LangChain结合LLM做私有化文档搜索
我们知道LLM(大语言模型)的底模是基于已经过期的公开数据训练出来的,对于新的知识或者私有化的数据LLM一般无法作答,此时LLM会出现“幻觉”。针对“幻觉”问题,一般的解决方案是采用RAG做检索增强。
但是我们不可能把所有数据都丢给LLM去学习,比如某个公司积累的某个行业的大量内部知识。此时就需要一个私有化的文档搜索工具了。
本文聊聊如何使用LangChain结合LLM快速做一个私有化的文档搜索工具。之前介绍过,LangChain几乎是LLM应用开发的第一选择,它的野心也比较大,它致力于将自己打造成LLM应用开发的最大社区。自然,它有这方面的成熟解决方案。
文末,还会向朋友们推荐一款非常好用的AI机器人和LLM API超市,价格实惠又稳定,还可以领一波福利。
1. RAG检索流程
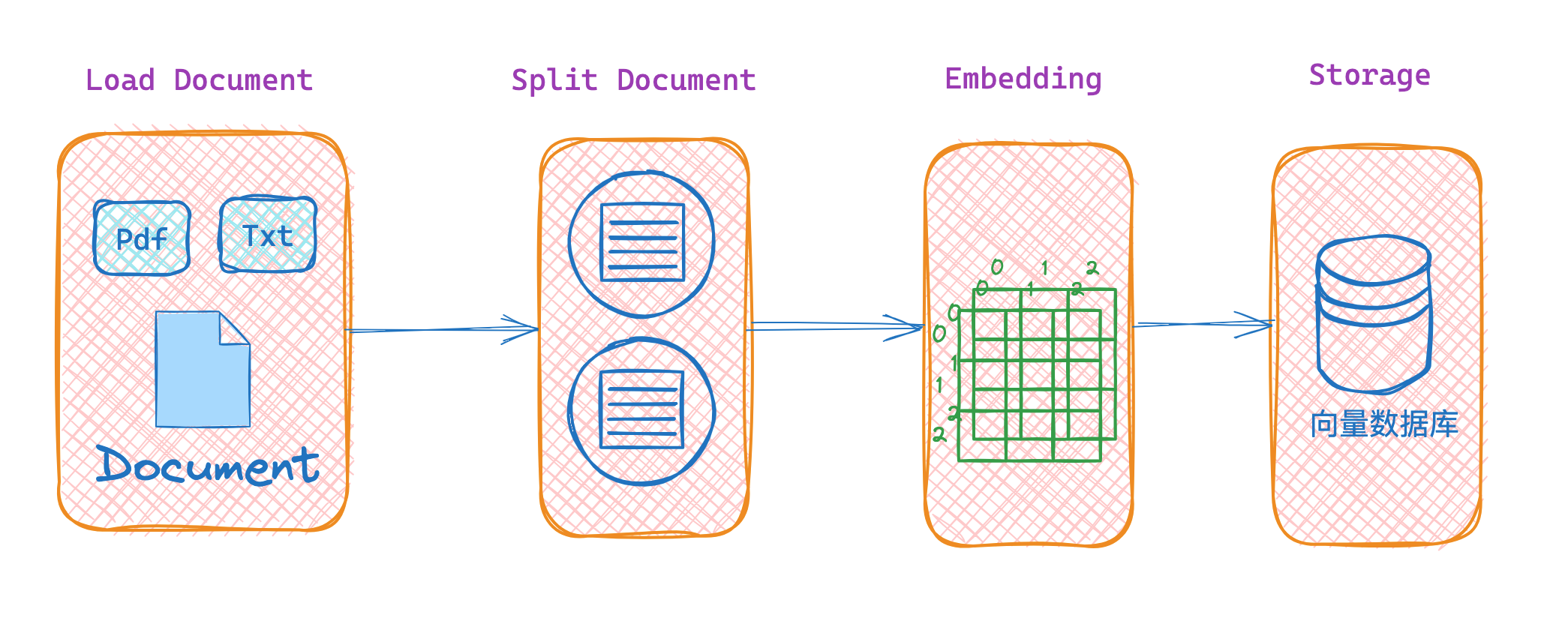
使用 LangChain 实现私有化文档搜索的主要流程,如下图所示:
文档加载 → 文档分割 → 文档嵌入 → 向量化存储 → 文档检索 → 生成回答
2. 代码实践细节
2.1. 文档加载
首先,我们需要加载文档数据。文档可以是各种格式,比如文本文件、PDF、Word 等。使用 LangChain,可以轻松地加载这些文档。下面以PDF为例:
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./GV2.pdf")
docs = loader.load()
2.2. 文档分割
加载的文档通常会比较大,为了更高效地处理和检索,我们需要将文档分割成更小的段落或句子。LangChain 提供了便捷的文本分割工具,可以按句子、块长度等方式分割文档。
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=50,
chunk_overlap=20,
separators=["\n", "。", "!", "?", ",", "、", ""],
add_start_index=True,
)
texts = text_splitter.split_documents(docs)
分割后的文档内容可以进一步用于生成向量。
2.3. 文档嵌入 Embeddings
文档分割后,我们需要将每一段文本转换成向量,这个过程称为文档嵌入。文档嵌入是将文本转换成高维向量,这是相似性搜索的关键。这里我们选择OpenAI的嵌入模型来生成文档的嵌入向量。
from langchain_openai import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(
openai_api_key="sk-xxxxxxxxxxx",
openai_api_base="https://api.302.ai/v1",
)
txts = [txt.page_content for txt in texts]
embeddings = embeddings_model.embed_documents(txts)
