Spark RDD深度解析-RDD计算流程
Spark RDD深度解析-RDD计算流程
摘要 RDD(Resilient Distributed Datasets)是Spark的核心数据结构,所有数据计算操作均基于该结构进行,包括Spark sql 、Spark Streaming。理解RDD有助于了解分布式计算引擎的基本架构,更好地使用Spark进行批处理与流计算。本文以Spark2.0源代码为主,对RDD的生成、计算流程、加载顺序等作深入的解析。
RDD印象
直观上,RDD可理解为下图所示结构,即RDD包含多个Partition(分区),每个Partition代表一部分数据并位于一个计算节点。
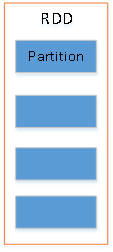
RDD本质上是Spark中的一个抽象类,所有子RDD(HadoopRDD、MapPartitionRDD、JdbcRDD等)都要继承并实现其中的方法。
abstract class RDD[T: ClassTag](
@transient private var _sc: SparkContext,
@transient private var deps: Seq[Dependency[_]]
) extends Serializable with Logging {
RDD包含以下成员方法或属性:
1、compute方法
提供在计算过程中Partition元素的获取与计算方式
2、partition的列表
每一个partition代表一个并行的最小划分单元;
3、dependencies列表
描述RDD依赖哪些父RDD生成,即RDD的血缘关系;
4、partition的位置列表
定义如何最快速的获取partition的数据,加快计算,这个是可选的,可作为本地化计算的优化选项;
5、partitioner方法
定义如何对数据进行分区。
RDD生成方式
1、scala集合
Partition的默认值:defaultParallelism
defaultParallelism与spark的部署模式相关:
- Local 模式:本机 cpu cores 的数量
- Mesos 模式:8
- Yarn:max(2, 所有 executors 的 cpu cores 个数总和)
2、物理数据载入
默认为min(defaultParallelism, 2)
3、其他RDD转换
根据具体的转换算子而定
Partition
Partiton不直接持有数据,仅仅代表了分区的位置(index的值)。
trait Partition extends Serializable {
/**
* Get the partition's index within its parent RDD
*/
def index: Int
// A better default implementation of HashCode
override def hashCode(): Int = index
override def equals(other: Any): Boolean = super.equals(other)
}
Dependency
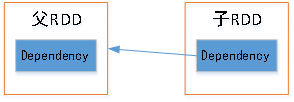
从名字可以猜想,他描述了RDD之间的依赖关系。成员rdd就是父RDD,会在构造RDD时被赋值。
abstract class Dependency[T] extends Serializable {
def rdd: RDD[T]
}
由上述RDD、Dependcy关系可画出下图,通过这种方式,子RDD能轻易找到父RDD的位置等信息,从而构建出RDD的转换路径,为DAGScheduler的任务划分及任务执行时寻找依赖的数据提供依据。
到此应该能大致明白RDD中涉及的各个概念的含义及其之间的联系。但是仔细思考,会发现存在很多问题,比如:
既然RDD不携带数据,那么数据是何时加载的?怎么加载的?怎么分布到不同计算节点的?
不同类型的RDD是怎么完成转换的?
