ElasticSearch 2 (7) - 基本概念
ElasticSearch 2 (7) - 基本概念
摘要
ElasticSearch的一些基本核心概念,理解这些概念有助于ElasticSearch的学习
- 准实时NRT(Near Realtime)
- 集群
- 节点
- 索引
- 类型
- 文档
- 分片与副本(Shards & Replicas)
版本
elasticsearch版本: elasticsearch-2.2.0
概念
准实时NRT(Near Realtime)
ElasticSearch是一个准实时的搜索平台。准实时的意思是说它的延迟非常小,从为一个文档建索引到这个文档可以搜索出来,只需要1秒的时间。
集群(Cluster)
一个ES集群可以由一个或者多个节点(nodes or servers)组成。所有这些节点用来存储所有的数据以及提供联合索引,为我们提供跨节点查询的能力。一个ES集群的名称是唯一的,默认情况下为“elasticsearch”。这个名称非常重要,因为一个节点(node)会通过这个名称来判断是否加入已有的集群。
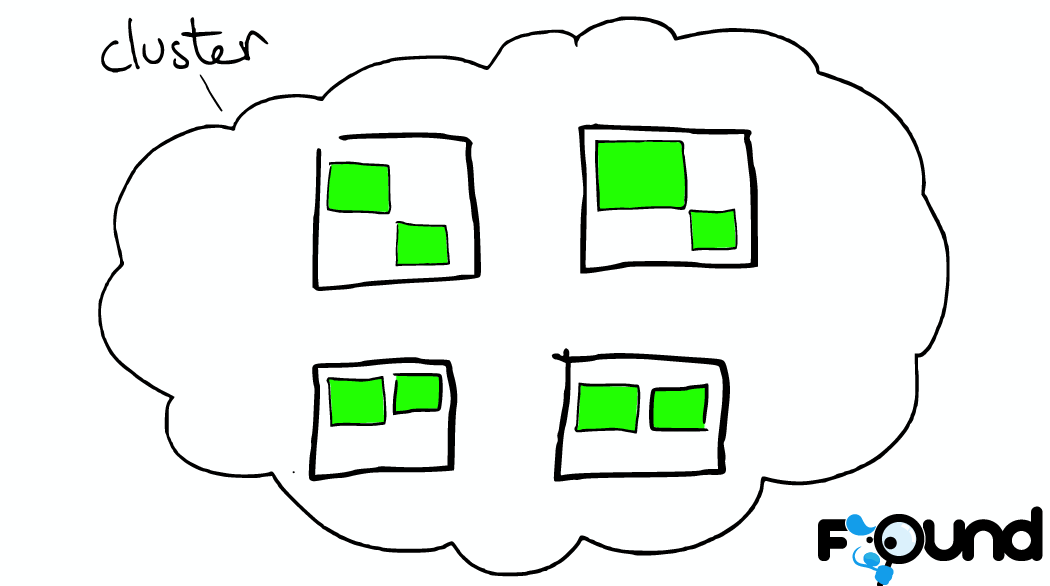
必须保证在不同环境下使用不同的集群名称,否则节点可能会加入错误的集群。比如我们可以为开发环境(development)、测试环境(staging)、产品环境(production)分别给出不同的集群名称:logging-dev、logging-staging、logging-prod。
需要注意的是我们也可以使用一个只有一个节点的集群,或者我们也可以有不同的集群,每个集群都有自己唯一的名称。
节点(Node)
一个节点是一个集群中的一台服务器,它用来存储数据,参与集群的索引以及提供搜索能力。如ES集群,一个节点也是由它的唯一名称来标识,默认状态下,ES会为在启动时随机为一个节点给定一个以漫威Marvel人物的名字为之命名,当然我们也可以为节点指定任何我们想指定的名称。这个名称对于管理ES集群非常重要,我们用它来定位网络或集群中的某一节点。
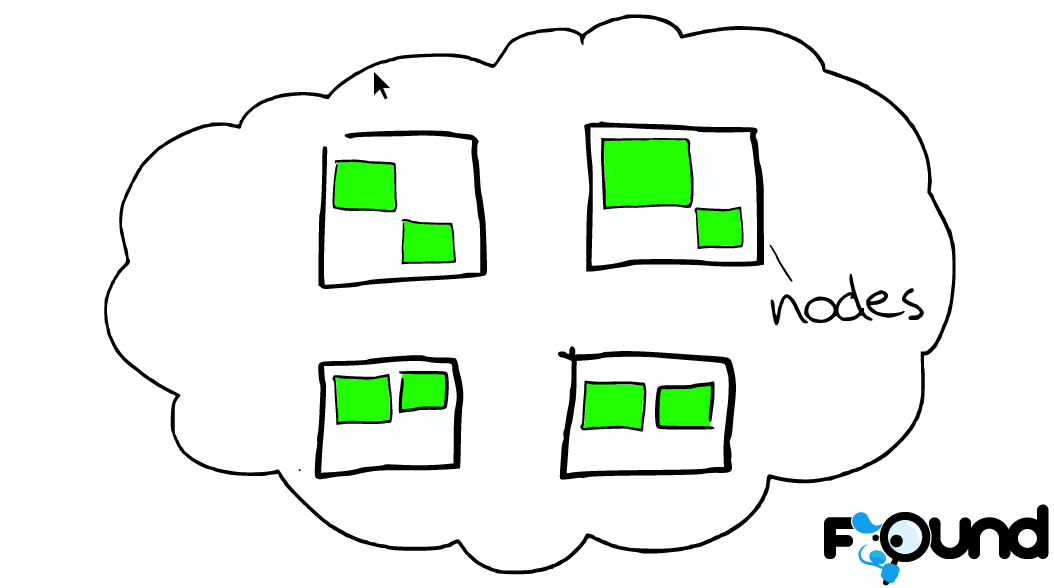
一个节点可以通过指定集群名称让它加入某个集群,默认情况下,每个节点都会加入到一个名为“elasticsearch”的集群中,也就是说,当我们在某一网络下启动一定数量的ES节点时,我们认为他们可以相互发现同一网络下的其他节点。