2.4. 文档向量化存储
接下来,我们需要将生成的向量化的文档,存入向量数据库中。向量数据库主要用来做相似性搜索,可以高效地存储和检索高维向量。LangChain 支持与多种向量数据库的集成,比如 Pinecone、FAISS、Chroma 等。
本文以FAISS为例,首先需要安装FAISS,直接使用pip install faiss-cpu安装。
from langchain_community.vectorstores import FAISS
db = FAISS.from_documents(texts, embeddings_model)
FAISS.save_local(db, "faiss_db2")
2.5. 文档检索
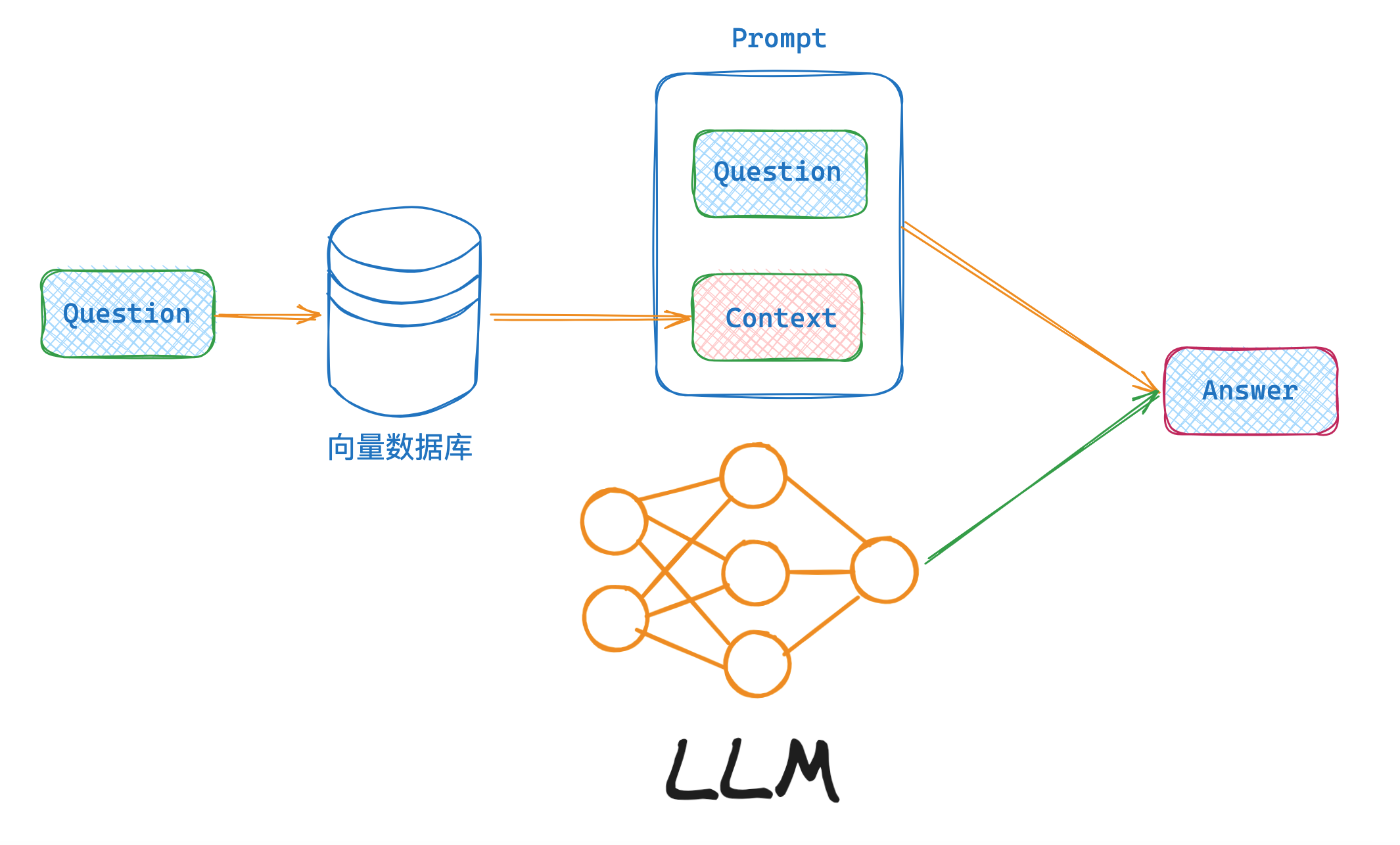
当用户提出问题时,我们需要在向量数据库中检索最相关的文档。检索过程是计算用户问题的向量表示,然后在向量数据库中查找与之最相似的文档。最后将找到的文档内容,拼接成一个大的上下文。
向量数据库的检索支持多种模式,本文先用最简单的,后续再出文章继续介绍别的模式。
from langchain.retrievers.multi_query import MultiQueryRetriever
retriever = db.as_retriever()
# retriever = db.as_retriever(search_type="similarity_score_threshold",search_kwargs={"score_threshold":.1,"k":5})
# retriever = db.as_retriever(search_type="mmr")
# retriever = MultiQueryRetriever.from_llm(
# retriever = db.as_retriever(),
# llm = model,
# )
context = retriever.get_relevant_documents(query="张学立是谁?")
_content = ""
for i in context:
_content += i.page_content
2.6. 将检索内容丢给LLM作答
最后,我们需要将检索到的文档内容丢入到 prompt 中,让LLM生成回答。LangChain 可以PromptTemplate模板的方式,将检索到的上下文动态嵌入到 prompt 中,然后丢给LLM,这样可以生成准确的回答。
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
question = "张学立是谁?"
template = [
(
"system",
"你是一个处理文档的助手,你会根据下面提供<context>标签里的上下文内容来继续回答问题.\n 上下文内容\n <context>\n{context} \n</context>\n",
),
