【原创】(四)Linux进程调度-组调度及带宽控制
背景
Read the fucking source code!--By 鲁迅A picture is worth a thousand words.--By 高尔基
说明:
- Kernel版本:4.14
- ARM64处理器,Contex-A53,双核
- 使用工具:Source Insight 3.5, Visio
1. 概述
组调度(task_group)是使用Linux cgroup(control group)的cpu子系统来实现的,可以将进程进行分组,按组来分配CPU资源等。
比如,看一个实际的例子:
A和B两个用户使用同一台机器,A用户16个进程,B用户2个进程,如果按照进程的个数来分配CPU资源,显然A用户会占据大量的CPU时间,这对于B用户是不公平的。组调度就可以解决这个问题,分别将A、B用户进程划分成组,并将两组的权重设置成占比50%即可。
带宽(bandwidth)控制,是用于控制用户组(task_group)的CPU带宽,通过设置每个用户组的限额值,可以调整CPU的调度分配。在给定周期内,当用户组消耗CPU的时间超过了限额值,该用户组内的任务将会受到限制。
由于组调度和带宽控制紧密联系,因此本文将探讨这两个主题,本文的讨论都基于CFS调度器,开始吧。
2. task_group
- 组调度,在内核中是通过
struct task_group来组织的,task_group本身支持cfs组调度和rt组调度,本文主要分析cfs组调度。 - CFS调度器管理的是
sched_entity调度实体,task_struct(代表进程)和task_group(代表进程组)中分别包含sched_entity,进而来参与调度;
关于组调度的相关数据结构,组织如下:
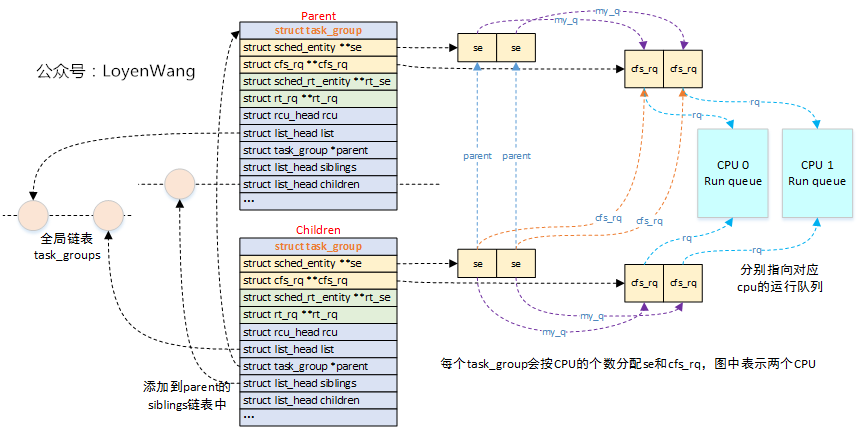
- 内核维护了一个全局链表
task_groups,创建的task_group会添加到这个链表中; - 内核定义了
root_task_group全局结构,充当task_group的根节点,以它为根构建树状结构; struct task_group的子节点,会加入到父节点的siblings链表中;- 每个
struct task_group会分配运行队列数组和调度实体数组(以CFS为例,RT调度类似),其中数组的个数为系统CPU的个数,也就是为每个CPU都分配了运行队列和调度实体;
对应到实际的运行中,如下:
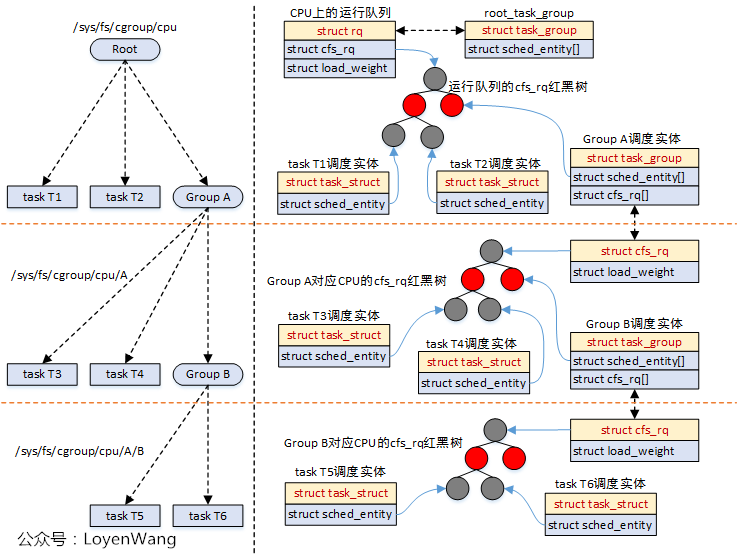
struct cfs_rq包含了红黑树结构,sched_entity调度实体参与调度时,都会挂入到红黑树中,task_struct和task_group都属于被调度对象;task_group会为每个CPU再维护一个cfs_rq,这个cfs_rq用于组织挂在这个任务组上的任务以及子任务组,参考图中的Group A;- 调度器在调度的时候,比如调用
pick_next_task_fair时,会从遍历队列,选择sched_entity,如果发现sched_entity对应的是task_group,则会继续往下选择; - 由于
