python成长笔记
正则表达式
1. 择一匹配:管道符号(|),表示“从多个模式中选择其一”。例:at|home à at、home
2. 点号匹配除了换行符以外的任何字符
3. 边界匹配:\b匹配一个单词的边界;\B匹配在一个单词中间,即不是单词边界。
4. 字符集:匹配方括号中包含的任何字符。只适用于单字符的情况。例:[ab] à a、b
5. 星号(*)匹配其左边出现零次或多次
加号(+)匹配一次或多次出现
问号(?)匹配零次或一次出现
6. 字符集特殊字符:\d表示匹配任何十进制数字
\w表示全部字母的字符集
\s表示空格字符
注:特殊字符的大写表示不匹配,例:\D表示任何非十进制数字
7. 圆括号指定分组和匹配子组,例:(\w+)-(\d+)
8. 匹配对象:group()和groups().
9. group():要么返回整个匹配对象,要么根据要求返回特定子组;groups()仅返回一个包含唯一或全部子组的元组。
10.match()和search()区别:match()从字符串的起始部分开始匹配;search()不但会搜索起始部分,而且严格地对字符串从左到右搜索。
11.findall()查询字符串中某个正则表达式模式全部的非重复出现情况,返回的是一个列表。
12.finditer()是与findall()类似但更节省内存的实体。区别:返回的是一个迭代器。
13.搜索与替换:sub()和subn()
都是将某字符串中所有匹配正则表达式的部分进行某种形式的替换。区别:subn()还返回一个表示替换的总数。
函数
1. *args 会把多传入的参数变成一个元组形式
2. **kwargs 会把多传入的参数变成一个dict形式
3. 参数:
普通参数:严格按照顺序,将实参传给形参
默认参数:必须放置在参数列表的最后
指定参数:将参数赋值给指定的形参
动态参数:* 默认传入的参数,全部放置在元组中
** 默认传入的参数,全部放置在字典中
万能参数: *args, ** kwargs
4. Python中,函数的参数传递,是引用,不是复制。
5. 变量:
全局变量,所有作用域都可读。
对全局变量进行重新赋值,需要global,如:global name
特殊,对列表、字典,可修改,但不可重新赋值。
全局变量统一大写。
6. 三元运算(三目运算) 对 if else的简写
例:name = ‘alex’ if 1==1 else ‘SB’
7. 闭包:
闭包是一个函数,并且这个函数具有以下特点:
- 定义在另外一个函数里面(嵌套函数)
- 引用其所在函数环境的自由变量
例:关于一个抛物线的函数
#!/usr/bin/env python
# coding:utf-8 def parabola(a, b, c):
def para(x):
return a*x**2 + b*x + c
return para p = parabola(2, 3, 4)
print(p(5))
内置函数
1. abs(): 绝对值
2. all(): 所有为真,才为真
3. any(): 又要有真就为真
4. ascii(): 自动执行对象的__repr__方法
5. bytes(): 字符串转换成字节类型
补充:字符编码
对utf-8,一个汉字占三个字节
对gbk,一个汉字占两个字节
n = bytes('李杰',encoding='utf-8/gbk')
bytes(要转换的字符串,编码类型)
6. str(): 字节转换成字符串
str(bytes('李杰',encoding='utf-8'),encoding='utf-8')
7. map(): map(func,seq) 例:map(lambda x: x+3,[1,2,3,4]) à [4,5,6,7]
8. reduce(): 横着逐个元素进行运算。
python3中,from functools import reduce 导入
例:计算1*2*3*4*5*6*7
>> reduce(lambda x,y:x*y , [1,2,3,4,5,6,7])
>> 5040
9. zip(): zip()的参数是可迭代对象。
例1:
>>> colors = ["red", "green", "blue"]
>>> values = [234, 12, 89, 65]
>>> for col, val in zip(colors, values):
... print ((col, val))
...
