MySQL笔记(3)-- SQL分析
- Linux服务器安装MySQL后,直接命令mysql进入服务,需进行修改:
/usr/bin/mysqladmin -u root password 123456
设置开机自启动:
chkconfig mysql on ---设置开机自启动mysql
chkconfig --list|grep mysql --查看mysql的运行级别
ntsysv --看到[*]mysql这一行,表示开机后自动启动mysql- MySQL客户端和服务器编码格式默认使用latin1,导致插入中文乱码,配置文件my.cnf进行修改字符集:
[client]节点下面添加:
default-character-set=utf8
[mysqld]节点下面添加:
character_set_server=utf8
character_set_client=utf8
collation-server=utf8_general_ci
[mysql]节点下面添加:
default-character-set=utf8 - MySQL主要配置文件信息:
- 二进制日志log-bin:主要用于主从复制;
- 错误日志log-error:默认关闭,记录严重的警告和错误信息,每次启动和关闭的详细信息等;
- 查询日志log:默认关闭,记录查询的sql语句,如果开启会降低MySQL的整体性能;
- 数据文件【每个库对应在磁盘中有下面文件】:
- frm文件:存放表结构;
- myd文件:存放表数据;
- myi文件:存放表索引;
- SQL执行加载顺序:
手写:
select distinct 列表
form 表
连接类型 join 表2
on 连接条件
where 筛选条件
group by 分组列表
having 分组后的筛选
order by 排序列表
limit 偏移,条目数
机读:
from 表
on 连接条件
连接类型 join 表2
where 筛选条件
group by 分组列表
having 分组后的筛选
select distinct 列表
order by 排序列表
limit 偏移,条目数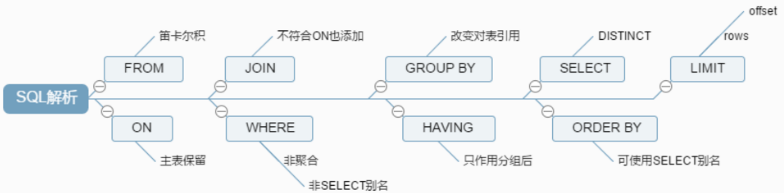
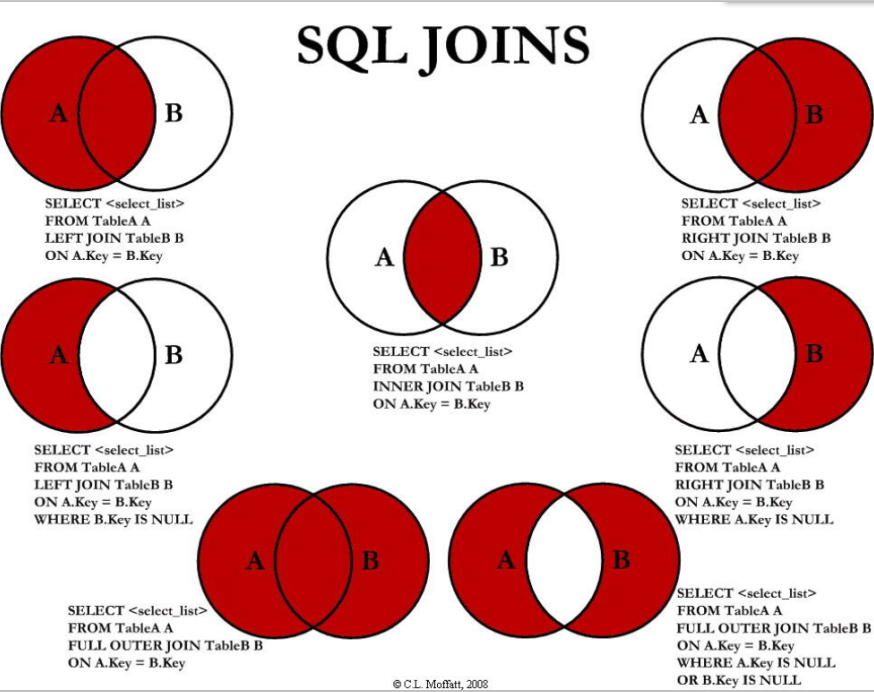
- 7种join:
- 内连接,共有部分:select A.*,B.* from A inner join B on A.id=B.id;
- 左连接:
- 共有部分+右表没有的匹配补null:select A.*,B.* from A left join B on A.id = B.id;【若建立索引进行SQL优化,需对右表B出现的字段建立索引,因为left join条件用于确定如何从右表搜索行,左边一定都有】
- 左表独有:select A.*,B.* from A left join B on A.id = B.id where B.id is null;
- 右连接:
- 共有部分+左表没有的匹配补null:select A.*,B.* from A right join B on A.id = B.id;【若建立索引进行SQL优化,需对左表A出现的字段建立索引,因为right join条件用于确定如何从左表搜索行,右边一定都有】
- 左表独有:select A.*,B.* from A right join B on A.id = B.id where A.id is null;
- 全连接union:
- 合并去重,全连接:select A.*,B.* from A left join B on A.id = B.id union select A.*,B.* from A right join B on A.id = B.id;
- 左右表独有:select A.*,B.* from A left join B on A.id = B.id where B.id is null union select A.*,B.* from A right join B on A.id = B.id where A.id is null;
- 索引:
- 优势:提高数据检索的效率,降低数据库的IO成本;通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗。
- 劣势:索引是一张表,该表保存了主键和索引字段,并指向实体表的记录,所以索引列是要占用空间的;索引提高了查找速度,但降低了更新速度,对表进行insert、update、delete时,MySQL不仅要保存数据,还要保存索引文件每次更新添加 了索引列的字段,调整更新带来的键值变化后的信息。
- 分类:
- 单值索引:一个索引只有一个列,一个表可以有多个单值索引;
- 唯一索引:索引列的值必须唯一,但可以有null值;
- 复合索引:一个索引包含多个列;
- BTree索引原理
- 索引创建的情况:
- 主键自动建立唯一索引;
- 频繁作为查询条件的字段;
- 查询中与其他表关联的字段,外键关系建立索引;
- 查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度【索引加快检索和排序速度】;
- 查询中统计或分组字段;【分组与排序配合使用,分组前必须排序】
- 高并发下倾向创建组合索引;
- 频繁更新的字段不适合创建索引;【需要更新索引信息】
- where条件里用不到的字段不创建索引;
- 字段存储的值重复,该字段不适合创建索引;
- explain,分析查询语句和表机构性能瓶颈:explain+查询SQL
- 作用:查看表的读取顺序【id】;数据读取操作的操作类型【select_type】;哪些索引可以使用【possible_key】;哪些索引实际被使用【key】;表之间的引用【ref】;每张表有多少行被优化器查询【rows】;
- 查看执行计划包含的信息

id:select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序【id为null,最后执行】