sched_entity结构中存在parent指针,指向它的父结构,因此,系统的运行也能从下而上的进行遍历操作,通常使用函数walk_tg_tree_from进行遍历;
2.2 task_group权重
- 进程或进程组都有权重的概念,调度器会根据权重来分配CPU的时间。
- 进程组的权重设置,可以通过
/sys文件系统进行设置,比如操作/sys/fs/cgoup/cpu/A/shares;
调用流程如下图:
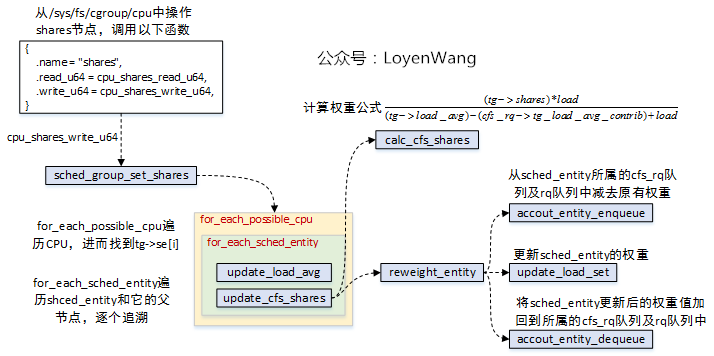
sched_group_set_shares来完成最终的设置;task_group为每个CPU都分配了一个sched_entity,针对当前sched_entity设置更新完后,往上对sched_entity->parent设置更新,直到根节点;shares的值计算与load相关,因此也需要调用update_load_avg进行更新计算;
看一下实际的效果图吧:
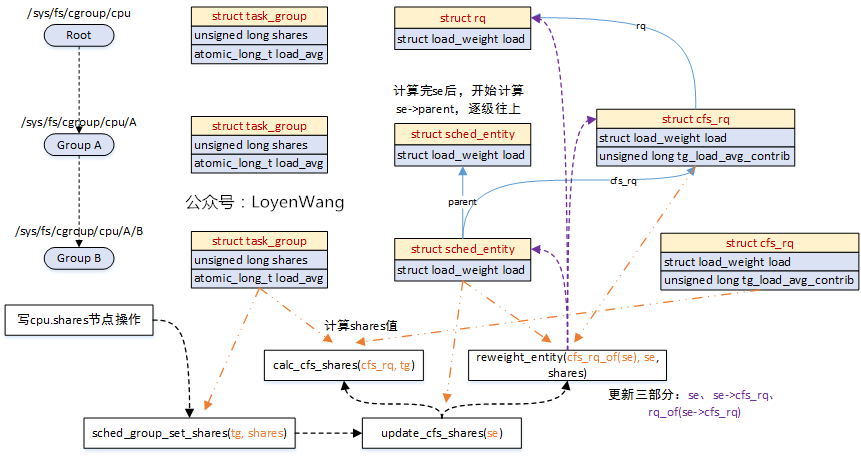
- 写节点操作可以通过
echo XXX > /sys/fs/cgroup/cpu/A/B/cpu.shares; - 橙色的线代表传入参数指向的对象;
- 紫色的线代表每次更新涉及到的对象,包括三个部分;
- 处理完
sched_entity后,继续按同样的流程处理sched_entity->parent;
3. cfs_bandwidth
先看一下/sys/fs/cgroup/cpu下的内容吧:

- 有两个关键的字段:
cfs_period_us和cfs_quota_us,这两个与cfs_bandwidth息息相关; period表示周期,quota表示限额,也就是在period期间内,用户组的CPU限额为quota值,当超过这个值的时候,用户组将会被限制运行(throttle),等到下一个周期开始被解除限制(unthrottle);
来一张图直观理解一下:

- 在每个周期内限制在
quota的配额下,超过了就throttle,下一个周期重新开始;
3.1 数据结构
内核中使用struct cfs_bandwidth来描述带宽,该结构包含在struct task_group中。
此外,struct cfs_rq中也有与带宽控制相关的字段。
还是来看一下代码吧:
struct cfs_bandwidth {
#ifdef CONFIG_CFS_BANDWIDTH
raw_spinlock_t lock;
ktime_t period;
u64 quota, runtime;
s64 hierarchical_quota;
u64 runtime_expires;
int idle, period_active;
struct hrtimer period_timer, slack_timer;
struct list_head throttled_cfs_rq;
/* statistics */
int nr_periods, nr_throttled;
u64 throttled_time;
#endif
};
- period:周期值;
- quota:限额值;
- runtime:记录限额剩余时间,会使用quota值来周期性赋值;
