吴裕雄--天生自然PYTHON爬虫:使用Selenium爬取大型电商网站数据
用python爬取动态网页时,普通的requests,urllib2无法实现。例如有些网站点击下一页时,会加载新的内容,但是网页的URL却没有改变(没有传入页码相关的参数),requests、urllib2无法抓取这些动态加载的内容,此时就需要使用Selenium了。

使用Selenium需要选择一个调用的浏览器并下载好对应的驱动,我使用的是Chrome浏览器。
将下载好的chromedrive.exe文件复制到系统路径:E:\python\Scripts下,如果安装python的时候打path勾的话这个目录就会配置到系统path里了,如果没有的话,请手动把这个路径添加到path路径下。
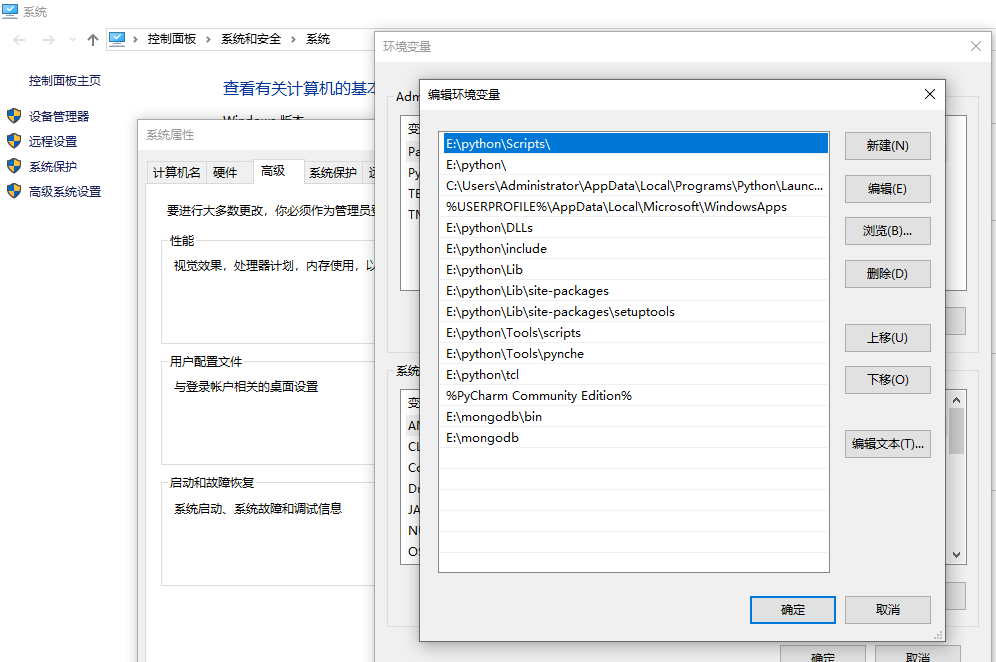
下载的浏览器驱动也要看清楚对应自己浏览器版本的,如果驱动与浏览器版本不对是会报错了。
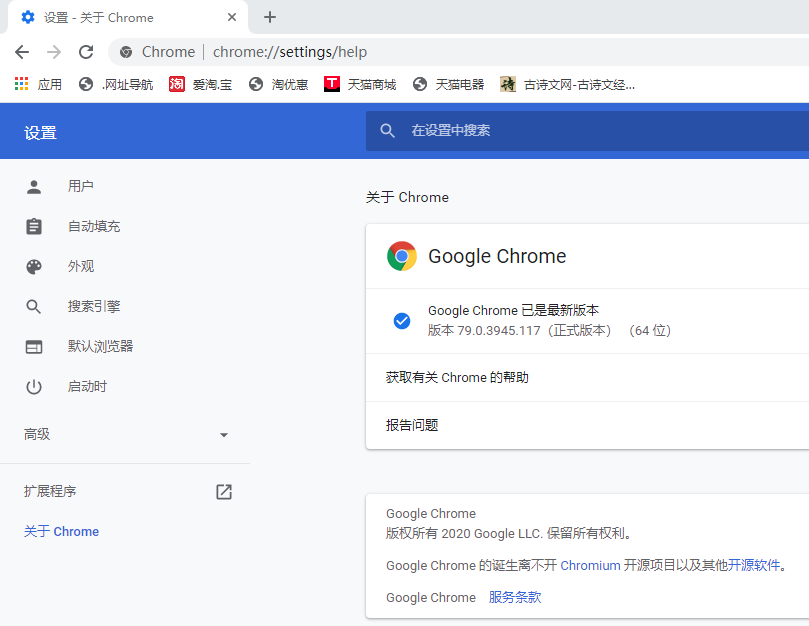
chromedriver与chrome浏览器对照表参考:
https://blog.csdn.net/huilan_same/article/details/51896672
国内不能直接访问Chrome官网,可以在ChromeDriver仓库中下载:http://chromedriver.storage.googleapis.com/index.html

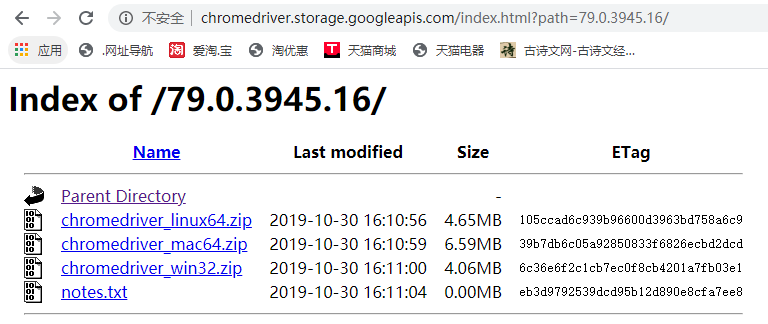
我的浏览器需要下载的是倒数第三个,请读者根据自己的电脑和浏览器的版本实际情况下载;
放到上面的python那个安装文件夹后,我记得也是需要放到chrome浏览器安装目录下的
查找chrome安装路径
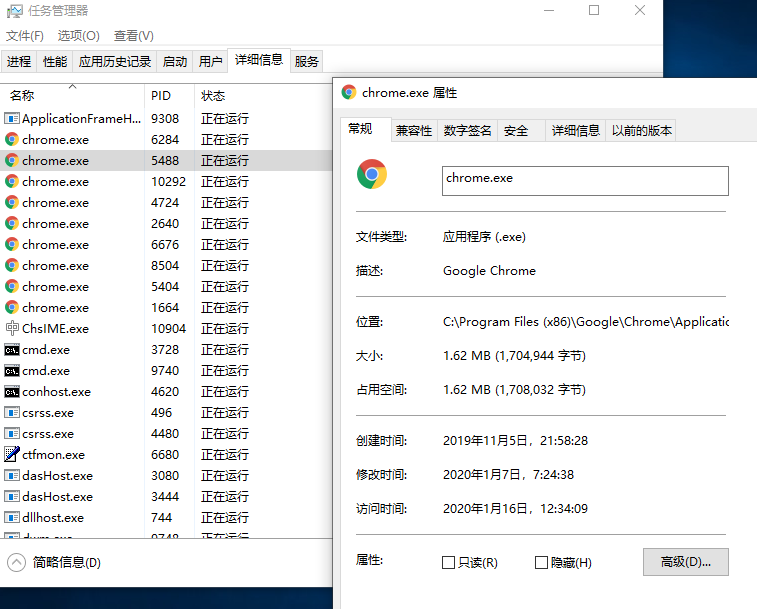
把下载的驱动放到这个路径下
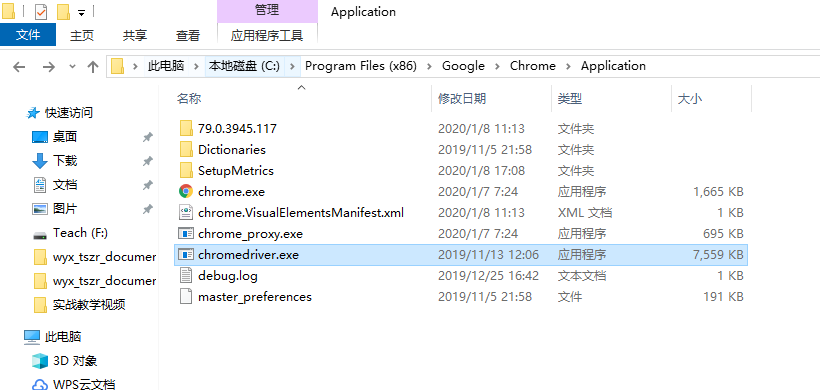
然后也把chrome浏览器的安装路径添加到path路径中。
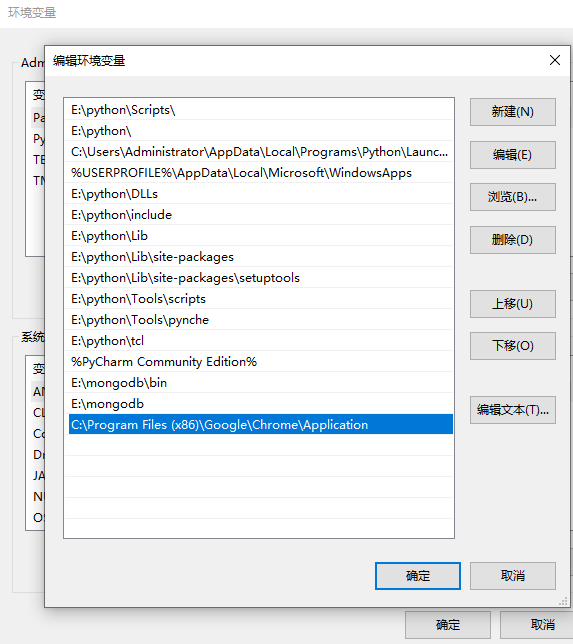
配置好之后,实现爬虫的代码如下:
import time
import random
import requests
