【NLP】Python NLTK 走进大秦帝国
Python NLTK 走进大秦帝国
作者:白宁超
2016年10月17日18:54:10
摘要:NLTK是由宾夕法尼亚大学计算机和信息科学使用python语言实现的一种自然语言工具包,其收集的大量公开数据集、模型上提供了全面、易用的接口,涵盖了分词、词性标注(Part-Of-Speech tag, POS-tag)、命名实体识别(Named Entity Recognition, NER)、句法分析(Syntactic Parse)等各项 NLP 领域的功能。本文主要介绍NLTK(Natural language Toolkit)的安装和基本方法使用,以大秦帝国部分章节为语料,文本当做词链表进行操作处理,采用统计的方式深入研究作者用词的讲究;然后在使用NLTK内置方法进行统计操作。最后将部分常用功能进行总结整理。本文是系列首篇,主要介绍入门知识,关于python基础知识,可以参看【Python五篇慢慢弹】系列文章(本文原创编著,转载注明出处: Python NLTK 走进大秦帝国
目录
【Python NLP】干货!详述Python NLTK下如何使用stanford NLP工具包(1)
【Python NLP】Python 自然语言处理工具小结(2)
【Python NLP】Python NLTK 走进大秦帝国(3)
【Python NLP】Python NLTK获取文本语料和词汇资源(4)
【Python NLP】Python NLTK处理原始文本(5)
1 NLTK简介
NLTK(Natural language Toolkit):自然语言工具包,Python编程语言实现的统计自然语言处理(NLP)工具。它是由宾夕法尼亚大学计算机和信息科学的史蒂芬-伯德和爱德华·洛珀编写的。 NLTK支持NLP研究和教学相关的领域,包括经验语言学,认知科学,人工智能,信息检索和机器学习。 在25个国家中已有 32所大学将NLTK作为教学工具。
NLTK模块及功能介绍:

1 NLTK安装
1 查看python版本
2 windows系统下载NLTK如下文件nltk-3.2.1.win32.exe,并执行exe文件,会自动匹配到python安装路径,如果没有找到路径说明nltk版本不正确,去官网选择正确版本号下载。
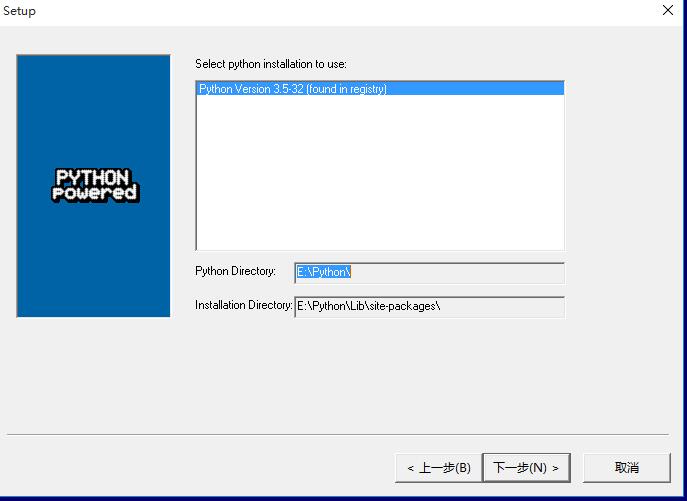
3 安装成功后,打开python编辑器,输入import nltk和nltk.download()下载NLTK_DATA,具体看下图,选中book,修改下载路径E:\Python\nltk_data,点击下载。(book包含了数据案例和内置函数)
>>> import nltk
>>> nltk.download()
4 在计算机-属性-高级系统设置-高级-环境变量-系统变量-path:E:\Python\nltk_data
5.打开python解释器,输入form nltk.book import *,如下图表示安装成功。

6 接下来在64位win10下安装pip,numpy,scipy,下载并解压pip-8.1.2.tar.gz,win+R环境进入解压路径,安装setup.py文件,完成pip工具安装,然后配置下环境变量,yourpath\Python\Scripts
NLTK核心包:(包下载)
- NLTK-Data:分析和处理语言的语料库
- NumPy:科学计算库
- Matplotlib:数据可视化2D绘图库
- NetworkX:存储和操作有节点和边组成的网络结构函数库
7 通过pip工具安装numpy包,下载numpy-1.11.2+mkl-cp35-cp35m-win32.whl 进入下载路径下,输入如下指令安装。