('red', 234)
('green', 12)
('blue', 89)
例2:
>>> a = [1, 2, 3, 4, 5]
>>> b = [2, 2, 9, 0, 9]
>>>list(map(lambda pair: max(pair), zip(a, b)))
[2, 2, 9, 4, 9]
说明:zip()可以同时迭代多个序列,其创建出的结果是一个迭代器。通常用在需要将不同的数据配对在一起时。
10. iter(): 可以选择性接受一个无参的可调用对象以及一个哨兵(结束)值作为输入。
import sys
f = open(‘/etc/passwd’)
for chunk in iter(lambda: f.read(10), ‘’):
n = sys.stdout,write(chunk)
文件操作
1. x: 表示文件存在,报错,文件不存在,创建并写内容(python3,x中新增)
2. a: 表追加
3. 自动关闭文件
with open(‘db.txt’,’r’) as f:
pass
4. 如果打开文件模式,无b,则 read按照字符
5. read(): 无参数,读全部,有参数[有b,按字节;无b,按字符]
6. tell(): 当前指针所在的位置,永远是字节单位
7. seek(): 调整当前指针的位置,以字节为单位
8. write(): 从当前指针位置向后覆盖
9. fileno(): 文件描述符
10.flush(): 将缓冲区文件强制写入硬盘
11. truncate(): 根据指针位置进行截断,且指针后的内容清空
12. 将多个映射合并为单个映射:collections模块中的ChainMap类。ChainMap只是简单地维护一个记录底层映射关系的列表。
from collections import ChainMap
a = {'x': 1 , 'z' : 3}
b = {'y': 2 , 'z' : 4} c = ChainMap(a,b)
print(c['x']) #output 1 (from a)
print(c['y']) #output 2 (from b)
print(c['z']) #output 3 (from a) >> del c['y']
...
KeyError: "Key not found in the first mapping: 'y'"
说明:修改映射的操作总是会作用在列出的第一个映射结构上。
ChainMap与update()区别:
>>> a = {'x': 1 , 'z' : 3}
>>> b = {'y': 2 , 'z' : 4}
>>> merged = dict(b)
>>> merged.update(a)
>>> merged
{'x': 1, 'y': 2, 'z': 3}
#修改属性值后,不变
>>> a['x'] = 32
>>> merged
{'x': 1, 'y': 2, 'z': 3}
字典中update()合并
>>> from collections import ChainMap
>>> a = {'x': 1 , 'z' : 3}
>>> b = {'y': 2 , 'z' : 4}
>>> c = ChainMap(a,b) >>> c
ChainMap({'x': 1, 'z': 3}, {'y': 2, 'z': 4})
#修改属性值,
>>> c['x'] = 32
>>> c
ChainMap({'x': 32, 'z': 3}, {'y': 2, 'z': 4})
ChainMap合并
总结:ChainMap使用的是原始的字典,而字典的update()方法并不是,修改其中一个字典,会破坏原始数据。
13. I/O系统是以一系列的层次来构建的。
>>> f = open('sample.txt','w')
>>> f
<_io.TextIOWrapper name='sample.txt' mode='w' encoding='cp936'> #文本处理层,负责编码和解码Unicode
>>> f.buffer
<_io.BufferedWriter name='sample.txt'> # 缓冲I/O层,负责处理二进制数据
>>> f.buffer.raw
<_io.FileIO name='sample.txt' mode='wb' closefd=True> # 原始文件,代表着操作系统底层的文件描述符
detach()方法将最上层的io.TextIOWrapper层同文件分离开来,并将下一层次(io.BufferWriter)返回,在这之后,最上层将不再起作用。
>>> import io
>>> f = open('sample.txt','w')
>>> f
<_io.TextIOWrapper name='sample.txt' mode='w' encoding='c
>>> b = f.detach()
>>> b
<_io.BufferedWriter name='sample.txt'>
>>> f.write('hello')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: underlying buffer has been detached # 一旦分离,就可以为返回的结果添加一个新的最上层。
>>> f = io.TextIOWrapper(b,encoding='latin-1')
>>> f
<_io.TextIOWrapper name='sample.txt' encoding='latin-1'>
14. 闭包
闭包就是根据不同的配置信息得到不同的结果。闭包(Closure)是引用了自由变量的函数。这个被引用的自由变量将和这个函数一同存在,即使已经离开了创造它的环境也不例外。所以,有另一种说法认为闭包是由函数和与其相关的引用环境组合而成的实体。
实例一:
def make_adder(addend):
def adder(augend):
return augend + addend
return adder p = make_adder(23)
q = make_adder(44) print p(100)
print q(100) #Output
123
144
分析:
make_adder是一个函数,包括一个参数addend,比较特殊的地方是这个函数里面又定义了一个新函数,这个新函数里面的一个变量正好是外部make_adder的参数.也就是说,外部传递过来的addend参数已经和adder函数绑定到一起了,形成了一个新函数,我们可以把addend看做新函数的一个配置信息,配置信息不同,函数的功能就不一样了,也就是能得到定制之后的函数.
再看看运行结果,我们发现,虽然p和q都是make_adder生成的,但是因为配置参数不同,后面再执行相同参数的函数后得到了不同的结果.这就是闭包.
