mapreduce 实现矩阵乘法
import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MatrixMultiply {
/** mapper和reducer需要的三个必要变量,由conf.get()方法得到 **/
public static int rowM = 0;
public static int columnM = 0;
public static int columnN = 0; public static class MatrixMapper extends Mapper<Object, Text, Text, Text> {
private Text map_key = new Text();
private Text map_value = new Text(); /**
* 执行map()函数前先由conf.get()得到main函数中提供的必要变量, 这也是MapReduce中共享变量的一种方式
*/
public void setup(Context context) throws IOException {
Configuration conf = context.getConfiguration();
columnN = Integer.parseInt(conf.get("columnN"));
rowM = Integer.parseInt(conf.get("rowM"));
} public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
/** 得到输入文件名,从而区分输入矩阵M和N **/
FileSplit fileSplit = (FileSplit) context.getInputSplit();
String fileName = fileSplit.getPath().getName(); if (fileName.contains("M")) {
String[] tuple = value.toString().split(",");
int i = Integer.parseInt(tuple[0]);
String[] tuples = tuple[1].split("\t");
int j = Integer.parseInt(tuples[0]);
int Mij = Integer.parseInt(tuples[1]); for (int k = 1; k < columnN + 1; k++) {
map_key.set(i + "," + k);
map_value.set("M" + "," + j + "," + Mij);
context.write(map_key, map_value);
}
} else if (fileName.contains("N")) {
String[] tuple = value.toString().split(",");
int j = Integer.parseInt(tuple[0]);
String[] tuples = tuple[1].split("\t");
int k = Integer.parseInt(tuples[0]);
int Njk = Integer.parseInt(tuples[1]); for (int i = 1; i < rowM + 1; i++) {
map_key.set(i + "," + k);
map_value.set("N" + "," + j + "," + Njk);
context.write(map_key, map_value);
}
}
}
} public static class MatrixReducer extends Reducer<Text, Text, Text, Text> {
private int sum = 0; public void setup(Context context) throws IOException {
Configuration conf = context.getConfiguration();
columnM = Integer.parseInt(conf.get("columnM"));
} public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
int[] M = new int[columnM + 1];
int[] N = new int[columnM + 1]; for (Text val : values) {
String[] tuple = val.toString().split(",");
if (tuple[0].equals("M")) {
M[Integer.parseInt(tuple[1])] = Integer.parseInt(tuple[2]);
} else
N[Integer.parseInt(tuple[1])] = Integer.parseInt(tuple[2]);
} /** 根据j值,对M[j]和N[j]进行相乘累加得到乘积矩阵的数据 **/
for (int j = 1; j < columnM + 1; j++) {
sum += M[j] * N[j];
}
context.write(key, new Text(Integer.toString(sum)));
sum = 0;
}
} /**
* main函数
* <p>
* Usage:
*
* <p>
* <code>MatrixMultiply inputPathM inputPathN outputPath</code>
*
* <p>
* 从输入文件名称中得到矩阵M的行数和列数,以及矩阵N的列数,作为重要参数传递给mapper和reducer
*
* @param args 输入文件目录地址M和N以及输出目录地址
*
* @throws Exception
*/ public static void main(String[] args) throws Exception { if (args.length != 3) {
System.err
.println("Usage: MatrixMultiply <inputPathM> <inputPathN> <outputPath>");
System.exit(2);
} else {
String[] infoTupleM = args[0].split("_");
rowM = Integer.parseInt(infoTupleM[1]);
columnM = Integer.parseInt(infoTupleM[2]);
String[] infoTupleN = args[1].split("_");
columnN = Integer.parseInt(infoTupleN[2]);
} Configuration conf = new Configuration();
/** 设置三个全局共享变量 **/
conf.setInt("rowM", rowM);
conf.setInt("columnM", columnM);
conf.setInt("columnN", columnN); Job job = new Job(conf, "MatrixMultiply");
job.setJarByClass(MatrixMultiply.class);
job.setMapperClass(MatrixMapper.class);
job.setReducerClass(MatrixReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path(args[0]), new Path(args[1]));
FileOutputFormat.setOutputPath(job, new Path(args[2]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
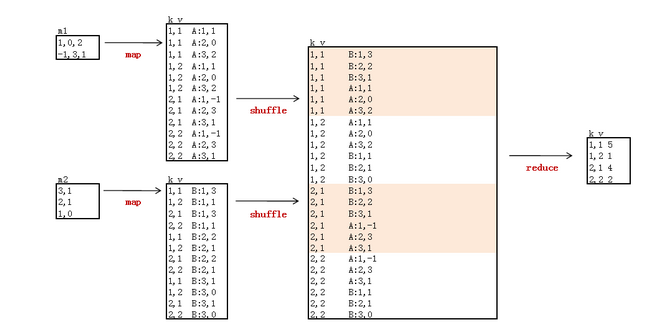
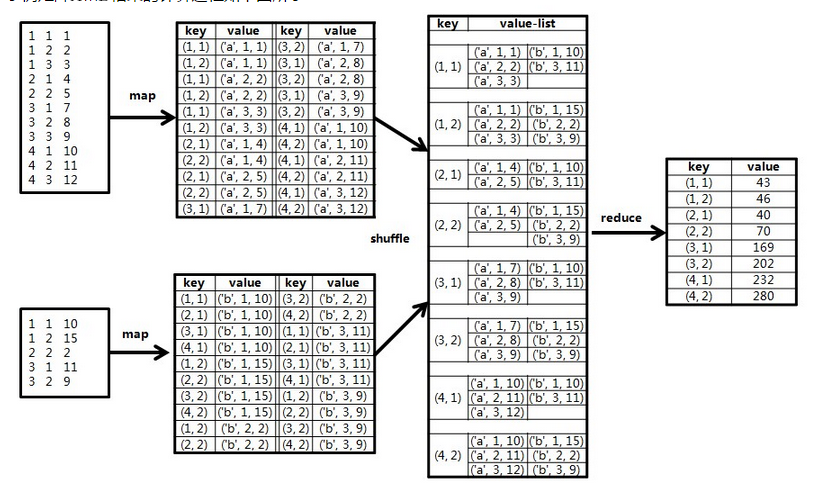
mapreduce 实现矩阵乘法的更多相关文章
- 【甘道夫】MapReduce实现矩阵乘法--实现代码
之前写了一篇分析MapReduce实现矩阵乘法算法的文章: [甘道夫]Mapreduce实现矩阵乘法的算法思路 为了让大家更直观的了解程序运行,今天编写了实现代码供大家參考. 编程环境: java v ...