8 通过pip工具安装Matplotlib包,下载matplotlib-1.5.3-cp35-cp35m-win32.whl进入下载路径下,输入如下指令安装。
9 通过pip工具安装scipy包,下载scipy-0.18.1-cp35-cp35m-win32.whl进入下载路径下,输入如下指令安装。

至此,完成所有操作,根据项目需要可以下载相应的包,点击这里基本包都有了。

3 NLTK基本操作
NLTK的book模块加载所有文档
>>> import nltk
>>> from nltk.corpus import *
>>> text1
<Text: Moby Dick by Herman Melville 1851>
函数concordance搜索指定内容

函数similar查找相似上下文

函数common_contexts共用多个词汇的上下文

函数dispersion_plot离散图表示词汇分布情况
判断词在文本中的位置,从开头算起有多少词出现,可以离散图表示,每一列代表一个单词,每一行代表有个文本
>>> text4.dispersion_plot(["citizens","democracy","freedom","duties","America"])

函数len()计数词汇
>>> len(text3)
44764
词汇表排序
>>> sorted(set(text3))

词汇表大小
>>> len(set(text3))
2789
每个词平均使用次数
>>> len(text3)/len(set(text3))
16.050197203298673
特定词在文本中出现的次数
>>> text3.count("smote")
5
特定词在文本中所占的百分比
>>> 100*text4.count('a')/len(text4)
1.4643016433938312
函数计算百分比
>>> def lexical_diversity(text):
return len(text)/len(set(text)) >>> lexical_diversity(text4)
14.941049825712529
>>> lexical_diversity(text3)
16.050197203298673 >>> def percentage(count,total):
return 100 * count / total
>>> percentage(text4.count("a"),len(text4))
1.4643016433938312
索引列表

NLTK搜索函数FreqDist()
查询文本text1中词汇分布情况,诸如the使用了13721次
>>> fdist1=FreqDist(text1)
>>> fdist1
FreqDist({',': 18713, 'the': 13721, '.': 6862, 'of': 6536, 'and': 6024, 'a': 4569, 'to': 4542, ';': 4072, 'in': 3916, 'that': 2982, ...})
指定查询某个词的使用频率
>>> fdist1['whale']
906
指定常用词累积频率图
fdist1.plot(50,cumulative=True),text1中50个常用词的累积频率图,这些词占了所有标识的将近一半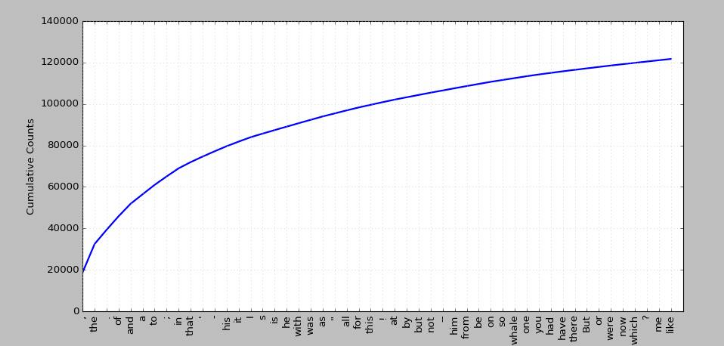
函数fdist1.hapaxes()低频词出现1次查找
细粒度查询
>>> V=set(text1)
>>> longwords=[w for w in V if len(w) > 15]
>>> sorted(longwords)

查询文本中单词长度大于7并且出现次数超过7次的
>>> sorted(w for w in set(text1) if len(w) > 7 and fdist1[w] > 7)