实例二:
def hellocounter (name):
count=0
def counter():
nonlocal count #nonlocal关键字 --> 告诉Python程序count变量是在外部定义的
count+=1
print 'Hello,',name,',',str(count[0])+' access!'
return counter hello = hellocounter(' ysisl')
hello()
hello()
hello() #输出
Hello, ysisl , 1 access!
Hello, ysisl , 2 access!
Hello, ysisl , 3 access!
字符串格式化
Format方式
[[fill]align][sign][#][0][width][,][.precision][type]
fill 【可选】空白处填充的字符
align 【可选】对齐方式(需配合width使用)
<,内容左对齐
>,内容右对齐(默认)
=,内容右对齐,将符号放置在填充字符的左侧,且只对数字类型有效。 即使:符号+填充物+数字
^,内容居中
sign 【可选】有无符号数字
+,正号加正,负号加负;
-,正号不变,负号加负;
空格 ,正号空格,负号加负;
# 【可选】对于二进制、八进制、十六进制,如果加上#,会显示 0b/0o/0x,否则不显示
【可选】为数字添加分隔符,如:1,000,000
width 【可选】格式化位所占宽度
.precision 【可选】小数位保留精度
type 【可选】格式化类型
传入” 字符串类型 “的参数
s,格式化字符串类型数据
空白,未指定类型,则默认是None,同s
传入“ 整数类型 ”的参数
b,将10进制整数自动转换成2进制表示然后格式化
c,将10进制整数自动转换为其对应的unicode字符
d,十进制整数
o,将10进制整数自动转换成8进制表示然后格式化;
x,将10进制整数自动转换成16进制表示然后格式化(小写x)
X,将10进制整数自动转换成16进制表示然后格式化(大写X)
传入“ 浮点型或小数类型 ”的参数
e, 转换为科学计数法(小写e)表示,然后格式化;
E, 转换为科学计数法(大写E)表示,然后格式化;
f , 转换为浮点型(默认小数点后保留6位)表示,然后格式化;
F, 转换为浮点型(默认小数点后保留6位)表示,然后格式化;
g, 自动在e和f中切换
G, 自动在E和F中切换
%,显示百分比(默认显示小数点后6位)
反射
1. hasattr , getattr , delattr , setattr
2. 反射:利用字符串的形式去对象(模块)中操作(寻找/检查/删除/设置)成员。
3. obj = __import__(“commons”) #导入commons模块,并命名为obj
4. obj = __import__(“lib.login”, fromlist=True) #fromlist=True表示将lib下的模块都导入,否则只导入lib。
常用模块
1. 模块中特殊变量:__doc__ __cached__ __file__ __name__ __package__
__doc__ : 获取注释
__cached__: 获取.pyc(字节码)的路径
__file__: 获取当前py文件的执行路径(相对路径)
扩展:os.path.abspath(): 获取文件的绝对路径。
os.path.dirname(): 获取当前文件的上一级目录
例:
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
__package__: 获取当前文件所在的包
__name__ : 只有执行当前文件时候,当前文件的特殊变量__name__ == ‘__main__’
2. \r: 表示指针移到行首
例:进度条实例
def view_bar(num,total):
rate = num / total
rate_num = int(rate * 100)
r = '\r%s>%d%%'%("="*num,rate_num)
sys.stdout.write(r)
sys.stdout.flush()
def main():
for i in range(0,101):
view_bar(i,100)
time.sleep(0.1)
3. os模块
用于提供系统级别的操作:
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dir1/dir2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","new") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 用于分割文件路径的字符串
os.name 字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
4. time & datetime模块
#_*_coding:utf-8_*_
2 __author__ = 'Alex Li'
3
4 import time
5
6
7 # print(time.clock()) #返回处理器时间,3.3开始已废弃 , 改成了time.process_time()测量处理器运算时间,不包括sleep时间,不稳定,mac上测不出来
8 # print(time.altzone) #返回与utc时间的时间差,以秒计算\
9 # print(time.asctime()) #返回时间格式"Fri Aug 19 11:14:16 2016",
10 # print(time.localtime()) #返回本地时间 的struct time对象格式
11 # print(time.gmtime(time.time()-800000)) #返回utc时间的struc时间对象格式
12
13 # print(time.asctime(time.localtime())) #返回时间格式"Fri Aug 19 11:14:16 2016",
14 #print(time.ctime()) #返回Fri Aug 19 12:38:29 2016 格式, 同上
15
16
17
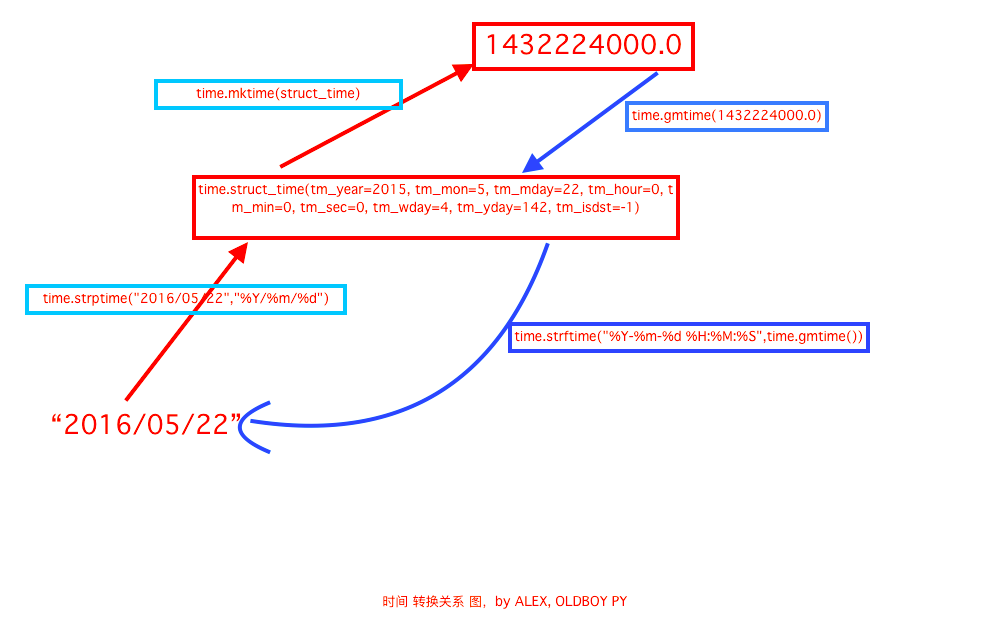
18 # 日期字符串 转成 时间戳
19 # string_2_struct = time.strptime("2016/05/22","%Y/%m/%d") #将 日期字符串 转成 struct时间对象格式
20 # print(string_2_struct)
