算法金 | 决策树、随机森林、bagging、boosting、Adaboost、GBDT、XGBoost 算法大全

大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」
决策树是一种简单直观的机器学习算法,它广泛应用于分类和回归问题中。它的核心思想是将复杂的决策过程分解成一系列简单的决策,通过不断地将数据集分割成更小的子集来进行预测。本文将带你详细了解决策树系列算法的定义、原理、构建方法、剪枝与优化技术,以及它的优缺点。

一、决策树
1.1 决策树的定义与原理
决策树的定义:决策树是一种树形结构,其中每个节点表示一个特征的测试,每个分支表示一个测试结果,每个叶子节点表示一个类别或回归值。决策树的目标是通过一系列的特征测试,将数据分成尽可能纯的子集。
决策树的原理:决策树通过递归地选择最优特征进行分割来构建。最优特征的选择通常基于某种度量标准,如信息增益、基尼指数或方差减少。每次分割都会将数据集分成更小的子集,直到满足停止条件(如达到最大深度或子集纯度)为止。
1.2 决策树的构建方法
构建方法:
- 选择最优特征:使用信息增益、基尼指数或方差减少等标准来选择最优特征进行分割
- 分割数据集:根据最优特征的不同取值将数据集分割成若干子集
- 递归构建子树:对每个子集递归地选择最优特征进行分割,直到满足停止条件
- 生成叶子节点:当满足停止条件时,生成叶子节点并标记类别或回归值
1.3 决策树的剪枝与优化
剪枝技术:
- 预剪枝:在构建过程中提前停止树的生长,如限制树的最大深度、最小样本数或最小增益
- 后剪枝:在构建完成后,通过剪去不重要的子树来简化模型,如通过交叉验证选择最优剪枝点
优化方法:
- 特征选择:使用基于统计显著性的特征选择方法来减少特征数量
- 参数调整:通过网格搜索或随机搜索优化超参数,如最大深度、最小样本数等
- 集成方法:结合多个决策树(如随机森林、梯度提升树)来提高模型性能
1.4 决策树的优缺点
优点:
- 直观简单,易于理解和解释
- 适用于数值型和类别型数据
- 可以处理多输出问题
缺点:
- 容易过拟合,尤其是深树
- 对噪声和小变动敏感
- 计算复杂度高,尤其是在特征数多时
更多内容,见微*公号往期文章: 突破最强算法模型,决策树算法!!
二、集成学习概述
集成学习是通过结合多个学习器的预测结果来提高模型性能的一种方法。它的核心思想是集成多个模型,通过投票、加权等方式获得更稳定、更准确的预测结果。集成学习在处理高维数据、降低过拟合和提高模型泛化能力方面具有显著优势。
2.1 集成学习的基本概念
集成学习的定义:集成学习(Ensemble Learning)是一种将多个基模型组合在一起的方法,其目标是通过结合多个模型的优点来提高整体性能。集成学习通常分为两类:同质集成(基模型相同,如随机森林)和异质集成(基模型不同,如堆叠模型)。
集成学习的原理:集成学习的基本原理是通过组合多个弱模型(即性能不佳的单个模型)来构建一个强模型(即性能优异的集成模型)。这种组合可以通过多种方式实现,常见的方法包括:Bagging、Boosting和Stacking。
以下是集成学习的一些常用方法:
- Bagging(Bootstrap Aggregating):通过对数据集进行有放回的随机抽样,生成多个子数据集,并在每个子数据集上训练基模型。最终的预测结果通过对所有基模型的预测结果进行平均或投票来确定
- Boosting:通过迭代地训练基模型,每个基模型在前一个基模型的基础上进行改进。每次迭代时,增加错误分类样本的权重,使得新模型能够更好地处理这些样本
- Stacking:通过训练多个基模型,并使用这些基模型的预测结果作为输入,训练一个次级模型来进行最终预测