词语搭配个双连词
搭配:不经常在一起出现的词序列,如red wine是搭配而the wine就不是。另一个特点就是词不能被类似的词置换,如maroon wine(栗色酒)就不行
bigrams():获取搭配,提前文本词汇的双连词
>>> from nltk import bigrams
>>> from collections import Counter
>>> b = bigrams('This is a test')
>>> Counter(b)
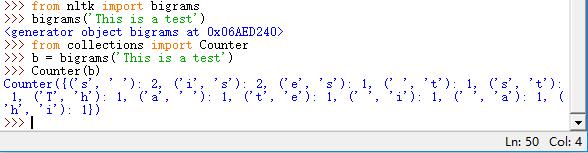
双连词的搭配
>>> text4.collocations()
计算词长分布
>>> fdist=FreqDist([len(w) for w in text8])
>>> fdist
>>> fdist.keys()
词长频率统计
>>> fdist.items()
词数最多的长度
>>> fdist.max()
查找词长为3的百分比
>>> fdist.freq(3)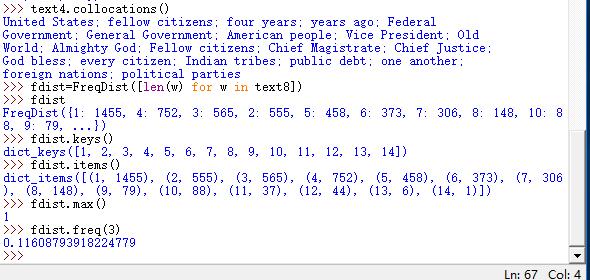
NLTK频率分布类中定义的函数
- fdist=FreqDist(Samples) 创建包含给定样本的频率分布
- fdist.inc(Sample) 增加样本
- fdist['monstrous'] 计数给定样本出现的次数
- fdist.freq('monstrous') 给定样本的频率
- fdist.N() 样本总数
- fdist.keys() 以频率递减顺序排序样本链表
- for sample in fdist: 以频率递减顺序遍历样本
- fdist.max() 数值最大的样本
- fdist.tabulate() 绘制频率分布表
- fdist.plot() 绘制频率分布图
- fdist.plot(cumulative=True)绘制累积频率分布图
- fdist1<fdist2 测试样本在fdist1中出现的频率是否小于fdist2
回到python:决策与控制
控制:按照我们意愿去处理关键特征
>>> sent7=['married','have','long','Seeking','country','nights','at','well','walks','home','would']
>>> [w for w in sent7 if len(w)<4]
['at']
>>> [w for w in sent7 if len(w)<=4]
['have', 'long', 'at', 'well', 'home']
>>> [w for w in sent7 if len(w)==4]
['have', 'long', 'well', 'home']
>>> [w for w in sent7 if len(w)!=4]
['married', 'Seeking', 'country', 'nights', 'at', 'walks', 'would']
共同的模式是:[w for w in text if condition],其中condition是一个python的测试
词汇比较运算
- s.startswith(t) 测试是否t开头
- s.endswith(t) 测试是否t结尾
- t in s 测试s是否包含t
- s.islower() 测试s所有字符是否都是小写字母
- s.isupper() 测试s所有字符是否都是大写字母
- s.isalpha() 测试s所有字符是否都是字母
- s.isalnum() 测试s所有字符是否都是字母或数字
- s.isdigit() 测试s所有字符是否都是数字
- s.istitle() 测试s所有词首字母都是大写
条件:
sorted([w for w in set(text1) if w.endswith('ableness')])
sorted([term for term in set(text4) if 'gnt' in term])
sorted([item for item in set(text6) if item.istitle()])
sorted([item for item in set(text7) if item.isdigit()])
>>> sorted([w for w in set(text7) if '-' and 'index' in w ])
['Stock-index', 'index', 'index-arbitrage', 'index-fund', 'index-options', 'index-related', 'indexers', 'indexes', 'stock-index']
>>> sorted([w for w in set(text3) if w.istitle() and len(w)>11 ])
['Allonbachuth', 'Beerlahairoi', 'Chedorlaomer', 'Hazezontamar', 'Jegarsahadutha', 'Jehovahjireh', 'Peradventure', 'Zaphnathpaaneah']
>>> sorted([w for w in set(text7) if not w.islower()])
>>> sorted([w for w in set(text7) if w.islower()])
>>> sorted([w for w in set(text7) if 'cie' in w or 'cei' in w])
4 NLTK统计大秦帝国第一部词链表
下载孙皓晖先生的《大秦帝国.zip》文件,里面按照语料大小包含5个文件,分别是30852词的p1.txt、70046词的p2.txt、111970词的p3.txt、1182769词的p5.txt、419275词的p10.txt.本事了节选大秦帝国第一部字的dqdg.txt
打开Python编辑器,导出NLTK,并统计大秦帝国第一部共计多少字。(注:在读取文本的时候,python 3.5 IDLE 执行起来比较卡比较慢,采用pycharm就效率高很多了)
>>> with open(r"C:\Users\cuitbnc\Desktop\dqdg.txt","r+") as f:
str=f.read()