- hierarchical_quota:层级管理任务组的限额比率;
- runtime_expires:每个周期的到期时间;
- idle:空闲状态,不需要运行时分配;
- period_active:周期性计时已经启动;
- period_timer:高精度周期性定时器,用于重新填充运行时间消耗;
- slack_timer:延迟定时器,在任务出列时,将剩余的运行时间返回到全局池里;
- throttled_cfs_rq:限流运行队列列表;
- nr_periods/nr_throttled/throttled_time:统计值;
struct cfs_rq结构中相关字段如下:
struct cfs_rq {
...
#ifdef CONFIG_CFS_BANDWIDTH
int runtime_enabled;
u64 runtime_expires;
s64 runtime_remaining;
u64 throttled_clock, throttled_clock_task;
u64 throttled_clock_task_time;
int throttled, throttle_count;
struct list_head throttled_list;
#endif /* CONFIG_CFS_BANDWIDTH */
...
}
- runtime_enabled:周期计时器使能;
- runtime_expires:周期计时器到期时间;
- runtime_remaining:剩余的运行时间;
3.2 流程分析
3.2.1 初始化流程
先看一下初始化的操作,初始化函数init_cfs_bandwidth本身比较简单,完成的工作就是将struct cfs_bandwidth结构体进程初始化。
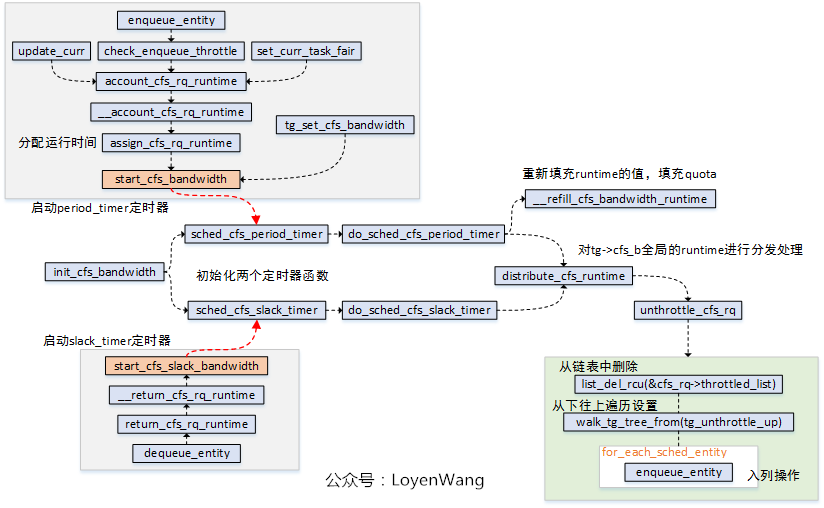
- 注册两个高精度定时器:
period_timer和slack_timer; period_timer定时器,用于在时间到期时重新填充关联的任务组的限额,并在适当的时候unthrottlecfs运行队列;slack_timer定时器,slack_period周期默认为5ms,在该定时器函数中也会调用distribute_cfs_runtime从全局运行时间中分配runtime;start_cfs_bandwidth和start_cfs_slack_bandwidth分别用于启动定时器运行,其中可以看出在dequeue_entity的时候会去利用slack_timer,将运行队列的剩余时间返回给tg->cfs_b这个runtime pool;unthrottle_cfs_rq函数,会将throttled_list中的对应cfs_rq删除,并且从下往上遍历任务组,针对每个任务组调用tg_unthrottle_up处理,最后也会根据cfs_rq对应的sched_entity从下往上遍历处理,如果sched_entity不在运行队列上,那就重新enqueue_entity以便参与调度运行,这个也就完成了解除限制的操作;