- MapReduce实现矩阵乘法
简单回想一下矩阵乘法: 矩阵乘法要求左矩阵的列数与右矩阵的行数相等.m×n的矩阵A,与n×p的矩阵B相乘,结果为m×p的矩阵C.具体内容能够查看:矩阵乘法. 为了方便描写叙述,先进行如果: 矩阵A的行 ...
- 基于MapReduce的矩阵乘法
参考:http://blog.csdn.net/xyilu/article/details/9066973文章 文字未得及得总结,明天再写文字,先贴代码 package matrix; import ...
- Python+MapReduce实现矩阵相乘
算法原理 map阶段 在map阶段,需要做的是进行数据准备.把来自矩阵A的元素aij,标识成p条<key, value>的形式,key="i,k",(其中k=1,2,. ...
- 矩阵乘法的MapReduce实现
对于任意矩阵M和N,若矩阵M的列数等于矩阵N的行数,则记M和N的乘积为P=M*N,其中mik 记做矩阵M的第i行和第k列,nkj记做矩阵N的第k行和第j列,则矩阵P中,第i行第j列的元素可表示为公式( ...
- MapReduce实现大矩阵乘法
来自:http://blog.csdn.net/xyilu/article/details/9066973 引言 何 为大矩阵?Excel.SPSS,甚至SAS处理不了或者处理起来非常困难,需要设计巧 ...
- MapReduce的矩阵相乘
一.单个mapreduce的实现 转自:http://blog.sina.com.cn/s/blog_62186b460101ai1x.html 王斌_ICTIR老师的<大数据:互联网大规模数据 ...
- *HDU2254 矩阵乘法
奥运 Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total Submissi ...
- *HDU 1757 矩阵乘法
A Simple Math Problem Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Ot ...
随机推荐
- mysql优化方法
1.选取最适用的字段属性 MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快.因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得尽 ...
- 统计机器学习(statistical machine learning)
组要组成部分:监督学习(supervised learning),非监督学习(unsupervised learning),半监督学习(semi-supervised learning),强化学习(r ...
- DataGridView 操作
//dataGridView 删除选中行 int num = dataGridView2.SelectedRows.Count; ) { DataGridViewRow r = dataGridVie ...
- java 获取数组(二维数组)长度实例程序
我们可能知道 js有个length函数,java也有啊length函数 例 如果数组是data[],则data.length 代码如下 复制代码 byte[] phone =new byte[81]; ...
- DTCMS使用ajax局部刷新
动力启航的DTCMS代码遇到的问题: 前台post请求: $.ajax({ type: "POST", url: sendUrl, dataType: "json&quo ...
- 构建前端Mock Server
写在前面 最开始只是在做活动页面时苦于效率太低制定了这样一个自动化的工作环境, 所以Github上项目名是Rapid-Dev-Activity-Page(快速开发活动页...). 活动页这类比较简单的 ...
- tomcat的OutOfMemoryError(PermGen space)解决方法
修改TOMCAT_HOME/bin/catalina.bat,在“echo "Using CATALINA_BASE: $CATALINA_BASE"”上面加入以下行: set J ...
- 《HTML5与CSS3基础教程》学习笔记 ——One Day
第一章 1. 邮箱地址的URL地址包括:mailto:+邮箱地址 2. ../表示向上走一级,开头直接使用/表示根目录 第三章 1. <header>: role = “ ...
- 《锋利的jQuery》心得笔记--Three Sections
第六章 1. JavaScript的Ajax的实现步骤: 1) 定义一个函数用来异步获取信息 function Ajax(){ } 2) 声明: var xmlH ...
- Vim 保存和退出命令
命令 简单说明 :w 保存编辑后的文件内容,但不退出vim编辑器.这个命令的作用是把内存缓冲区中的数据写到启动vim时指定的文件中. :w! 强制写文件,即强制覆盖原有文件.如果原有文件的访问权限不允 ...