NebulaGraph实战:2-NebulaGraph手工和Python操作
图数据库是专门存储庞大的图形网络并从中检索信息的数据库。它可以将图中的数据高效存储为点(Vertex)和边(Edge),还可以将属性(Property)附加到点和边上。本文以示例数据集basketballplayer为例,通过nGQL操作和Python脚本两种方式构建图谱。数据[10]和代码[9]详见参考文献。
一.示例数据集介绍
1.数据集Schema
点包括player(球员)和team(球队),边包括serve(球员->球队)和follow(球员->球员):
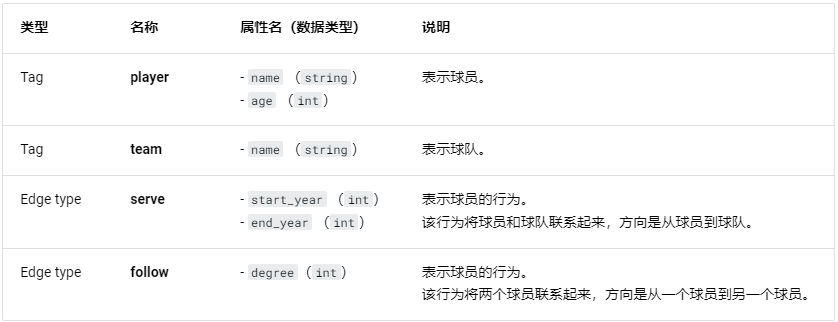
下面是数据集的一个展示例子,如下所示:
2.vertex_player.csv
球员player点数据包括player_id(球员id)、age(年龄)和name(名字):
player105 31 Danny Green
player109 34 Tiago Splitter
player111 38 David West
player118 30 Russell Westbrook
player143 23 Kristaps Porzingis
player104 32 Marco Belinelli
player107 32 Aron Baynes
player116 34 LeBron James
player120 29 James Harden
player125 41 Manu Ginobili
3.vertex_team.csv
球队team点数据包括team_id(球对id)和name(名字):
team204 Spurs
team218 Raptors
team229 Heat
team202 Rockets
team208 Kings
team216 Cavaliers
team217 Celtics
team223 Knicks
team224 Pistons
team205 Thunders
4.edge_serve.csv
serve边数据包括player_id(球员id)、team_id(球对id)、start_year(开始年)和end_year(结束年):
