutdown-hook") {
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try {
streams.start();
latch.await();
} catch (Throwable e) {
System.exit(1);
}
System.exit(0);
}
}
如果你已经启动了Kafka集群通过下面的命令执行程序:
> mvn clean package
> mvn exec:java -Dexec.mainClass=myapps.Pipe
本节不讨论流应用执行的详细节,相关信息参考Play with a Streams Application
第二个流应用: Line Split
从前面的日志可以知道要创建一个流客户端需要两个重要的组件: StreamsConfig and Topology. 现在我们添加一些处理逻辑到当前的拓扑中.重新创建一个类LineSplit.java :
cp src/main/java/myapps/Pipe.java src/main/java/myapps/LineSplit.java
变更应用程序名称:
public class LineSplit {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-linesplit");
// ...
}
}
由于源流的每一个记录都是一个字符串类型的键-值组成,所以让我们把value字符串当作文本行来处理,并使用FlatMapValues操作符将其分割成单词:
KStream<String, String> source = builder.stream("streams-plaintext-input");
KStream<String, String> words = source.flatMapValues(new ValueMapper<String, Iterable<String>>() {
@Override
public Iterable<String> apply(String value) {
return Arrays.asList(value.split("\\W+"));
}
});
下面是JDK8的代码:
KStream<String, String> source = builder.stream("streams-plaintext-input");
KStream<String, String> words = source.flatMapValues(value -> Arrays.asList(value.split("\\W+")));
然后把单词作为流写到输出流主题中:
KStream<String, String> source = builder.stream("streams-plaintext-input");
source.flatMapValues(value -> Arrays.asList(value.split("\\W+")))
.to("streams-linesplit-output");
完整代码如下:
package myapps;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import org.apache.kafka.streams.kstream.KStream;
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class LineSplit {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-linesplit");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
final StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> source = builder.stream("streams-plaintext-input");
source.flatMapValues(value -> Arrays.asList(value.split("\\W+")))
.to("streams-linesplit-output");
final Topology topology = builder.build();
final KafkaStreams streams = new KafkaStreams(topology, props);
final CountDownLatch latch = new CountDownLatch(1);
// ... same as Pipe.java above
}
}
查看下这个拓扑描述:
> mvn clean package
> mvn exec:java -Dexec.mainClass=myapps.LineSplit
Sub-topologies:
Sub-topology: 0
Source: KSTREAM-SOURCE-0000000000(topics: streams-plaintext-input) --> KSTREAM-FLATMAPVALUES-0000000001
Processor: KSTREAM-FLATMAPVALUES-0000000001(stores: []) --> KSTREAM-SINK-0000000002 <-- KSTREAM-SOURCE-0000000000
Sink: KSTREAM-SINK-0000000002(topic: streams-linesplit-output) <-- KSTREAM-FLATMAPVALUES-0000000001
Global Stores:
none
里面新增了一个处理器节点 KSTREAM-FLATMAPVALUES-0000000001 , 使用了 KSTREAM-SOURCE-0000000000 数据源 , 下沉到
KSTREAM-SINK-0000000002 . 由于没有使用任何存储类型,所以处理器是无状态的.显示(stores:[])
第三个应用: Wordcount 单词计数
现在用相同的方式从LineSplit.java 构造一个 WordCount.java , 改下应用表示即可:
public class WordCount {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-wordcount");
// ...
}
}
然后改下处理逻辑:
KTable<String, Long> counts =
source.flatMapValues(new ValueMapper<String, Iterable<String>>() {
@Override
public Iterable<String> apply(String value) {
return Arrays.asList(value.toLowerCase(Locale.getDefault()).split("\\W+"));
}
})
.groupBy(new KeyValueMapper<String, String, String>() {
@Override
public String apply(String key, String value) {
return value;
}
})
// Materialize the result into a KeyValueStore named "counts-store".
// The Materialized store is always of type <Bytes, byte[]> as this is the format of the inner most store.
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>> as("counts-store"));
为了进行计数聚合,我们必须首先指定我们想要在值字符串上键入流,即小写字母,与groupBy操作符一起。这个操作会生成一个新的分组流,然后由一个计数操作符聚合,它会在每个分组的键上产生一个运行的计数 .
