【大数据实战】将普通文本文件导入ElasticSearch
以《刑法》文本.txt为例。
一、格式化数据
1,首先,ElasticSearch只能接收格式化的数据,所以,我们需要将文本文件转换为格式化的数据---json。
下图为未处理的文本文件。

2,这里,使用python文件操作,将文本格式化为ElasticSearch可识别的json格式。
#python 3.6
#!/usr/bin/env python # -*- coding:utf-8 -*-
__author__ = 'BH8ANK'
'''
最终将输出格式改为
{"index":{"_index":"xingfa","_id":1}}
{"text_entry":"犯罪的行为或者结果有一项发生在中华人民共和国领域内的,就认为是在中华人民共和国领域内犯罪。"} ''' '''读取文件
'''
a = open(r"D:\xingfa.txt", "r",encoding='utf-8')
out = a.read()
#print(out)
TypeList = out.split('\n')
#print(TypeList) lenth = len(TypeList)
print(lenth) number = 1
ju_1 = '{"index":{"_index":"xingfa","_id":'
ju_2 = '{"text_entry":"' # print(ju_1)
for x in TypeList: res_1 = ju_1 + str(number) + '}}'+'\n'
print(res_1)
a = open(r"D:\out.json", "a", encoding='UTF-8')
a.write(res_1) res_2 = ju_2 + x + '"}'+'\n'
print(res_2)
a = open(r"D:\out.json", "a", encoding='UTF-8')
a.write(res_2) a.close()
number+=1
3,执行后,输出的json内容为:
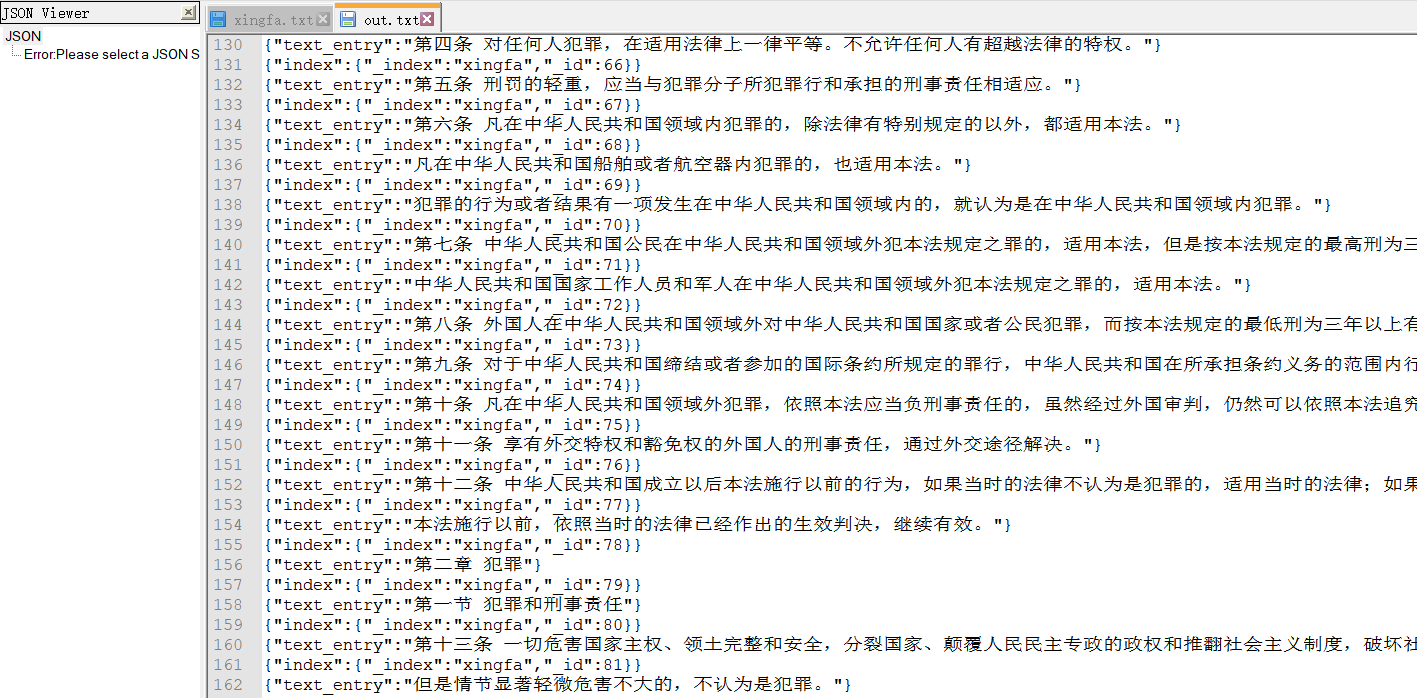
二、将数据导入ElasticSearch
1,我们要为即将导入的数据,建立映射。此操作可以在kibana或命令行完成。
PUT /xingfa
{
"mappings": {
"doc": {
"properties": {
"text_entry":{"type":"keyword"}
}
}
}
}
2,登录虚拟机,将之前生成的out.json文件,导入到对应ElasticSearch集群中。
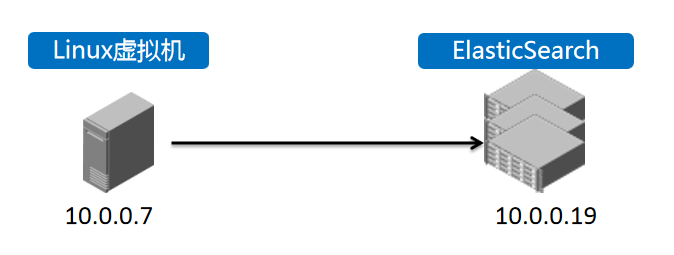
我们的ES组网情况如上图。
操作如下:
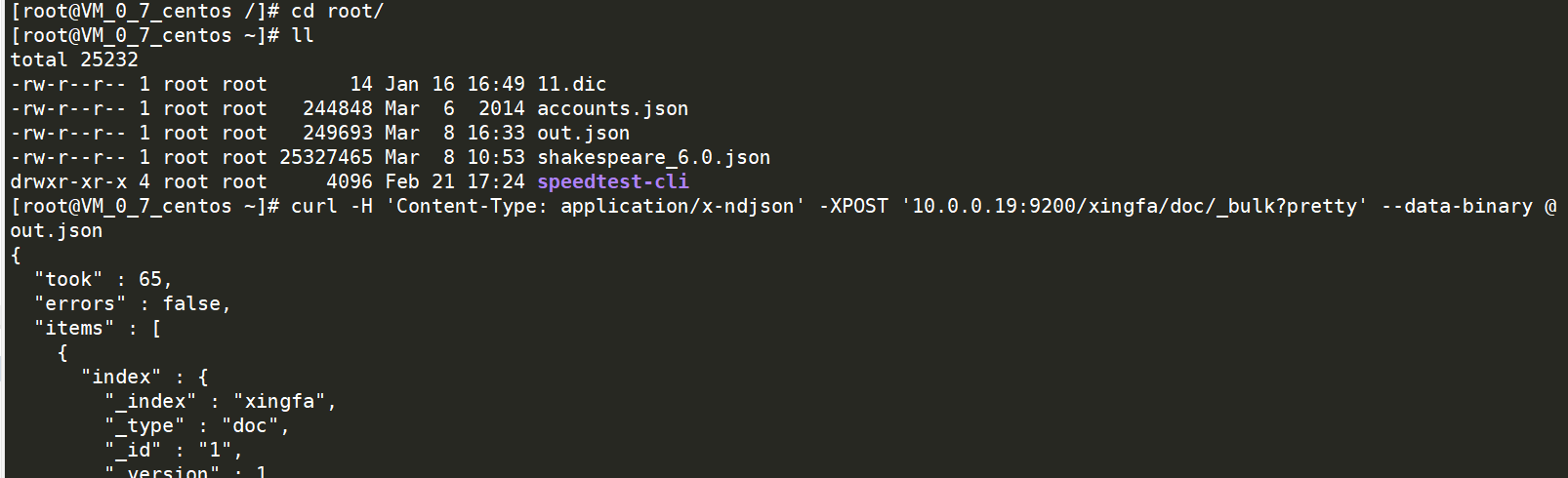
命令如下:
curl -H 'Content-Type: application/x-ndjson' -XPOST '10.0.0.19:9200/xingfa/doc/_bulk?pretty' --data-binary @out.json
等待命令执行完成后,即可登录kibana去查询对应的数据了。
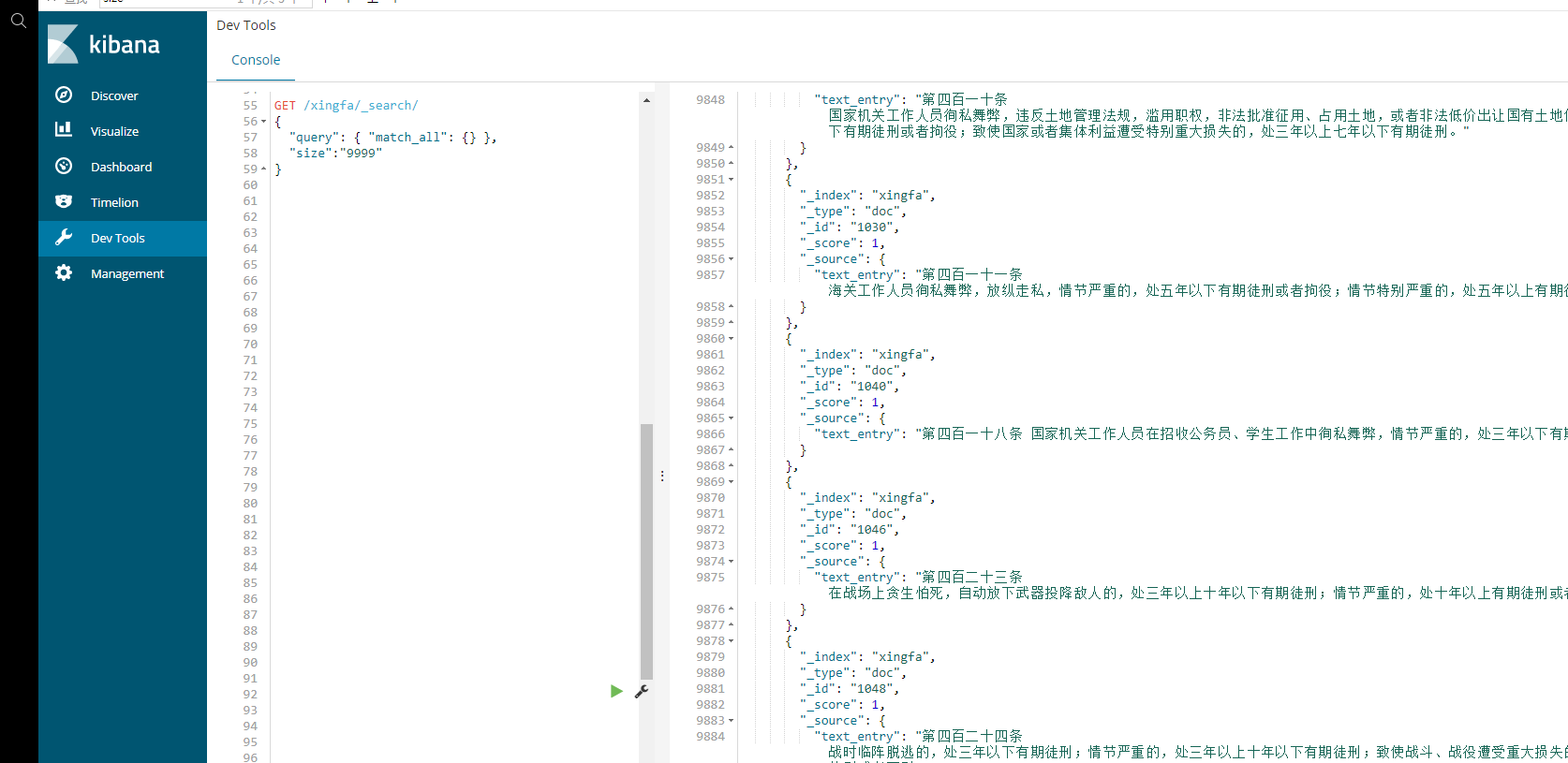
使用查询语句:
GET /xingfa/_search/
{
"query": { "match_all": {} },
"size":"" //此处设置为9999,主要原因是,不加参数的话,默认搜索结果仅显示部分,一般是5.
}
也可以直接在虚拟机命令行里,查询这个索引,确认数据是否已经完成上传。
使用查询语句:
curl -XGET "http://10.0.0.19:9200/xingfa/_search/" -H 'Content-Type: application/json' -d'
{
"query": {
"match_all": {}
},
"size": ""
}'
至此,完成数据导入。
【大数据实战】将普通文本文件导入ElasticSearch的更多相关文章
- SparkSQL大数据实战:揭开Join的神秘面纱
本文来自 网易云社区 . Join操作是数据库和大数据计算中的高级特性,大多数场景都需要进行复杂的Join操作,本文从原理层面介绍了SparkSQL支持的常见Join算法及其适用场景. Join背景介 ...
