ML 与 DM 工具 Weka 的使用
1、关于Weka
Weka 的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),是一款免费的、非商业化(与之对应的是SPSS公司商业数据挖掘产品--Clementine )的,基于JAVA环境下开源的机器学习(machine learning)以及数据挖掘(data mining)软件。它和它的源代码可在其官方网站下载。有趣的是,该软件的缩写WEKA也是新西兰独有的一种鸟名,而Weka的主要开发者同时恰好来自新西兰的the University of Waikato。
Weka 作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。
2、Weka 的安装
Weka 官网:http://www.cs.waikato.ac.nz/ml/weka/ 。
于网页左下角找到 download , 进入下载页面,支持 windows,mac os,linux等平台下的版本,此处以windows系统作为示例。目前最新版本是3-8-1。如果计算机没有安装 Java,可以选择带有jre的版本。下载后是一个exe的可执行文件,双击进行安装即可。安装完毕,打开启动weka的快捷方式,如果可以看到如下界面,即是安装成功。
进入下载页面,支持 windows,mac os,linux等平台下的版本,此处以windows系统作为示例。目前最新版本是3-8-1。如果计算机没有安装 Java,可以选择带有jre的版本。下载后是一个exe的可执行文件,双击进行安装即可。安装完毕,打开启动weka的快捷方式,如果可以看到如下界面,即是安装成功。
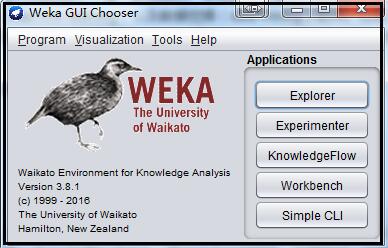
上图所示窗口共有4个Applications ,分别是:
1)Explorer(探索功能,用的最多)
用来进行数据实验、挖掘的环境,它提供了数据预处理,分类,聚类,关联规则,特征选择,数据可视化的功能。(An environment for exploring data with WEKA)
Preprocess (数据预处理)窗口:
2)Experimentor
用来进行实验,对不同学习方案进行数据测试的环境。(An environment for performing experiments and conducting statistical tests between learning schemes.)
3)KnowledgeFlow
功能和Explorer差不多,不过提供的接口不同,用户可以使用拖拽的方式去建立实验方案。另外,它支持增量学习。(This environment supports essentially the same functions as the Explorer but with a drag-and-drop interface. One advantage is that it supports incremental learning.)
4)SimpleCLI
简单的命令行界面。(Provides a simple command-line interface that allows direct execution of WEKA commands for operating systems that do not provide their own command line interface.)
3、Weka 数据格式
Weka 所处理的数据,其存储的格式是ARFF(Attribute-Relation File Format)文件,这是一种ASCII文本文件。Weka 所处理的数据集是一个二维的表格。表格里的一个横行称作一个实例(Instance),相当于统计学中的一个样本,或者数据库中的一条记录。 竖行称作一个属性(Attribute),相当于统计学中的一个变量,或者数据库中的一个字段。这样一个表格,或者叫数据集,在WEKA看来,呈现了属性之 间的一种关系(Relation)。
例子:Weka 自带的weather.numeric.arff 文件(在Weka安装目录下有:...\Weka-3-8\data)
% This is weather data ==》》"%" 开头的内容属于注释
% This is weather data
% This is weather data @relation weather ==》》关系声明 @attribute outlook {sunny, overcast, rainy} ==》》属性声明
@attribute temperature numeric
@attribute humidity numeric
@attribute windy {TRUE, FALSE}
@attribute play {yes, no} @data ==》》真实数据
sunny,85,85,FALSE,no
sunny,80,90,TRUE,no
overcast,83,86,FALSE,yes
rainy,70,96,FALSE,yes
rainy,68,80,FALSE,yes
rainy,65,70,TRUE,no
overcast,64,65,TRUE,yes
sunny,72,95,FALSE,no
sunny,69,70,FALSE,yes
rainy,75,80,FALSE,yes
sunny,75,70,TRUE,yes
overcast,72,90,TRUE,yes
overcast,81,75,FALSE,yes
rainy,71,91,TRUE,no
其中,数据信息需要注意:
①数据信息 :数据信息中“@data”标记独占一行,剩下的是各个实例的数据。
②数据缺失值:如果某个属性的值是缺失值(missing value),用问号“?”表示,且这个问号不能省略。例如:
@data
sunny,85,85,FALSE,no
?,78,90,?,yes
③稀疏数据 :有的时候数据集中含有大量的0值(比如购物篮分析),这个时候用稀疏格式的数据存贮更加省空间。
稀疏格式是针对数据信息中某个实例的表示而言,不需要修改ARFF文件的其它部分。看如下的数据:
@data
0, X, 0, Y, "class A"
0, 0, W, 0, "class B"
用稀疏格式表达的话就是
@data
{1 X, 3 Y, 4 "class A"}
{2 W, 4 "class B"}
每个实例用花括号括起来。实例中每一个非0的属性值用<index> <空格> <value>表示。<index>是属性的序号,从0开始计;<value>是属性值。属性值之间仍用逗号隔开。这里每个实例的数值必须按属性的顺序来写,如 {1 X, 3 Y, 4 "class A"},不能写成{3 Y, 1 X, 4 "class A"}。
注意在稀疏格式中没有注明的属性值不是缺失值,而是0值。若要表示缺失值必须显式的用问号表示出来。
【References】
1. https://baike.baidu.com/item/weka/10701215?fr=aladdin
2. http://blog.csdn.net/yangliuy/article/details/7589306
3. http://blog.51cto.com/baidutech/1033714
ML 与 DM 工具 Weka 的使用的更多相关文章
- 利用DM工具Weka进行数据挖掘(分类)的完整过程
利用DM工具Weka进行数据挖掘(分类)的完整过程:
- AI,DM,ML,PR的区别与联系
数据挖掘和机器学习的区别和联系,周志华有一篇很好的论述<机器学习与数据挖掘>可以帮助大家理解.数据挖掘受到很多学科领域的影响,其中数据库.机器学习.统计学无疑影响最大.简言之,对数据挖掘而 ...