注意,计数操作符有一个物化参数,它指定运行计数应该存储在名为counts-store的state store中。这个计数存储可以实时查询,在开发人员手册中描述
有详细信息。
我们还可以把KTable的changelog流写回另一个卡夫卡的主题,比如streams-wordcount-output。因为结果是一个changelog流,所以输出主题streams-wordcount-output应该配置为启用日志压缩。请注意,这一次,value类型不再是字符串,而是Long,因此默认的序列化类不再适合将其写入卡夫卡。我们需要为Long提供覆盖的序列化方法,否则将抛出一个运行时异常:
counts.toStream().to("streams-wordcount-output", Produced.with(Serdes.String(), Serdes.Long()));
为了将数据输出到streams-wordcount-output主题,你需要修改生产者的序列化类型:
KStream<String, String> source = builder.stream("streams-plaintext-input");
source.flatMapValues(value -> Arrays.asList(value.toLowerCase(Locale.getDefault()).split("\\W+")))
.groupBy((key, value) -> value)
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("counts-store"))
.toStream()
.to("streams-wordcount-output", Produced.with(Serdes.String(), Serdes.Long());
拓扑描述如下:
> mvn clean package
> mvn exec:java -Dexec.mainClass=myapps.WordCount
Sub-topologies:
Sub-topology: 0
Source: KSTREAM-SOURCE-0000000000(topics: streams-plaintext-input) --> KSTREAM-FLATMAPVALUES-0000000001
Processor: KSTREAM-FLATMAPVALUES-0000000001(stores: []) --> KSTREAM-KEY-SELECT-0000000002 <-- KSTREAM-SOURCE-0000000000
Processor: KSTREAM-KEY-SELECT-0000000002(stores: []) --> KSTREAM-FILTER-0000000005 <-- KSTREAM-FLATMAPVALUES-0000000001
Processor: KSTREAM-FILTER-0000000005(stores: []) --> KSTREAM-SINK-0000000004 <-- KSTREAM-KEY-SELECT-0000000002
Sink: KSTREAM-SINK-0000000004(topic: Counts-repartition) <-- KSTREAM-FILTER-0000000005
Sub-topology: 1
Source: KSTREAM-SOURCE-0000000006(topics: Counts-repartition) --> KSTREAM-AGGREGATE-0000000003
Processor: KSTREAM-AGGREGATE-0000000003(stores: [Counts]) --> KTABLE-TOSTREAM-0000000007 <-- KSTREAM-SOURCE-0000000006
Processor: KTABLE-TOSTREAM-0000000007(stores: []) --> KSTREAM-SINK-0000000008 <-- KSTREAM-AGGREGATE-0000000003
Sink: KSTREAM-SINK-0000000008(topic: streams-wordcount-output) <-- KTABLE-TOSTREAM-0000000007
Global Stores:
none
正如我们在上面看到的,拓扑现在包含两个断开连接的子拓扑。第一个子拓扑的下沉节点KSTREAM-SINK-0000000004将流写入重新分配的topic Counts-repartition,它将由第二个子拓扑的源节点KSTREAM-SOURCE-0000000006读取。重新分配的主题通过聚合键“清洗”源数据流,在本例中聚合键是字符串值。此外,在第一个子拓扑中,在分组KSTREAM-FILTER-0000000002节点和sink节点之间注入无状态KSTREAM-FILTER-0000000005节点,以过滤出聚合键为空的任何中间记录。
在第二个子拓扑中,聚合节点KSTREAM-AGGREGATE-0000000003与一个名为Counts的state store相关联(这个名称是由count操作符指定的)。在收到即将到来的流源节点的每条记录后,聚合处理器将首先查询它的相关计数存储,以获得该键的当前计数,然后再增加一个,然后将新计数写入store。每个更新的键值也将被管道传输到KTABLE-TOSTREAM-0000000007节点,该节点将这个更新流解释为一个记录流,然后再进一步传输到下沉节点KSTREAM-SINK-0000000008以便将其写入卡夫卡。
完整代码如下:
package myapps;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.Topology;
import org.apache.kafka.streams.kstream.KStream;
import java.util.Arrays;
import java.util.Locale;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
public class WordCount {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-wordcount");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
final StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> source = builder.stream("streams-plaintext-input");
source.flatMapValues(value -> Arrays.asList(value.toLowerCase(Locale.getDefault()).split("\\W+")))
.groupBy((key, value) -> value)
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("counts-store"))
.toStream()
.to("streams-wordcount-output", Produced.with(Serdes.String(), Serdes.Long());
final Topology topology = builder.build();
final KafkaStreams streams = new KafkaStreams(topology, props);
final CountDownLatch latch = new CountDownLatch(1);
// ... same as Pipe.java above
}
}
转载于:https://my.oschina.net/congwei/blog/1791141
翻译 - Kafka Streams 介绍(一)的更多相关文章
- [翻译]Kafka Streams简介: 让流处理变得更简单
Introducing Kafka Streams: Stream Processing Made Simple 这是Jay Kreps在三月写的一篇文章,用来介绍Kafka Streams.当时Ka ...