- id相同,执行顺序从上到下

- id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
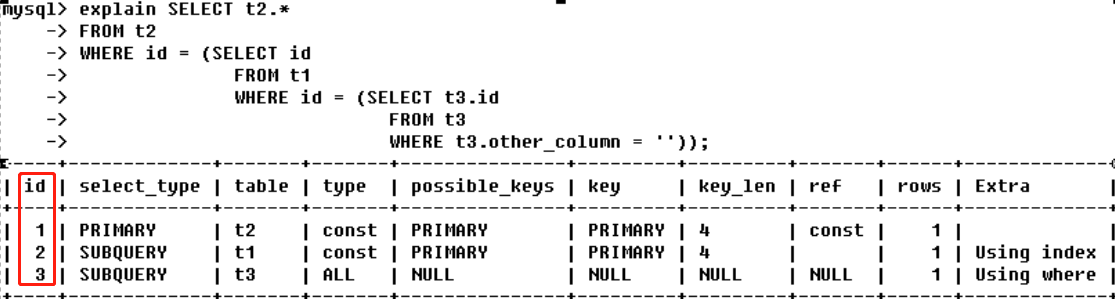
- id相同不同,同时存在:id如果相同,可以认为是一组,从上到下顺序执行;在所有组中,id值越大,优先级越高,越先被执行;【衍生=DERIVED】
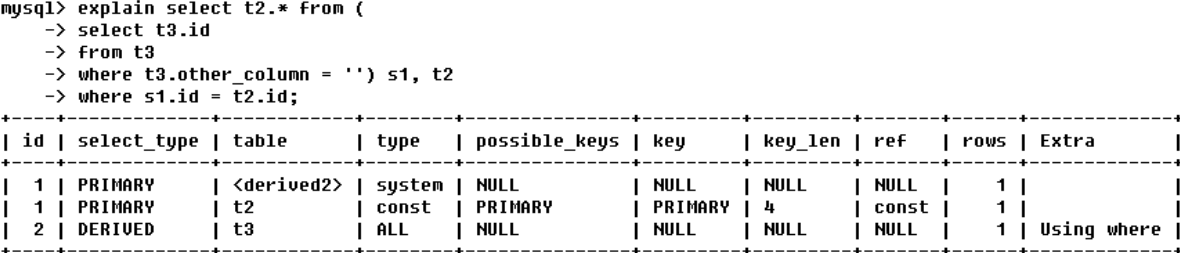
- id相同,执行顺序从上到下
select_type:查询的类型,主要是用于区分普通查询、联合查询、子查询等复杂查询
- SIMPLE:简单的select查询,查询中不包含子查询或UNION;
- PRIMARY:查询中若包含任何复杂的子部分,最外层查询则为PRIMARY;【select *from A where id =(select id from B)中A表为PRIMARY】
- SUBQUERY:在select或where列表中包含了子查询;
- DERIVED:在from列表中包含的子查询为DERIVED(衍生),MySQL会递归执行这些子查询,把结果放在临时表里;
- UNION:若第二个select出现在union之后,则被标记为UNION;若UNION包含在from子句的子查询中,外层select被标记为DERIVED;【分析前面7种join中的合并去重,全连接sql】
- UNION RESULT:从UNION表获取结果的select;
table:显示这一行的数据是关于哪张表的;
type:访问类型【all、index、range、ref、eq_ref、const、system、NULL】,显示查询使用了何种类型,从最好到最差依次是system>const>eq_ref>ref>range>index>all
- system:表只有一行记录,等于系统表;
- const:表示通过索引一次就找到了,const用于比较primary key或unique索引;因为只匹配一行数据,所以很快;如将主键置于where条件中,MySQL就能将该查询转换为一个常量;

- eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配,常见于主键或唯一索引扫描;【由t2进行驱动查找】

- ref:非唯一性索引扫描,本质是一种索引访问,它返回所有匹配某个单独值的行,然而,它可能会找到多个符合条件的行,所以应该属于查找和扫描的混合体
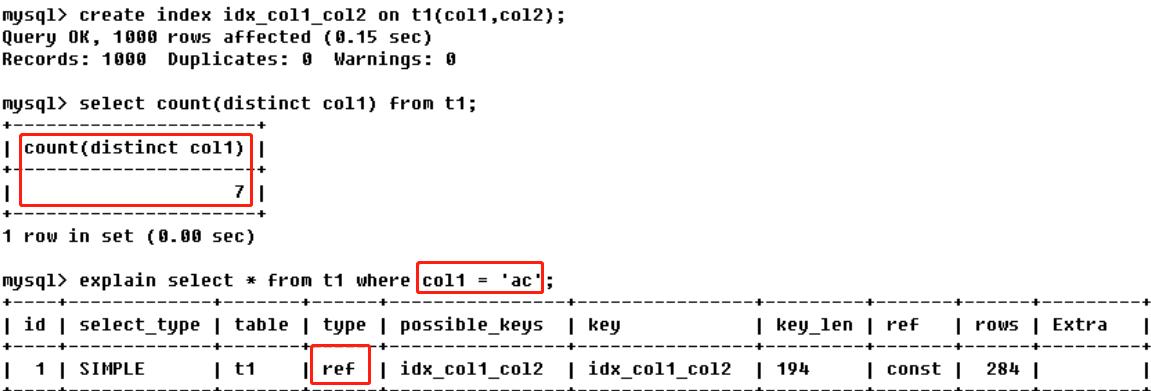
- range:只检索给定范围的行,使用一个索引来进行;一般在where条件中出现了between、<、>、in等的查询;这种范围扫描索引比全表扫描要好,因为它只需要开始于索引的某一点,结束于另一点,不用扫描全部索引;【如果索引字段是a,b,c,条件中使用了a的值是常量,b是范围,对c进行排序,会导致索引失效】【优化:对范围的字段从索引列中删除,即覆盖索引a,b,c改为a,c,从而变成ref级别】