player100 team204 1997 2016
player101 team204 1999 2018
player101 team215 2018 2019
player102 team203 2006 2015
player102 team204 2015 2019
player103 team204 2017 2019
player103 team208 2013 2017
player103 team212 2006 2013
player103 team218 2013 2013
player104 team200 2007 2009
5.edge_follow.csv
follow边数据包括player_id(球员id)、player_id(球员id)和degree(程度):
player100 player101 95
player100 player125 95
player101 player100 95
player101 player102 90
player101 player125 95
player102 player100 75
player102 player101 75
player103 player102 70
player104 player100 55
player104 player101 50
二.nGQL操作构建图谱
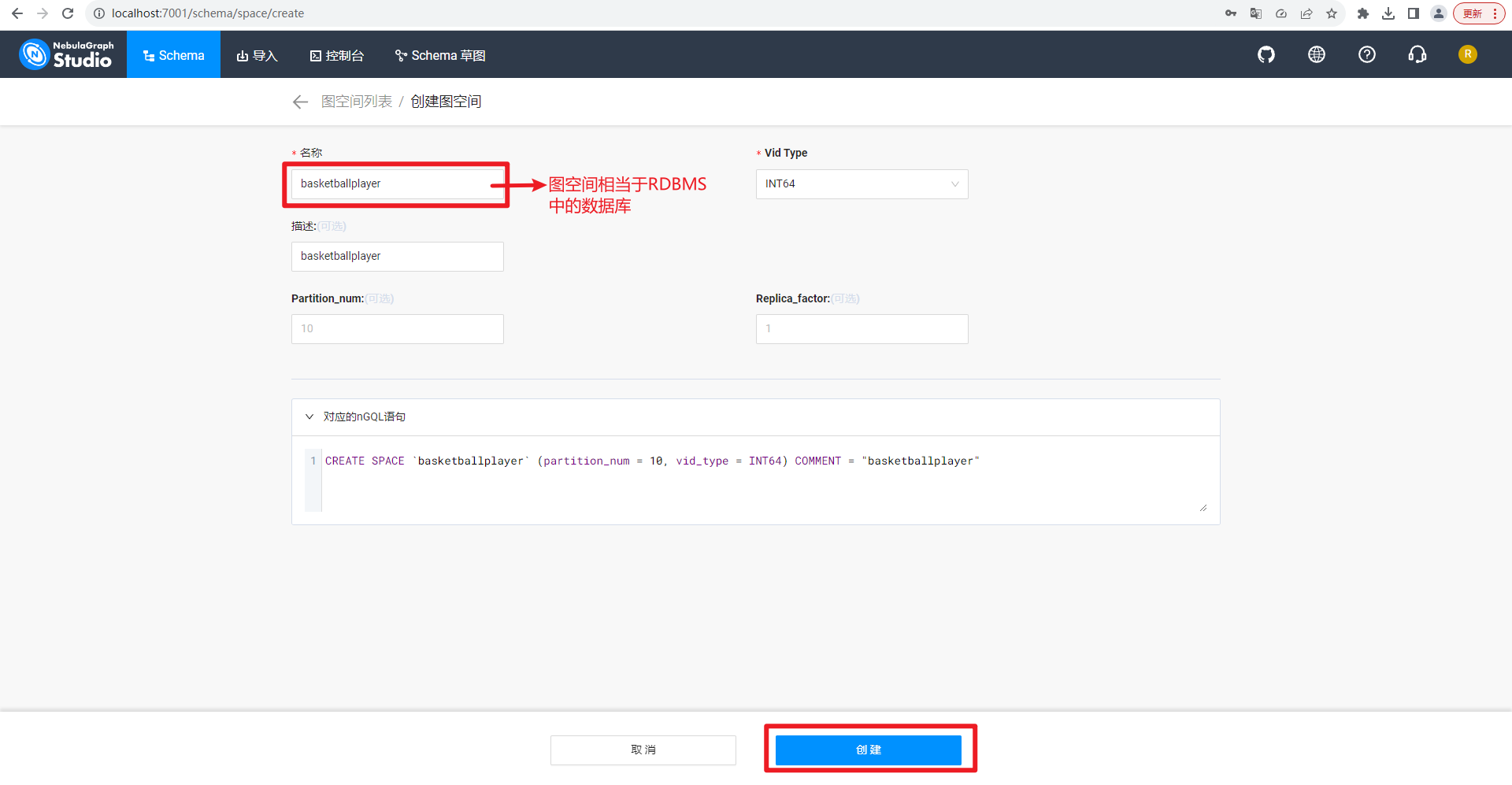
创建图空间,包括名字和Vid Type,如下所示:
查看图空间列表,如下所示:
接下来通过命令创建Tag(点)和Edge type(边),如下所示:
// 创建Tag player,带有2个属性
CREATE TAG player(name string, age int);
// 创建Tag team,带有1个属性
CREATE TAG team(name string);
// 创建Edge type follow,带有1个属性
CREATE EDGE follow(degree int);
// 创建Edge type serve,带有2个属性
CREATE EDGE serve(start_year int, end_year int);