21 # #
22 # struct_2_stamp = time.mktime(string_2_struct) #将struct时间对象转成时间戳
23 # print(struct_2_stamp)
24
25
26
27 #将时间戳转为字符串格式
28 # print(time.gmtime(time.time()-86640)) #将utc时间戳转换成struct_time格式
29 # print(time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime()) ) #将utc struct_time格式转成指定的字符串格式
30
31
32
33
34
35 #时间加减
36 import datetime
37
38 # print(datetime.datetime.now()) #返回 2016-08-19 12:47:03.941925
39 #print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2016-08-19
40 # print(datetime.datetime.now() )
41 # print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天
42 # print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天
43 # print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时
44 # print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分
45
46
47 #
48 # c_time = datetime.datetime.now()
49 # print(c_time.replace(minute=3,hour=2)) #时间替换
| Directive | Meaning | Notes |
|---|---|---|
%a |
Locale’s abbreviated weekday name. | |
%A |
Locale’s full weekday name. | |
%b |
Locale’s abbreviated month name. | |
%B |
Locale’s full month name. | |
%c |
Locale’s appropriate date and time representation. | |
%d |
Day of the month as a decimal number [01,31]. | |
%H |
Hour (24-hour clock) as a decimal number [00,23]. | |
%I |
Hour (12-hour clock) as a decimal number [01,12]. | |
%j |
Day of the year as a decimal number [001,366]. | |
%m |
Month as a decimal number [01,12]. | |
%M |
Minute as a decimal number [00,59]. | |
%p |
Locale’s equivalent of either AM or PM. | (1) |
%S |
Second as a decimal number [00,61]. | (2) |
%U |
Week number of the year (Sunday as the first day of the week) as a decimal number [00,53]. All days in a new year preceding the first Sunday are considered to be in week 0. | (3) |
%w |
Weekday as a decimal number [0(Sunday),6]. | |
%W |
Week number of the year (Monday as the first day of the week) as a decimal number [00,53]. All days in a new year preceding the first Monday are considered to be in week 0. | (3) |
%x |
Locale’s appropriate date representation. | |
%X |
Locale’s appropriate time representation. | |
%y |
Year without century as a decimal number [00,99]. | |
%Y |
Year with century as a decimal number. | |
%z |
Time zone offset indicating a positive or negative time difference from UTC/GMT of the form +HHMM or -HHMM, where H represents decimal hour digits and M represents decimal minute digits [-23:59, +23:59]. | |
%Z |
Time zone name (no characters if no time zone exists). | |
%% |
A literal '%' character. |
5.random模块
随机数
import random
print random.random()
print random.randint(1,2)
print random.randrange(1,10)
生成随机验证码
import random
checkcode = ''
for i in range(4):
current = random.randrange(0,4)
if current != i:
temp = chr(random.randint(65,90))
else:
temp = random.randint(0,9)
checkcode += str(temp)
print checkcode
6. hashlib模块
