MapReduce中的partitioner
1.日志源文件:
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
1363157993044 18211575961 94-71-AC-CD-E6-18:CMCC-EASY 120.196.100.99 iface.qiyi.com 视频网站 15 12 1527 2106 200
1363157995074 84138413 5C-0E-8B-8C-E8-20:7DaysInn 120.197.40.4 122.72.52.12 20 16 4116 1432 200
1363157993055 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200
1363157995033 15920133257 5C-0E-8B-C7-BA-20:CMCC 120.197.40.4 sug.so.360.cn 信息安全 20 20 3156 2936 200
1363157983019 13719199419 68-A1-B7-03-07-B1:CMCC-EASY 120.196.100.82 4 0 240 0 200
1363157984041 13660577991 5C-0E-8B-92-5C-20:CMCC-EASY 120.197.40.4 s19.cnzz.com 站点统计 24 9 6960 690 200
1363157973098 15013685858 5C-0E-8B-C7-F7-90:CMCC 120.197.40.4 rank.ie.sogou.com 搜索引擎 28 27 3659 3538 200
1363157986029 15989002119 E8-99-C4-4E-93-E0:CMCC-EASY 120.196.100.99 www.umeng.com 站点统计 3 3 1938 180 200
1363157992093 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 15 9 918 4938 200
1363157986041 13480253104 5C-0E-8B-C7-FC-80:CMCC-EASY 120.197.40.4 3 3 180 180 200
1363157984040 13602846565 5C-0E-8B-8B-B6-00:CMCC 120.197.40.4 2052.flash2-http.qq.com 综合门户 15 12 1938 2910 200
1363157995093 13922314466 00-FD-07-A2-EC-BA:CMCC 120.196.100.82 img.qfc.cn 12 12 3008 3720 200
1363157982040 13502468823 5C-0A-5B-6A-0B-D4:CMCC-EASY 120.196.100.99 y0.ifengimg.com 综合门户 57 102 7335 110349 200
1363157986072 18320173382 84-25-DB-4F-10-1A:CMCC-EASY 120.196.100.99 input.shouji.sogou.com 搜索引擎 21 18 9531 2412 200
1363157990043 13925057413 00-1F-64-E1-E6-9A:CMCC 120.196.100.55 t3.baidu.com 搜索引擎 69 63 11058 48243 200
1363157988072 13760778710 00-FD-07-A4-7B-08:CMCC 120.196.100.82 2 2 120 120 200
1363157985079 13823070001 20-7C-8F-70-68-1F:CMCC 120.196.100.99 6 3 360 180 200
1363157985069 13600217502 00-1F-64-E2-E8-B1:CMCC 120.196.100.55 18 138 1080 186852 200
2.写含有partitioner的MR代码:
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class TrafficApp {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration(), TrafficApp.class.getSimpleName());
job.setJarByClass(TrafficApp.class); FileInputFormat.setInputPaths(job, args[0]); job.setMapperClass(TrafficMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(TrafficWritable.class); //job.setNumReduceTasks(2);//设定Reduce的数量为2 这个针对TrafficPartitioner.class
//job.setPartitionerClass(TrafficPartitioner.class);//设定一个Partitioner的类. //job.setNumReduceTasks(3);//设定Reduce的数量为3 这个针对ProviderPartitioner
//也可以通过参数指定
job.setNumReduceTasks(Integer.parseInt(args[2]));
job.setPartitionerClass(ProviderPartitioner.class); /*
*Partitioner是如何实现不同的Map输出分配到不同的Reduce中?
*在不适用指定的Partitioner时,有 一个默认的Partitioner.
*就是HashPartitioner.
*其只有一行代码,其意思就是过来的key,不管是什么,模numberReduceTasks之后 返回值就是reduce任务的编号.
*numberReduceTasks的默认值是1. 任何一个数模1(取余数)都是0.
*这个地方0就是取编号为0的Reduce.(Reduce从0开始编号.)
*/ job.setReducerClass(TrafficReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(TrafficWritable.class); FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
} public static class TrafficPartitioner extends Partitioner<Text,TrafficWritable>{//k2,v2 @Override
public int getPartition(Text key, TrafficWritable value,int numPartitions) {
long phoneNumber = Long.parseLong(key.toString());
return (int)(phoneNumber%numPartitions);
} } //根据号码所属的运营商进行分区,号码的前三位(也可以根据号码所在的行政区域进行分区,号码的前七位)
public static class ProviderPartitioner extends Partitioner<Text,TrafficWritable>{//k2,v2
//初始化映射关系
/*
* 这两个静态的static的执行的先后顺序是 从上往下,先执行providerMap 再 执行static静态块.