创建完毕后,在控制台通过NGQL查看点和边信息,如下所示:
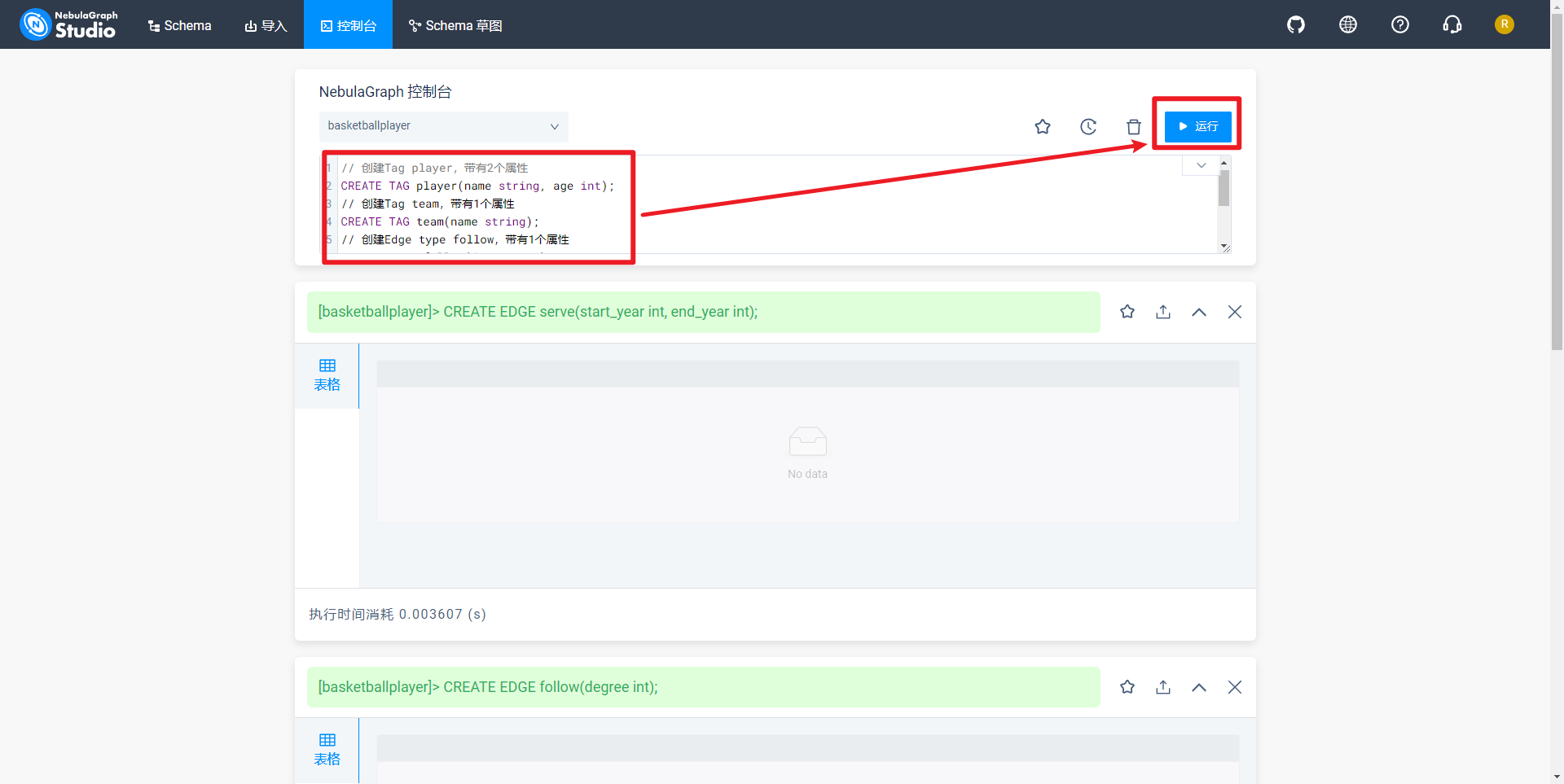
接下来查看当前图空间中所有Tag和Edge type,如下所示:
SHOW TAGS; // 列出当前图空间中所有Tag
SHOW EDGES; // 列出当前图空间中所有Edge type
// 查看每种Tag和Edge type的结构是否正确
DESCRIBE TAG player;
DESCRIBE TAG team;
DESCRIBE EDGE follow;
DESCRIBE EDGE serve;
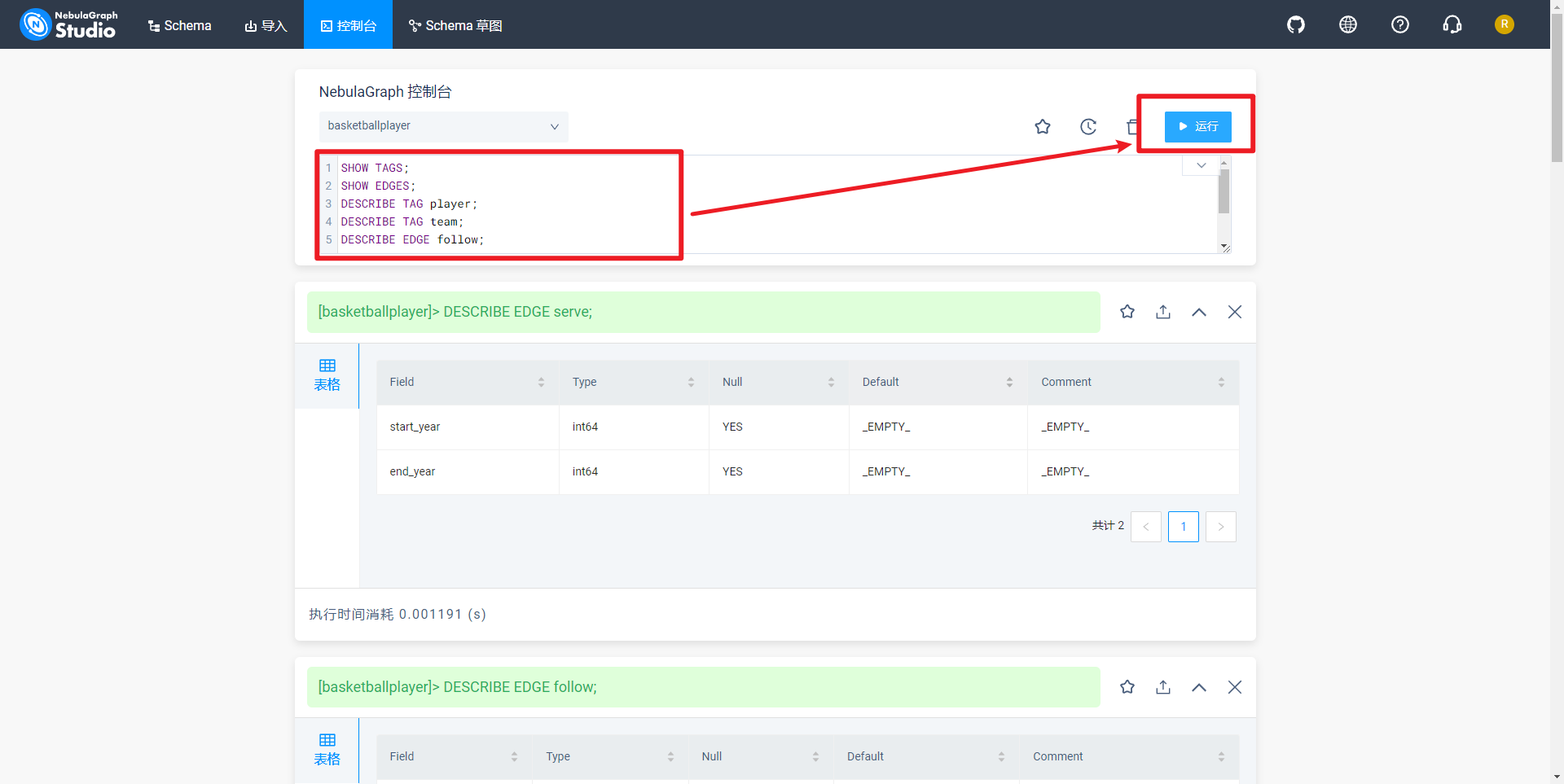
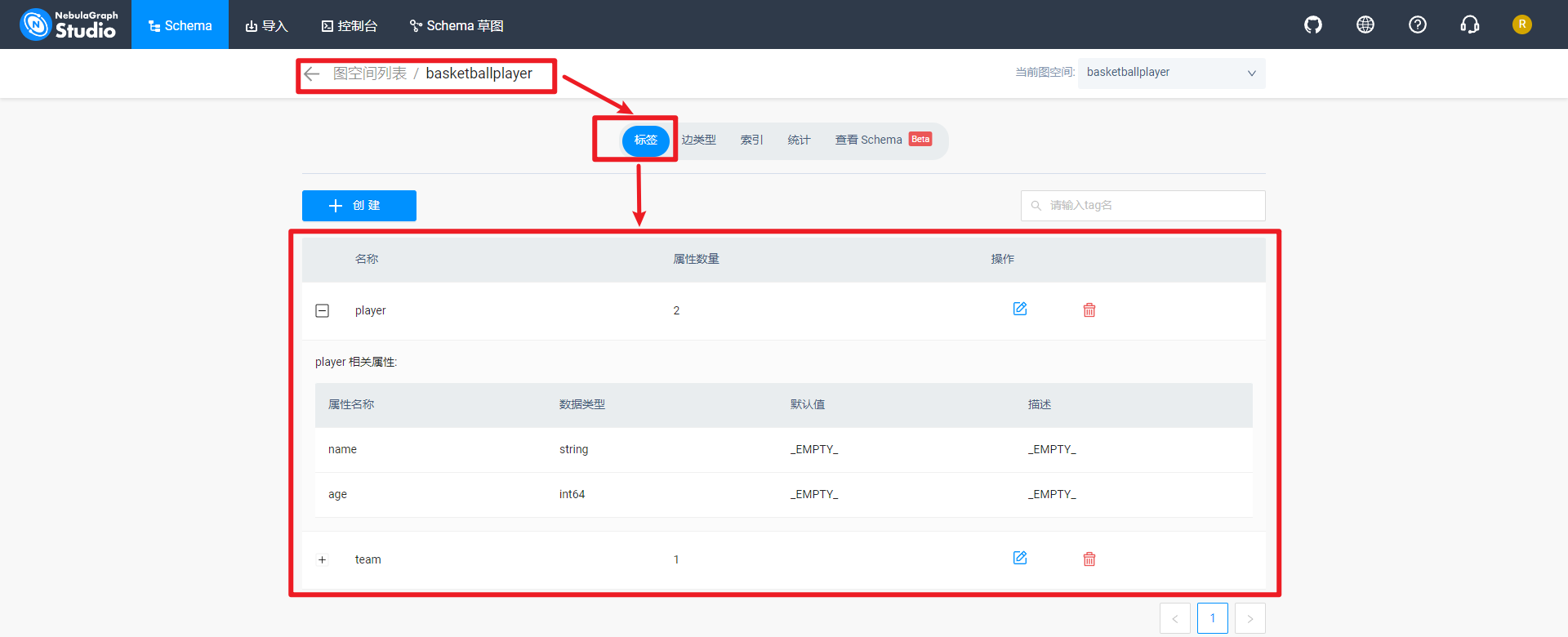
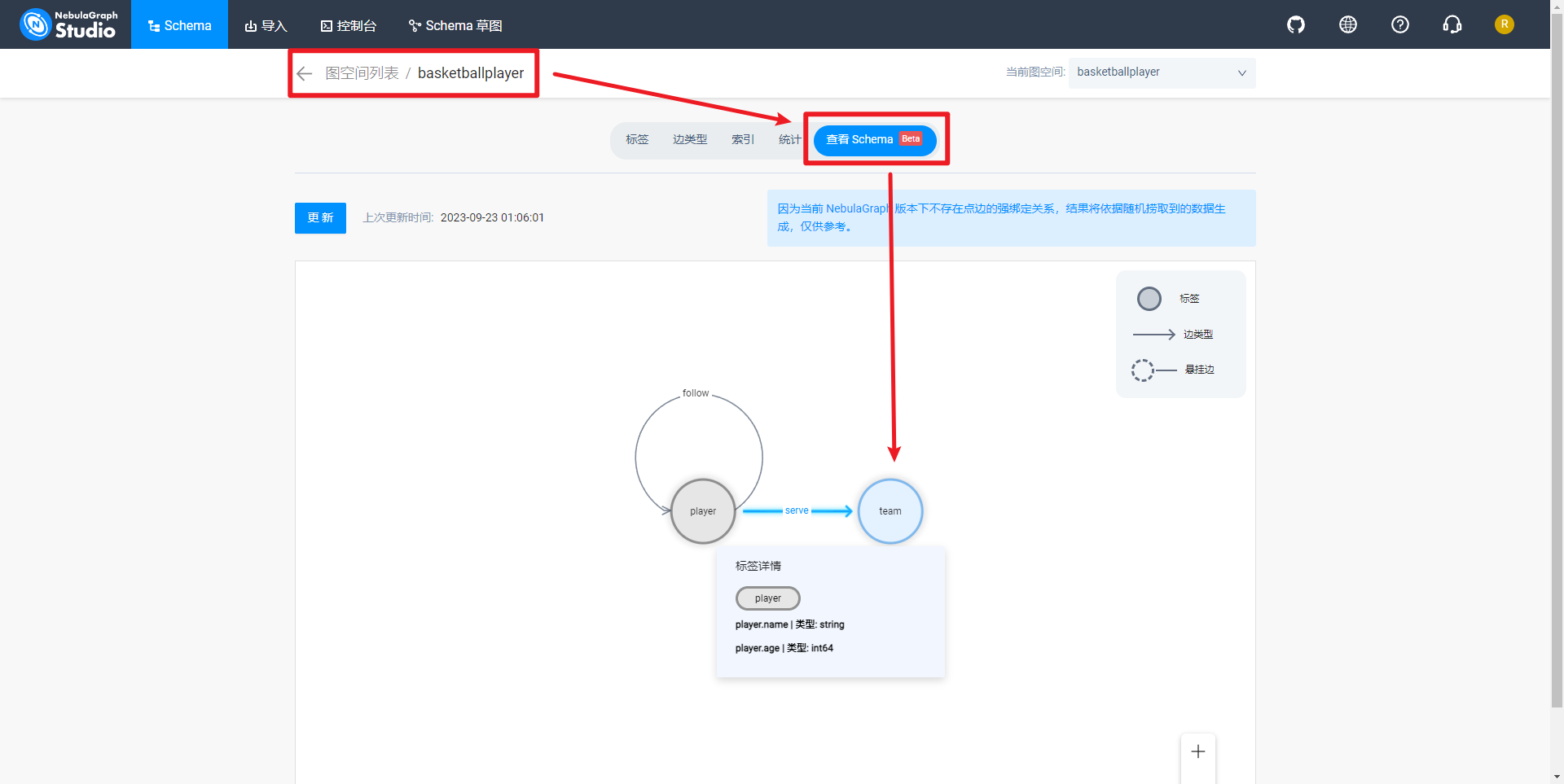
查看图空间basketballplayer标签,如下所示:
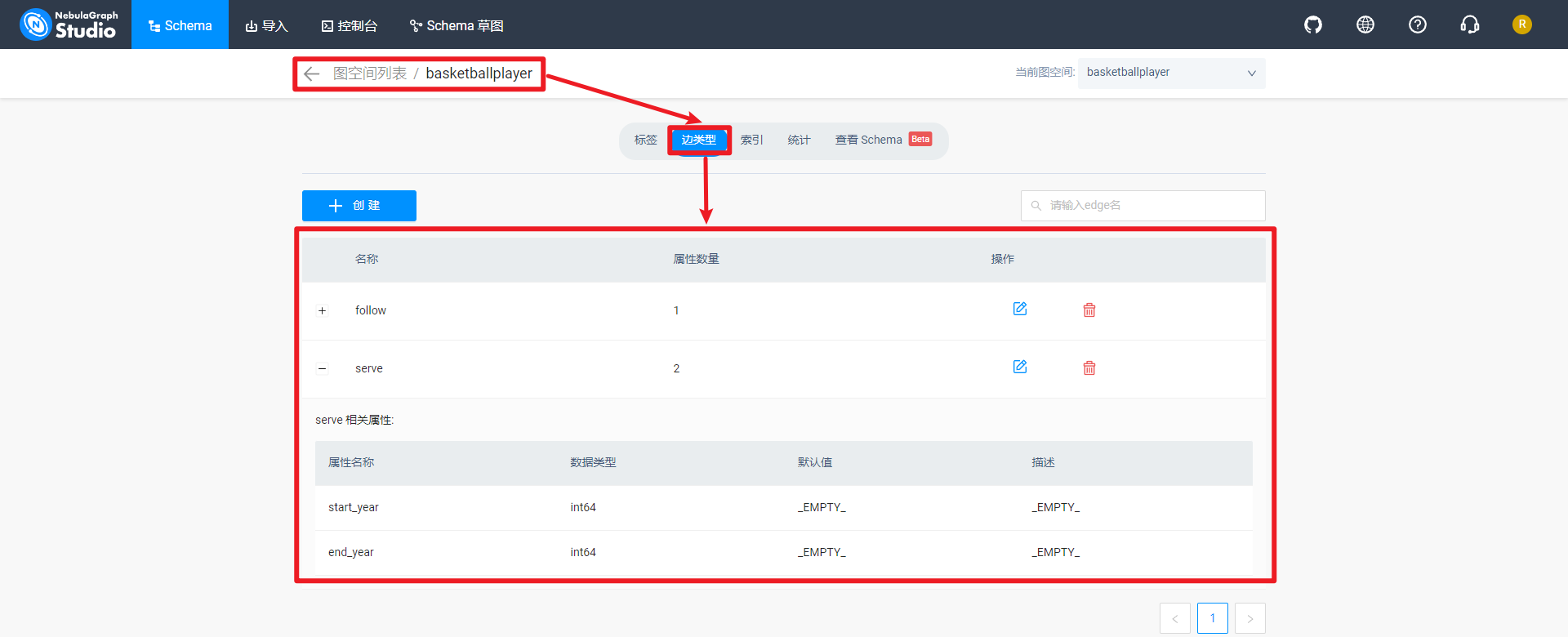
查看图空间basketballplayer边类型,如下所示:
然后分别导入关联标签和关联边,这步骤是重点,主要是关联好列字段,如下所示:
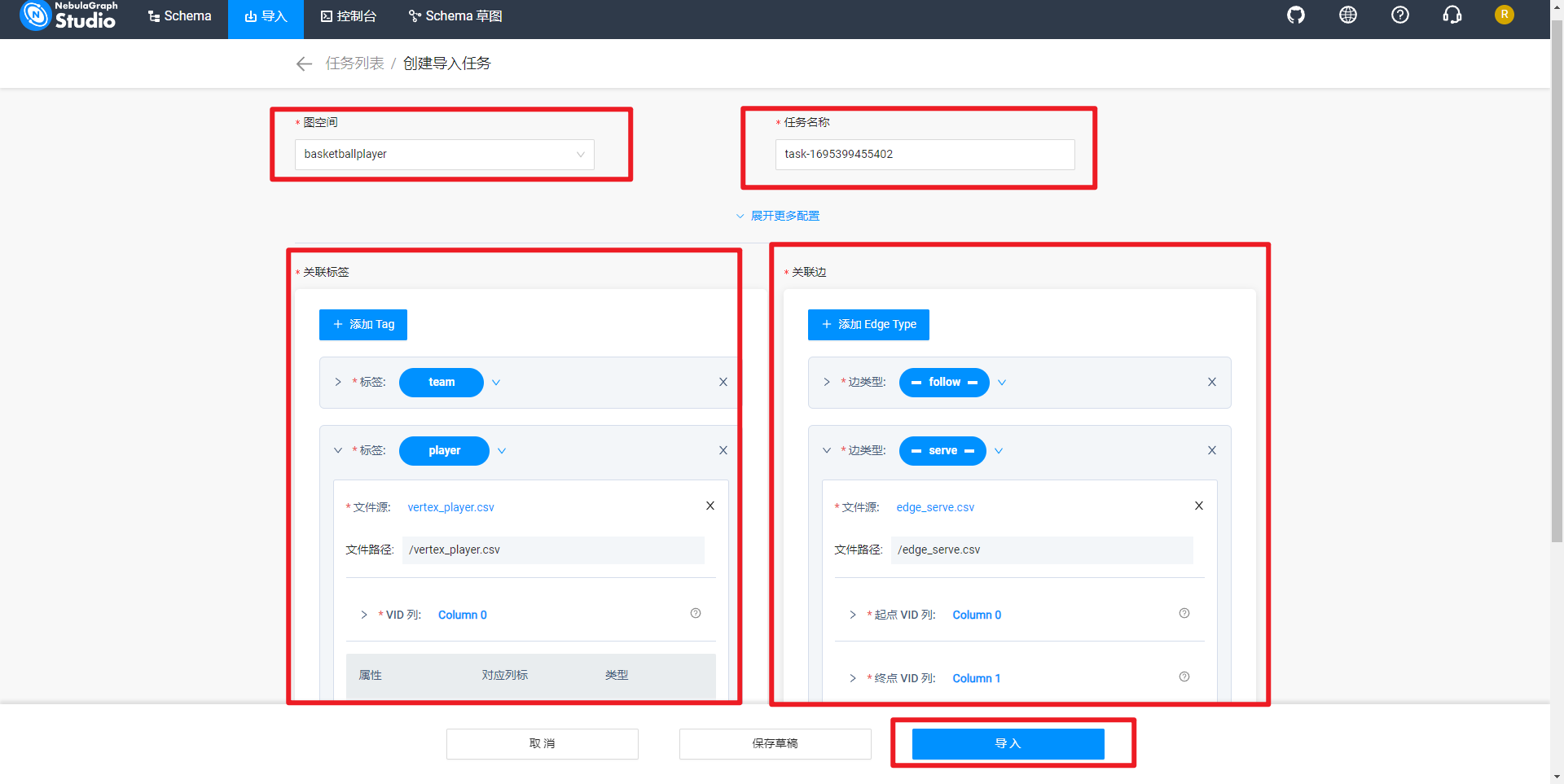
说明:VID函数选择Hash,否则导入失败。
通过任务列表查看导入信息,如下所示:
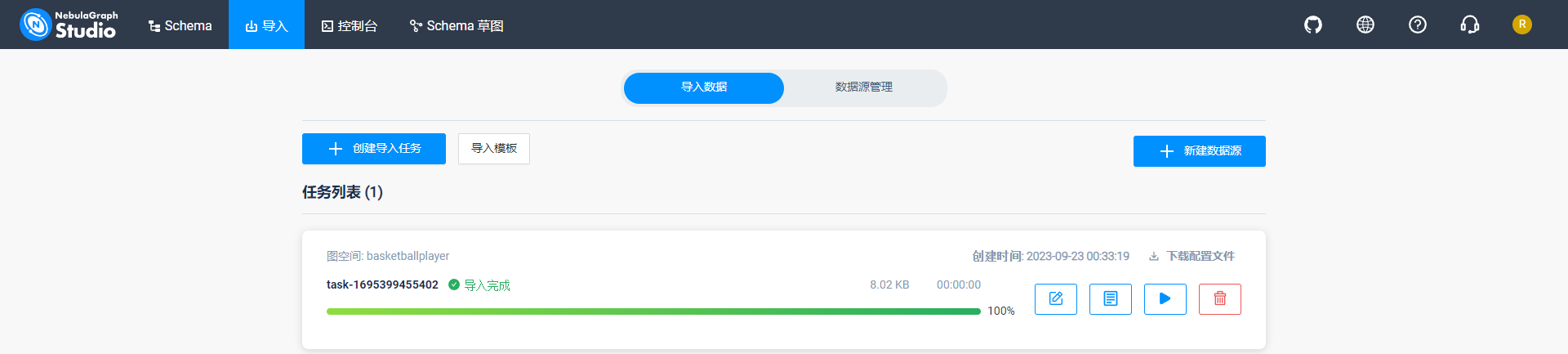
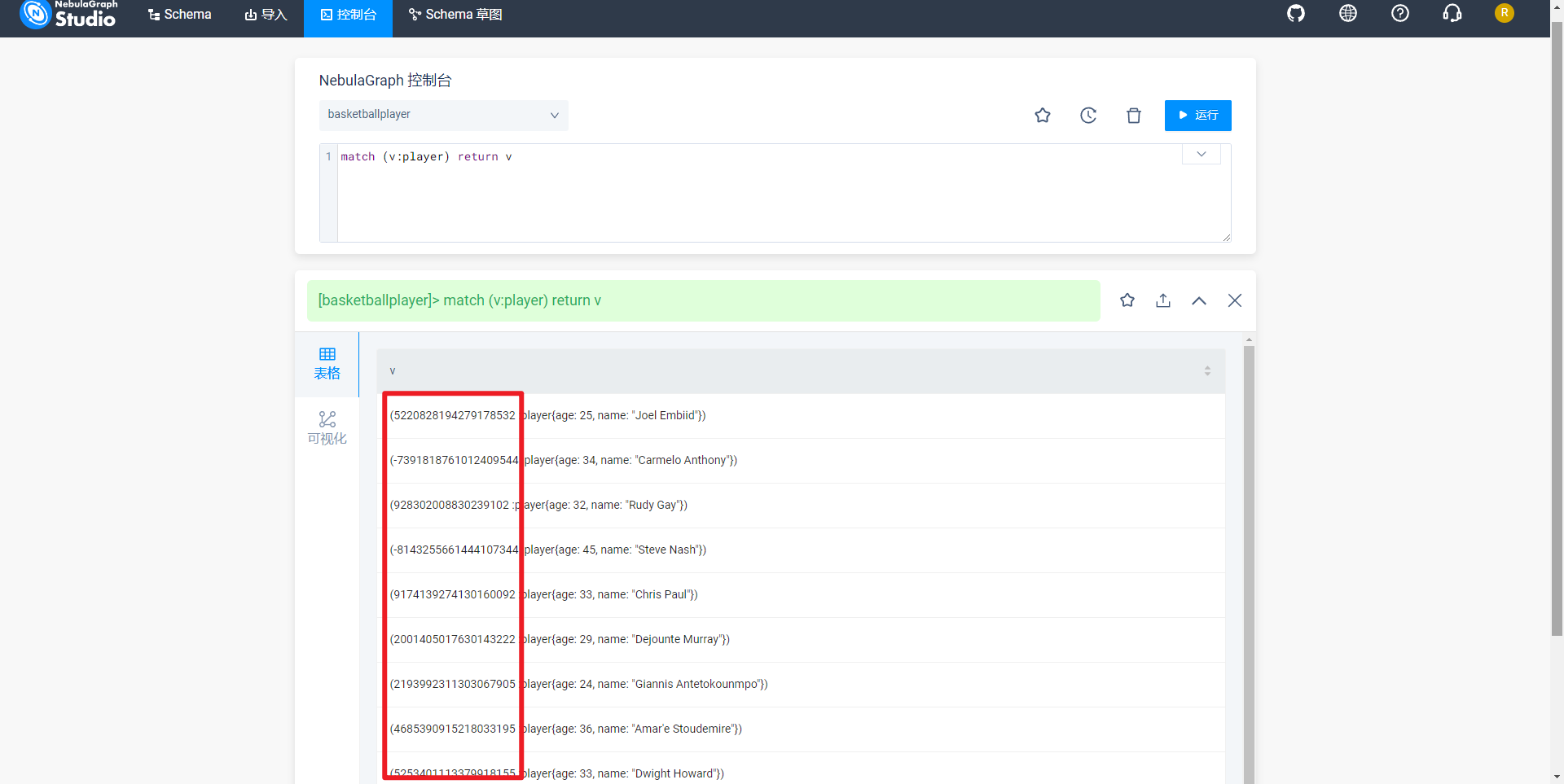
特别说明:显示节点数值而非名字,推测可能和创建图空间时,与选择的Vid Type有关。这次选择的INT64,下次选择FIXED_STRING试试。
通过NebulaGraph控制台,执行命令查看如下所示:
三.Python脚本构建图谱
上述通过nGQL命令进行操作,当数据量大的时候,最好通过脚本进行处理,如下所示:
from nebula3.gclient.net import ConnectionPool
from nebula3.Config import Config