查看大秦帝国第一部总共有多大的用字量,即不重复词和符合的尺寸:
>>> len(set(str))
4053 >>> len(str)/len(set(str))
166.09104367135456
实验可知用了4053个尺寸的词汇表,平均每个词使用了166次,那么常用词分布如何呢?既然是大秦帝国,那么秦字使用了多少次呢?
>>> str.count("秦")
3538
>>> str.count("大秦")
14
>>> str.count("国")
6536
可以知道,秦用词3538次,大秦用了14次,因为讲的各国之间的事情,国也是高频词6536次。如上所述大秦帝国第一部总词汇表673167,整个词汇累积分布如何?
>>> fdist=FreqDist(str)
>>> fdist.plot()
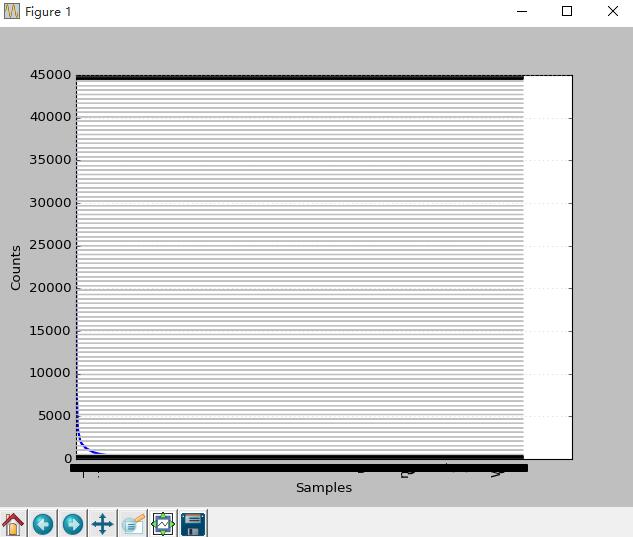
这个图横坐标表示词的序列,纵坐标表示词频。表说明词频大于5000的非常少,说明高频词不多。低频词特别多。后面进一步探究下.
看看整本书的累积分布情况如何?
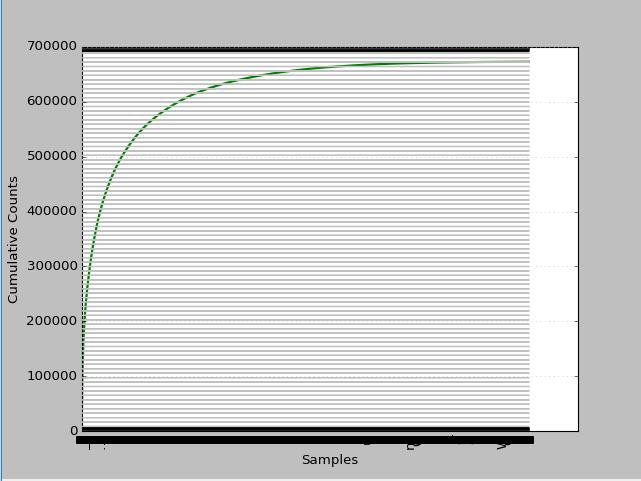
分析上图我们不难发现,3万以下是低频词大于30%,高频词大于1.4%,中频占68.6%(偏低中频2万左右占29.85%,偏高中频占8.96%)
研究下高频率的1000个词情况?看看都有哪些?
>>> sorted(set(str[:1000]))