在单集群下,我们可以有任意数量的节点,如果当前网络下没有任何ES节点,那么在启动节点后,当前节点会默认形成一个单节点集群,名称为“elasticsearch”。
索引(Index)
一个索引是一组具有相似特性的文档的集合。例如,可以为客户数据(customer data)建立索引一个索引,也可以为产品目录(product catalog)建立另一个索引,还可以为订单数据(order data)建立另一个索引。一个索引由它的名称唯一标识(必须所有字母为小写字母),这个名称会在进行索引(indexing)、搜索(search)、修改(update)和删除(delete)操作的时候使用。
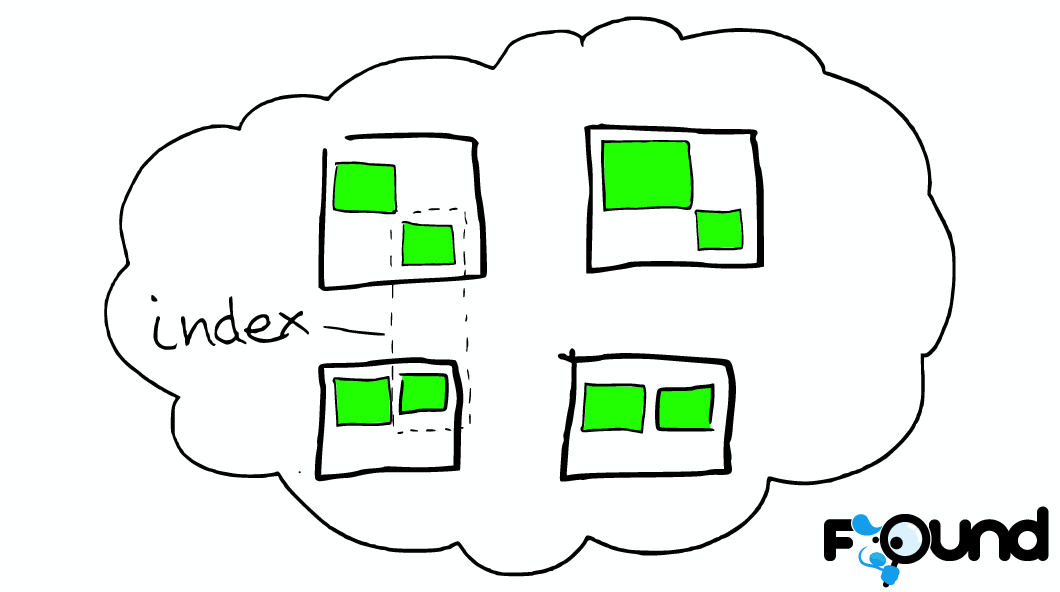
在一个单集群下,我们可以定义任意多的索引。
类型(Type)
在一个索引下,我们可以定义一个或多个类型(types)。一个类型是一个索引逻辑分类或分区(category/partition),而分类或分区的划分方法由我们自己决定。通常情况下,我们会为具有相类似的字段的一组文档定义类型。比如,如果我们运行一个博客平台,所有的数据都使用同一索引,我们为用户数据定义一种类型,为博客数据定义另一种类型,同时为评论数据定义另一种类型。
文档(Document)
一个文档是一个可以被索引的基本信息单元。比如,一个用户可以是一个文档,一个产品可以是一个文档,一个订单同样也可以成为一个文档。这个文档以JSON格式表示。
分片与副本(Shards & Replicas)
一个索引可能会存储大量数据从而超过单个节点硬件的限制。例如,单个索引可能会有上亿的文档占用1TB的磁盘空间,这对于单个节点来说太大,同时使用单个节点也会是搜索变慢。
为了解决这个问题,ES提供了一种分片(shard)能力,让我们将一个索引切分成片。当我们创建一个索引时,我们可以为它指定分片的数量。每个分片自己都能独立工作,并且存在与集群的任一节点中。
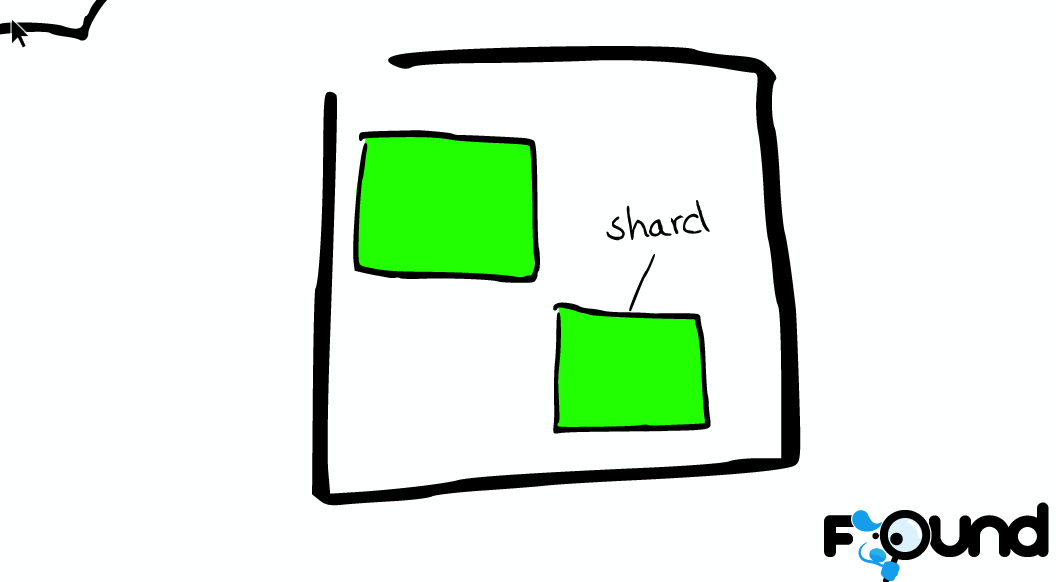
分片的重要性主要体现在以下两个原因:
- 可以水平分割或扩展内容体量。
- 可以分布式和并行的方式在多个分片上进行操作(多个节点)从而提高性能和吞吐量。