import numpy as np
import pandas as pd
config = Config() # 定义一个配置
config.max_connection_pool_size = 10 # 设置最大连接数
connection_pool = ConnectionPool() # 初始化连接池
# 如果给定的服务器是ok的,返回true,否则返回false
ok = connection_pool.init([('172.27.211.84', 9669)], config)
vertex_player_df = pd.read_csv("C:/Users/Administrator/Downloads/dataset/dataset/vertex_player.csv", header=None, names=['player_id', 'age', 'name'])
vertex_team_df = pd.read_csv("C:/Users/Administrator/Downloads/dataset/dataset/vertex_team.csv", header=None, names=['team_id', 'name'])
edge_follow_df = pd.read_csv("C:/Users/Administrator/Downloads/dataset/dataset/edge_follow.csv", header=None, names=['player_id1', 'player_id2', 'degree'])
edge_serve_df = pd.read_csv("C:/Users/Administrator/Downloads/dataset/dataset/edge_serve.csv", header=None, names=['player_id', 'team_id', 'start_year', 'end_year'])
# Session Pool,session将自动释放
with connection_pool.session_context('root', 'nebula') as session:
# 创建basketballplayer_python空间
session.execute('CREATE SPACE IF NOT EXISTS `basketballplayer_python_test` (vid_type = FIXED_STRING(32))')
# result = session.execute('SHOW SPACES')
# print(result)
# 使用basketballplayer_python空间
session.execute('USE basketballplayer_python')
session.execute('CREATE TAG IF NOT EXISTS player(name string, age int)') # 创建player标签
session.execute('CREATE TAG IF NOT EXISTS team(name string)') # 创建team标签
session.execute('CREATE EDGE IF NOT EXISTS follow(degree int)') # 创建follow边
session.execute('CREATE EDGE IF NOT EXISTS serve(start_year int, end_year int)') # 创建serve边
# 从CSV文件中读取数据,插入到player标签中
for index, row in vertex_player_df.iterrows():
session.execute('INSERT VERTEX IF NOT EXISTS player(name, age) VALUES "{}":("{}", {})'.format(row['player_id'], row['name'], np.int64(row['age'])))
# 从CSV文件中读取数据,插入到team标签中
for index, row in vertex_team_df.iterrows():
session.execute('INSERT VERTEX IF NOT EXISTS team(name) VALUES "{}":("{}")'.format(row['team_id'], row['name']))