do_sched_cfs_period_timer函数与do_sched_cfs_slack_timer()函数都调用了distrbute_cfs_runtime(),该函数用于分发tg->cfs_b的全局运行时间runtime,用于在该task_group中平衡各个CPU上的cfs_rq的运行时间runtime,来一张示意图:
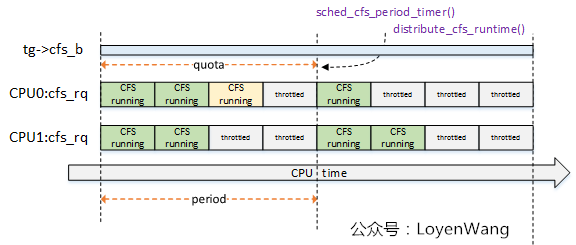
- 系统中两个CPU,因此
task_group针对每个cpu都维护了一个cfs_rq,这些cfs_rq来共享该task_group的限额运行时间; - CPU0上的运行时间,浅黄色模块表示超额了,那么在下一个周期的定时器点上会进行弥补处理;
3.2.2 用户设置流程
用户可以通过操作/sys中的节点来进行设置:

- 操作
/sys/fs/cgroup/cpu/下的cfs_quota_us/cfs_period_us节点,最终会调用到tg_set_cfs_bandwidth函数; tg_set_cfs_bandwidth会从root_task_group根节点开始,遍历组调度树,并逐个设置限额比率 ;- 更新
cfs_bandwidth的runtime信息; - 如果使能了
cfs_bandwidth功能,则启动带宽定时器; - 遍历
task_group中的每个cfs_rq队列,设置runtime_remaining值,如果cfs_rq队列限流了,则需要进行解除限流操作;
3.2.3 throttle限流操作
cfs_rq运行队列被限制,是在throttle_cfs_rq函数中实现的,其中调用关系如下图:

- 调度实体
sched_entity入列时,进行检测是否运行时间已经达到限额,达到则进行限制处理; pick_next_task_fair/put_prev_task_fair在选择任务调度时,也需要进行检测判断;
3.2.4 总结
总体来说,带宽控制的原理就是通过task_group中的cfs_bandwidth来管理一个全局的时间池,分配给属于这个任务组的运行队列,当超过限额的时候则限制队列的调度。同时,cfs_bandwidth维护两个定时器,一个用于周期性的填充限额并进行时间分发处理,一个用于将未用完的时间再返回到时间池中,大抵如此。
组调度和带宽控制就先分析到此,下篇文章将分析CFS调度器了,敬请期待。

【原创】(四)Linux进程调度-组调度及带宽控制的更多相关文章
- 【原创】(六)Linux进程调度-实时调度器
背景 Read the fucking source code! --By 鲁迅 A picture is worth a thousand words. --By 高尔基 说明: Kernel版本: ...
- Linux进程组调度机制分析【转】
转自:http://oenhan.com/task-group-sched 又碰到一个神奇的进程调度问题,在系统重启过程中,发现系统挂住了,过了30s后才重新复位,真正系统复位的原因是硬件看门狗重启的 ...
- 【原创】(五)Linux进程调度-CFS调度器
背景 Read the fucking source code! --By 鲁迅 A picture is worth a thousand words. --By 高尔基 说明: Kernel版本: ...