一个分片是如何散发的,如何将它的文档聚合并返回个查询是对用户透明的,这个过程完全由ES来管理。
在网络或云的环境下,错误可以在任何时候发生,当一个分片或节点因为某种原因下线或消失时,一个错误恢复机制就非常重要。为了解决这个问题,ES让我们可以为一个索引分片创建一个或多个拷贝,这个拷贝称作副本分片,简称为副本。
副本的重要性主要体现在以下两个原因:
- 当一个分片或者节点出错时,集群任然可用。正因如此,我们会发现一个分片副本从来不会在它的原始分片或主分片所在的节点出现。
- 横向扩展搜索体量和吞吐量,因为搜索可以在所有副本上并行执行。
总之,每个索引都可以分为多个分片,一个索引也可以被复制到零个或多个副本。一旦发生复制,每个索引都会有主分片(primary shards)和多个副本分片(replica shards)。分片数和副本数可以在一个索引创建时指定。当索引创建以后,可以动态的改变副本数,但是不能改变分片数。
默认情况下,每个ES索引都有5个主分片(primary shards)和1个副本(replica),也就是说当我们的集群有两个节点时,我们的索引会有5个主分片和另外5个副本分片,也就是说每个索引有总共10个分片。

注意
每个ES分片都是一个Lucene索引。对于单个Lucene索引,文档的最大数有一个限制,2,147,483,519。即(= Integer.MAX_VALUE - 128)。可以通过
_cat/shards
来查看。

Each Elasticsearch shard is a Lucene index. There is a maximum number of documents you can have in a single Lucene index. As of LUCENE-5843, the limit is 2,147,483,519 (= Integer.MAX_VALUE - 128) documents. You can monitor shard sizes using the _cat/shards api.
参考
参考来源:
https://www.elastic.co/guide/en/elasticsearch/reference/current/_basic_concepts.html
图片来源:
https://www.youtube.com/watch?v=LDyxijDEqj4
结束
ElasticSearch 2 (7) - 基本概念的更多相关文章
- 【分布式搜索引擎】Elasticsearch中的基本概念
一.Elasticsearch中的基本概念 以下概念基于这个例子:存储员工数据,每个文档代表一个员工 1)索引(index) 在Elasticsearch中存储数据的行为就叫做索引(indexing ...
- 第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念
第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念 elasticsearch的基本概念 1.集群:一个或者多个节点组织在一起 2.节点 ...
- 三十九 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念
elasticsearch的基本概念 1.集群:一个或者多个节点组织在一起 2.节点:一个节点是集群中的一个服务器,由一个名字来标识,默认是一个随机的漫微角色的名字 3.分片:将索引(相当于数据库)划 ...
- Elasticsearch之重要核心概念(cluster(集群)、shards(分配)、replicas(索引副本)、recovery(据恢复或叫数据重新分布)、gateway(es索引的持久化存储方式)、discovery.zen(es的自动发现节点机制机制)、Transport(内部节点或集群与客户端的交互方式)、settings(修改索引库默认配置)和mappings)
Elasticsearch之重要核心概念如下: 1.cluster 代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的.es的一个概念就是 ...
- Elasticsearch核心技术(2)--- 基本概念(Index、Type、Document、集群、节点、分片及副本、倒排索引)
Elasticsearch核心技术(2)--- 基本概念 这篇博客讲到基本概念包括: Index.Type.Document.集群,节点,分片及副本,倒排索引. 一.Index.Type.Docume ...