*/
private static Map<String,Integer> providerMap = new HashMap<String,Integer>();
static{
providerMap.put("135", 1);//1是移动,2是联通,3是电信
providerMap.put("136", 1);
providerMap.put("137", 1);
providerMap.put("138", 1);
providerMap.put("139", 1);
providerMap.put("134", 2);
providerMap.put("150", 2);
providerMap.put("159", 2);
providerMap.put("183", 3);
providerMap.put("182", 3);
}
@Override
public int getPartition(Text key, TrafficWritable value,int numPartitions) {
//
String account = key.toString();
//
String sub_account = account.substring(0,3);//从第0位开始取,取三位...这个东西不需要记,忘了就自己写个代码试一下.
//
Integer code = providerMap.get(sub_account);
if(code == null){
code = 0;//代表是其他的运行商.
}
return code;
}
} /**
* 第一个参数是LongWritable类型是文本一行数据开头的字节数
* 第二个参数是文本中的一行数据 Text类型
* 第三个参数是要输出的手机号 Text类型
* 第四个参数是需要我们自定义的流量类型TrafficWritable
* @author ABC
*
*/
public static class TrafficMapper extends Mapper<LongWritable, Text, Text, TrafficWritable>{
Text k2 = new Text();
TrafficWritable v2 = null;
@Override
protected void map(LongWritable key,Text value, Mapper<LongWritable, Text, Text, TrafficWritable>.Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] splited = line.split("\t"); k2.set(splited[1]);//这个值对应的是手机号码
v2 = new TrafficWritable(splited[6], splited[7], splited[8], splited[9]);
context.write(k2, v2);
} } public static class TrafficReducer extends Reducer <Text, TrafficWritable, Text, TrafficWritable>{
@Override
protected void reduce(Text k2,Iterable<TrafficWritable> v2s,
Reducer<Text, TrafficWritable, Text, TrafficWritable>.Context context)
throws IOException, InterruptedException {
//遍历v2s 流量都这个集合里面
long t1 = 0L;
long t2 = 0L;
long t3 = 0L;
long t4 = 0L; for (TrafficWritable v2 : v2s) {
t1 += v2.getT1();
t2 += v2.getT2();
t3 += v2.getT3();
t4 += v2.getT4();
}
TrafficWritable v3 = new TrafficWritable(t1, t2, t3, t4);
context.write(k2, v3);
}
} public static class TrafficWritable implements Writable{
private long t1;
private long t2;
private long t3;
private long t4;