- 《Linux内核设计与实现》读书笔记 第四章 进程调度
第四章进程调度 进程调度程序可看做在可运行太进程之间分配有限的处理器时间资源的内核子系统.调度程序是多任务操作系统的基础.通过调度程序的合理调度,系统资源才能最大限度地发挥作用,多进程才会有并发执行的 ...
- Linux进程调度器的设计--Linux进程的管理与调度(十七)
1 前景回顾 1.1 进程调度 内存中保存了对每个进程的唯一描述, 并通过若干结构与其他进程连接起来. 调度器面对的情形就是这样, 其任务是在程序之间共享CPU时间, 创造并行执行的错觉, 该任务分为 ...
- Linux进程调度器概述--Linux进程的管理与调度(十五)
调度器面对的情形就是这样, 其任务是在程序之间共享CPU时间, 创造并行执行的错觉, 该任务分为两个不同的部分, 其中一个涉及调度策略, 另外一个涉及上下文切换. 1 背景知识 1.1 什么是调度器 ...
- Linux内核分析——第四章 进程调度
第四章 进程调度 4.1 多任务 1.多任务操作系统就是能同时并发的交互执行多个进程的操作系统. 2.多任务操作系统使多个进程处于堵塞或者睡眠状态,实际不被投入执行,这些任务尽管位于内存,但是并不处于 ...
- 《Linux内核设计与实现》第八周读书笔记——第四章 进程调度
<Linux内核设计与实现>第八周读书笔记——第四章 进程调度 第4章 进程调度35 调度程序负责决定将哪个进程投入运行,何时运行以及运行多长时间,进程调度程序可看做在可运行态进程之间分配 ...
- 《Linux内核设计与实现》 第八周读书笔记 第四章 进程调度
20135307 张嘉琪 第八周读书笔记 第四章 进程调度 调度程序负责决定将哪个进程投入运行,何时运行以及运行多长时间,进程调度程序可看做在可运行态进程之间分配有限的处理器时间资源的内核子系统.只有 ...
随机推荐
- linear correlation coefficient|Correlation and Causation|lurking variables
4.4 Linear Correlation 若由SxxSyySxy定义则为: 所以为了计算方便: 所以,可以明白的是,Sxx和Sx是不一样的! 所以,t r is independent of th ...
- 2013 ACM网络搜索与数据挖掘国际会议
ACM网络搜索与数据挖掘国际会议" title="2013 ACM网络搜索与数据挖掘国际会议"> 编者按:ACM网络搜索与数据挖掘国际会议(6th ACM Conf ...
- JS代码,从一个数组中得到连号的数并显示
JavaScript code function m() { var k = [1, 2, 7, 8, 9, 11, 22, 35, 36]; ) return; ; ; ; ; i < k.l ...
- tmux的基本用法
tmux的基本用法: tmux #启动 C-b d #挂起,效果如同screen中的C-a d tmux attach #恢复会话,效果如同screen中的screen -r 更多功能(需要在tmux ...
- [LC] 221. Maximal Square
Given a 2D binary matrix filled with 0's and 1's, find the largest square containing only 1's and re ...
- JavaScript小数转百分比
在浏览器的控制台操作0.28*100会得到28.000000000000004这样一个不太精确的值 进行转换 toPercent(point){ let str = Number(point * 10 ...
- Centos_7安装python-pip
使用yum -y install python-pip安装pip时,会报出”No package python-pip available.“. 使用命令: yum -y install epel-r ...
- (六)mybatis-spring集成完整版
mybatis-spring集成完整版 一.项目整体 mybatis接口层.mapper层 Service层 Test调用测试 二.自动生成代码-mybatis generator 主要修改: 接口. ...
- springboot oauth 鉴权之——password鉴权相当于jwt鉴权模式
近期一直在研究鉴权方面的各种案例,这几天有空,写一波总结及经验. 第一步:什么是 OAuth鉴权 OAuth2是工业标准的授权协议.OAuth2取代了在2006创建的原始OAuthTM协议所做的工作. ...
- connect() failed (111: Connection refused) while connecting to upstream报错处理
新lnmp环境调试项目时,nginx报错如下: 解决: 发现php-fpm.conf是以套接字方式通信,而nginx是以端口方式通信,见下图: 将nginx.conf修改为如下,重新reload即可