# 从CSV文件中读取数据,插入到follow边中
for index, row in edge_follow_df.iterrows():
session.execute('INSERT EDGE IF NOT EXISTS follow(degree) VALUES "{}"->"{}":({})'.format(row['player_id1'], row['player_id2'], np.int64(row['degree'])))
# 从CSV文件中读取数据,插入到serve边中
for index, row in edge_serve_df.iterrows():
session.execute('INSERT EDGE IF NOT EXISTS serve(start_year, end_year) VALUES "{}"->"{}":({}, {})'.format(row['player_id'], row['team_id'], np.int64(row['start_year']), np.int64(row['end_year'])))
# 关闭连接池
connection_pool.close()
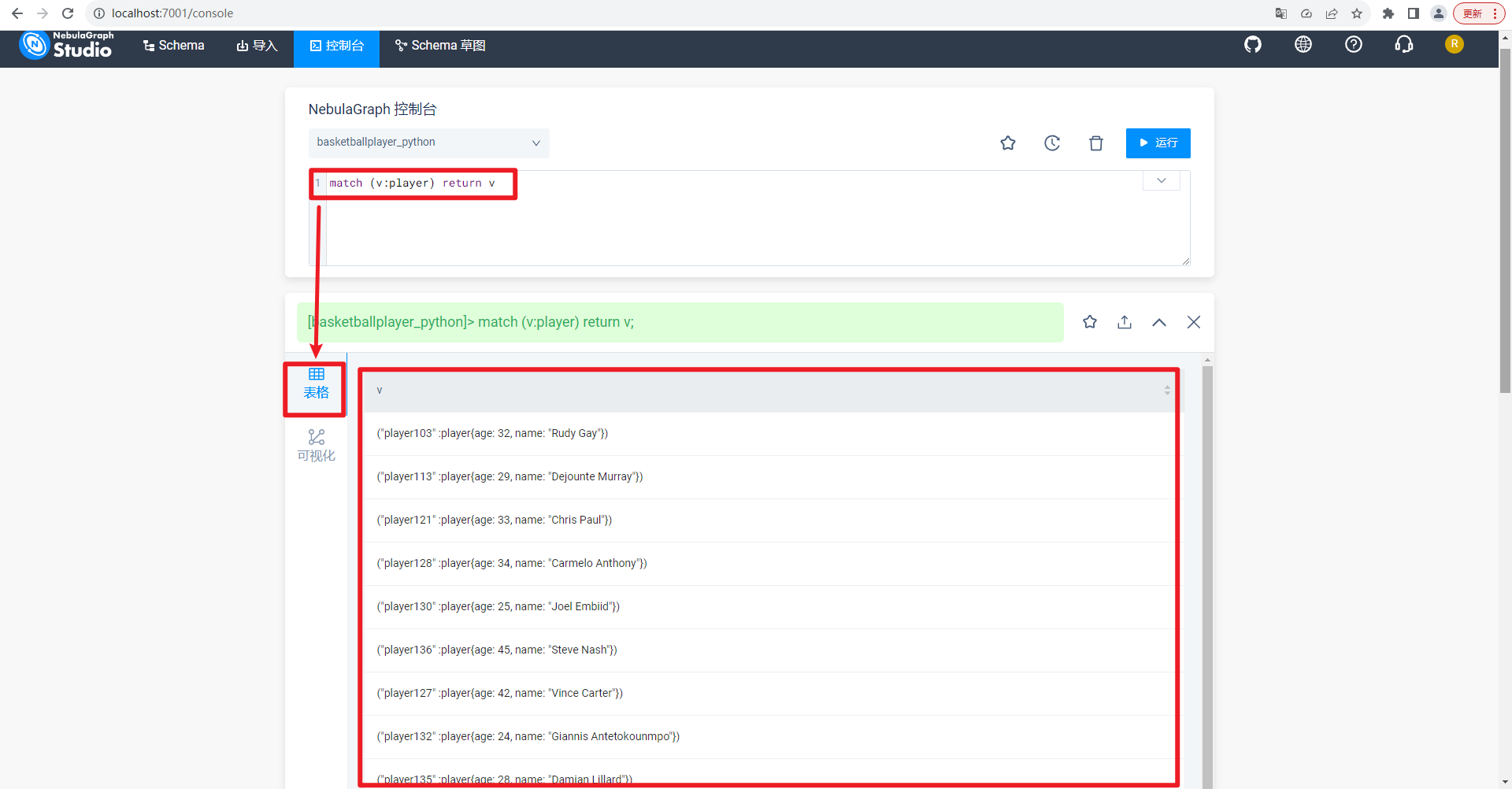
通过NebulaGraph控制台,执行命令match (v:player) return v;。结果以表格形式展现,如下所示:
结果以可视化形式展现,如下所示:
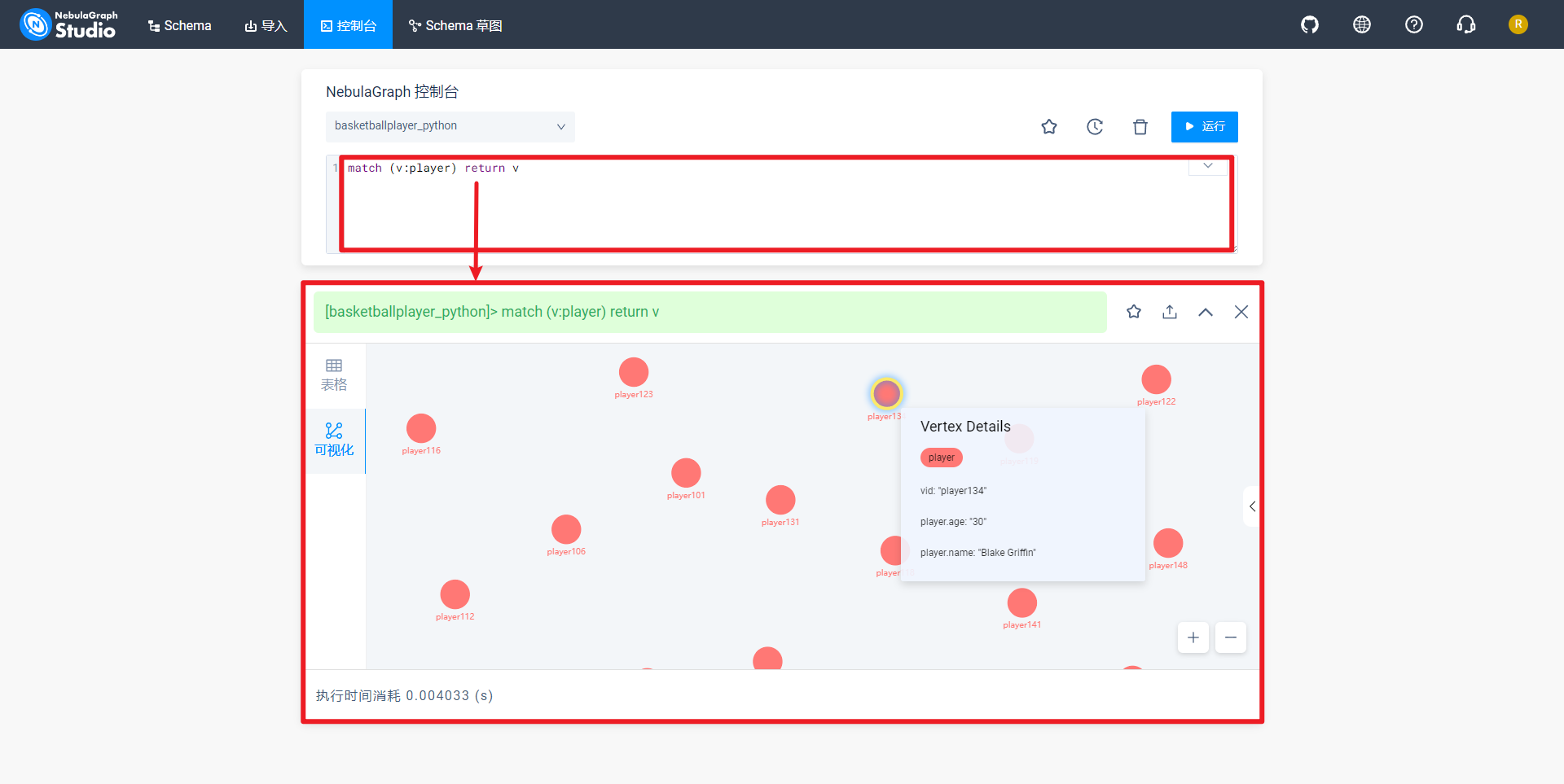
说明:由于代码简单,就不详细介绍了,可参考代码注释[9]。
参考文献:
[1]规划Schema:https://docs.nebula-graph.com.cn/3.3.0/nebula-studio/quick-start/st-ug-plan-schema/
[2]导入数据:https://docs.nebula-graph.com.cn/3.6.0/nebula-studio/quick-start/st-ug-import-data/