查看1000个高频词分布如何?
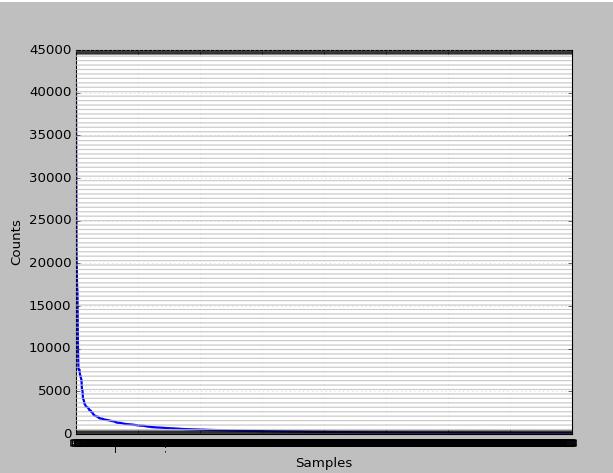
1000个高频的累计分布又如何?
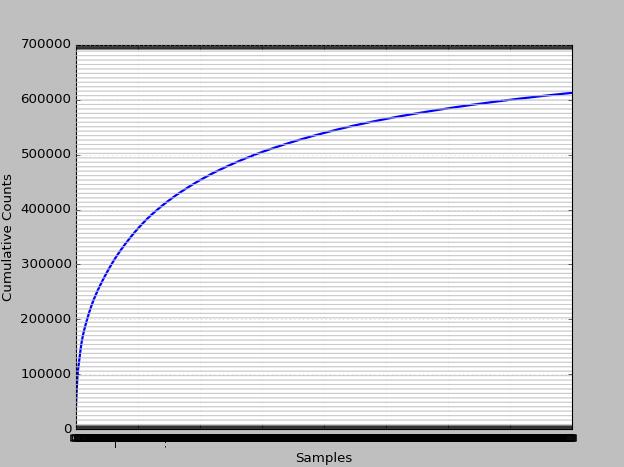
初略估计下大于占了80%以上。频率最高的前100词的分布如何?

前100个词也就是大约0.02%的词在本书的累积分布情况怎样呢?
>>> fdist=FreqDist(str)
>>> fdist.plot(100,cumulative=True)
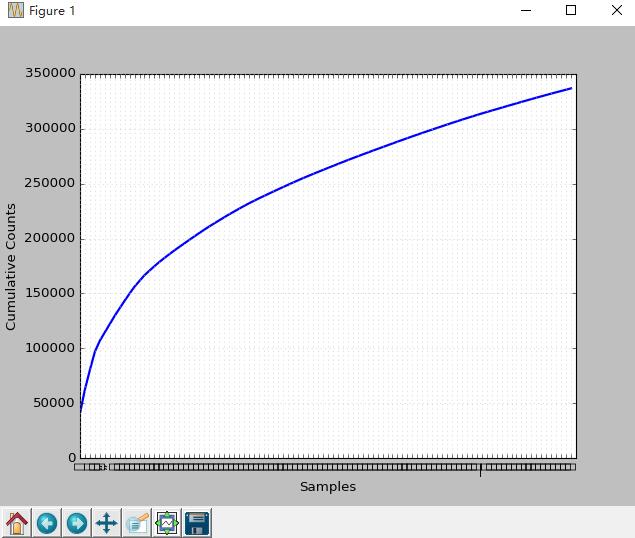
如图可知,前0.2%词汇占据整本书的50%以上的比例。国、旗、秦、魏、队、阅等跟战争相关词汇使用较多。那么低频词如何呢?有时候低频词也具有其特殊的研究价值。
>>> FreqDist(str).hapaxes()

统计可知大约有4053个词出现一次,占比0.6%
词语内部搭配又是如何?
>>> from collections import Counter
>>> V=Counter(str)
大秦帝国第一部用词统计