2.2 Bagging 和 Boosting 的区别
Bagging(Bootstrap Aggregating):
- 通过对数据集进行有放回的随机抽样,生成多个子数据集
- 在每个子数据集上训练基模型
- 通过对所有基模型的预测结果进行平均或投票来确定最终结果
- 主要用于减少方差,防止过拟合
Boosting:
- 通过迭代地训练基模型,每个基模型在前一个基模型的基础上进行改进
- 每次迭代时,增加错误分类样本的权重,使得新模型能够更好地处理这些样本
- 通过加权平均或加权投票来确定最终结果
- 主要用于减少偏差,提高模型的准确性
主要区别:
- 训练方式:Bagging 是并行训练多个基模型,Boosting 是串行训练多个基模型
- 数据处理:Bagging 使用有放回的随机抽样,Boosting 根据错误率调整样本权重
- 目标:Bagging 主要减少方差,Boosting 主要减少偏差
2.3 集成学习在机器学习中的重要性
提高模型性能:集成学习通过结合多个基模型的预测结果,可以显著提高模型的准确性和稳定性。这在处理复杂问题和高维数据时尤为重要
降低过拟合风险:集成学习通过对多个模型的预测结果进行综合,减少了单个模型的过拟合风险,使得模型具有更好的泛化能力
增强模型鲁棒性:集成学习可以通过结合不同的模型,提高模型对噪声和异常值的鲁棒性,增强模型在实际应用中的可靠性

三、Bagging
Bagging 是集成学习中的一种方法,通过并行训练多个基模型来提高整体性能。它通过对数据集进行有放回的随机抽样,生成多个子数据集,并在每个子数据集上训练基模型。最终的预测结果通过对所有基模型的预测结果进行平均或投票来确定。Bagging 主要用于减少模型的方差,防止过拟合。
3.1 Bagging 的定义与原理
Bagging 的定义:Bagging(Bootstrap Aggregating)是一种通过并行训练多个基模型来提高模型性能的集成学习方法。它通过对原始数据集进行有放回的随机抽样,生成多个子数据集,并在每个子数据集上训练基模型。
Bagging 的原理:Bagging 的核心思想是通过减少模型的方差来提高模型的泛化能力。具体步骤如下:
- 从原始数据集中有放回地随机抽样生成多个子数据集
- 在每个子数据集上训练一个基模型
- 对每个基模型的预测结果进行平均(回归任务)或投票(分类任务)以得到最终预测结果
3.2 Bagging 的具体算法与流程
Bagging 的具体流程:
- 数据集生成:对原始数据集进行有放回的随机抽样,生成多个子数据集
- 模型训练:在每个子数据集上训练一个基模型(如决策树)
- 结果综合:对每个基模型的预测结果进行平均或投票,得到最终的预测结果
3.3 Bagging 的优缺点
优点:
- 减少方差:通过对多个基模型的预测结果进行综合,Bagging 能有效减少模型的方差,提升模型的泛化能力
- 防止过拟合:由于每个基模型是在不同的子数据集上训练的,Bagging 能有效防止单个模型过拟合
- 简单易用:Bagging 方法实现简单,适用于多种基模型
缺点:
- 计算复杂度高:由于需要训练多个基模型,Bagging 的计算复杂度较高,训练时间较长
- 模型解释性差:由于 Bagging 是对多个基模型的结果进行综合,单个基模型的解释性较差,难以解释最终模型的预测结果
Bagging 方法在处理高维数据和防止过拟合方面具有显著优势,适用于多种机器学习任务。

四、随机森林
随机森林是 Bagging 的一种改进版本,通过构建多个决策树并结合它们的预测结果来提高模型的准确性和稳定性。与 Bagging 不同的是,随机森林在每次分割节点时还会随机选择部分特征进行考虑,从而进一步增加模型的多样性。
4.1 随机森林的定义与原理