import urllib.request from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC def get_url(url):
time.sleep(3)
return(requests.get(url)) if __name__ == "__main__":
driver = webdriver.Chrome() # 初始化一个浏览器对象
dep_cities = ["北京","上海","广州","深圳","天津","杭州","南京","济南","重庆","青岛","大连","宁波","厦门","成都","武汉","哈尔滨","沈阳","西安","长春","长沙","福州","郑州","石家庄","苏州","佛山","烟台","合肥","昆明","唐山","乌鲁木齐","兰州","呼和浩特","南通","潍坊","绍兴","邯郸","东营","嘉兴","泰州","江阴","金华","鞍山","襄阳","南阳","岳阳","漳州","淮安","湛江","柳州","绵阳"]
for dep in dep_cities:
strhtml = get_url('https://m.dujia.qunar.com/golfz/sight/arriveRecommend?dep=' + urllib.request.quote(dep) + '&exclude=&extensionImg=255,175')
arrive_dict = strhtml.json()
for arr_item in arrive_dict['data']:
for arr_item_1 in arr_item['subModules']:
for query in arr_item_1['items']:
driver.get("https://fh.dujia.qunar.com/?tf=package")
# 等待出发地输入框加载完毕,最多等待10s
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, "depCity")))
# 清空出发地文本框,输入出发地和目的地,点击“开始定制”按钮
driver.find_element_by_xpath("//*[@id='depCity']").clear()
driver.find_element_by_xpath("//*[@id='depCity']").send_keys(dep)