//写两个构造方法,一个是有参数的构造方法,一个是无参数的构造方法.
//必须要有 一个无参数的构造方法,否则程序运行会报错. public TrafficWritable(){
super();
} public TrafficWritable(long t1, long t2, long t3, long t4) {
super();
this.t1 = t1;
this.t2 = t2;
this.t3 = t3;
this.t4 = t4;
}
//在程序中读取文本穿过来的都是字符串,所以再搞一个字符串类型的构造方法
public TrafficWritable(String t1, String t2, String t3, String t4) {
super();
this.t1 = Long.parseLong(t1);
this.t2 = Long.parseLong(t2);
this.t3 = Long.parseLong(t3);
this.t4 = Long.parseLong(t4);
} public void write(DataOutput out) throws IOException {
//对各个成员变量进行序列化
out.writeLong(t1);
out.writeLong(t2);
out.writeLong(t3);
out.writeLong(t4);
} public void readFields(DataInput in) throws IOException {
//对成员变量进行反序列化
this.t1 = in.readLong();
this.t2 = in.readLong();
this.t3 = in.readLong();
this.t4 = in.readLong();
} public long getT1() {
return t1;
} public void setT1(long t1) {
this.t1 = t1;
} public long getT2() {
return t2;
} public void setT2(long t2) {
this.t2 = t2;
} public long getT3() {
return t3;
} public void setT3(long t3) {
this.t3 = t3;
} public long getT4() {
return t4;
} public void setT4(long t4) {
this.t4 = t4;
} @Override
public String toString() {
return t1 + "\t" + t2 + "\t" + t3 + "\t" + t4 ;
} }
}
3.命令执行:
hadoop jar /root/itcastmr.jar mapreduce.TrafficApp /files/traffic /traffic_provider3 4
产生的结果文件:
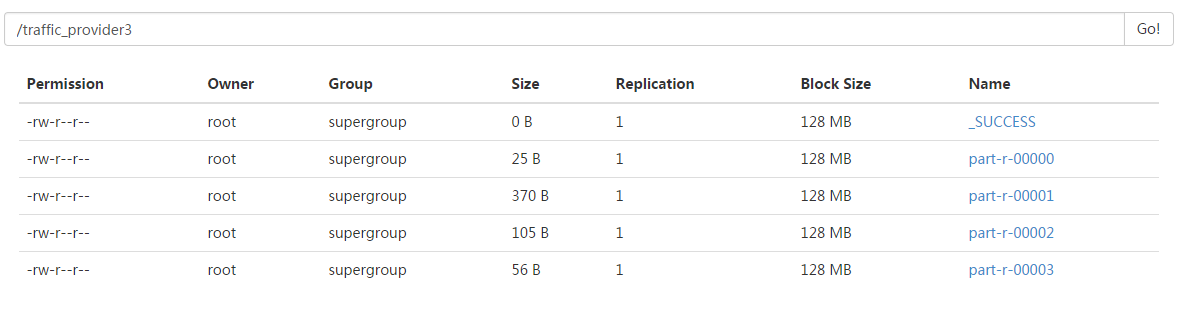
代码中的逻辑是对应4个分区,设置了4个分区,就产生了4个分区文件...
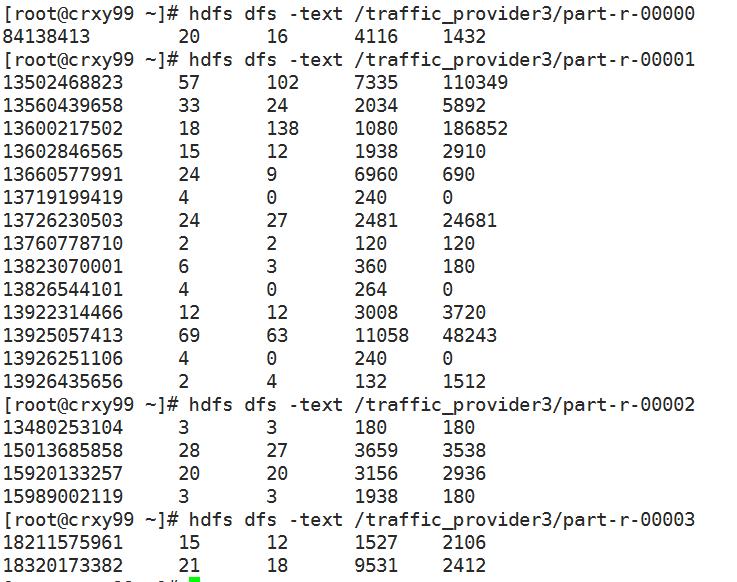
查看各个文件中的内容:
4.其他情况:
①
如果代码中不设置分区的数量: job.setNumReduceTasks(Integer.parseInt(args[2])); 运行命令执行会发现只产生了一个结果文件.
因为MR默认只启动一个reducer...一个reducer对应一个结果文件. 不是分区所要的效果.
②
如果代码中设置的分区数量大于实际的产生的分区数量. 比如以上代码根据数据情况只产生4个分区,但是设置6个分区.
同样会产生6个结果文件,但是后两个结果文件中是没有值的.
③
代码中的分区数量小于实际产生的分区数量. 比如以上代码根据数据情况会产生4个分区,但是只设置2个分区.
报错:(就是因为182对应应该在3号分区,但是实际是只设置了2个分区)

还有设置分区之后代码执行会变慢:因为之前只需要之前只需要把结果发给一个reducer,现在要根据某个属性把mapper的结果分发到不同的reducer中.
MapReduce中的partitioner的更多相关文章
- Hadoop Mapreduce 中的Partitioner
Partitioner的作用的对Mapper产生的中间结果进行分片,以便将同一分组的数据交给同一个Reduce处理,Partitioner直接影响Reduce阶段的负载均衡. MapReduce提供了 ...