随机森林的定义:随机森林(Random Forest)是一种基于决策树的集成学习方法,通过构建多个决策树并结合它们的预测结果来提高模型的性能。每棵树在训练时都使用了不同的样本和特征,从而增加了模型的多样性和鲁棒性。
随机森林的原理:随机森林的核心思想是通过引入随机性来减少模型的方差和过拟合风险。具体步骤如下:
- 对原始数据集进行有放回的随机抽样,生成多个子数据集
- 在每个子数据集上训练一棵决策树。在每个节点分割时,随机选择部分特征进行考虑
- 对所有决策树的预测结果进行平均(回归任务)或投票(分类任务)以得到最终预测结果
4.2 随机森林的构建方法
构建方法:
- 数据集生成:对原始数据集进行有放回的随机抽样,生成多个子数据集
- 决策树训练:在每个子数据集上训练一棵决策树,在每个节点分割时随机选择部分特征进行考虑
- 结果综合:对所有决策树的预测结果进行平均或投票,得到最终的预测结果
4.3 随机森林的优化技术
优化方法:
- 特征选择:通过分析特征重要性,选择最有价值的特征进行训练
- 参数调整:使用网格搜索或随机搜索优化超参数,如树的数量(n_estimators)、最大深度(max_depth)、最小样本数(min_samples_split)等
- 样本加权:在训练时对样本进行加权处理,使得模型对不同样本的重要性有所区别
- 交叉验证:通过交叉验证评估模型性能,选择最优参数配置
4.4 随机森林的优缺点
优点:
- 高准确率:通过集成多个决策树,随机森林具有较高的预测准确率
- 抗过拟合:通过引入随机性,随机森林能有效减少过拟合风险
- 特征重要性评估:随机森林可以评估各个特征的重要性,帮助理解数据
缺点:
- 计算复杂度高:由于需要训练多个决策树,随机森林的计算复杂度较高,训练时间较长
- 内存占用大:随机森林需要存储多个决策树模型,占用较多内存
- 模型解释性差:由于随机森林是对多个决策树的结果进行综合,单个决策树的解释性较差,难以解释最终模型的预测结果
随机森林在处理高维数据和防止过拟合方面具有显著优势,适用于多种机器学习任务。
更多内容,见微*公号往期文章:突破最强算法模型!!学会随机森林,你也能发表高水平SCI
五、Boosting
Boosting 是另一种强大的集成学习方法,通过逐步改进弱模型的性能来构建一个强模型。与 Bagging 不同,Boosting 是一种串行过程,每个基模型在训练时都会关注前一个模型中被错误分类的样本,从而不断提高整体模型的准确性。
5.1 Boosting 的定义与原理
Boosting 的定义:Boosting 是一种集成学习方法,通过逐步训练多个弱模型,每个模型在前一个模型的基础上进行改进,最终将这些弱模型组合成一个强模型。常见的 Boosting 算法包括 AdaBoost、GBDT 和 XGBoost。
Boosting 的原理:Boosting 的核心思想是通过逐步减小模型的偏差来提高整体性能。具体步骤如下:
- 初始化模型,将所有样本的权重设为相等
- 训练第一个基模型,计算每个样本的误差
- 根据误差调整样本的权重,使得错误分类的样本权重增加
- 训练下一个基模型,并继续调整样本权重,直至达到指定的模型数量或误差阈值
- 最终将所有基模型的预测结果进行加权平均或加权投票,得到最终预测结果
5.2 Boosting 的具体算法与流程
Boosting 的具体流程:
- 初始化权重:将所有样本的权重设为相等
- 训练基模型:在当前样本权重下训练基模型,计算每个样本的误差
- 调整权重:根据误差调整样本的权重,错误分类的样本权重增加
- 重复步骤 2 和 3:直至达到指定的基模型数量或误差阈值
- 加权综合:将所有基模型的预测结果进行加权平均或加权投票,得到最终预测结果
5.3 Boosting 的优缺点