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import hashlib
obj = hashlib.md5(bytes('dkjhajgdsa',encoding='utf-8'))
obj.update(bytes('123',encoding='utf-8'))
ret = obj.hexdigest()
print(ret)
7.logging模块
很多程序都有记录日志的需求,并且日志中包含的信息即有正常的程序访问日志,还可能有错误、警告等信息输出,python的logging模块提供了标准的日志接口,你可以通过它存储各种格式的日志,logging的日志可以分为 debug(), info(), warning(), error() and critical() 5个级别,下面我们看一下怎么用。
最简单用法
import logging
logging.warning("user [alex] attempted wrong password more than 3 times")
logging.critical("server is down")
#输出
WARNING:root:user [alex] attempted wrong password more than 3 times
CRITICAL:root:server is down
看一下这几个日志级别分别代表什么意思
| Level | When it’s used |
|---|---|
DEBUG |
Detailed information, typically of interest only when diagnosing problems. |
INFO |
Confirmation that things are working as expected. |
WARNING |
An indication that something unexpected happened, or indicative of some problem in the near future (e.g. ‘disk space low’). The software is still working as expected. |
ERROR |
Due to a more serious problem, the software has not been able to perform some function. |
CRITICAL |
A serious error, indicating that the program itself may be unable to continue running. |
如果想把日志写到文件里,也很简单
import logging logging.basicConfig(filename='example.log',level=logging.INFO)
logging.debug('This message should go to the log file')
logging.info('So should this')
logging.warning('And this, too')
其中下面这句中的level=loggin.INFO意思是,把日志纪录级别设置为INFO,也就是说,只有比日志是INFO或比INFO级别更高的日志才会被纪录到文件里,在这个例子, 第一条日志是不会被纪录的,如果希望纪录debug的日志,那把日志级别改成DEBUG就行了。
logging.basicConfig(filename='example.log',level=logging.INFO)
感觉上面的日志格式忘记加上时间啦,日志不知道时间怎么行呢,下面就来加上!
import logging
logging.basicConfig(format='%(asctime)s %(message)s', datefmt='%m/%d/%Y %I:%M:%S %p')
logging.warning('is when this event was logged.') #输出
12/12/2010 11:46:36 AM is when this event was logged.
日志格式
|
%(name)s |
Logger的名字 |
|
%(levelno)s |
数字形式的日志级别 |
|
%(levelname)s |
文本形式的日志级别 |
|
%(pathname)s |
调用日志输出函数的模块的完整路径名,可能没有 |
|
%(filename)s |
调用日志输出函数的模块的文件名 |
|
%(module)s |
调用日志输出函数的模块名 |
|
%(funcName)s |
调用日志输出函数的函数名 |
|
%(lineno)d |
调用日志输出函数的语句所在的代码行 |
|
%(created)f |
当前时间,用UNIX标准的表示时间的浮 点数表示 |
|
%(relativeCreated)d |
输出日志信息时的,自Logger创建以 来的毫秒数 |
|
%(asctime)s |
字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 |
|
%(thread)d |
线程ID。可能没有 |
|
%(threadName)s |
线程名。可能没有 |
|
%(process)d |
进程ID。可能没有 |
|
%(message)s |
用户输出的消息 |
如果想同时把log打印在屏幕和文件日志里,就需要了解一点复杂的知识 了
Python 使用logging模块记录日志涉及四个主要类,使用官方文档中的概括最为合适:
logger提供了应用程序可以直接使用的接口;
handler将(logger创建的)日志记录发送到合适的目的输出;
filter提供了细度设备来决定输出哪条日志记录;
formatter决定日志记录的最终输出格式。
logger
每个程序在输出信息之前都要获得一个Logger。Logger通常对应了程序的模块名,比如聊天工具的图形界面模块可以这样获得它的Logger:
LOG=logging.getLogger(”chat.gui”)
而核心模块可以这样:
LOG=logging.getLogger(”chat.kernel”)
Logger.setLevel(lel):指定最低的日志级别,低于lel的级别将被忽略。debug是最低的内置级别,critical为最高
Logger.addFilter(filt)、Logger.removeFilter(filt):添加或删除指定的filter
