17 RAID与mdadm管理命令
在"14 磁盘及文件系统管理详解"中,我们详细介绍了磁盘的工作原理,但是,有一点我们一定要明白,作为现在存储数据的主要设备,机械磁盘早就是上个世纪的产品,而它的读写速度与内存、CPU比起来已经不在一个级别上,但是当前“大数据”背景下,我们有大量的数据需要进行存储,这样对磁盘的要求更加高了。
为了解决,或者是缓解磁盘读写存储速度慢,以及保证数据的冗余性,我们创建了RADI技术,同时,通过mdadm命令来管理软RAID。这一节内容,我们就来详细了解RAID技术和mdadm管理命令。
硬盘的分类(接口)
我们说电脑的核心部件为CPU、内存和I/O总线;他们之间的大概工作过程如下图:

1、我们要知道,系统要实现某一个应用的功能,就需要对应的启动这个应用的进程。而这个进程的运行与否,则取决于内核进程。所以,第一步,我们需要将内核进程调用CPU上,让内核进程调用你要实现的那个应用的进程内容。而这些进程内容默认都是存储在内存中的;
所以,我们说内存的大小直接决定了进程运行的快慢;
【这里要注意的是,我们的内存将进程分为一个一个的“页面”,而“页面”的大小正好就是2^n,所以,我们的磁盘上的数据块(block)的大小,也是以2^n来进行存储的,就是为了方便内存调用】
2、内核进程决定调用的哪个普通进程,比如,我要运行“mkdir”创建目录,则这个时候,“mkdir”的进程就会被调用到CPU上来运行;这个过程就是由内核进程来决定的;
3、“mkdir”的进程决定了调用磁盘的那些数据,而这个过程则由CPU通过控制总线来向磁盘发起控制指令;例如:运行 “mkdir /test” 则此时,CPU就会控制在 / 目录对应的磁盘来创建 test 目录;
4、如果是数据调用,则这个数据会通过数据总线,从磁盘上调用到内存中,方便应用进程来对该数据进行处理;
明白这个过程后,我们需要明白一个问题;不管是在数据传输、还是指令传输的时候,我们的CPU、磁盘、内存都来自于不同的厂家,而这些厂家之间的指令都是不同的。就好像一个说英语的和一个说汉语的之间无法沟通。这时候,我就需要两个东西来解决这个问题:1、驱动;2、控制器(接口)
驱动我们不多研究,这里我们重点说磁盘控制器:
主板上不同的接口,就是不同设备的控制器,他们都担任着控制指令转换的任务,也就是将CPU的控制指令装换为各个设备能够识别的控制指令。在保证指令能够读懂的情况下,来进行数据传输;
在硬盘设备上,我们根据不同的接口来区分不同的硬盘:
1、IDE并行总线:133Mbps
2、SATA串行总线:300Mbps、600Mbps
3、USB3.0串行接口:480Mbps
4、SCSI(small computer system interface 小型计算机系统接口)并行总线
5、SAS将SCSI并行总线接口作为串行总线接口
此时,我们回到我们最初提出的问题,在一台繁忙的服务器上面,单块磁盘没办法满足内存对于数据读取速度的要求了。这是候,就出现了RAID技术;
RAID的工作原理
RAID原理说白了,就是将多个磁盘同时为服务器提供数据读取与写入的服务;
原来磁盘用来连接服务器的那个接口,不再用来直接连接硬盘,而是连接一个特定的设备,而这个设备能将一个接口模拟成多个接口,用来连接硬盘,而接主机的那个口依然只有一个,这样,在CPU看来,后面接的硬盘依然是一个,而实际上已经接上了多个磁盘;
而这个中间设备,我们就叫做RAID(可以是硬件,也可以由软件模拟,模拟的叫软RAID,而硬件搭建的叫硬RAID,这内容我们之后再提),Redundant arrays of dependent disks 独立的磁盘冗余阵列。现在,它已经成为了一个企业级存储的标准解决方案;
条带与镜像
RAID如何进行数据存储呢?