优点:
- 高准确率:通过逐步改进模型性能,Boosting 能显著提高模型的预测准确率
- 减少偏差:通过关注前一个模型的错误分类样本,Boosting 能有效减少模型的偏差
- 灵活性强:Boosting 可以与多种基模型结合,具有较高的灵活性
缺点:
- 计算复杂度高:由于需要逐步训练多个基模型,Boosting 的计算复杂度较高,训练时间较长
- 易过拟合:如果基模型过于复杂或迭代次数过多,Boosting 可能会导致过拟合
- 对噪声敏感:由于 Boosting 会增加错误分类样本的权重,可能会对噪声样本过度拟合
Boosting 方法在处理复杂数据和提高模型准确性方面具有显著优势,适用于多种机器学习任务

六、Adaboost
Adaboost 是 Boosting 家族中最早提出的一种算法,通过逐步调整样本权重来训练一系列弱分类器,从而组合成一个强分类器。它的核心思想是让后续的分类器重点关注前面被错误分类的样本,从而提高模型的准确性。
6.1 Adaboost 的定义与原理
Adaboost 的定义:Adaboost(Adaptive Boosting)是一种自适应 Boosting 算法,通过调整样本权重来逐步提高模型性能。每个弱分类器的权重根据其错误率进行调整,错误率低的分类器权重较高,错误率高的分类器权重较低。
Adaboost 的原理:Adaboost 的核心思想是通过逐步调整样本权重,使得每个弱分类器能够更好地处理前一个分类器错误分类的样本。具体步骤如下:
- 初始化样本权重,使得每个样本的权重相等
- 训练弱分类器,并计算其错误率
- 根据错误率调整分类器权重,错误率越低的分类器权重越高
- 根据错误分类情况调整样本权重,错误分类的样本权重增加
- 迭代上述步骤,直到达到指定的弱分类器数量或误差阈值
- 最终将所有弱分类器的预测结果进行加权综合,得到最终预测结果
6.2 Adaboost 的构建方法
构建方法:
- 初始化权重:将所有样本的权重设为相等
- 训练弱分类器:在当前样本权重下训练弱分类器,计算每个样本的误差
- 调整分类器权重:根据弱分类器的错误率调整其权重,错误率越低的分类器权重越高
- 调整样本权重:根据错误分类情况调整样本权重,错误分类的样本权重增加
- 重复步骤 2-4:直到达到指定的弱分类器数量或误差阈值
- 加权综合:将所有弱分类器的预测结果进行加权综合,得到最终预测结果
6.3 Adaboost 的优化技术
优化方法:
- 参数调整:通过网格搜索或随机搜索优化超参数,如弱分类器数量(n_estimators)、学习率(learning_rate)等
- 弱分类器选择:选择合适的弱分类器,如决策树、线性模型等,根据具体问题选择最优模型
- 样本加权:在训练时对样本进行加权处理,使得模型对不同样本的重要性有所区别
- 交叉验证:通过交叉验证评估模型性能,选择最优参数配置
6.4 Adaboost 的优缺点
优点:
- 高准确率:通过逐步改进模型性能,Adaboost 能显著提高模型的预测准确率
- 减少偏差:通过关注前一个模型的错误分类样本,Adaboost 能有效减少模型的偏差
- 适用于多种基模型:Adaboost 可以与多种基模型结合,具有较高的灵活性
缺点:
- 计算复杂度高:由于需要逐步训练多个弱分类器,Adaboost 的计算复杂度较高,训练时间较长
- 易过拟合:如果弱分类器过于复杂或迭代次数过多,Adaboost 可能会导致过拟合
- 对噪声敏感:由于 Adaboost 会增加错误分类样本的权重,可能会对噪声样本过度拟合
Adaboost 方法在处理复杂数据和提高模型准确性方面具有显著优势,适用于多种机器学习任务

七、GBDT
