【11】python 递归,深度优先搜索与广度优先搜索算法模拟实现

一、递归原理小案例分析
(1)# 概述
递归:即一个函数调用了自身,即实现了递归 凡是循环能做到的事,递归一般都能做到!
(2)# 写递归的过程
1、写出临界条件
2、找出这一次和上一次关系
3、假设当前函数已经能用,调用自身计算上一次的结果,再求出本次的结果
(3)案例分析:求1+2+3+...+n的数和
# 概述
'''
递归:即一个函数调用了自身,即实现了递归
凡是循环能做到的事,递归一般都能做到! ''' # 写递归的过程
'''
1、写出临界条件
2、找出这一次和上一次关系
3、假设当前函数已经能用,调用自身计算上一次的结果,再求出本次的结果
''' # 问题:输入一个大于1 的数,求1+2+3+....
def sum(n):
if n==1:
return 1
else:
return n+sum(n-1) n=input("请输入:")
print("输出的和是:",sum(int(n))) '''
输出:
请输入:4
输出的和是: 10
'''

#__author:"吉*佳"
#date: 2018/10/21 0021
#function: import os
def getAllDir(path):
fileList = os.listdir(path)
print(fileList)
for fileName in fileList:
fileAbsPath = os.path.join(path,fileName)
if os.path.isdir(fileAbsPath):
print("$$目录$$:",fileName)
getAllDir(fileAbsPath)
else:
print("**普通文件!**",fileName)
# print(fileList)
pass getAllDir("G:\\")
输出结果如下:


二、深度遍历与广度遍历
(一)、深度优先搜索
说明:深度优先搜索借助栈结构来进行模拟
深度遍历示意图:
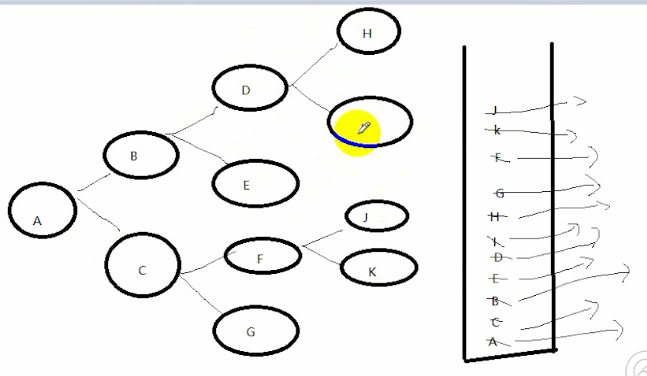
说明:
先把A压栈进去,在A出栈的同时把B C压栈进去,此时让B出栈的同时把DE压栈(C留着先不处理) 同理,在D出栈的时候,H I压栈,最后再从上往下
取出栈内还未出栈的元素,即达到深度优先遍历。
案例实践:利用栈来深度搜索打印出目录结构

程序代码:
#__author:"吉**"
#date: 2018/10/21 0021
#function: # 深度优先遍历目录层级结构 import os def getAllDirDP(path):
stack = []
# 压栈操作,相当于图中的A压入
stack.append(path) # 处理栈,当栈为空的时候结束循环
while len(stack) != 0:
#从栈里取数据,相当于取出A,取出A的同时把BC压入
dirPath = stack.pop()
firstList = os.listdir(dirPath)
#判断:是目录压栈,把该目录地址压栈,不是目录即是普通文件,打印
for filename in firstList:
fileAbsPath=os.path.join(dirPath,filename)
if os.path.isdir(fileAbsPath):
#是目录就压栈
print("目录:",filename)
stack.append(fileAbsPath)
else:
#是普通文件就打印即可,不压栈
print("普通文件:",filename) getAllDirDP(r'E:\[AAA](千)全栈学习python\18-10-21\day7\temp\dir')
结果:

该过程示意图解释:(s-05-1部分)
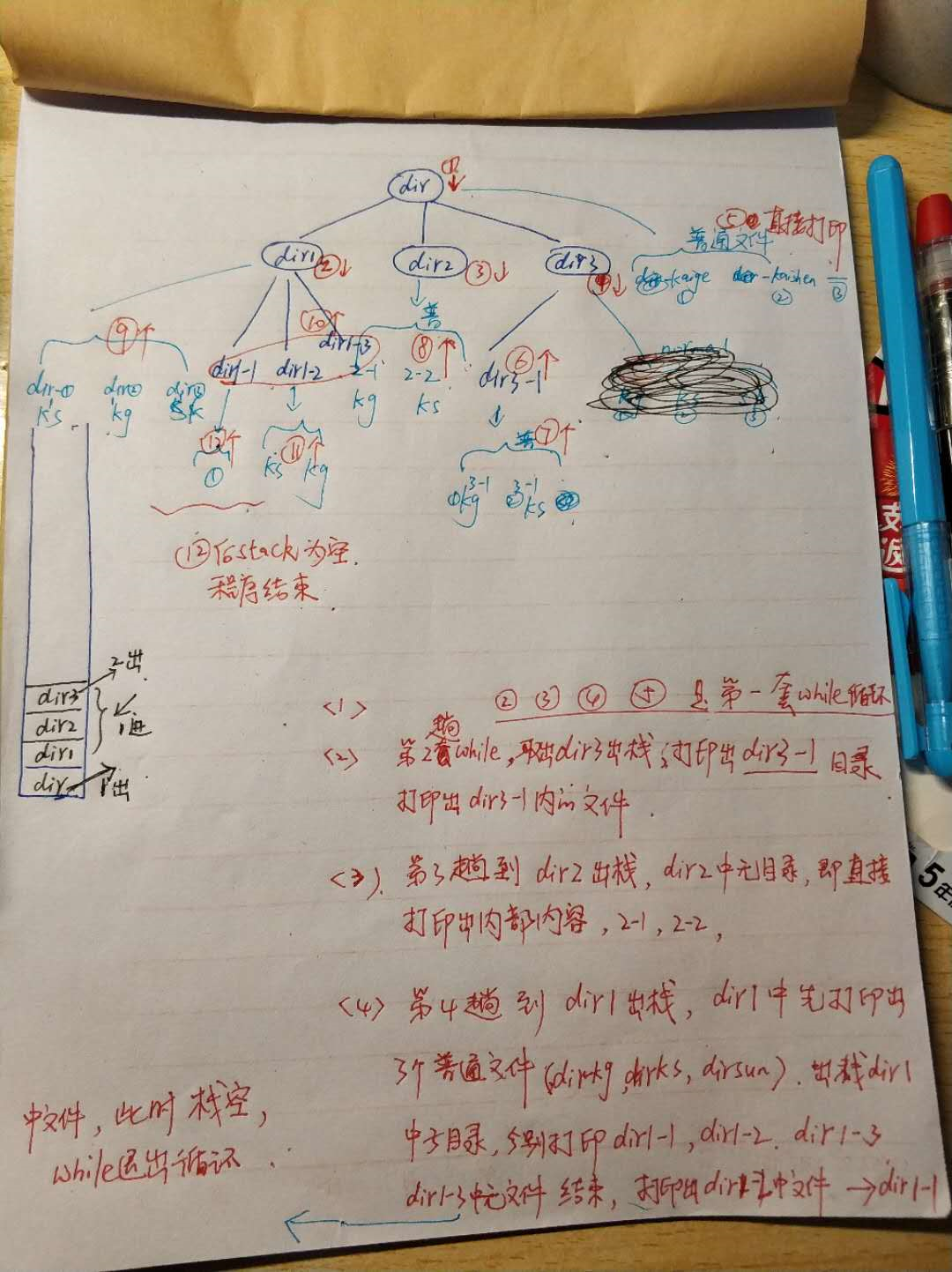

原理分析:

说明:
队列是 先进先出的模型。A先进队,在A出队的时候,C B入队,按图示,C出队,FG 入队,B出队,DE入队,
F出队,JK入队,G出队,无入队,D出队,H I入队,最后E J K H I出队,均无入队了,即每一层一层处理、
故:先进先出的队列结构实现了广度优先遍历。 先进后出的栈结构实现的是深度优先遍历。
代码实现:
其实深度优先和广度优先在代码书写上是差别不大的,基本相同,只是一个是使用栈结构(用列表进行模拟)
另一个(广度优先遍历)是使用了队列的数据结构来达到先进先出的目的。
#__author:"吉**"
#date: 2018/10/21 0021
#function: # 广度优先搜索模拟
# 利用队列来模拟广度优先搜索 import os
import collections def getAllDirIT(path):
queue=collections.deque()
#进队
queue.append(path) #循环,当队列为空,停止循环
while len(queue) != 0:
#出队数据 这里相当于找到A元素的绝对路径
dirPath = queue.popleft()
# 找出跟目录下的所有的子目录信息,或者是跟目录下的文件信息
dirList = os.listdir(dirPath) #遍历该文件夹下的其他信息
for filename in dirList:
#绝对路径
dirAbsPath = os.path.join(dirPath,filename) # 判断:如果是目录dir入队操作,如果不是dir打印出即可
if os.path.isdir(dirAbsPath):
print("目录:"+filename)
queue.append(dirAbsPath)
else:
print("普通文件:"+filename) # 函数的调用
getAllDirIT(r'E:\[AAA](千)全栈学习python\18-10-21\day7\temp\dir')
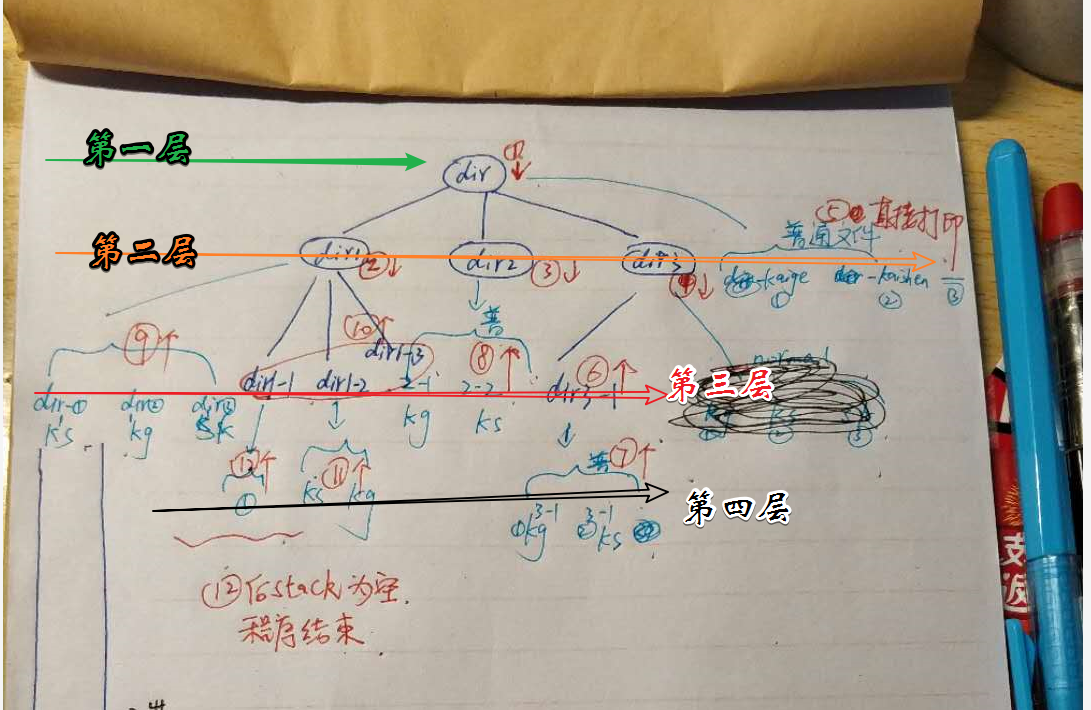
广度优先运行输出结构:

先图解:按照每一层从左到右遍历即可实现。

【11】python 递归,深度优先搜索与广度优先搜索算法模拟实现的更多相关文章
- python 递归深度优先搜索与广度优先搜索算法模拟实现
一.递归原理小案例分析 (1)# 概述 递归:即一个函数调用了自身,即实现了递归 凡是循环能做到的事,递归一般都能做到! (2)# 写递归的过程 1.写出临界条件2.找出这一次和上一次关系3.假设当前 ...
- python 递归,深度优先搜索与广度优先搜索算法模拟实现
一.递归原理小案例分析 (1)# 概述 递归:即一个函数调用了自身,即实现了递归 凡是循环能做到的事,递归一般都能做到! (2)# 写递归的过程 1.写出临界条件 2.找出这一次和上一次关系 3.假设 ...
- DFS_BFS(深度优先搜索 和 广度优先搜索)
package com.rao.graph; import java.util.LinkedList; /** * @author Srao * @className BFS_DFS * @date ...
- 【Python排序搜索基本算法】之深度优先搜索、广度优先搜索、拓扑排序、强联通&Kosaraju算法
Graph Search and Connectivity Generic Graph Search Goals 1. find everything findable 2. don't explor ...
- Depth-first search and Breadth-first search 深度优先搜索和广度优先搜索
Depth-first search Depth-first search (DFS) is an algorithm for traversing or searching tree or grap ...
- 递归——深度优先搜索(DFS)——以滑雪问题为例(自顶而下)
一.问题:滑雪 问题描述:小明喜欢滑雪,为了获得速度,滑的区域必须向下倾斜,而且当你滑到坡底,你不得不再次走上坡或者等待升降机来载你.小明想知道在一个区域中最长底滑坡.区域由一个二维数组给出.数组的每 ...
- 11: python递归
1.1 递归讲解 1.定义 1. 在函数内部,可以调用其他函数.如果一个函数在内部调用自身本身,这个函数就是递归函数. 2.递归特性 1. 必须有一个明确的结束条件 2. 每次进入更深一层递归时,问题 ...
- 【js数据结构】图的深度优先搜索与广度优先搜索
图类的构建 function Graph(v) {this.vertices = v;this.edges = 0;this.adj = []; for (var i = 0; i < this ...
- DFS或BFS(深度优先搜索或广度优先搜索遍历无向图)-04-无向图-岛屿数量
给定一个由 '1'(陆地)和 '0'(水)组成的的二维网格,计算岛屿的数量.一个岛被水包围,并且它是通过水平方向或垂直方向上相邻的陆地连接而成的.你可以假设网格的四个边均被水包围. 示例 1: 输入: ...
随机推荐
- [Node.js] 3、搭建hexo博客
一.安装新版本的nodejs和npm 安装n模块: npm install -g n 升级node.js到最新稳定版 n stable 二.安装hexo note: 参考github,不要去其 ...
- 【学习笔记】浅析Promise函数
一.Promise是什么? 在JavaScript中,所有的代码都是单线程执行,所以javaScript的所有网络操作(“GET”/"POST"/"PUT"/& ...
- maven官方教程
What is Maven? At first glance Maven can appear to be many things, but in a nutshell Maven is an att ...
- Git学习笔记4
现在,远程库已经准备好了,下一步是用命令git clone克隆一个本地库: $ git clone git@github.com:michaelliao/gitskills.git 要克隆一个仓库,首 ...
- 用ECMAScript4 ( ActionScript3) 实现Unity的热更新 -- 热更新Live2D
live2D是一个很强大的2D动画组件.我们可以使用AS3脚本对它进行热更新. live2D在Unity中的使用请看这里: 如何获取Live2D 总得来说,我们可以先去live2D官网下载它的Unit ...
- [C#]记一次解析XML转对象的笔记
项目中调用第三方API,返回格式是XML字符串,需要将XML反序列化为对象,格式如下: <?xml version="1.0"?> <Response xmlns ...
- Dapper入门使用,代替你的DbSQLhelper
Dapper介绍 Dapper是.Net下的一个轻量级ORM框架.在小型工具向的项目下,使用Dapper会使数据库操作层代码更加优雅. Dapper的使用 在项目中使用引用Dapper非常简单,你可以 ...
- WCF发布多个服务
using System; using System.Collections.Generic; using System.Linq; using System.Text; using WcfServi ...
- 为什么IIS的应用池回收设置默认为1740分钟-20180720
[非原创,个人收集,希望大家有感触] 你可曾留心过IIS的应用池回收设置默认值是多少?1740分钟对吗,那么为什么会是这样的数值呢? 在asp.net的某篇博客里提到了这个问题. 有关微软产品的许多决 ...
- JS forEach()与map() 用法(转载)
JavaScript中的数组遍历forEach()与map()方法以及兼容写法 原理: 高级浏览器支持forEach方法语法:forEach和map都支持2个参数:一个是回调函数(item,ind ...