论文阅读 | FoveaBox: Beyond Anchor-based Object Detector
论文阅读——FoveaBox: Beyond Anchor-based Object Detector
概述
这是一篇ArXiv 2019的文章,作者提出了一种新的anchor-free的目标检测框架FoveaBox,直接学习目标存在的可能性(预测类别敏感的语义map)和bbox的坐标(为可能存在目标的每个位置生成无类别的bbox)。该算法的单模型(基于ResNeXt-101-FPN )在COCO数据集上的AP达到42.1%。代码尚未开源。
介绍
anchor弊端:额外的超参数设计很复杂;设计的anchor泛化能力差;密集的anchor采样使得正负样本严重失衡。
受人眼的启发,视觉区域(目标)的中心有着最高的视觉灵敏度。FoveaBox联合预测对象的中心区域可能存在的位置以及每个有效位置的边界框。
FoveaBox
FoveaBox的框架:
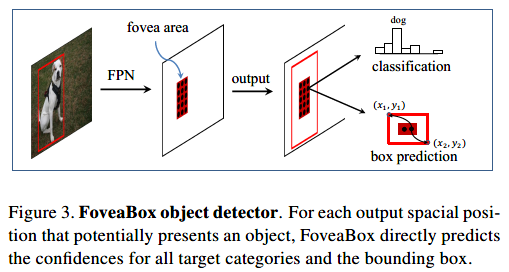
FoveaBox包括一个backbone和两个子网。第一个子网对主干网的输出执行每个像素的分类,第二个子网预测相应位置的bbox。
FPN的使用:
每层金字塔用于检测不同大小的目标,论文中作者设计的金字塔{Pl},其中l=3,4,5,6,7,Pl的分辨率是输入的1/2^l。金字塔所有层的通道数都是256。

每层特征金字塔的box的有效尺度范围:
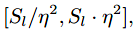

S0取16,η取2.
Object Fovea
从gt box到特征金字塔Pl的映射:
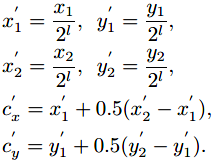
正样本区域(fovea):

正样本区域相比于原始区域有一定程度的缩小。σ1是收缩因子(文中取0.3)。同样使用上面的公式,因子记为σ2(文中取0.4),产生负样本区域。训练时类别损失采用focal loss。
Box Prediction
位置回归则是学习一个变换:

其中z=sqrt(Sl)是归一化因子,将输出空间投影到以1为中心的空间,使学习过程更稳定。函数首先将feature map的坐标(x,y)映射到输入图像,然后计算归一化的偏移,最后正则化到log空间。回归损失采用Smooth L1损失。
优化
4GPUs,SGD,8 imgs/minibatch
训练细节:270k次迭代(180k前:lr=0.005,180k-240k:lr=0.0005,240k后:lr=5e-5)
使用权值衰减(0.0001),momentum(0.9)
ignore区域的location不参与类别训练,但参与回归训练(标注为对应的位置目标)。
推理
置信度阈值:0.05,NMS阈值:0.5,没有使用bbox voting、Soft-NMS、测试阶段图像扩增等策略。
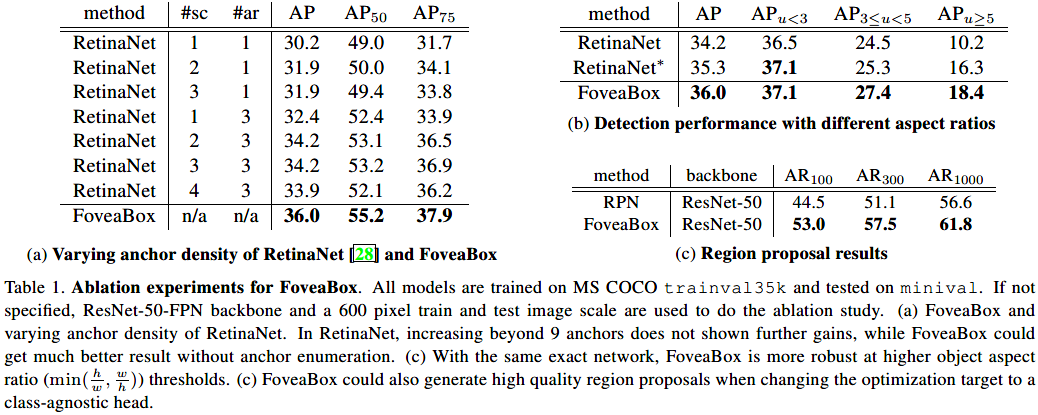
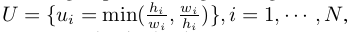
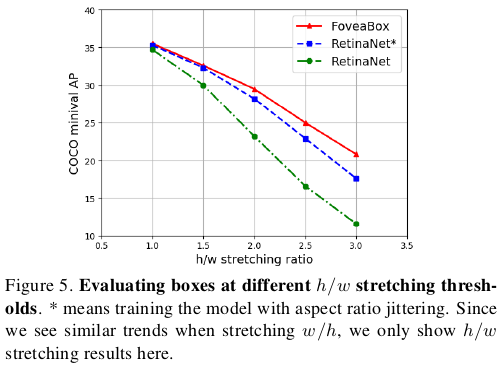
RetinaNet与FoveaBox检测对比:

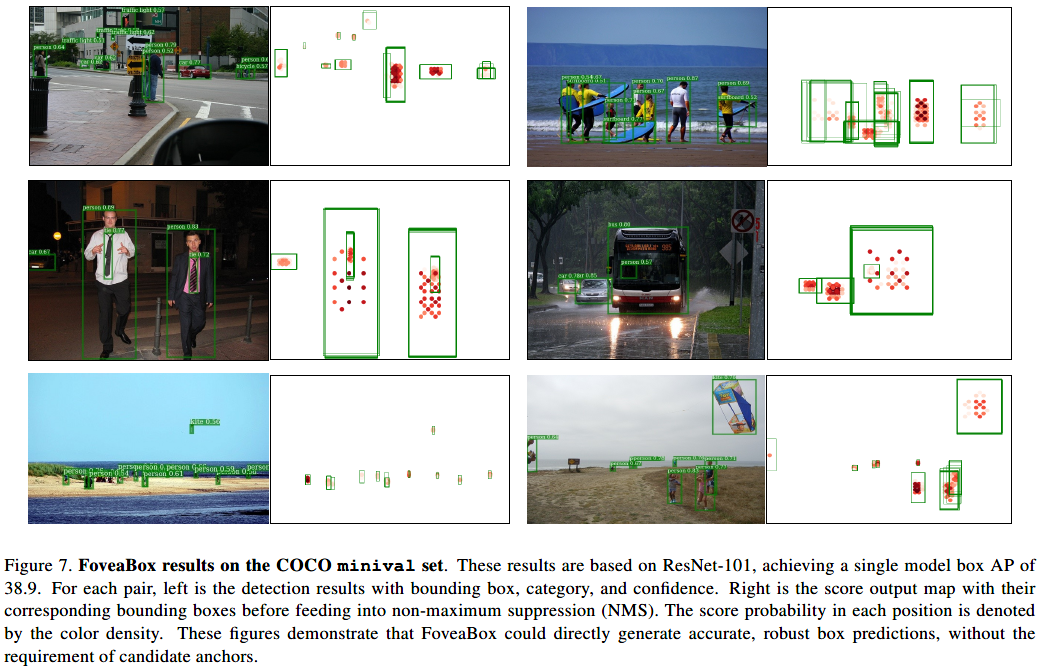
FoveaBox检测结果:
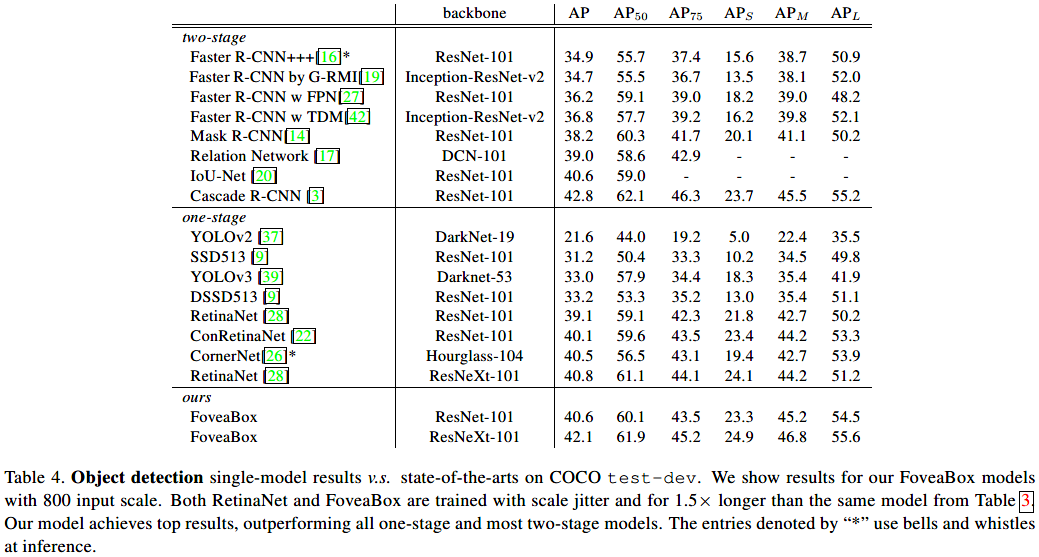
SOTA对比:
与FSAF的对比:
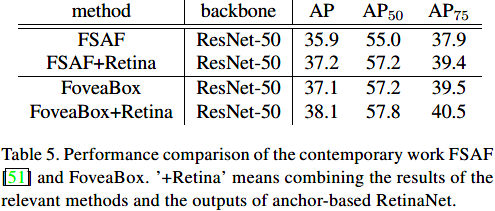
总的来说,这是一篇利用语义分割的思想来做目标检测的文章,通过定义fovea区域(也就是正样本区域)来限制类别学习和预测的大致范围,所以没有出现类似于FCOS算法中远离目标中心的位置会产生大量低置信度bbox的情况。
论文阅读 | FoveaBox: Beyond Anchor-based Object Detector的更多相关文章
- 论文阅读 | FCOS: Fully Convolutional One-Stage Object Detection
论文阅读——FCOS: Fully Convolutional One-Stage Object Detection 概述 目前anchor-free大热,从DenseBoxes到CornerNet. ...
- 论文阅读之 DECOLOR: Moving Object Detection by Detecting Contiguous Outliers in the Low-Rank Representation
DECOLOR: Moving Object Detection by Detecting Contiguous Outliers in the Low-Rank Representation Xia ...
- SSD: Single Shot MultiBox Detector论文阅读摘要
论文链接: https://arxiv.org/pdf/1512.02325.pdf 代码下载: https://github.com/weiliu89/caffe/tree/ssd Abstract ...
- [论文理解] FoveaBox: Beyond Anchor-based Object Detector
FoveaBox: Beyond Anchor-based Object Detector Intro 本文是一篇one-stage anchor free的目标检测文章,大体检测思路为,网络分两路, ...
- 论文阅读:Prominent Object Detection and Recognition: A Saliency-based Pipeline
论文阅读:Prominent Object Detection and Recognition: A Saliency-based Pipeline 如上图所示,本文旨在解决一个问题:给定一张图像, ...
- YOLO: You Only Look Once论文阅读摘要
论文链接: https://arxiv.org/pdf/1506.02640.pdf 代码下载: https://github.com/gliese581gg/YOLO_tensorflow Abst ...
- YOLO 论文阅读
YOLO(You Only Look Once)是一个流行的目标检测方法,和Faster RCNN等state of the art方法比起来,主打检测速度快.截止到目前为止(2017年2月初),YO ...