Logger.addHandler(hdlr)、Logger.removeHandler(hdlr):增加或删除指定的handler
Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical():可以设置的日志级别
handler
handler对象负责发送相关的信息到指定目的地。Python的日志系统有多种Handler可以使用。有些Handler可以把信息输出到控制台,有些Logger可以把信息输出到文件,还有些 Handler可以把信息发送到网络上。如果觉得不够用,还可以编写自己的Handler。可以通过addHandler()方法添加多个多handler
Handler.setLevel(lel):指定被处理的信息级别,低于lel级别的信息将被忽略
Handler.setFormatter():给这个handler选择一个格式
Handler.addFilter(filt)、Handler.removeFilter(filt):新增或删除一个filter对象
每个Logger可以附加多个Handler。接下来我们就来介绍一些常用的Handler:
1) logging.StreamHandler
使用这个Handler可以向类似与sys.stdout或者sys.stderr的任何文件对象(file object)输出信息。它的构造函数是:
StreamHandler([strm])
其中strm参数是一个文件对象。默认是sys.stderr
2) logging.FileHandler
和StreamHandler类似,用于向一个文件输出日志信息。不过FileHandler会帮你打开这个文件。它的构造函数是:
FileHandler(filename[,mode])
filename是文件名,必须指定一个文件名。
mode是文件的打开方式。参见Python内置函数open()的用法。默认是’a',即添加到文件末尾。
3) logging.handlers.RotatingFileHandler
这个Handler类似于上面的FileHandler,但是它可以管理文件大小。当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建 一个新的同名日志文件继续输出。比如日志文件是chat.log。当chat.log达到指定的大小之后,RotatingFileHandler自动把 文件改名为chat.log.1。不过,如果chat.log.1已经存在,会先把chat.log.1重命名为chat.log.2。。。最后重新创建 chat.log,继续输出日志信息。它的构造函数是:
RotatingFileHandler( filename[, mode[, maxBytes[, backupCount]]])
其中filename和mode两个参数和FileHandler一样。
maxBytes用于指定日志文件的最大文件大小。如果maxBytes为0,意味着日志文件可以无限大,这时上面描述的重命名过程就不会发生。
backupCount用于指定保留的备份文件的个数。比如,如果指定为2,当上面描述的重命名过程发生时,原有的chat.log.2并不会被更名,而是被删除。
4) logging.handlers.TimedRotatingFileHandler
这个Handler和RotatingFileHandler类似,不过,它没有通过判断文件大小来决定何时重新创建日志文件,而是间隔一定时间就 自动创建新的日志文件。重命名的过程与RotatingFileHandler类似,不过新的文件不是附加数字,而是当前时间。它的构造函数是:
TimedRotatingFileHandler( filename [,when [,interval [,backupCount]]])
其中filename参数和backupCount参数和RotatingFileHandler具有相同的意义。
interval是时间间隔。
when参数是一个字符串。表示时间间隔的单位,不区分大小写。它有以下取值:
S 秒
M 分
H 小时
D 天
W 每星期(interval==0时代表星期一)
midnight 每天凌晨
import logging #create logger
logger = logging.getLogger('TEST-LOG')
logger.setLevel(logging.DEBUG) # create console handler and set level to debug
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG) # create file handler and set level to warning
fh = logging.FileHandler("access.log")
fh.setLevel(logging.WARNING)
# create formatter
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') # add formatter to ch and fh
ch.setFormatter(formatter)
fh.setFormatter(formatter) # add ch and fh to logger
logger.addHandler(ch)
logger.addHandler(fh) # 'application' code
logger.debug('debug message')
logger.info('info message')
logger.warn('warn message')
logger.error('error message')
logger.critical('critical message')
8.subprocess模块
从Python 2.4开始,Python引入subprocess模块来管理子进程,以取代一些旧模块的方法:如 os.system、os.spawn*、os.popen*、popen2.*、commands.*不但可以调用外部的命令作为子进程,而且可以连接到子进程的input/output/error管道,获取相关的返回信息
一、subprocess以及常用的封装函数
运行python的时候,我们都是在创建并运行一个进程。像Linux进程那样,一个进程可以fork一个子进程,并让这个子进程exec另外一个程序。在Python中,我们通过标准库中的subprocess包来fork一个子进程,并运行一个外部的程序。
subprocess.call()