("human", "你好!"),
("ai", "你好"),
("human", "{question}"),
]
prompt = ChatPromptTemplate.from_messages(template)
messages = prompt.format_messages(context=_content, question=question)
response = model.invoke(messages)
output_parser = StrOutputParser()
output_parser.invoke(response)
2.7. 完整代码
最后,将以上所有代码串起来,整合到一起,如下:
from langchain_openai import ChatOpenAI
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
model = ChatOpenAI(
model_name="gpt-3.5-turbo",
openai_api_key="sk-xxxxxxx",
openai_api_base="https://api.302.ai/v1",
)
loader = PyPDFLoader("./GV2.pdf")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=50,
chunk_overlap=20,
separators=["\n", "。", "!", "?", ",", "、", ""],
add_start_index=True,
)
texts = text_splitter.split_documents(docs)
embeddings_model = OpenAIEmbeddings(
openai_api_key="sk-xxxxxxx",
openai_api_base="https://api.302.ai/v1",
)
txts = [txt.page_content for txt in texts]
embeddings = embeddings_model.embed_documents(txts)
db = FAISS.from_documents(texts, embeddings_model)
FAISS.save_local(db, "faiss_db2")
retriever = db.as_retriever()
template = [
(
"system",
"你是一个处理文档的助手,你会根据下面提供<context>标签里的上下文内容来继续回答问题.\n 上下文内容\n <context>\n{context} \n</context>\n",
),
("human", "你好!"),
("ai", "你好"),
("human", "{question}"),
]
prompt = ChatPromptTemplate.from_messages(template)
question = "张学立是谁?"