- index:Full Index Scan全索引扫描,index与all区别为index类型只遍历索引树;通常比all快,因为索引文件通常比数据文件小;【all和index都是读全表,但index是从索引中读取,all是从磁盘中读取】
- all:全表扫描,遍历全表查找符合的数据行;
possible_keys:显示可以应用在这张表中索引,一个或多个;查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用;
key:实际使用的索引,如果没null【进行全表扫描】,则没有使用索引;查询中若使用了覆盖索引,则该索引仅出现在key列表中【查询的字段个数、顺序与索引一一对应】;

key_len:表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度;在不损失精确性的情况下,长度越短越好;key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的;

ref:显示索引的哪一列被使用了【库名.表名,被使用列名】,如果可能的话,是一个常数【const】;哪些列或常量被用于查找索引列上的值;

rows:根据表统计信息及索引选用情况,大致估算出找到所需记录所需要读取的行数;
extra::包含不适合在其他列中显示但十分重要的额外信息
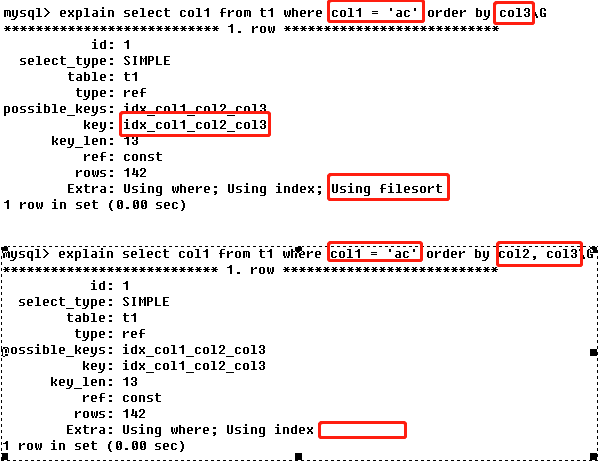
- Using filesort:说明MySQL会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取【创建了一个组合索引包含a,b,c,但在where条件和order by排序时,只使用了a,c,导致这个索引出现了断层,会出现文件排序】;MySQL中无法利用索引完成的排序操作称为“文件排序”;
- Using temporary:使用了临时表保存中间结果,MySQL在对查询结果进行排序时使用临时表,常见于排序order by和分组查询group by;【临时表增加数据库负担】
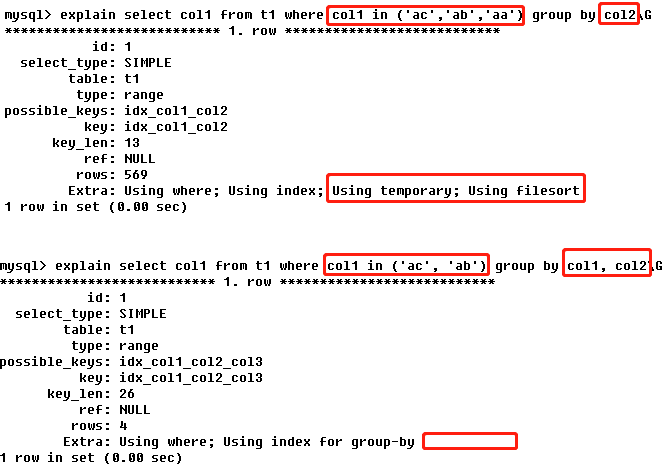
- Using index:表示相应的select操作中使用了覆盖索引【覆盖索引:创建的索引包含a,b,进行select查询的列全包含或部分包含如a,b或a】,避免访问了表的数据行,效率不错;如果同时出现using where,表明索引被用来执行索引键值的查找;如果没有同时出现using where,表明索引用来读取数据而非执行查找动作;

- Using where:表明使用了where过滤;
- using join buffer:使用了连接缓存;【出现在多表的inner join内连接中】【最好在my.cnf配置文件中的缓存调大点】
- impossible where: where子句的值总是false,不能用来获取任何元组;