RDD计算流程
以下面几行代码为例,解答上述问题。
var sc = new SparkContext();
var hdfs_rdd = sc.textFile(hdfs://master:9000/examples/people.txt); // 加载数据
var rdd = hdfs_rdd.map(_.split(“,”)); // 对每行数据按逗号分隔
print(rdd.count()); // 打印数据的条数
RDD的转换
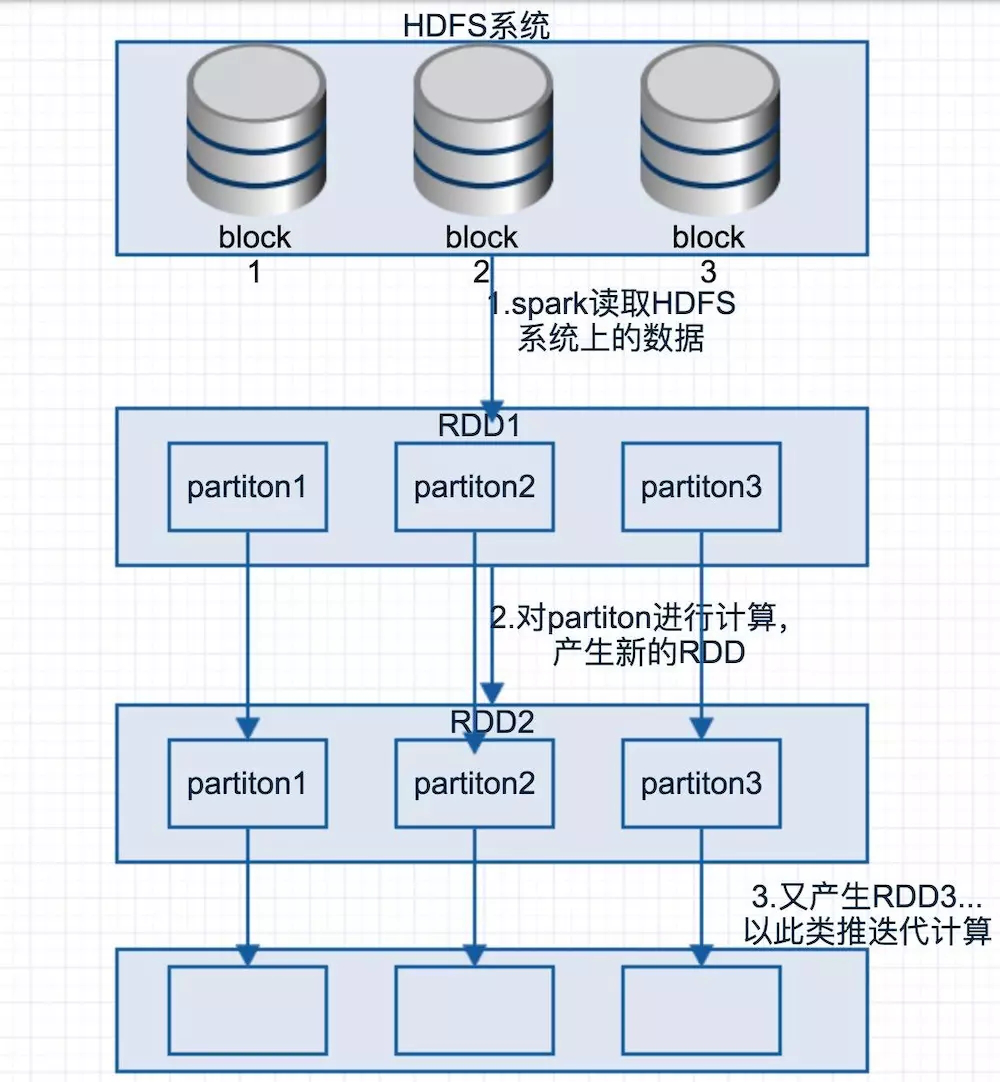
首先从直观上了解上述代码执行过程中RDD的转换,如下图,Spark按照HDFS中文件的block将数据加载到内存,成为初始RDD1,经过每一步操作后转换为相应RDD。
首先分析textFile方法的作用,源码如下:
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)
}
着重看红色语句,textFile方法实际上是先调用了hadoopFile方法,再利用其返回值调用map方法,HadoopFile执行了什么,返回了什么呢?
def hadoopFile[K, V](
path: String,
inputFormatClass: Class[_ <: InputFormat[K, V]],
keyClass: Class[K],
valueClass: Class[V],
minPartitions: Int = defaultMinPartitions): RDD[(K, V)] = withScope {
assertNotStopped()
// This is a hack to enforce loading hdfs-site.xml.
// See SPARK-11227 for details.
FileSystem.getLocal(hadoopConfiguration)
// A Hadoop configuration can be about 10 KB, which is pretty big, so broadcast it.
