吴裕雄 python 爬虫(1)
from urllib.parse import urlparse url = 'http://www.pm25x.com/city/beijing.htm'
o = urlparse(url)
print(o) print("scheme={}".format(o.scheme)) # http
print("netloc={}".format(o.netloc)) # www.pm25x.com
print("port={}".format(o.port)) # None
print("path={}".format(o.path)) # /city/beijing.htm
print("query={}".format(o.query)) # 空

import requests url = 'http://www.wsbookshow.com/'
html = requests.get(url)
html.encoding="GBK"
print(html.text)

import requests url = 'http://www.wsbookshow.com/'
html = requests.get(url)
html.encoding="gbk" htmllist = html.text.splitlines()
n=0
for row in htmllist:
if "新概念" in row:
n+=1
print("找到 {} 次!".format(n))
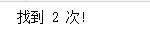
import re
pat = re.compile('[a-z]+') m = pat.match('tem12po')
print(m) if not m==None:
print(m.group())
print(m.start())
print(m.end())
print(m.span())

import re
m = re.match(r'[a-z]+','tem12po')
print(m) if not m==None:
print(m.group())
print(m.start())
print(m.end())
print(m.span())
import re
pat = re.compile('[a-z]+')
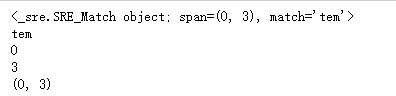
m = pat.search('3tem12po')
print(m) # <_sre.SRE_Match object; span=(1, 4), match='tem'>
if not m==None:
print(m.group()) # tem
print(m.start()) #
print(m.end()) #
print(m.span()) # (1,4)

import re
pat = re.compile('[a-z]+') m = pat.findall('tem12po')
print(m) # ['tem', 'po']
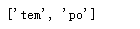
import requests,re
regex = re.compile('[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+')
url = 'http://www.wsbookshow.com/'
html = requests.get(url)
emails = regex.findall(html.text)
for email in emails:
print(email)

吴裕雄 python 爬虫(1)的更多相关文章
- 吴裕雄 python 爬虫(4)
import requests user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, li ...
- 吴裕雄 python 爬虫(3)
import hashlib md5 = hashlib.md5() md5.update(b'Test String') print(md5.hexdigest()) import hashlib ...
- 吴裕雄 python 爬虫(2)
import requests from bs4 import BeautifulSoup url = 'http://www.baidu.com' html = requests.get(url) ...
- 吴裕雄--python学习笔记:爬虫基础
一.什么是爬虫 爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息. 二.Python爬虫架构 Python 爬虫架构主要由五个部分组成,分别是调度器.URL管理器.网页下载器.网 ...
- 吴裕雄--python学习笔记:爬虫包的更换
python 3.x报错:No module named 'cookielib'或No module named 'urllib2' 1. ModuleNotFoundError: No module ...
- 吴裕雄--python学习笔记:爬虫
import chardet import urllib.request page = urllib.request.urlopen('http://photo.sina.com.cn/') #打开网 ...
- 吴裕雄 python 神经网络——TensorFlow pb文件保存方法
import tensorflow as tf from tensorflow.python.framework import graph_util v1 = tf.Variable(tf.const ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(4)
# -*- coding: utf-8 -*- import glob import os.path import numpy as np import tensorflow as tf from t ...
- 吴裕雄 python 神经网络——TensorFlow 花瓣分类与迁移学习(3)
import glob import os.path import numpy as np import tensorflow as tf from tensorflow.python.platfor ...
随机推荐
- 使用Solrj 获取语句分词结果的代码
import java.util.ArrayList; import java.util.Iterator; import java.util.List; import org.apache.log4 ...
- angularjs中阻止事件冒泡,以及指令的注意点
appModule.directive('newStr',function(){ return{ restrict:'AE', //阻止事件冒泡需要加$event参数 template:`<di ...
- Mysql存储过程(六)——存储过程中使用临时表
Mysql 不支持数组.但有时候需要组合几张表的数据,在存储过程中,经过比较复杂的运算获取结果直接输出给调用方,比如符合条件的几张表的某些字段的组合计算. Mysql 临时表可以解决这个问题. 临时表 ...
- 连接Hive的客户端界面工具–SQuirrel SQL Client
关键字:Hive客户端.界面.SQuirrel SQL Client 刚看到一个可以连接Hive的客户端界面工具–SQuirrel SQL Client,试了一下,用起来还行,在这里记录一下安装及使用 ...
- str 操作
str 认识字符串(重点, 多) 字符: 单一的文字符号 字符按照固定的顺序连成串 被' 或者" 或者''' 或者"""括起来的内容 索引 编号, 顺序 从0开 ...
- SVG 学习<三>渐变
目录 SVG 学习<一>基础图形及线段 SVG 学习<二>进阶 SVG世界,视野,视窗 stroke属性 svg分组 SVG 学习<三>渐变 SVG 学习<四 ...
- uiautomator 代码记录 : 随机发送短信
package sms_test; import java.lang.*; import java.util.Random; import javax.microedition.khronos.egl ...
- MYSQL 存储 while 统计每个表
群里一朋友,有一需求就是获取数据库每个表的总计(条数)思路:动态传入表名, count(1) -- 1.执行这句.获取所有表名 as num ) b where t.table_schema='tes ...
- ubuntu上virtualbox无法找到usb设备【解决】
How to set up USB for Virtualbox? USB in different versions of Virtual Box For use of USB in Virtual ...
- An error was encountered while running(Domain=LaunchSerivcesError, Code=0)
今天突然遇到这样一个错误,编译可以通过,但是运行就会弹出这个错误提示: An error was encountered while running(Domain=LaunchSerivcesErro ...