GBDT(Gradient Boosting Decision Tree,梯度提升决策树)是一种基于决策树的 Boosting 方法,通过逐步构建一系列决策树来提升模型的预测性能。每棵树都在前面所有树的残差上进行拟合,从而不断减小整体模型的误差。
7.1 GBDT 的定义与原理
GBDT 的定义:GBDT 是一种通过逐步构建一系列决策树来提升模型性能的集成学习方法。每棵树都在前面所有树的残差上进行拟合,以减小整体模型的误差。GBDT 适用于回归和分类任务,在许多实际应用中表现出色。
GBDT 的原理:GBDT 的核心思想是通过逐步减小残差来提高模型的准确性。具体步骤如下:
- 初始化模型,将所有样本的预测值设为目标值的均值(回归)或初始概率(分类)
- 计算当前模型的残差,即目标值与当前预测值之间的差异
- 训练一棵决策树来拟合残差,得到新的预测值
- 更新模型的预测值,将新的预测值加到当前预测值上
- 重复步骤 2-4,直到达到指定的树数量或误差阈值
7.2 GBDT 的构建方法
构建方法:
- 初始化预测值:将所有样本的预测值设为目标值的均值(回归)或初始概率(分类)
- 计算残差:计算当前模型的残差,即目标值与当前预测值之间的差异
- 训练决策树:在当前残差上训练一棵决策树,得到新的预测值
- 更新预测值:将新的预测值加到当前预测值上
- 重复步骤 2-4:直到达到指定的树数量或误差阈值
7.3 GBDT 的优化技术
优化方法:
- 参数调整:通过网格搜索或随机搜索优化超参数,如树的数量(n_estimators)、学习率(learning_rate)、最大深度(max_depth)等
- 特征选择:通过分析特征重要性,选择最有价值的特征进行训练
- 正则化:通过添加正则化项来控制模型的复杂度,防止过拟合
- 早停:通过监控验证集上的误差,在误差不再显著降低时提前停止训练
7.4 GBDT 的优缺点
优点:
- 高准确率:通过逐步减小残差,GBDT 能显著提高模型的预测准确率
- 减少偏差:通过在残差上训练决策树,GBDT 能有效减少模型的偏差
- 处理非线性关系:GBDT 能处理复杂的非线性关系,适用于多种数据类型
缺点:
- 计算复杂度高:由于需要逐步训练多个决策树,GBDT 的计算复杂度较高,训练时间较长
- 易过拟合:如果决策树过于复杂或迭代次数过多,GBDT 可能会导致过拟合
- 对参数敏感:GBDT 对参数设置较为敏感,需要仔细调整超参数以获得最佳性能
GBDT 方法在处理复杂数据和提高模型准确性方面具有显著优势,适用于多种机器学习任务。接下来我们会详细探讨 XGBoost 及其具体实现。
八、XGBoost
XGBoost 是一种高效的梯度提升算法,被广泛应用于各种机器学习竞赛和实际项目中。它在 GBDT 的基础上进行了多种优化,包括正则化、并行处理和树结构的改进,使得其在精度和效率上均有显著提升。
8.1 XGBoost 的定义与原理
XGBoost 的定义:XGBoost(eXtreme Gradient Boosting)是一种基于梯度提升决策树的增强版算法,具有更高的效率和准确性。XGBoost 通过引入二阶导数信息、正则化项和并行处理等技术,显著提升了模型的性能和训练速度。
XGBoost 的原理:XGBoost 的核心思想与 GBDT 类似,通过逐步减小残差来提高模型的准确性。不同的是,XGBoost 引入了以下优化:
- 正则化项:通过添加 L1 和 L2 正则化项来控制模型复杂度,防止过拟合
- 二阶导数信息:在优化目标函数时引入二阶导数信息,提高优化精度
- 并行处理:通过并行计算和分布式计算加速模型训练
- 树结构优化:使用贪心算法和剪枝技术优化树的结构
8.2 XGBoost 的构建方法
构建方法:
- 数据准备:将数据转换为 DMatrix 格式,XGBoost 专用的数据结构