val confBroadcast = broadcast(new SerializableConfiguration(hadoopConfiguration))
val setInputPathsFunc = (jobConf: JobConf) => FileInputFormat.setInputPaths(jobConf, path)
new HadoopRDD(
this,
confBroadcast,
Some(setInputPathsFunc),
inputFormatClass,
keyClass,
valueClass,
minPartitions).setName(path)
}
很明显,hadoopFile实际上是获取了HADOOP的配置,然后构造并返回了HadoopRDD对象,HadoopRDD是RDD的子类。因此textFile最后调用的是HadoopRDD对象的map方法,其实RDD接口中定义并实现了map方法,所有继承了RDD的类调用的map方法都来自于此。
观察RDD的map方法:
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}
map方法很简单,首先包装一下传进来的函数,然后返回MapPartitionsRDD对象。至此,textFile结束,他最终只是返回了MapPartitionsRDD,并没有执行数据读取、计算操作。
接着看下一语句:var rdd = hdfs_rdd.map(_.split(“,”));
由上面的分析可知hdfs_rdd是一个MapPartitionsRDD对象,于是其map方法内容与上文的一模一样,也只是返回一个包含用户函数的MapPartitionsRDD对象。
目前为止每个方法的调用只是返回不同类型的RDD对象,还未真正执行计算。
接着看var cnt = rdd.count();
count是一种action类型的操作,会触发RDD的计算,为什么说count会触发RDD的计算呢?需要看看count的实现:
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum
可以看到,count方法中调用了sc(sparkContext)的runJob方法,该操作将触发DagScheduler去分解任务并提交到集群执行。count方法会返回Array[U]类型的结果,数组中每个值代表了当前RDD每个分区中包含的元素个数,因此sum的结果就是RDD中所有元素的个数,本例的结果就是HDFS文件中存在几行数据。
RDD的计算
下面介绍任务提交后RDD是怎么计算出来的。
任务分解并提交后开始执行,task会在最后一个RDD上执行compute方法。
以上述代码为例,最后一个RDD的类型是MapPartitionsRDD,看其compute方法:
override def compute(split: Partition, context: TaskContext): Iterator[U] =
f(context, split.index, firstParent[T].iterator(split, context))
其中split是RDD的分区,firstParent是父RDD;最外层的f其实是构造MapPartitionsRDD时传入的一个参数,改参数是一个函数对象,接收三个参数并返回Iterator
private[spark] class MapPartitionsRDD[U: ClassTag, T: ClassTag](
var prev: RDD[T],
f: (TaskContext, Int, Iterator[T]) => Iterator[U], // (TaskContext, partition index, iterator)
preservesPartitioning: Boolean = false)
f是何时生成的呢?就看何时生成的MapPartitionsRDD,参考上文可知MapPartitionsRDD是在map方法里构造的,其第二个构造参数就是f的具体实现。
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
综上可知,MapPartitionsRDD的compute中f的作用就是就是对f的第三个参数iter执行iter.map(cleanF),其中cleanF就是用户调用map时传入的函数,而iter又是firstParent[T].iterator(split, context)的返回值。
firstParent[T].iterator(split, context)又是什么呢?他是对父RDD执行iterator方法,该方法是RDD接口的final方法,因此所有子RDD调用的都是该方法。
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
getOrCompute(split, context)
} else {
computeOrReadCheckpoint(split, context)
}
}
通过进一步查看可知,iterator先判断 RDD 的 storageLevel 是否为 NONE,若不是,则尝试从缓存中读取,读取不到则通过计算来获取该 Partition 对应的数据的迭代器;若是,尝试从 checkpoint 中获取 Partition 对应数据的迭代器,若 checkpoint 不存在则通过计算来获取。
Iterator方法将返回一个迭代器,通过迭代器可以访问父RDD的某个分区的每个元素,如果内存中不存在父RDD的数据,则调用父RDD的compute方法进行计算。
RDD真正的计算由RDD的action 操作触发,对于action 操作之前的所有Transformation 操作,Spark只记录Transformation的RDD生成轨迹,即各个RDD之间的相互依赖关系。
总结
Spark RDD的计算方式为:spark是从最后一个RDD开始计算(调用compute),计算时寻找父RDD,若父RDD在内存就直接使用,否则调用父RDD的compute计算得出,以此递归,过程可抽象为下图:
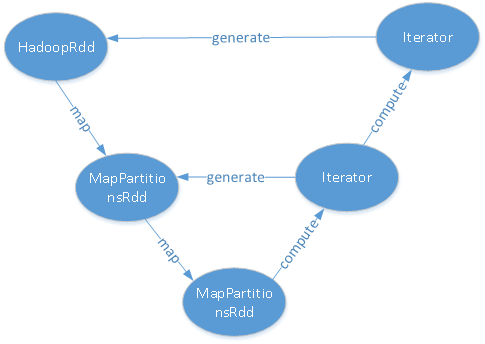
从对象产生的顺序看,先生成了HadoopRDD,调用两次map方法后依次产生两个MapPartitionsRDD;从执行的角度看,先执行最后一个RDD的compute方法,在计算过程中递归执行父RDD的compute,以生成对应RDD的数据;从数据加载角度看,第一个构造出来的RDD在执行compute时才会将数据载入内存(本例中为HDFS读入内存),然后在这些数据上执行用户传入的方法,依次生成子RDD的内存数据。
Spark RDD深度解析-RDD计算流程的更多相关文章
- 【原创】大数据基础之Spark(4)RDD原理及代码解析
一 简介 spark核心是RDD,官方文档地址:https://spark.apache.org/docs/latest/rdd-programming-guide.html#resilient-di ...