- Hadoop学习之路(二十三)MapReduce中的shuffle详解
概述 1.MapReduce 中,mapper 阶段处理的数据如何传递给 reducer 阶段,是 MapReduce 框架中 最关键的一个流程,这个流程就叫 Shuffle 2.Shuffle: 数 ...
- MapReduce中combine、partition、shuffle的作用是什么
http://www.aboutyun.com/thread-8927-1-1.html Mapreduce在hadoop中是一个比較难以的概念.以下须要用心看,然后自己就能总结出来了. 概括: co ...
- Hadoop学习笔记—11.MapReduce中的排序和分组
一.写在之前的 1.1 回顾Map阶段四大步骤 首先,我们回顾一下在MapReduce中,排序和分组在哪里被执行: 从上图中可以清楚地看出,在Step1.4也就是第四步中,需要对不同分区中的数据进行排 ...
- Hadoop学习笔记—12.MapReduce中的常见算法
一.MapReduce中有哪些常见算法 (1)经典之王:单词计数 这个是MapReduce的经典案例,经典的不能再经典了! (2)数据去重 "数据去重"主要是为了掌握和利用并行化思 ...
- MapReduce中作业调度机制
MapReduce中作业调度机制主要有3种: 1.先入先出FIFO Hadoop 中默认的调度器,它先按照作业的优先级高低,再按照到达时间的先后选择被执行的作业. 2.公平调度器(相当于时间 ...
- Mapreduce中的字符串编码
Mapreduce中的字符串编码 $$$ Shuffle的执行过程,需要经过多次比较排序.如果对每一个数据的比较都需要先反序列化,对性能影响极大. RawComparator的作用就不言而喻,能够直接 ...
- MapReduce中一次reduce方法的调用中key的值不断变化分析及源码解析
摘要:mapreduce中执行reduce(KEYIN key, Iterable<VALUEIN> values, Context context),调用一次reduce方法,迭代val ...
- [MapReduce_5] MapReduce 中的 Combiner 组件应用
0. 说明 Combiner 介绍 && 在 MapReduce 中的应用 1. 介绍 Combiner: Map 端的 Reduce,有自己的使用场景 在相同 Key 过多的情况下 ...
随机推荐
- C++之输出100-200内的素数
素数(质数) 除了1和它本身以外不再被其他的除数整除. // 输出100--200内的素数 #include<iostream> using namespace std; int m ...
- IntelliJ IDEA 2017版 编译器使用学习笔记(十) (图文详尽版);IDE快捷键使用;IDE关联一切
关联一切 一.与spring关联 通过图标跳转相关联的类 设置关联:进入project structure ===>facets =>选加号,===>选spring,默认添 ...
- nginx proxy_pass后的url加不加/的区别
在nginx中配置proxy_pass时,当在后面的url加上了/,相当于是绝对根路径,则nginx不会把location中匹配的路径部分代理走;如果没有/,则会把匹配的路径部分也给代理走. 下面四种 ...
- H5总结
1.新增的语义化标签: <nav>: 导航 <header>: 页眉 <footer>: 页脚 <section>:区块 <article> ...
- Codeforces Round #535 (Div. 3) 1108C - Nice Garland
#include <bits/stdc++.h> using namespace std; int main() { #ifdef _DEBUG freopen("input.t ...
- c#运用反射获取属性和设置属性值
/// <summary> /// 获取类中的属性值 /// </summary> /// <param name="FieldName">&l ...
- Codeforces816B Karen and Coffee 2017-06-27 15:18 39人阅读 评论(0) 收藏
B. Karen and Coffee time limit per test 2.5 seconds memory limit per test 512 megabytes input standa ...
- STL容器(C11)--unordered_set用法
http://www.cplusplus.com/reference/unordered_set/
- PHP搜索 搜索 搜索
//搜索界面 public function search(){ $param=input('param.'); $where=[]; //搜索框 if(!empty($param['content' ...
- AngularJS 路由 resolve属性
当路由切换的时候,被路由的页面中的元素(标签)就会立马显示出来,同时,数据会被准备好并呈现出来.但是注意,数据和元素并不是同步的,在没有任何设置的情况下,AngularJS默认先呈现出元素,而后再呈现 ...