- 设置参数:配置 XGBoost 的超参数,如目标函数、最大深度、学习率等
- 训练模型:使用训练数据训练 XGBoost 模型
- 预测结果:使用训练好的模型进行预测
- 评估性能:计算预测结果的准确性等指标
8.3 XGBoost 的优化技术
优化方法:
- 参数调整:通过网格搜索或随机搜索优化超参数,如树的数量(num_round)、学习率(eta)、最大深度(max_depth)等
- 特征选择:通过分析特征重要性,选择最有价值的特征进行训练
- 正则化:通过添加 L1 和 L2 正则化项来控制模型的复杂度,防止过拟合
- 早停:通过监控验证集上的误差,在误差不再显著降低时提前停止训练
8.4 XGBoost 的优缺点
优点:
- 高准确率:通过引入多种优化技术,XGBoost 具有极高的预测准确率
- 快速训练:通过并行计算和分布式计算,XGBoost 的训练速度非常快
- 正则化控制:通过添加 L1 和 L2 正则化项,XGBoost 能有效控制模型复杂度,防止过拟合
- 处理缺失值:XGBoost 能自动处理数据中的缺失值,提高模型的鲁棒性
缺点:
- 参数调整复杂:XGBoost 具有大量超参数,需要仔细调整以获得最佳性能
- 内存占用大:XGBoost 需要存储大量中间结果,内存占用较大
- 对数据预处理敏感:XGBoost 对数据预处理要求较高,需确保数据规范化和特征选择合理
XGBoost 方法在处理复杂数据和提高模型准确性方面具有显著优势,适用于多种机器学习任务
更多内容,见微*公号往期文章:不愧是腾讯,问基础巨细节 。。。
[ 抱个拳,总个结 ]
集成学习算法通过结合多个基模型的预测结果来提高模型的性能。常见的集成学习算法包括 Bagging、Boosting、随机森林、Adaboost、GBDT 和 XGBoost。每种算法都有其独特的优势和适用场景。
9.1 各算法的比较
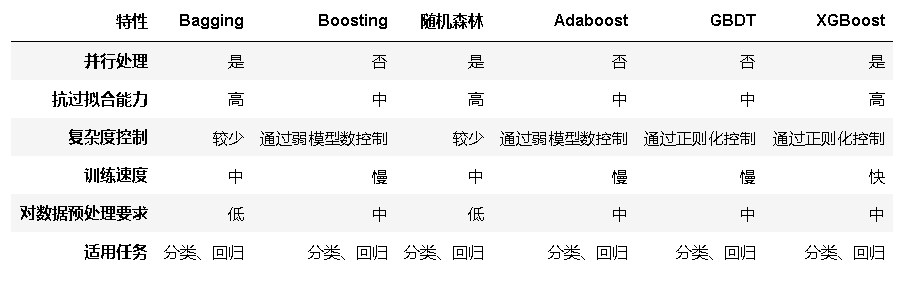
Bagging vs Boosting:
- Bagging(如随机森林)主要通过并行训练多个基模型来减少方差,防止过拟合。它在处理高维数据和噪声数据时表现出色,适用于多种任务
- Boosting(如 Adaboost 和 GBDT)通过串行训练多个基模型来逐步减少模型偏差。它更适合处理复杂的非线性关系,但训练时间较长,对数据预处理要求较高
随机森林 vs GBDT:
- 随机森林是 Bagging 的一种实现,通过构建大量的决策树来提高模型性能。它具有较高的抗过拟合能力和训练速度,但在处理复杂非线性关系时可能表现不如 GBDT
- GBDT 是 Boosting 的一种实现,通过逐步拟合残差来提高模型性能。它在处理复杂非线性关系和高维数据方面表现出色,但训练时间较长,参数调整复杂
XGBoost:
- XGBoost 是 GBDT 的增强版,通过引入正则化、并行处理和二阶导数信息等技术,显著提高了模型的准确性和训练速度。它在各种机器学习竞赛和实际项目中表现优异,适用于多种任务
9.2 实际应用中的选择指南
选择集成学习算法时应考虑以下因素:
- 数据特性:
- 数据维度较高且噪声较多时,Bagging 和随机森林表现较好
- 数据关系复杂且存在非线性特征时,Boosting、GBDT 和 XGBoost 更为适用
- 模型性能:
- 需要高准确率和稳定性的任务,优先选择 XGBoost 或 GBDT
- 需要快速训练和较低复杂度的任务,可以选择 Bagging 或随机森林
- 计算资源:
- 有足够的计算资源和时间,可以选择 XGBoost 或 GBDT 以获得最佳性能
- 资源有限或时间紧迫时,Bagging 和随机森林是更好的选择
- 过拟合风险:
- 数据量较小或过拟合风险较高时,选择具有较高抗过拟合能力的算法,如 Bagging、随机森林和 XGBoost
综合考虑,在实际应用中选择合适的集成学习算法可以显著提高模型的性能和鲁棒性。以下是一个简要的选择指南:
- Bagging:适用于高维、噪声较多的数据,快速训练,防止过拟合
- Boosting:适用于复杂的非线性关系,逐步减少偏差,提高准确性
- 随机森林:适用于各种任务,具有较高的抗过拟合能力和训练速度
- Adaboost:适用于分类任务,逐步调整样本权重,提高模型性能
- GBDT:适用于处理复杂数据和高维数据,提高模型准确性,但训练时间较长
- XGBoost:适用于各种任务,具有最高的准确性和训练速度,但参数调整复杂
通过合理选择和应用集成学习算法,可以有效提升机器学习模型的性能,为各种实际任务提供强大的解决方案。
接下来,大侠可以具体选定某个算法进行更深入的研究或实践应用。山高路远,江湖再会
- 科研为国分忧,创新与民造福 -

日更时间紧任务急,难免有疏漏之处,还请大侠海涵 内容仅供学习交流之用,部分素材来自网络,侵联删
[ 算法金,碎碎念 ]
全网同名,日更万日,让更多人享受智能乐趣
如果觉得内容有价值,烦请大侠多多 分享、在看、点赞,助力算法金又猛又持久、很黄很 BL 的日更下去;
同时邀请大侠 关注、星标 算法金,围观日更万日,助你功力大增、笑傲江湖
算法金 | 决策树、随机森林、bagging、boosting、Adaboost、GBDT、XGBoost 算法大全的更多相关文章
- 机器学习 —— 决策树及其集成算法(Bagging、随机森林、Boosting)
本文为senlie原创,转载请保留此地址:http://www.cnblogs.com/senlie/ 决策树--------------------------------------------- ...
- Jackknife,Bootstrap, Bagging, Boosting, AdaBoost, RandomForest 和 Gradient Boosting的区别
Bootstraping: 名字来自成语“pull up by your own bootstraps”,意思是依靠你自己的资源,称为自助法,它是一种有放回的抽样方法,它是非参数统计中一种重要的估计统 ...
- 决策树与树集成模型(bootstrap, 决策树(信息熵,信息增益, 信息增益率, 基尼系数),回归树, Bagging, 随机森林, Boosting, Adaboost, GBDT, XGboost)
1.bootstrap 在原始数据的范围内作有放回的再抽样M个, 样本容量仍为n,原始数据中每个观察单位每次被抽到的概率相等, 为1/n , 所得样本称为Bootstrap样本.于是可得到参数θ的 ...
- bootstrap && bagging && 决策树 && 随机森林
看了一篇介绍这几个概念的文章,整理一点点笔记在这里,原文链接: https://machinelearningmastery.com/bagging-and-random-forest-ensembl ...
- AI学习---分类算法[K-近邻 + 朴素贝叶斯 + 决策树 + 随机森林 ]
分类算法:对目标值进行分类的算法 1.sklearn转换器(特征工程)和预估器(机器学习) 2.KNN算法(根据邻居确定类别 + 欧氏距离 + k的确定),时间复杂度高,适合小数据 ...
- 决策树&随机森林
参考链接: https://www.bilibili.com/video/av26086646/?p=8 <统计学习方法> 一.决策树算法: 1.训练阶段(决策树学习),也就是说:怎么样构 ...