100M的数据,将其存储于两个磁盘上,如果按照block单位来存储,则会被切分为过小的数据,不太适合,为了方便将数据存储,我们使用条带技术,将数据均匀的切分为多个“条带”;如下图,将100M的数据分为两个50M的条带分别存储于两块磁盘上;
在数据进行读取的时候,也是从来块次磁盘上面同时读取;
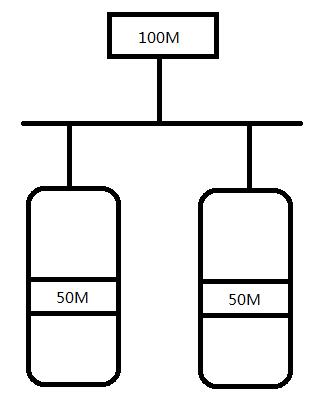
但是这样来存储数据也有一个问题,如果任何一个磁盘上的数据出现问题,则整个数据就无法读取了;
RAID如何进行数据冗余呢?(镜像)
为了解决条带技术带来的数据容易丢失的问题,我们又通过镜像的方式来对数据进行备份,这种方式就是将同一份数据在两个磁盘上都存放一份,其中一个磁盘数据丢失,还有另外一个磁盘的数据还在;但是,这种方式使得数据读写速度降低。
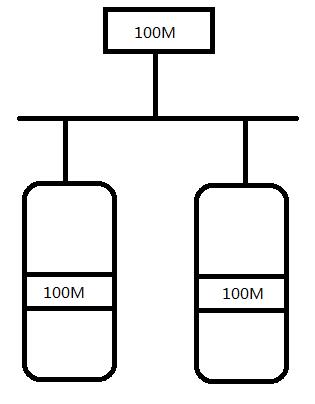
所以,就产生了各种级别的RAID。
RAID级别
首先,RAID级别仅仅只是代表磁盘的组织方式不同,没有上下之分;
RAID0 条带技术,实现的即为RAID0
RAID1 镜像技术,实现的即为RAID1
RAID10 对磁盘先做RAID1,在对磁盘做RAID0,则是RAID10

A,B两盘做RAID1,C,D两盘做RAID1,然后再一起做RAID0;
RAID01
A,B两盘先做RAID0,C,D两盘先做RAID0,然后再一起做RAID1;
R10要比R01好,因为,如果A,B做的RAID1,当B盘出现故障的时候,则在数据恢复的时候就可以直接从A盘进行数据恢复;如果A,B做的是RAID0,当B盘出现故障的时候,则在数据恢复的时候,就需要从C,D两盘中获取数据进行恢复;
RAID4 最少要三块盘,才能实现RAID4;其中一块校验盘,如果A,B或者校验盘任何一块盘坏了,都可以进行数据恢复。但是,在读取或者存储数据的时候都要经过校验盘,所以,这大大影响了数据的读取;于是就有了RAID5;
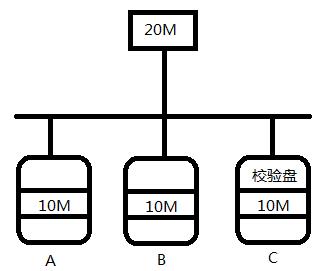
RAID5 如下图,相对于RAID4而言,RAID5则是将校验数据分布在各个磁盘上,则时候就不会单独拿出一个磁盘来作为校验盘了。这就解决了RAID4校验盘影响数据读写速度的问题;【这是最常用的RAID方式】

RAID50 磁盘先做RAID5,在做RAID0;
RAID6 相对于RAID5而言,RAID5只做了一次数据校验,而RAID6则由添加了一次数据校验的过程;
JBOD 磁盘大小可以不停的累加,当单个文件特别大的时候,并且在逐渐变大的时候,空间不够用了,就可以使用该技术;Hadoop就需要使用到该技术;
硬RAID与软RAID
硬RAID是由特定的RAID卡来完成工作的。
这个RAID卡上包含自己的控制芯片,自己的内存,以及供电电池;硬RAID的配置需要在BIOS里面完成;做好了RAID以后,CPU是无法看到你的真正的磁盘了,而是一些虚拟的磁盘;当CPU需要将数据写入磁盘的时候,这时现将数据缓存在RAID卡上的内存上面,然后慢慢写入到磁盘中;当CPU要读取数据的时候,这个工作就由RAID的芯片来完成;
软RAID的实现是通过系统内核模块md(multi disks)来完成。