父进程等待子进程完成
返回退出信息(returncode,相当于Linux exit code)
subprocess.Popen()
class Popen(args, bufsize=0, executable=None, stdin=None, stdout=None, stderr=None, preexec_fn=None, close_fds=False,shell=False, cwd=None, env=None, universal_newlines=False, startupinfo=None, creationflags=0)
Popen对象创建后,主程序不会自动等待子进程完成。我们必须调用对象的wait()方法,父进程才会等待 (也就是阻塞block)。
child.poll() # 检查子进程状态
child.kill() # 终止子进程
child.send_signal() # 向子进程发送信号
child.terminate() # 终止子进程
二、子进程的文本流控制
child.stdin
child.stdout
child.stderr
Popen()建立子进程的时候改变标准输入、标准输出和标准错误,并可以利用subprocess.PIPE将多个子进程的输入和输出连接在一起,构成管道(pipe),示例如下:
>>> import subprocess
>>> child1 = subprocess.Popen(["ls","-l"], stdout=subprocess.PIPE)
>>> print child1.stdout.read() #或者child1.communicate()
>>> import subprocess
>>> child1 = subprocess.Popen(["cat","/etc/passwd"], stdout=subprocess.PIPE)
>>> child2 = subprocess.Popen(["grep","0:0"],stdin=child1.stdout, stdout=subprocess.PIPE)
>>> out = child2.communicate()
subprocess.PIPE实际上为文本流提供一个缓存区。child1的stdout将文本输出到缓存区,随后child2的stdin从该PIPE中将文本读取走。child2的输出文本也被存放在PIPE中,直到communicate()方法从PIPE中读取出PIPE中的文本。
注意:communicate()是Popen对象的一个方法,该方法会阻塞父进程,直到子进程完成
描述符
描述符就是以特殊方法__get__()、__set__()和__delete__()的形式实现了三个核心的属性访问操作(对应于get、set和delete)的类。这些方法通过接受类实例作为输入来工作。之后,底层的实例字典会根据需要适当地进行调整。
示例:
# Descriptor attribute for an integer type-checked attribute
class Integer:
def __init__(self,name):
self.name = name def __get__(self, instance, cls):
if instance is None:
return self
else:
return instance.__dict__[self.name] def __set__(self, instance, value):
if not isinstance(value,int):
raise TypeError("Expected an int")
instance.__dict__[self.name] = value def __delete__(self, instance):
del instance.__dict__[self.name]
要使用一个描述符,我们把描述符的实例放置在类的定义中作为类变量来用。示例如下:
class Point:
x = Integer('x')
y = Integer('y')
def __init__(self,x,y):
self.x = x
self.y = y
当这么做,所有针对描述符属性的访问都会被__get__()、__set__()和__delete__()方法所捕获。示例如下:
>>> p = Point(2,3) # Calls Point.x__get__(p,Point)
>>> p.y = 5 # Calls Point.y__set__(p,5)
>>> p.x = 2.3 # Calls Point.x__set__(p,2.3)
报错:必须是整型
描述符都提供了底层的魔法,包括@classmethod、@staticmethod、@property甚至__slots__。
通过定义一个描述符,可以在很底层的情况捕获关键的实例操作(get、set、delete),并可以完全自定义这些操作的行为。
注意:在实现__get__()方法时比想象中要复杂一些,其原因在于实例变量和类变量之间是有区别的。如果是以类变量的形式访问描述符,参数instance应该设为None,返回的即实例本身。示例如下:
>>> Point.x # Calls Point.x.__get__(None,Point)
<__main__.Integer instance at 0x00000000028BDB08>
接口或抽象基类
要定义一个抽象基类,可以使用abc模块。示例如下:
from abc import ABCMeta,abstractmethod
# 发送接口
class Alert:
__metaclass__ = ABCMeta @abstractmethod
def Send(self):
pass
抽象基类的核心特征就是不能被直接实例化。抽象基类是用来给其它的类当做基类使用的,这些子类需要实现基类中要求的那些方法。
# 抽象类 + 抽象方法 = 接口(第二种规范) # 微信发送接口调用
class Wechat(Alert):
def __init__(self):
pass def Send(self):
print("send.wechat") wechat = Wechat()
抽象基类的主要用途是强制规定所需的编程接口。
python成长笔记的更多相关文章
- Python成长笔记 - 基础篇 (十二)
本节内容 ORM介绍 sqlalchemy安装 sqlalchemy基本使用 多外键关联 多对多关系 表结构设计作业 主题:学员管理系统 需求: 用户角色,讲师\学员, 用户登陆后根据角色不同,能做的 ...