context = retriever.get_relevant_documents(query=question)
_content = ""
for i in context:
_content += i.page_content
messages = prompt.format_messages(context=_content, question=question)
response = model.invoke(messages)
output_parser = StrOutputParser()
output_parser.invoke(response)
2.8. 总结、推荐
通过 LangChain可以轻松实现私有化文档搜索,充分利用LLM的能力来处理和检索文档信息。按照文中的步骤,你也可以轻松实现。
好的问答系统离不开优秀的LLM,根据我的个人经验,OpenAI的大模型能力排名是Top1的。但是使用OpenAI不方便,不但需要梯子而且还不稳定。
一款好的LLM摆在面前,却用不了,着实头疼。有没有方便稳定的方式呢?当然有啦,下面我来推荐一款AI自助平台,不但有问答机器人、文生图机器人、文生视频机器人,还有常见的LLM API,稳定又还便宜。
3. 推荐一款好用的AI平台 - 302.AI
3.1. 什么是302.AI
302.AI是一个汇集全球顶级AI的自助平台,汇集全球各类顶尖AI大模型,提供多种AI机器人,各种AI工具的使用和AI API接入。
这个平台太适合开发者了,一站式配齐了 支持各种模型的工具 和 AI API,再也不用这个网站用一下,那个网站用一下了。
自由配置机器人、自由配置各种模型,每一款都很能打。
3.2. 302.AI的优势
我为什么愿意使用302.AI呢?主要还是有点比较多:
- 功能全面:平台提供了各种机器人,其中包括不限于文字处理,图片处理,声音处理。 这一点就可以轻松应付我们平时的工作了,无需到处找AI工具网站。总之,平台提供的机器人,工具和API多种使用方法,可以满足从小白到开发者多种角色的需求。
- 精选优质大模型:平台帮用户测试市面上众多的AI模型,挑出最好用的模型接入到平台,简化用户的挑选成本。而且再大模型的API调用处,还很贴心的集成了Apifox,在线调试,自动生成多种语言的代码。
- 价格透明价格便宜:价格透明,token计算清晰,我对比过多个代理的价格,302.AI绝对是最便宜的,没有之一。
- 按需付费,零门槛:302.AI另外一个特点是,不像大部分的AI工具网站按月收费或者按年收费,302.AI是按需付费,用多少付多少,价格便宜又透明,计费清晰,更无须担心跑路。这两年我见过的倒闭的AI工具站太多了。
- 管理者和使用者分离:使用者无需关心复杂的AI设置,让懂AI的管理者来配置,配置完毕后分享给使用者,简化使用流程。小白也可简易使用。更无需使用梯子,方便又稳定。
- 稳定性好:从我最近的使用感受来看,整体还是比较稳定的。不像有些API,时不时的给我冒一个配额不足的情况。
下面上几个截图,功能较多,我就不一一解说了,欢迎朋友们自行尝试。


总之,302.AI是一个可以满足从工具到API的聚合AI网站,也是一个可以满足从小白到开发者的需求的AI网站,同时,又兼顾了稳定性和性价比。更多功能,欢迎朋友们自行尝试解锁。
3.3. 粉丝福利
我这边创建了AI全能工具箱分享给大家体验,每天都会有 5美元额度,先到先用。
AI全能工具箱链接:https://aitoolbox1-all.tools302.com?pwd=0658 分享码0658,注册完填写个问卷会得到1美元的试用额度。
对于开发者朋友,可以私信我获取免费token,薅一波羊毛。
=====>>>>>> 关于我 <<<<<<=====
本篇完结!欢迎点赞 关注 收藏!!!
原文链接:https://mp.weixin.qq.com/s/idLmCB8OXwtJIqAqfgBxuQ

LangChain结合LLM做私有化文档搜索的更多相关文章
- lucene全文搜索之四:创建索引搜索器、6种文档搜索器实现以及搜索结果分析(结合IKAnalyzer分词器的搜索器)基于lucene5.5.3
前言: 前面几章已经很详细的讲解了如何创建索引器对索引进行增删查(没有更新操作).如何管理索引目录以及如何使用分词器,上一章讲解了如何生成索引字段和创建索引文档,并把创建的索引文档保存到索引目录,到这 ...
- 10 华电内部文档搜索系统 search02
搜索项目并不是一个很大的项目,在实际项目中往往是作为子项目和别的项目集成在一起的.比如说和OA项目集成在一起,作为另外一个项目的子系统来使用.搜索项目的功能并不复杂. 整个项目是文档搜索项目,如题:企 ...
- 海量Office文档搜索
知识管理系统Data Solution研发日记之十 海量Office文档搜索 经过前面两篇文章的介绍,<分享制作精良的知识管理系统 博客备份程序 Site Rebuild>和<分 ...
- 500 多个 Linux 命令文档搜索
500 多个 Linux 命令文档搜索 搜索界面:https://wangchujiang.com/linux-command/ 源码:https://github.com/jaywcjlove/li ...
- 基于.NetCore3.1搭建项目系列 —— 使用Swagger做Api文档 (上篇)
前言 为什么在开发中,接口文档越来越成为前后端开发人员沟通的枢纽呢? 随着业务的发张,项目越来越多,而对于支撑整个项目架构体系而言,我们对系统业务的水平拆分,垂直分层,让业务系统更加清晰,从而产生一系 ...