- 新文预览 | IoU-aware Single-stage Object Detector for Accurate Localization
论文基于RetinaNet提出了IoU-aware sinage-stage目标检测算法,该算法在regression branch接入IoU predictor head并通过加权分类置信度和IoU ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
随机推荐
- 下拉菜单--JavaScript触发方法
1. $(function(){ $(".dropdown-toggle").one("click",function(){ $(this).dropdown( ...
- [GO]revoer的应用
error的函数只是用来报一些低等级的错误,panic是报那些会导致程序崩溃的错误,但是会有一个问题就是panic也会导致程序中断 ,如果我们需要程序在报错之后继续运行并报出错误的信息 就需要使用到r ...
- 通过cat方式生成yum源
cat >> /etc/yum.repos.d/centos7.repo << EOF[test-iso7]name=CentOS- - Mediabaseurl=http:/ ...
- Dubbo服务启动依赖检查
dubbo 官方文档地址:http://dubbo.io/User+Guide-zh.htm 项目中存在服务之间存在循环依赖,启动时总是报错,通过修改启动检查check=false解决,下面是dubb ...
- 三)EasyUI layout
参考文档 http://www.jeasyui.com/documentation/layout.php
- 我的BootStrap学习笔记
1.全局样式里面: 1.container:版心 2.col-xx-xx:栅格布局 3.btn btn-default: 按钮,默认按钮样式 4..pull-left pull-right cle ...
- javascript高级程序设计读书笔记----严格模式
ECMAScript5最早引入“严格模式". 使用 "use strict"开启严格模式 function test(){ "use strict"; ...
- Delphi 10.1.2 berlin开发跨平台APP的几点经验
1.ios不允许app有退出功能,所以不能调用Application.Terminate. 2.info.plist文件的自定义:info.plist文件是由info.plist.TemplateiO ...
- Lazy<T> 提供对延迟初始化的支持
延迟初始化 就是在第一次使用的时候在 进行类的初始化 public class Student { public Student() { this.Name = "DefaultName& ...
- 20145218张晓涵_Web基础
20145218张晓涵_Web基础 基础知识 Apache一个开放源码的网页服务器,可以在大多数计算机操作系统中运行,由于其多平台和安全性被广泛使用,是最流行的Web服务器端软件之一.它快速.可靠并且 ...