driver.find_element_by_xpath("//*[@id='arrCity']").send_keys(query["query"])
driver.find_element_by_xpath("/html/body/div[2]/div[1]/div[2]/div[3]/div/div[2]/div/a").click()
print("dep:%s arr:%s" % (dep, query["query"]))
for i in range(10):
time.sleep(random.uniform(5, 6))
# 如果定位不到页码按钮,说明搜索结果为空
pageBtns = driver.find_elements_by_xpath("html/body/div[2]/div[2]/div[8]")
if pageBtns == []:
break
# 找出所有的路线信息DOM元素
routes = driver.find_elements_by_xpath("html/body/div[2]/div[2]/div[7]/div[2]/div")
for route in routes:
result = {
'date': time.strftime('%Y-%m-%d', time.localtime(time.time())),
'dep': dep,
'arrive': query['query'],
'result': route.text
}
print(result) if i < 9:
# 找到“下一页"按钮并点击翻页
btns = driver.find_elements_by_xpath("html/body/div[2]/div[2]/div[8]/div/div/a")
for a in btns:
if a.text == u"下一页":
a.click()
break driver.close()

可能是网络慢运行的时间有点长才有输出。爬虫的话建议网速带宽要大些这样就会避免一些很乱的错误了。
吴裕雄--天生自然PYTHON爬虫:使用Selenium爬取大型电商网站数据的更多相关文章
- 小白学 Python 爬虫:Selenium 获取某大型电商网站商品信息
目标 先介绍下我们本篇文章的目标,如图: 本篇文章计划获取商品的一些基本信息,如名称.商店.价格.是否自营.图片路径等等. 准备 首先要确认自己本地已经安装好了 Selenium 包括 Chrome ...