- 7.spark Streaming 技术内幕 : 从DSteam到RDD全过程解析
原创文章,转载请注明:转载自 听风居士博客(http://www.cnblogs.com/zhouyf/) 上篇博客讨论了Spark Streaming 程序动态生成Job的过程,并留下一个疑问: ...
- Spark性能调优-RDD算子调优篇(深度好文,面试常问,建议收藏)
RDD算子调优 不废话,直接进入正题! 1. RDD复用 在对RDD进行算子时,要避免相同的算子和计算逻辑之下对RDD进行重复的计算,如下图所示: 对上图中的RDD计算架构进行修改,得到如下图所示的优 ...
- Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述
Spark SQL模块,主要就是处理跟SQL解析相关的一些内容,说得更通俗点就是怎么把一个SQL语句解析成Dataframe或者说RDD的任务.以Spark 2.4.3为例,Spark SQL这个大模 ...
- 大数据入门第二十二天——spark(二)RDD算子(1)
一.RDD概述 1.什么是RDD RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的 ...
- spark中的pair rdd,看这一篇就够了
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是spark专题的第四篇文章,我们一起来看下Pair RDD. 定义 在之前的文章当中,我们已经熟悉了RDD的相关概念,也了解了RDD基 ...
- Spark笔记:复杂RDD的API的理解(上)
本篇接着讲解RDD的API,讲解那些不是很容易理解的API,同时本篇文章还将展示如何将外部的函数引入到RDD的API里使用,最后通过对RDD的API深入学习,我们还讲讲一些和RDD开发相关的scala ...
- Spark编程模型及RDD操作
转载自:http://blog.csdn.net/liuwenbo0920/article/details/45243775 1. Spark中的基本概念 在Spark中,有下面的基本概念.Appli ...
- Spark源码系列:RDD repartition、coalesce 对比
在上一篇文章中 Spark源码系列:DataFrame repartition.coalesce 对比 对DataFrame的repartition.coalesce进行了对比,在这篇文章中,将会对R ...
随机推荐
- linux 下获取文件最后几行
在Linux下,获取文件倒数几行的命令是: tail -n 10 your_filename #获取倒数10行
- CreateEvent
事件对象就像一个开关:它只有两种状态---开和关.当一个事件处于”开”状态,我们称其为”有信号”否则称为”无信号”.可以在一个线程的执行函数中创建一个事件对象,然后观察它的状态,如果是”无信号”就让该 ...
- 将jar包添加到maven仓库
Maven资源库配置 访问http://mvnrepository.com/,在搜索栏中输入你要搜索的 JAR 包的关键字 例如下载ImpalaJDBC41这个jar包 选择你想要下载的Jar包版 ...
- 解决PC有道云笔记卸载重装后无法数据同步问题
将客户端内容成功同步后,按键盘win键选择文件资源管理器,将以下路径一次粘贴到搜索框按回车搜索,将搜索到的所有内容(文件,文件夹)全部删除,再重启软件登录账户同步试试看 配置目录:%USERPROFI ...
- easyui combobox 带 checkbox 亲自验证
$('#cc').combobox({ url:'combobox_data1.json', method:'get', ...
- Spring 事务回滚代码
在事务中实行的方法:org.springframework.transaction.interceptor.TransactionAspectSupport#invokeWithinTransacti ...
- 【转】Android Camera 相机开发详解
在Android 5.0(SDK 21)中,Google使用Camera2替代了Camera接口.Camera2在接口和架构上做了巨大的变动, 但是基于众所周知的原因,我们还必须基于 Android ...
- OpenCV——反向投影(定位模板图像在输入图像中的位置)
反向投影: #include <opencv2/opencv.hpp> #include <iostream> using namespace cv; using namesp ...
- 理解javascript观察者模式(订阅者与发布者)
什么是观察者模式? 观察者模式又叫做发布订阅模式,它定义了一种一对多的关系,让多个观察者对象同时监听某一个主题对象,这个主题对象的状态发生改变时就会通知所有观察着对象.它是由两类对象组成,主题和观察者 ...
- switchable图片切换
前提: 最近由于项目的需要jquery "switchable图片切换"效果 所以趁着周末有空时间研究下 ,以前工作都依赖于kissy框架,所以也没有综合的写过类似的,如下图所示效 ...