[3]控制台界面:https://docs.nebula-graph.com.cn/3.6.0/nebula-studio/quick-start/st-ug-console/
[4]操作图空间:https://docs.nebula-graph.com.cn/3.6.0/nebula-studio/manage-schema/st-ug-crud-space/
[5]操作Tag(点类型):https://docs.nebula-graph.com.cn/3.6.0/nebula-studio/manage-schema/st-ug-crud-tag/
[6]操作Edge type:https://docs.nebula-graph.com.cn/3.6.0/nebula-studio/manage-schema/st-ug-crud-edge-type/
[7]操作索引:https://docs.nebula-graph.com.cn/3.6.0/nebula-studio/manage-schema/st-ug-crud-index/
[8]查看Schema:https://docs.nebula-graph.com.cn/3.6.0/nebula-studio/manage-schema/st-ug-view-schema/
[9]本文源码:https://github.com/ai408/nlp-engineering/blob/main/20230917_NLP工程化公众号文章/NebulaGraph教程/basketballplayer.py
[10]本文数据:basketballplayer.zip: https://url39.ctfile.com/f/2501739-944592417-0f75d0?p=2096 (访问密码: 2096)
NebulaGraph实战:2-NebulaGraph手工和Python操作的更多相关文章
- Python接口测试实战3(上)- Python操作数据库
如有任何学习问题,可以添加作者微信:lockingfree 课程目录 Python接口测试实战1(上)- 接口测试理论 Python接口测试实战1(下)- 接口测试工具的使用 Python接口测试实战 ...