- Python成长笔记 - 基础篇 (十一)
回顾: 线程:资源的集合:内存共享,两个或多个线程同时修改一份数据时,造成结果可能不正确,必须加锁 进程:运行的最小单元 守护进程:在start之前设置setDemo() 队列queue:作用解耦,使 ...
- Python成长笔记 - 基础篇 (十)
本节内容 进程.与线程区别 python GIL全局解释器锁 线程 语法 join 线程锁之Lock\Rlock\信号量 将线程变为守护进程 Event事件 queue队列 生产者消费者模型 Queu ...
- Python成长笔记 - 基础篇 (七)python面向对象
三大特性: 1.封装:在类中对数据赋值.内部调用对外部用户是透明的,这使类变成了一个胶囊或容器,里面包含着类的数据和方法 2.继承:一个类可以派生出子类,在父类中定义的属性.方法会自动被子类继承 ...
- Python成长笔记 - 基础篇 (六)python模块
本节大纲: 模块介绍 time &datetime模块 random os sys shutil json & picle shelve xml处理 yaml处理 configpars ...
- Python成长笔记 - 基础篇 (四)函数
1.面向对象:类(class) 2.面向过程:过程(def) 3.函数式编程:函数(def)----python 1.函数:http://egon09.blog.51cto.com/9161406 ...
- Python成长笔记 - 基础篇 (三)python列表元组、字典、集合
本节内容 列表.元组操作 字符串操作 字典操作 集合操作 文件操作 字符编码与转码 一.列表和元组的操作 列表是我们最以后最常用的数据类型之一,通过列表可以对数据实现最方便的存储.修改等操作 定义 ...
- Python成长笔记 - 基础篇 (二)python基本语法
Python的设计目标之一是让代码具备高度的可阅读性.它设计时尽量使用其它语言经常使用的标点符号和英文单字,让代码看起来整洁美观.它不像其他的静态语言如C.Pascal那样需要重复书写声明语句,也不像 ...
- Python成长笔记 - 基础篇 (一)python简介
一.Python介绍 Python(英国发音:/ˈpaɪθən/ 美国发音:/ˈpaɪθɑːn/),由吉多·范罗苏姆(Guido van Rossum)于1989年发明,第一个公开发行版发行于1991 ...
随机推荐
- 网页调用外部APP
<activity android:name=".MainActivity" android:label="@string/app_name"> & ...
- asp.net 读取sql存储过程返回值
关于Exec返回值的问题有很多,在这做个简要的总结. 读查询语句示例: Declare @count int select @Count 要点: ...
- JavaScript--Date函数
1. Date函数 var now = new Date(); 获取当前日期对象 now对象->Date.prototype->Object.prototype 将一个字符串转换为Date ...
- 键盘数字对应的ASCII码(keycode码)
keycode 1 = 鼠标左键keycode 2 = 鼠标右键keycode 3 = Cancelkeycode 4 = 鼠标中键keycode 8 = BackSpace keycode 9 = ...
- JavaScript--函数-01
函数的本质: function:创建一个函数对象的意思 什么是函数对象: 专门封装一个函数定义的存储空间 其实,函数是一个引用类型的对象 函数名,其实是一个引用函数对象的变量 函数只有在调用时才执行, ...
- 模仿qq音乐播放字母效果
html <div class="cont"> <ul class="cont_ul" id="cont_ul"> ...
- Java学习----构造方法的重载
一个类中有多个同名的参数不一样(参数的个数,参数的类型,参数的顺序)的构造方法 public class Student { public Student() { System.out.println ...
- js实现输入验证码
html部分: <div> <input type="text" id="input" /> <input type=" ...
- 15 3Sum(寻找三个数之和为指定数的集合Medium)
题目意思:给一个乱序数组,在里面寻找三个数之和为0的所有情况,这些情况不能重复,增序排列 思路:前面2sum,我用的是map,自然那道题map比双指针效率高,这道题需要先排序,再给三个指针,i.j.k ...
- c# sqlserver备份还原(转)
WinForm c# 备份 还原 数据库 其实是个非常简单的问题,一个Form,一个Button,一个OpenFileDialog,一个SaveFileDialog.下面给出备份与还原类 using ...