- 基于.NetCore3.1搭建项目系列 —— 使用Swagger做Api文档 (下篇)
前言 回顾上一篇文章<使用Swagger做Api文档 >,文中介绍了在.net core 3.1中,利用Swagger轻量级框架,如何引入程序包,配置服务,注册中间件,一步一步的实现,最终 ...
- 【Elasticsearch学习】文档搜索全过程
在ES执行分布式搜索时,分布式搜索操作需要分散到所有相关分片,若一个索引有3个主分片,每个主分片有一个副本分片,那么搜索请求会在这6个分片中随机选择3个分片,这3个分片有可能是主分片也可能是副本分片, ...
- SharePoint 2010 文档管理系列之文档搜索
前言:如果一个文档库里面有很多文档,成千上万,对我们来说查找就是个麻烦事儿,所以搜索的必要性就体现出来了.下面,我们简单的介绍下,sharepoint搜索配置,并创建一个简单的搜索页面. 一. 配置S ...
- Asp.net Core WebApi 使用Swagger做帮助文档,并且自定义Swagger的UI
WebApi写好之后,在线帮助文档以及能够在线调试的工具是专业化的表现,而Swagger毫无疑问是做Docs的最佳工具,自动生成每个Controller的接口说明,自动将参数解析成json,并且能够在 ...
- 用Python做SVD文档聚类---奇异值分解----文档相似性----LSI(潜在语义分析)
转载请注明出处:电子科技大学EClab——落叶花开http://www.cnblogs.com/nlp-yekai/p/3848528.html SVD,即奇异值分解,在自然语言处理中,用来做潜在语义 ...
随机推荐
- Metasploit 实现木马生成、捆绑及免杀
简介: 在渗透测试的过程中,避免不了使用到社会工程学的方式来诱骗对方运行我们的木马或者点击我们准备好的恶意链接.木马的捆绑在社会工程学中是我们经常使用的手段,而为了躲避杀毒软件的查杀,我们又不得不对 ...
- RAG 工具和框架介绍: Haystack、 LangChain 和 LlamaIndex
Haystack. LangChain 和 LlamaIndex,以及这些工具是如何让我们轻松地构建 RAG 应用程序的? 我们将重点关注以下内容: Haystack LangChain LlamaI ...
- Docker Volume 的经常用法区别
对于使用 NFS 的 Docker 数据卷,配置示例应当类似于这样: version: '3' services: my_service: image: your_image volumes: # 挂 ...
- 使用SQL Server语句统计某年龄段人数占总人数的比例(多层查询语句嵌套-比例分析)
需求:需统计出某个集合内,某个段所占的比例,涉及SELECT查询语句的嵌套,如有疑问可留言. 如下: --按性别进行年度挂号年龄段分析--男SELECT 年龄段,SUM(人数) 数量,cast(cas ...
- 详解Python 中可视化数据分析工作流程
本文分享自华为云社区<Python 可视化数据分析从数据获取到洞见发现的全面指南>,作者:柠檬味拥抱. 在数据科学和分析的领域中,可视化是一种强大的工具,能够帮助我们理解数据.发现模式,并 ...
- C++ 类的继承(Inheritance)
一.继承(Inheritance) C++有一个很好的性质称为inheritance(继承),就是声明一个class(derived class),把另一个或多个class(base class)的所 ...
- 5GC 关键技术之 CUPS(控制与用户面分离)
目录 文章目录 目录 前文列表 CUPS(控制与用户面分离) 前文列表 <简述移动通信网络的演进之路> <5G 第五代移动通信网络> <5GC 关键技术之 SBA(基于服 ...
- Metabase 安装和使用教程
Metabase 是一款开源的数据分析和商业智能工具,允许企业用户在几分钟内搭建起一个功能完善的数据探索和数据分析平台,不需要编写复杂的 SQL 查询语句或者使用专业的数据可视化工具,就可以轻松地探索 ...
- 更智能!AIRIOT加速煤炭行业节能减排升级
"双碳政策"下,各个行业都在践行节能减排行动,依靠数字化.智能化手段开展节能减排工作. 煤炭行业是能源消耗大户,煤炭选洗是煤炭行业节能减排的重要环节之一,加强煤炭清洁高效利用工作, ...
- 【C#】使用WebHttpRequest调用Restful带token接口500 返回401 未授权错误
测试对方的接口,发现单个调用对方接口是可以的,但是多个连续的调用对方接口时,会出现第一条调用一般是200,随后的调用就会报500,401未授权的错误,除了第一条后面的请求数据几乎都不得行. 我于是用f ...