- AI,DM,ML,PR的区别与联系
数据挖掘和机器学习的区别和联系,周志华有一篇很好的论述<机器学习与数据挖掘>可以帮助大家理解.数据挖掘受到很多学科领域的影响,其中数据库.机器学习.统计学无疑影响最大.简言之,对数据挖掘而 ...
- ml
基础篇: 1. 读书<Introduction to Data Mining>,这本书很浅显易懂,没有复杂高深的公式,很合适入门的人.另外可以用这本书做参考<Data Mining ...
- 数据挖掘系列(4)使用weka做关联规则挖掘
前面几篇介绍了关联规则的一些基本概念和两个基本算法,但实际在商业应用中,写算法反而比较少,理解数据,把握数据,利用工具才是重要的,前面的基础篇是对算法的理解,这篇将介绍开源利用数据挖掘工具weka进行 ...
- Weka 3: Data Mining Software in Java
官方网站: Weka 3: Data Mining Software in Java 相关使用方法博客 WEKA使用教程(经典教程转载) (实例数据:bank-data.csv) Weka初步一.二. ...
- ML笔记_机器学习基石01
1 定义 机器学习 (Machine Learning):improving some performance measure with experience computed from data ...
- Spark的MLlib和ML库的区别
机器学习库(MLlib)指南 MLlib是Spark的机器学习(ML)库.其目标是使实际的机器学习可扩展和容易.在高层次上,它提供了如下工具: ML算法:通用学习算法,如分类,回归,聚类和协同过滤 特 ...
- 【深度学习Deep Learning】资料大全
最近在学深度学习相关的东西,在网上搜集到了一些不错的资料,现在汇总一下: Free Online Books by Yoshua Bengio, Ian Goodfellow and Aaron C ...
随机推荐
- C# dataGridView根据数据调整列宽
//自适应列宽 this.dgvBaoming.AutoSizeColumnsMode = System.Windows.Forms.DataGridViewAutoSizeColumnsMode.A ...
- 前后端常用通讯方式-- ajax 、websocket
一.前后端常用通讯方式 1. ajax 浏览器发起请求,服务器返回数据,服务器不能主动返回数据,要实现实时数据交互只能是ajax轮询(让浏览器隔个几秒就发送一次请求,然后更新客户端显示.这种方式实际 ...
- 能使用html/css解决的问题就不要使用JS
为什么说能使用html/css解决的问题就不要使用JS呢?两个字,因为简单.简单就意味着更快的开发速度,更小的维护成本,同时往往具有更好的体验,下面介绍几个实例. 1. 导航高亮 导航高亮是一种很常见 ...
- printf回到上一行开头以及回到本行开头的方法
回到上一行开头 #include <stdio.h> #include <unistd.h> int main(void) { ; ){ printf("%d\n&q ...
- 【spring cloud】spring cloud 使用feign调用,1.fallback熔断器不起作用,2.启动报错Caused by: java.lang.ClassNotFoundException: com.netflix.hystrix.contrib.javanica.aop.aspectj.Hystri解决
示例GitHub源码地址:https://github.com/AngelSXD/springcloud 1.首先使用feign调用,需要配置熔断器 2.配置熔断器需要将熔断器注入Bean,熔断器类上 ...
- weblogic打补丁,bsu方法
刚装了10.3.6版本的weblogic,想把版本补丁到10.3.6.0.12 我用的系统是windows 8.1 ,呵呵 查看版本 执行java weblogic.version WebLogic ...
- ExtJS4.2:自定义主题 入门
背景 用过 ExtJs 的朋友都有一种趋势:审美疲劳,好在 Ext4.1 之后的版本提供了快速自定义主题的功能,本文的内容主要来自:http://docs.sencha.com/extjs/4.2.2 ...
- Android RadioButton设置选中时文字和背景颜色同时改变
主要应用在购物车,像淘宝的那样,点击以后弹出一个选择种类颜色这样的popuwindow以后,然后这个选择种类的地方要用到类似这个玩意儿. 搜了一下,效果和这个文章一致.转了. 原文地址:http:// ...
- Spring核心之IoC——依赖注入
在J2EE开发平台中,Spring是一种优秀的轻量级企业应用解决方案.Spring倡导一切从实际出发,它的核心技术就是IOC(控制反转)和AOP(面向切面编程)技术.本文用的Spring版本为spri ...
- android获取周围AP信息(下)
疑问: 在上一篇中,还有一个问题未解决:WifiManager的startscan() 方法是立即返回的,也就是说这个方法会调用一个扫描wifi信号的线程,那么这个扫描什么时候结束呢?我们又该什么时候 ...