查看词汇
>>> sorted(V.keys())

查看词汇频率排名
>>> sorted(V.values())

查询词频在[0--100]的词有多少?
>>> len([w for w in V.values() if w<100])
3103
查询词频在[100--1000]的词有多少?
>>> len([w for w in V.values() if w>100 and w<1000])
819
查询词频在[1000-5000]的词有多少?
>>> len([w for w in V.values() if w>1000 and w<5000])
113
查询词频在[5000--]的词有多少?
>>> len([w for w in V.values() if w>5000])
14
双连词:
import nltk
from nltk.book import *
from nltk import bigrams
from collections import Counter
with open(r"C:\Users\cuitbnc\Desktop\dqdg.txt","r") as f:
str=f.read()
V=bigrams(str)
W=Counter(V)
print(W)
结果
5 自动理解自然语言
词意消歧
看下面歧义的句子:词意消歧就是分析出特定上下文的词被赋予的哪个意思。
- 1.川大学生上网成瘾如患绝症。歧义在于“川大学生”(1)四川大学的学生(2)四川的大学生
- 2.两代教授,人格不同。歧义:“两代”(1)两位代理教授(2)两个时代的教授
- 3.被控私分国有资产,专家总经理成了被告人。歧义:“专家总经理”(1)专家和总经理(2)有专家身份的总经理
- 4.新生市场苦熬淡季。歧义:“新生”(1)新学生的市场(2)新产生的市场
- 5.朝鲜十年走近国际社会一步。歧义:“十年走近国际社会一步”(1)每十年就向国际社会走近一步(2)最近十年间向国际社会走近了一步
- 6.新汽车牌照。歧义:“新”(1)新的汽车(2)新的牌照
- 7.咬死了猎人的狗。歧义:(1)猎人的狗被咬死了(2)把猎人咬死了的那条狗
- 8.菜不热了。歧义:“热”(1)指菜凉了(2)指菜不加热了
- 9.还欠款四万元。歧义:“还”(1)读huai(2)读hai
- 10.北京人多。歧义:(1)北京/人多(2)北京人/多
指代消解
指代消解是解决“谁对谁做了 什么”,处理如上所述自然语言的问题,下面看看例子
- (1)美国政府表示仍然支持强势美元,但这到底只是嘴上说说还是要采取果断措施,经济学家对此的看法是否定的。
- (2)今天老师又在班会上表扬了自己,但是我觉得还需要继续努力。
- (3)三妹拉着葛姐的手说,她老家在偏远的山区,因为和家里赌气才跑到北京打工的,接着她又哭泣起自己的遭遇来。
- (4)当他把证书发给小钱时,他对他笑了。
- (5)小明和肖华去公园玩,他摔了一跤,他急忙把他扶起来.
- (6)星期天,小雨和小英到田老师家补习功课,她一早就打电话给她约好在红旗饭店吃早餐.
未完待续...
【NLP】Python NLTK 走进大秦帝国的更多相关文章
- 【NLP】干货!Python NLTK结合stanford NLP工具包进行文本处理
干货!详述Python NLTK下如何使用stanford NLP工具包 作者:白宁超 2016年11月6日19:28:43 摘要:NLTK是由宾夕法尼亚大学计算机和信息科学使用python语言实现的 ...
- 【NLP】Python NLTK处理原始文本
Python NLTK 处理原始文本 作者:白宁超 2016年11月8日22:45:44 摘要:NLTK是由宾夕法尼亚大学计算机和信息科学使用python语言实现的一种自然语言工具包,其收集的大量公开 ...
- 【NLP】Python NLTK获取文本语料和词汇资源
Python NLTK 获取文本语料和词汇资源 作者:白宁超 2016年11月7日13:15:24 摘要:NLTK是由宾夕法尼亚大学计算机和信息科学使用python语言实现的一种自然语言工具包,其收集 ...
- [转]【NLP】干货!Python NLTK结合stanford NLP工具包进行文本处理 阅读目录
[NLP]干货!Python NLTK结合stanford NLP工具包进行文本处理 原贴: https://www.cnblogs.com/baiboy/p/nltk1.html 阅读目录 目 ...