- select tables optimized away:在没有group by子句的情况下,基于索引优化MIN/MAX操作或对于MyISAM存储引擎优化count(*)操作,不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化;
- distinct:优化distinct操作,在找到第一匹配的元组后即停止找同样值的动作;
- Using filesort:说明MySQL会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取【创建了一个组合索引包含a,b,c,但在where条件和order by排序时,只使用了a,c,导致这个索引出现了断层,会出现文件排序】;MySQL中无法利用索引完成的排序操作称为“文件排序”;
MySQL笔记(3)-- SQL分析的更多相关文章
- 【MySQL笔记】SQL语言四大类语言
SQL语言共分为四大类:数据查询语言DQL,数据操纵语言DML,数据定义语言DDL,数据控制语言DCL. 1. 数据查询语言DQL 数据查询语言DQL基本结构是由SELECT子句,FROM子句, ...
- MySQL笔记(5)-- SQL执行流程,MySQL体系结构
MySQL的体系结构,可以清楚地看到 SQL 语句在 MySQL 的各个功能模块中的执行过程:Server层包括连接层.查询缓存.分析器.优化器.执行器等,涵盖MySQL的大多数核心服务功能,以及所有 ...
- MySQL SQL分析(SQL profile)
分析SQL优化运营开销SQL的重要手段.在MySQL数据库.可配置profiling参数启用SQL分析.此参数可以在全局和session水平集.级别则作用于整个MySQL实例,而session级别紧影 ...
- mysql show profiles使用分析sql性能
mysql show profiles使用分析sql性能 Show profiles是5.0.37之后添加的,要想使用此功能,要确保版本在5.0.37之后. 查看一下我的数据库版本 mysql> ...
- MySQL笔记(6)-- SQL更新语句日志系统流程
一.背景 在上一篇[MySQL笔记(5)-- SQL执行流程,MySQL体系结构]中讲述了select查询语句在MySQL体系中的运行流程,从连接器开始,到分析器.优化器.执行器等,最后到达存储引擎. ...
- (2)MySQL进阶篇SQL优化(show status、explain分析)
1.概述 在应用系统开发过程中,由于初期数据量小,开发人员写SQL语句时更重视功能上的实现,但是当应用系统正式上线后,随着生产数据量的急剧增长,很多SQL语句开始逐渐显露出性能问题,对生产环境的影响也 ...
- Mysql慢SQL分析及优化
为何对慢SQL进行治理 从数据库角度看:每个SQL执行都需要消耗一定I/O资源,SQL执行的快慢,决定资源被占用时间的长短.假设总资源是100,有一条慢SQL占用了30的资源共计1分钟.那么在这1分钟 ...