首先md会模拟出一个逻辑设备来,这个逻辑设备就是以md开头的文件,例如/dev/md0最后的数字只是一个标号而已;再进行数据存储的时候就会通过你对应的RAID级别进行存储;所以软RAID是由你的CPU完成的,这个性能是无法保证的;
mdadm管理命令(软RAID)
mdadm(md admin)md的管理器;将任何块设备做成RAID;
-C 创建
-l 级别 指定级别
-n 设备个数
-c chunk大小
--add
--del
-F 监控查看
-G 增加
-A 装配
-x 指定空闲盘自动填充坏盘
例如:mdadm -C /dev/md0 -a yes -l 0 -n 2 /dev/sdb{1,2}
【在创建这个虚拟的RAID磁盘的过程中,我们可以通过 cat /proc/mdstat 文件,看到磁盘的同步过程】
cat /proc/mdstat或fdisk -l查看创建RAID的相关信息;
mount /dev/md0 /mnt 挂载就能使用了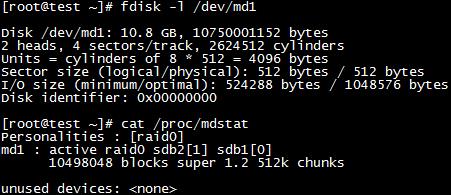
例如:mdadm -C /dev/md1 -a yes -n 2 -l 1 -x 1 /dev/sdb{1,2,3} #指定/dev/md1磁盘,然后 -x 指定一个备份盘;
mke2fs -j /dev/md1 格式化
mount /dev/md1 /media/ 挂载
mdadm -D /dev/md1 显示磁盘阵列RAID的详细信息

-f 可以模拟坏盘
mdadm /dev/md1 -f /dev/sdb1 #将sdb1模拟损坏
-r 移除坏盘
mdadm /dev/md1 -r /dev/sdb1 #将sdb1拔出来
-S 暂停运行整个磁盘阵列
mdadm -S /dev/md1 #停止这个整列
-A 再次启动磁盘整列
mdadm -A /dev/md1 /dev/sdb{1,2} 重新再启用这个RAID
watch 周期性的执行某命令,并以全屏的方式显示这个结果;
-n 制定周期长度
例如:watch -n 5 ‘命令’ #将当前RAID信息保存至配置文件,以便以后进行装配
mdadm -D --scan > /etc/mdadm.conf
17 RAID与mdadm管理命令的更多相关文章
- 软RAID管理命令mdadm详解
软RAID管理命令mdadm详解 mdadm是linux下用于创建和管理软件RAID的命令,是一个模式化命令.但由于现在服务器一般都带有RAID阵列卡,并且RAID阵列卡也很廉价,且由于软件RAID的 ...
- Linux 系统常用管理命令(精简笔记)
Linux是一套免费使用和自由传播的类Unix操作系统,下面的笔记是我从鸟菜中摘抄出来的重要命令,并进行了一定的排版,摒弃了一些用不到的乱七八糟的命令,目的是在生产环境中能够快速的定位并查询需要命令的 ...
- TUXEDO管理命令总结
tmboot 启动服务: 参数说明: -l lmid 启动逻辑服务器名为lmcd服务器上的所有进程 -g grpname 启动GROUP名为grpname的所有进程 -i srvid 启动SRV ...
- 详解MongoDB管理命令
MongoDB是一个NoSQL数据库系统:一个数据库可以包含多个集合(Collection),每个集合对应于关系数据库中的表:而每个集合中可以存储一组由列标识的记录,列是可以自由定义的,非常灵活,由一 ...