- Python NLTK 自然语言处理入门与例程(转)
转 https://blog.csdn.net/hzp666/article/details/79373720 Python NLTK 自然语言处理入门与例程 在这篇文章中,我们将基于 Pyt ...
- Python写各大聊天系统的屏蔽脏话功能原理
Python写各大聊天系统的屏蔽脏话功能原理 突然想到一个视频里面弹幕被和谐的一满屏的*号觉得很有趣,然后就想用python来试试写写看,结果还真玩出了点效果,思路是首先你得有一个脏话存放的仓库好到时 ...
- Python逐块读取大文件行数的代码 - 为程序员服务
Python逐块读取大文件行数的代码 - 为程序员服务 python数文件行数最简单的方法是使用enumerate方法,但是如果文件很大的话,这个方法就有点慢了,我们可以逐块的读取文件的内容,然后按块 ...
- Python+NLTK自然语言处理学习(一):环境搭建
Python+NLTK自然语言处理学习(一):环境搭建 参考黄聪的博客地址:http://www.cnblogs.com/huangcong/archive/2011/08/29/2157437.ht ...
- 零起点PYTHON足彩大数据与机器学习实盘分析
零起点PYTHON足彩大数据与机器学习实盘分析 第1章 足彩与数据分析 1 1.1 “阿尔法狗”与足彩 1 1.2 案例1-1:可怕的英国足球 3 1.3 关于足彩的几个误区 7 1.4 足彩·大事件 ...
随机推荐
- C语言 · 矩阵乘法 · 算法训练
问题描述 输入两个矩阵,分别是m*s,s*n大小.输出两个矩阵相乘的结果. 输入格式 第一行,空格隔开的三个正整数m,s,n(均不超过200). 接下来m行,每行s个空格隔开的整数,表示矩阵A(i,j ...
- 再谈CAAnimation动画
CAAnimaton动画分为CABasicAnimation & CAKeyframeAnimation CABasicAnimation动画, 顾名思义就是最基本的动画, 老规矩先上代码: ...
- Android Button的基本使用
title: Android Button的基本使用 tags: Button,按钮 --- Button介绍: Button(按钮)继承自TextView,在Android开发中,Button是常用 ...
- UWP开发之Mvvmlight实践八:为什么事件注销处理要写在OnNavigatingFrom中
前一段开发UWP应用的时候因为系统返回按钮事件(SystemNavigationManager.GetForCurrentView().BackRequested)浪费了不少时间.现象就是在手机版的详 ...
- C#中5步完成word文档打印的方法
在日常工作中,我们可能常常需要打印各种文件资料,比如word文档.对于编程员,应用程序中文档的打印是一项非常重要的功能,也一直是一个非常复杂的工作.特别是提到Web打印,这的确会很棘手.一般如果要想选 ...
- 解决“chrome提示adobe flash player 已经过期”的小问题
这个小问题也确实困扰我许久,后来看到chrome吧里面有人给出了解决方案: 安装install_flash_player_ppapi, 该软件下载地址:http://labs.adobe.com/do ...
- eclipse如何添加Memory Analyzer
①启动Eclipse,并打开"Install New software..."对话框: ②点击Add,如图: ③点击OK,最后一直点next,完成
- PHP 设计模式概述
一.设计模式(Design pattern)是什么? 设计模式是一套被反复使用.多数人知晓的.经过分类编目的.代码设计经验的总结.使用设计模式是为了可重用代码.让代码更容易被他人理解.保证代码可靠性. ...
- MySQL常见面试题
1. 主键 超键 候选键 外键 主 键: 数据库表中对储存数据对象予以唯一和完整标识的数据列或属性的组合.一个数据列只能有一个主键,且主键的取值不能缺失,即不能为空值(Null). 超 键: 在关系中 ...
- Linux命令【第一篇】
1.创建一个目录/data 记忆方法:英文make directorys缩写后就是mkdir. 命令: mkdir /data 或 cd /;mkdir data #提示:使用分号可以在一行内分割两个 ...