- 技术分析 | 浅谈在MySQL体系下SQL语句是如何在系统中执行的及可能遇到的问题
欢迎来到 GreatSQL社区分享的MySQL技术文章,如有疑问或想学习的内容,可以在下方评论区留言,看到后会进行解答 SQL语句大家并不陌生,但某种程度上来看,我们只是知道了这条语句是什么功能,它可 ...
- Mysql中的sql是如何执行的 --- 极客时间学习笔记
MySQL中的SQL是如何执行的 MySQL是典型的C/S架构,也就是Client/Server架构,服务器端程序使用的mysqld.整体的MySQL流程如下图所示: MySQL是有三层组成: 连接层 ...
- MySQL监控、性能分析——工具篇
https://blog.csdn.net/leamonjxl/article/details/6431444 MySQL越来越被更多企业接受,随着企业发展,MySQL存储数据日益膨胀,MySQL的性 ...
随机推荐
- TCP 为什么是三次握手,而不是两次或四次?
TCP是一种全双工的可靠传输协议,核心思想:保证数据可靠传输以及数据的传输效率 A------B 二次握手: 1.A发送同步信号SYN+A's initial sequence number 2.B发 ...
- MySQL数据类型(DATA Type)与数据恢复与备份方法
一.数据类型(DATA Type)概述 MySQL支持多种类型的SQL数据类型:数字类型,日期和时间类型,字符串(字符和字节)类型以及空间类型 数据类型描述使用以下约定: M表示整数类型的最大显示宽度 ...
- CSAPC08台湾邀请赛_T1_skyline
题目链接:CSAPC08台湾邀请赛_T1_skyline 题目描述 一座山的山稜线由许多片段的45度斜坡构成,每一个片段不是上坡就是下坡. / / * / / * / // / // / 在我 ...
- Solr7.3.0入门教程,部署Solr到Tomcat,配置Solr中文分词器
solr 基本介绍 Apache Solr (读音: SOLer) 是一个开源的搜索服务器.Solr 使用 Java 语言开发,主要基于 HTTP 和 Apache Lucene 实现.Apache ...
- Rime输入法一些设定
有鉴于谷歌搜狗拼音等不太好用,但是博主一直页没找到合心的输入法,直到遇见Rime,中州韵就是我想要的输入法.记录一下自己用的时候的修改,以备查询.注意:缩进不要弄丢,所有更改完都需要重新部署才能生效. ...
- CentOS7用yum安装wget命令后仍然提示命令找不到的解决方法
需求:用的AWS实例自带的CentOS7用yum安装wget命令后扔提示命令找不到,后面用源码安装方式解决,下面先讲解决方法,疑问及知识点扩展最后写出 1.问题(因是mini版本系统,有些基本命令扔需 ...
- 借助mkcert签发本地证书
mkcert 是由 Filippo Valsorda 使用go语言开源的一款零配置搭建本地证书服务的工具,它可以兼容Window, Linux, macOS等多种开发平台,省去了我们自签本地证书的繁琐 ...
- 实现子数组和绝对值差最小 - Objective-C
类似于背包问题,前提条件是数组全是正整数和0,先求和Sum,再从子数组中找出接近Sum/2的子数组 @interface TempState : NSObject @property (nonatom ...
- 张益肇:AI 医疗,微软有哪些布局?
编者按:近几年来,医疗和人工智能碰撞出了相当多的火花,大量资金短期投入到医疗领域当中.然而在微软亚洲研究院副院长张益肇博士看来,人工智能医疗是一场持久战,大家一定要沉下心多调研.多思考.多学习. 人工 ...
- JDK_Packages_java_utils
utils包需要关注的主要有 集合框架.并发包.函数式编程.观察者模式@see PropertyChangeSupport java.util(集合框架) Contains the collect ...