- python操作三大主流数据库(14)python操作redis之新闻项目实战②新闻数据的展示及修改、删除操作
python操作三大主流数据库(14)python操作redis之新闻项目实战②新闻数据的展示及修改.删除操作 项目目录: ├── flask_redis_news.py ├── forms.py ├ ...
- python操作三大主流数据库(10)python操作mongodb数据库④mongodb新闻项目实战
python操作mongodb数据库④mongodb新闻项目实战 参考文档:http://flask-mongoengine.readthedocs.io/en/latest/ 目录: [root@n ...
- kafka实战教程(python操作kafka),kafka配置文件详解
kafka实战教程(python操作kafka),kafka配置文件详解 应用往Kafka写数据的原因有很多:用户行为分析.日志存储.异步通信等.多样化的使用场景带来了多样化的需求:消息是否能丢失?是 ...
- Python操作数据库实战
pymysql # -*- coding: utf-8 -*- """ @Datetime: 2018/12/26 @Author: Zhang Yafei " ...
- 基于Python的接口自动化实战-基础篇之pymysql模块操作数据库
引言 在进行功能或者接口测试时常常需要通过连接数据库,操作和查看相关的数据表数据,用于构建测试数据.核对功能.验证数据一致性,接口的数据库操作是否正确等.因此,在进行接口自动化测试时,我们一样绕不开接 ...
- Python操作Excel
一.系统性学习 对于操作Excel,需要Xlrd/xlwt这两个模块,下面推荐出系统性学习的网址: python操作Excel读写--使用xlrd 官方文档 Python 使用 Xlrd/xlwt 操 ...
- python操作数据库PostgreSQL
1.简述 python可以操作多种数据库,诸如SQLite.MySql.PostgreSQL等,这里不对所有的数据库操作方法进行赘述,只针对目前项目中用到的PostgreSQL做一下简单介绍,主要包括 ...
- python操作oracle数据库-查询
python操作oracle数据库-查询 参照文档 http://www.oracle.com/technetwork/cn/articles/dsl/mastering-oracle-python- ...
- 转载 Python 操作 MySQL 的正确姿势 - 琉璃块
Python 操作 MySQL 的正确姿势 收录待用,修改转载已取得腾讯云授权 作者 |邵建永 编辑 | 顾乡 使用Python进行MySQL的库主要有三个,Python-MySQL(更熟悉的名字可能 ...
随机推荐
- ChatGPT API Transition Guide
ChatGPT API Transition Guide How to get started Written by Joshua J.. Updated over a week ago Prompt ...
- .then()方法的意思和用法
then()方法是异步执行. 意思是:就是当.then()前的方法执行完后再执行then()内部的程序,这样就避免了,数据没获取到等的问题. 语法:promise.then(onCompleted, ...
- 关于Windows打印机驱动相关问题-如何利用Java(或其他)调用打印机驱动程序完成原始文件翻译为PCL语言的步骤
前面这些都是问题描述,问题在偏下面 场景:用户电脑上安装了PCL驱动,可通过驱动完成打印. 需求:现在需要提供一种脱离PC端完成文件上传并打印的功能.让用户使用手机或pc未安装驱动时都能打印文件. 目 ...
- YbtOJ 数位DP G.幸运666
日常写点奇奇怪怪的乱搞做法 awa 这题跟前面几道数位 DP 的区别在于让求第 \(n\) 小的数. 虽然我不会求也不想学这个,但我们可以 binary search! 问题就转换为求 \([1,mi ...
- Kurator v0.5.0发布,打造统一的多集群备份与存储体验
本文分享自华为云社区<Kurator v0.5.0正式发布! 打造统一的多集群备份与存储体验>,作者: 云容器大未来 . Kurator 是由华为云推出的开源分布式云原生套件.面向分布式云 ...
- GitHub - 如何对开源项目做出贡献
GitHub - 对项目做出贡献 转载来自git官方教程:https://git-scm.com/book/zh/v2/GitHub-对项目做出贡献 对项目做出贡献 账户已经建立好了,现在我们来了解一 ...
- Java基础知识(纯干货)
基础篇 IDEA 开发 Java项目 卸载JDK 删除Java的安装目录 删除JAVA_HOME 删除path下关于java的目录 java -version 安装JDK17 下载链接:https:/ ...
- 文心一言 VS 讯飞星火 VS chatgpt (138)-- 算法导论11.4 2题
二.用go语言,试写出HASH-DELETE 的伪代码;修改 HASH-INSERT,使之能处理特殊值DELETED. 文心一言: 首先,让我们定义一个基本的哈希表数据结构.这个结构将包括一个存储键值 ...
- 一个基于ASP.NET Core完全开源的CMS 解决方案
本文简介 MixCoreCMS是一个基于.NET Core框架的开源内容管理系统(CMS),提供了丰富的的基础功能和插件,是一款面向未来的企业 Web CMS,可轻松构建任何类型的应用程序.集成了Go ...
- 【Javaweb】implements Serializable是什么意思?反序列化是什么意思?
为了保证数据传输的可靠 性,常常要implements Serializable,为什么? 对象本质上是虚无缥缈的,只是内存中的一个地址,如果想要让对象持久化,让对象在网络上传输,总不可能传送一个内存 ...