- 第四章· Redis的事务、锁及管理命令
一.事务介绍 二.Redis乐观锁介绍 三.Redis管理命令 一.事务介绍 Redis的事务与关系型数据库中的事务区别 1)在MySQL中讲过的事务,具有A.C.I.D四个特性 Atomic(原子性 ...
- Docker 共有 13 个管理命令和 41 个通用命令,以下是常用 Docker 命令列表
开发人员一直在努力提高 Docker 的使用率和性能,命令也在不停变化.Docker 命令经常被弃用,或被替换为更新且更有效的命令,本文总结了近年来资深专家最常用的命令列表并给出部分使用方法. 目前, ...
- hadoop 管理命令dfsadmin
hadoop 管理命令dfsadmin dfsadmin 命令用于管理HDFS集群,这些命令常用于管理员. 1. (Safemode)安全模式 动作 命令 把集群切换到安全模式 bin/hdfs df ...
- LINUX文件及目录管理命令基础
Linux命令行组成结构 Linux命令结构 在Linux中一切皆文件,一切皆命令! 命令提示符: [root@tt ~]# [xiaohui@tt ~]$ Linux命令行常用快捷键 ctrl + ...
- docker之镜像管理命令
一.docker image 镜像管理命令 指令 描述ls 列出本机镜像build 构建镜像来自Dockerfilehistory 查看镜像历史inspect 显示一个或多个镜像详细信息pull 从镜 ...
随机推荐
- 将数组A中的内容和数组B中的内容进行交换。(数组一样大)
将两个数组中的内容相互交换,必须是两个数组的内容一样大小. 思路: 结合两个整型变量之间的交换,同样可以用于内容一样大的数组.用异或关系相互交换. #include<stdio.h> in ...
- 我发起了一个 .Net 平台上的 产生式编程 开源项目 GP.Net
大家好 , 我发起了一个 .Net 平台上的 产生式编程 开源项目 GP.Net . 我们可以先看看一个网友的 代码生成器 项目 : <.Net 代码生成器 for PostgreSql> ...
- Spring4相关jar包介绍(转)
Spring4相关jar包介绍 spring-core.jar(必须):这个jar 文件包含Spring 框架基本的核心工具类.Spring 其它组件要都要使用到这个包里的类,是其它组件的基本核心,当 ...
- CenterOS下安装NodeJS
1. 首先下载NodeJS的版本 wget https://nodejs.org/dist/v8.1.3/node-v8.1.3-linux-x64.tar.gz 我这里下载的是v8.1.3 版本 n ...
- 使用FormsAuthenticationTicket进行登陆验证
if (账号密码验证成功) { //登陆成功 Session["User"] = account; FormsAuthenticationTicket ticket = new F ...
- mysql的变量信息详解
mysql的变量详解 执行show variables命令可以查看MySQL服务器的变量 变量名 默认值 说明 对应的配置文件参数 auto_increment_increment 1 自增长类型的初 ...
- 浅谈负margin
通常来说margin为正值时,我们很清楚其布局形式,即在border边界线处再往外扩展指定长度.可margin为负又表示什么呢,表示始于border边界线处并向内扩展指定长度,这样,下一个文档流对象便 ...
- java反射以及动态代理的学习
java反射学习 1)字节码文件的三种获取方式 ①:Object类的getClass()方法:对象.getClass() ②:数据类型的静态的class属性:类名.class ③:通过Class类的静 ...
- 基于vue.js实现远程请求json的select控件
基本思路 前端把需要的参数类型编码传到后台,后台返回相应的参数列表json,前端利用vue渲染select控件 具体实现 前端代码 <select v-model="template. ...
- CSS3 圆角(border-radius)
值:半径的长度 前缀 -moz(例如 -moz-border-radius)用于Firefox -webkit(例如:-webkit-border-radius)用于Safari和Chrome. 例1 ...