- 《OD大数据实战》HDFS入门实例
一.环境搭建 1. 下载安装配置 <OD大数据实战>Hadoop伪分布式环境搭建 2. Hadoop配置信息 1)${HADOOP_HOME}/libexec:存储hadoop的默认环境 ...
- 《OD大数据实战》驴妈妈旅游网大型离线数据电商分析平台
一.环境搭建 1. <OD大数据实战>Hadoop伪分布式环境搭建 2. <OD大数据实战>Hive环境搭建 3. <OD大数据实战>Sqoop入门实例 4. &l ...
- 《OD大数据实战》Hive环境搭建
一.搭建hadoop环境 <OD大数据实战>hadoop伪分布式环境搭建 二.Hive环境搭建 1. 准备安装文件 下载地址: http://archive.cloudera.com/cd ...
- 【大数据实战】Logstash采集->Kafka->ElasticSearch检索
1. Logstash概述 Logstash的官网地址为:https://www.elastic.co/cn/products/logstash,以下是官方对Logstash的描述. Logstash ...
- Azure HDInsight 和 Spark 大数据实战(一)
What is HDInsight? Microsoft Azure HDInsight 是基于 Hortonoworks Data Platform (HDP) 的 Hadoop 集群,包括Stor ...
- 大数据入门第二十五天——elasticsearch入门
一.概述 推荐路神的ES权威指南翻译:https://es.xiaoleilu.com/010_Intro/00_README.html 官网:https://www.elastic.co/cn/pr ...
- 《OD大数据实战》环境整理
一.关机后服务重新启动 1. 启动hadoop服务 sbin/hadoop-daemon.sh start namenode sbin/hadoop-daemon.sh start datanode ...
- 【若泽大数据实战第二天】Linux命令基础
Linux基本命令: 查看IP: ifconfig 或者 hostname -i(需要配置文件之后才可以使用) ipconfig(Windows) 关闭防火墙: Service iptables st ...
随机推荐
- Android之间传递数据包
在Android中 ,我们知道,两个activity之间通讯要用到Intent类,传递简单数据的方式我们也已经知道了.那么,如何在两个activity之间传递数据包呢,这就要用到我们的Bundle类了 ...
- PHPStorm 中配置 XDebug
1.下载 Xdebug ps : php版本和xdebug版本一定要相对应 如果不知道下载哪个版本,将phpinfo网页的源代码拷贝到https://xdebug.org/wizard.php,然后按 ...
- 安全之路 —— 利用SVCHost.exe系统服务实现后门自启动
简介 在Windows系统中有一个系统服务控制器,叫做SVCHost.exe,它可以用来管理系统的多组服务.它与普通的服务控制不同的是它采用dll导出的ServiceMain主函数实现服务运行,详细原 ...
- PyQt5--QCalendar
# -*- coding:utf-8 -*- ''' Created on Sep 20, 2018 @author: SaShuangYiBing Comment: ''' import sys f ...
- Android Bitmap Drawable byte[] InputStream 相互转换方法
用android处理图片的时候,由于得到的资源不一样,所以经常要在各种格式中相互转化,以下介绍了 Bitmap Drawable byte[] InputStream 之间的转换方法: import ...
- Scala学习之路 (六)Scala的类、对象、继承、特质
一.类 1.类的定义 scala语言中没有static成员存在,但是scala允许以某种方式去使用static成员这个就是伴生机制,所谓伴生,就是在语言层面上,把static成员和非static成员用 ...
- docker tomcat jvm 使用 visualVM监控
1. 建立基础镜像 FROM centos MAINTAINER fengjian <fengjian@senyint.com> ENV TZ "Asia/Shanghai&q ...
- Vue入门2
欢迎转载,转载请注明出处. 前言 学习本系列Vue知识,需要结合本系列的一些demo.你可以查看我的 Github 或者直接下载 ZIP包 . 建议学习本系列之前已经会一个其他的前端框架,了解计算属性 ...
- Drupal使用
首先到https://www.drupal.org/download去下载Drupal 更好的办法是使用composer,这个先放着,了解后再添加 然后将解压后的文件夹整个复制到设置的部署路径下,因为 ...
- JAVA框架 Spring junit整合单元测试
一.准备工作 1:Junit的需要的jar包: 2.spring的整合的jar包:spring-test-4.2.4.RELEASE.jar 3.代码实现 1) //导入整合的类,帮我们加载对应的配置 ...