- Kafka Streams简介: 让流处理变得更简单
Introducing Kafka Streams: Stream Processing Made Simple 这是Jay Kreps在三月写的一篇文章,用来介绍Kafka Streams.当时Ka ...
- 大全Kafka Streams
本文将从以下三个方面全面介绍Kafka Streams 一. Kafka Streams 概念 二. Kafka Streams 使用 三. Kafka Streams WordCount 一. ...
- Confluent Platform 3.0支持使用Kafka Streams实现实时的数据处理(最新版已经是3.1了,支持kafka0.10了)
来自 Confluent 的 Confluent Platform 3.0 消息系统支持使用 Kafka Streams 实现实时的数据处理,这家公司也是在背后支撑 Apache Kafka 消息框架 ...
- Kafka入门介绍
1. Kafka入门介绍 1.1 Apache Kafka是一个分布式的流平台.这到底意味着什么? 我们认为,一个流平台具有三个关键能力: ① 发布和订阅消息.在这方面,它类似一个消息队列或企业消息系 ...
- 浅谈kafka streams
随着数据时代的到来,数据的实时计算也越来越被大家重视.实时计算的一个重要方向就是实时流计算,目前关于流计算的有很多成熟的技术实现方案,比如Storm.Spark Streaming.flink等.我今 ...
- Kafka Streams演示程序
本文从以下六个方面详细介绍Kafka Streams的演示程序: Step 1: 下载代码 Step 2: 启动kafka服务 Step 3: 准备输入topic并启动Kafka生产者 Step 4: ...
- 简介Kafka Streams
本文从以下几个方面介绍Kafka Streams: 一. Kafka Streams 背景 二. Kafka Streams 架构 三. Kafka Streams 并行模型 四. Kafka Str ...
- kafka基础介绍
kafka基础介绍 一.kafka介绍 1.1主要功能 根据官网的介绍,kafka是一个分布式流媒体的平台,它主要有三大功能: 1.11:It lets you publish and subscri ...
随机推荐
- Java通过Http请求服务器
Java通过Http请求服务器图片输出.下载.转换 Java开发过程中总会遇到从服务器中请求文件(图片.text文档等).此处详情记录从服务器下载图片的方法,以及以多种方式输出. 1.整体流程: 建立 ...
- MySQL数据库三
MySQL数据库三 多表查询: 有条件的内连接 将两张表根据相同的id连接起来 select * from info join details on info.id = details.id sele ...
- Linux网络安全篇,进入SELinux的世界(一)
SELinux 即安全强化的Linux. 一.基本概念 SELinux是通过MAC(强制访问控制,,可以针对特定的进程与特定的文件资源来进行访问权限的控制!也就是说即使你是root,在使用不同的进程时 ...
- 数据库里账号的密码,需要怎样安全的存放?—— 密码哈希(Password Hash)
最早在大学的时候,只知道用 MD5 来存用户的账号的密码,但其实这非常不安全,而所用到的哈希函数,深入挖掘,也发现并不简单-- 一.普通的 Hash 函数 哈希(散列)函数是什么就不赘述了. 1.不推 ...
- SIM900A 通过RS232串口进行短信的发送。
一.基本数据 1.SIM900A模块支持RS232串口和LVTTL串口.保留了232口,在学习或者开发时可以监听51低端单片机和模块指令执行情况,能更快的找出原因,节省开发和学习的时间. 2.此模块供 ...
- floyd三重循环最外层为什么一定是K
Floyd算法为什么把k放在最外层? - 知乎 https://www.zhihu.com/question/30955032高票答案: 简单地总结一下:K没放在最外面一定是错的,但是在某些数据比较水 ...
- readelf命令
//查看文件头信息 readelf -h [file] //查看文件依赖的动态库 readelf -d [file] //查看文件中的符号 readelf -s [file]
- spring中BeanPostProcessor之三:InitDestroyAnnotationBeanPostProcessor(01)
在<spring中BeanPostProcessor之二:CommonAnnotationBeanPostProcessor(01)>一文中,分析到在调用CommonAnnotationB ...
- 接口测试中实际发生的几个问题——python中token传递
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:AFKplayer PS:如有需要Python学习资料的小伙伴可以加点 ...
- 一文回顾Reids五大对象(数据类型)
Redis 是一个高性能的分布式内存型数据库,在国内外各大互联网公司中都有着广泛的使用,即使是一些非互联网公司中也有着非常重要的适用场景,所以对 Redis 的掌握也成为后端工程师必备的基础技能,在面 ...