- 吴裕雄--天生自然python学习笔记:爬取我国 1990 年到 2017年 GDP 数据并绘图显示
绘制图形所需的数据源通常是不固定的,比如,有时我们会需要从网页抓取, 也可能需从文件或数据库中获取. 利用抓取网页数据技术,把我国 1990 年到 2016 年的 GDP 数据抓取出来 ,再利用 Ma ...
- 吴裕雄--天生自然PYTHON爬虫:使用Scrapy抓取股票行情
Scrapy框架它能够帮助提升爬虫的效率,从而更好地实现爬虫.Scrapy是一个为了抓取网页数据.提取结构性数据而编写的应用框架,该框架是封装的,包含request异步调度和处理.下载器(多线程的Do ...
- 吴裕雄--天生自然PYTHON爬虫:爬取某一大型电商网站的商品数据(效率优化以及代码容错处理)
这篇博文主要是对我的这篇https://www.cnblogs.com/tszr/p/12198054.html爬虫效率的优化,目的是为了提高爬虫效率. 可以根据出发地同时调用多个CPU,每个CPU运 ...
- 吴裕雄--天生自然PYTHON爬虫:爬虫攻防战
我们在开发者模式下不仅可以找到URL.Form Data,还可以在Request headers 中构造浏览器的请求头,封装自己.服务器识别浏览器访问的方法就是判断keywor是否为Request h ...
- 吴裕雄--天生自然PYTHON爬虫:安装配置MongoDBy和爬取天气数据并清洗保存到MongoDB中
1.下载MongoDB 官网下载:https://www.mongodb.com/download-center#community 上面这张图选择第二个按钮 上面这张图直接Next 把bin路径添加 ...
- 吴裕雄--天生自然PYTHON爬虫:用API爬出天气预报信息
天气预报网址:https://id.heweather.com/,这个网站是需要注册获取一个个人认证后台密钥key的,并且每个人都有访问次数的限制,这个key就是访问API的钥匙. 这个key现在是要 ...
- 吴裕雄--天生自然PYTHON爬虫:使用BeautifulSoup解析中国旅游网页数据
import requests from bs4 import BeautifulSoup url = "http://www.cntour.cn/" strhtml = requ ...
- 吴裕雄--天生自然python爬虫:使用requests模块的get和post方式抓取中国旅游网站和有道翻译网站翻译内容数据
import requests url = 'http://www.cntour.cn/' strhtml = requests.get(url) print(strhtml.text) URL='h ...
随机推荐
- C# 对象对比是否相等 工作笔记
需要在Linq 中对比两个对象是否相等 /// <summary> /// 定义一个点 /// </summary> class Point { public int x { ...
- jmeter-BeanShell PreProcessor的使用
BeanShell简介 BeanShell是一个小型嵌入式Java源代码解释器,具有对象脚本语言特性,能够动态地执行标准JAVA语法.在BeanShell中,我们可以使用java语言自定义函数来处理特 ...
- etc/hosts文件详解
Linux 修改 etc/hosts文件 hosts文件 hosts —— the static table lookup for host name(主机名查询静态表). hosts文件是Linux ...
- Django 创建app 应用,数据库配置
一.create project mkdir jango cd jango 目录创建project myapp django-admin startproject myapp 2.在给project创 ...
- django removing hardcoded URLs in template --- 使用变量,把url放在变量中 {% url 'namespace:name' %}
urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^votes/', include("polls.urls", na ...
- JS高级---利用原型共享数据
什么样子的数据是需要写在原型中? 需要共享的数据就可以写原型中 原型的作用之一: 数据共享 //属性需要共享, 方法也需要共享 //不需要共享的数据写在构造函数中,需要共享的数据写在原型中 //构造函 ...
- oracle增加字段,循环
alter table PARAMETETER_CONFIGURATION add (INPUT_IS VARCHAR2(20) ): declare sum_i int:=0; --定义整型变量,存 ...
- TCP协议下的服务端并发,GIL全局解释器锁,死锁,信号量,event事件,线程q
TCP协议下的服务端并发,GIL全局解释器锁,死锁,信号量,event事件,线程q 一.TCP协议下的服务端并发 ''' 将不同的功能尽量拆分成不同的函数,拆分出来的功能可以被多个地方使用 TCP服务 ...
- js遍历传参到html
<p id="subp" hidden><button id= "upsub"shiro:hasPermission="sys:me ...
- Eclipse无法查看第三方jar包文件源代码解决方法
来源于:https://www.cnblogs.com/1995hxt/p/5252098.html 1.打开第三方依赖包,源文件的快捷键:ctrl + mouseClick 2.由于我们下载的第三方 ...