- 002 elasticsearch中的一些概念
在本文中,主要是ES7中的核心概念. ElasticSearch是一个实时分布式开源全文搜索和分析引擎.它可以从RESTful网络服务接口访问,并使用无模式JSON (JavaScript对象符号)文 ...
- Elasticsearch教程之基础概念
基础概念 Elasticsearch有几个核心概念.从一开始理解这些概念会对整个学习过程有莫大的帮助. 1.接近实时(NRT) Elasticsearch是一个接近实时的搜索平台.这意味 ...
- 1.ElasticSearch介绍及基本概念
一.ElasticSearch介绍 一个采用RESTful API标准的高扩展性的和高可用性的实时性分析的全文搜索工具 基于Lucene[开源的搜索引擎框架]构建 ElasticSearch是一个面向 ...
- Elasticsearch介绍,一些概念的笔记
Elasticsearch,分布式,高性能,高可用,可伸缩的搜索和分析系统 什么是搜索? 如果用数据库做搜索会怎么样? 什么是全文检索和Lucene? 什么是Elasticsearch? Elasti ...
随机推荐
- Wannafly挑战赛27
Wannafly挑战赛27 我打的第一场$Wannafly$是第25场,$T2$竟然出了一个几何题?而且还把我好不容易升上绿的$Rating$又降回了蓝名...之后再不敢打$Wannafly$了. 由 ...
- 连接远程数据库ORACLE11g,错误百出!
客户机中PLSQL DEV访问虚拟机中的ORACLE11g,错误百出! 创建时间: 2017/10/14 18:44 作者: CNSIMO 标签: ORACLE 忙了一下午,只有两个字形容:麻烦! ...
- C#控件中的KeyDown、KeyPress 与 KeyUp事件浅谈
研究了一下KeyDown,KeyPress 和 KeyUp 的学问.让我们带着如下问题来说明: 1.这三个事件的顺序是怎么样的? 2.KeyDown 触发后,KeyUp是不是一定触发? 3.三个事件的 ...
- day25
今日内容 1.组合 2.多态与多态性 3.封装 4.property 组合: 什么是组合? 是指某一对象拥有的一个属性,该属性的值是另一个类的对象 为何用组合? 就是通过为某个对象添加一个新的属性(另 ...
- HBase启动报错:ERROR: org.apache.hadoop.hbase.ipc.ServerNotRunningYetException: Server is not running yet
今天进入hbase shell中输入命令报错:ERROR: org.apache.hadoop.hbase.ipc.ServerNotRunningYetException: Server is no ...
- AI Summit(2018.07.19)
AI Summit 时间:2018.07.19地点:北京丽都皇冠假日酒店
- 汇编 if else
知识点: if else 逆向还原代码 一.了解if else结构 sub esp, |. 8B45 FC MOV EAX,DWORD PTR SS:[EBP-] 0040102C |. 3B45 ...
- 外部事件/中断的区别及EXTI->SWIER的用途
EXTI_SWIER作用:允许我们通过程序控制就可以启动中断/事件线 1.产生事件的线路最终的产物是一个脉冲信号,这个脉冲信号可以给其他外设电路使用,比如定时器TIM.模拟数字转换器ADC等等. 2. ...
- C++中前置声明介绍
前置声明是指对类.函数.模板或者结构体进行声明,仅仅是声明,不包含相关具体的定义.在很多场合我们可以用前置声明来代替#include语句. 类的前置声明只是告诉编译器这是一个类型,但无法告知类型的大小 ...
- 【LG4070】[SDOI2016]生成魔咒
[LG4070][SDOI2016]生成魔咒 题面 洛谷 题解 如果我们不用在线输的话,那么答案就是对于所有状态\(i\) \[ \sum (i.len-i.fa.len) \] 现在我们需要在线询问 ...