- scikit-learn机器学习(四)使用决策树做分类,并画出决策树,随机森林对比
数据来自 UCI 数据集 匹马印第安人糖尿病数据集 载入数据 # -*- coding: utf-8 -*- import pandas as pd import matplotlib matplot ...
- 机器学习--boosting家族之XGBoost算法
一.概念 XGBoost全名叫(eXtreme Gradient Boosting)极端梯度提升,经常被用在一些比赛中,其效果显著.它是大规模并行boosted tree的工具,它是目前最快最好的开源 ...
- 随机森林(Random Forest),决策树,bagging, boosting(Adaptive Boosting,GBDT)
http://www.cnblogs.com/maybe2030/p/4585705.html 阅读目录 1 什么是随机森林? 2 随机森林的特点 3 随机森林的相关基础知识 4 随机森林的生成 5 ...
- Adaboost和随机森林
在集成学习中,主要分为bagging算法和boosting算法.随机森林属于集成学习(Ensemble Learning)中的bagging算法. Bagging和Boosting的概念与区别该部分主 ...
随机推荐
- dotnet 使用 XWT 构建跨平台客户端 入门篇
本文告诉大家如何入门开始开发一个基于 mono 组织开源的 XWT 跨平台客户端 UI 框架的应用,本文的 xwt 是在 GitHub 上完全开源的,基于 MIT 协议的,底层采用 GTK# 的 UI ...
- 我用 GitHub 9.8k 的 Go 语言 2D 游戏引擎写了个游戏
前言 hi,大家好,这里是白泽.今天给大家分享一个 GitHub 9.8k 的 Go 语言 2D 游戏引擎. https://github.com/hajimehoshi/ebiten 引擎的贡献者依 ...
- java代码审计跨站脚本(XSS)--反射型
一.基础:跨站脚本(Xss) 一.原理: 恶意攻击者往web页面里插入恶意js代码,而在服务端没有对数据进行严格的过滤.当用户浏览页面时,js代码必须在该html页面中(hrml必须要存在这个而已艾玛 ...
- Xcode多进程调试:WKWebView
由于WKWebView使用的是多线程架构,渲染模块和网络模块都各自在一个单独的进程里面,因此,如果需要设置渲染模块或者网络模块里面的断点,需要做一些特殊处理. 举个例子,假设在Xcode里面设置了渲染 ...
- Spring环境获取Spring的Bean
一.测试数据准备 /* Navicat Premium Data Transfer Source Server : swp-mysql Source Server Type : MySQL Sourc ...
- pageoffice6 版本实现在线打开word 文件禁止保存、禁止另存、禁止打印的需求
在实际项目需求中,有时需要限制用户的保存.另存.打印文件操作,实现此效果只需在OnPageOfficeCtrlInit或AfterDocumentOpened事件中调用js设置PageOffice控件 ...
- es部署
部署单机版es tar xf elasticsearch-7.16.0-linux-x86_64.tar.gz./bin/elasticsearch -dcan not run elasticsear ...
- 食道测压结合Manoview软件
我认为是位于食道开始的地方是上食道括约肌(UES):upper esophageal sphincte,吞咽时,此处的压力会有变大.食道结束的地方是食道下括约肌(LES),从这在往下就是胃,一般情况这 ...
- C# wpf 使用 polyline 做一个贪吃蛇游戏的小蛇移动吃食部分功能
wpf中 polyline 里有一个存放Point的集合,方向靠蛇头的前两个点的向量旋转控制.我发现,靠计算向量来旋转十分的方便.蛇的移动,就是按照蛇头计算的向量,加一个移动长度,然后得到新的点,然后 ...
- 解密Prompt系列30. LLM Agent之互联网冲浪智能体
这一章我们介绍能自主浏览操作网页的WebAgent们和相关的评估数据集,包含初级任务MiniWoB++,高级任务MIND2WEB,可交互任务WEBARENA,多模态WebVoyager,多轮对话Web ...