【自动化】使用PlayWright+代理IP实现多环境隔离
Playwright是由微软公司2020年初发布的新一代自动化测试工具,相较于目前最常用的Selenium,它仅用一个API即可自动执行Chromium、Firefox、WebKit等主流浏览器自动化操作。
对各种开发语言也有非常好的支持。常用的NodeJs、Java、python都有支持,且有丰富的文档参考。
Python环境下的安装使用
1、安装依赖库
pip install playwright
2、安装浏览器驱动文件
安装好依赖库之后,会自动注册全局命令。下面2种方式都可以快速安装驱动文件(驱动就是内置的浏览器)
python -m playwright install
或者:
playwright install
如果命令是python3,替换为pip3 install 和python3 -m 即可。
网上有非常多的教程。安装并非本文的重点。
多环境隔离的应用场景
常见的如爬虫,可能需要使用代理IP隔离开不同的浏览器进行数据抓取。
像另一些需要多号操作的营销内容,也需要多个浏览器互相隔离开。更高要求的才会使用代理+隔离的方式。
产生完全不一样的浏览器环境。比如大量的号去做不同的事。
还有很多常用的场景。独立干净的浏览器环境+Playwright的自动化。可以实现非常多的有趣的应用。
Playwright启动浏览器有几种模式。我们需要先进行了解。
1、普通的无痕模式,用完即销毁。这种方式下,浏览器的历史记录之类的不会保存。适合用于爬虫性的工作。
代码大致是这样的。
browser = pw.chromium.launch(headless=headless, proxy=my_proxy,
ignore_default_args=ignore_args,
args=default_args)
browserContext = browser.new_context(user_agent=userAgent, storage_state=storage_state)
可以指定UserAgent,这是我们模拟不同操作系统和浏览器数据的必填项。
也可以指定headless无头模式,这样浏览器不会有界面出现。背后去工作。
2、普通的持久模式,需要指定用户的数据目录。实现数据的隔离。
比如1号浏览器存到data1,2号存到data2,数据不会冲突,各干各的事,可以同时登陆一个网站的多个账号,互不影响。
不方便的地方在于,每次执行完任务,浏览器会随着程序关闭而关闭。
copy一段网上的示例
# 获取 google chrome 的本地缓存文件
USER_DIR_PATH = f"C:\\Users\\{getpass.getuser()}\\AppData\Local\Google\Chrome\\User Data"
with sync_playwright() as p:
browser = p.chromium.launch_persistent_context(
# 指定本机用户缓存地址,这是隔离环境的主要点,指定不同的目录存放用户的数据。
user_data_dir=USER_DIR_PATH,
# 接收下载事件,允许下载需要
accept_downloads=True,
# 设置 GUI 模式,可以看到浏览器界面
headless=False,
bypass_csp=True,
slow_mo=1000,
channel="chrome",
)
page = browser.new_page()
page.goto("https://www.cnblogs.com/yoyoketang")
page.pause()
3、直连系统的Chrome。如果系统有Chrome浏览器,playwright可以直接连接,并进行操作。但是需要做一些配置。
这也是我目前用得最多的模式。
核心的原理就是使用CDP连接上Chrome。需要开启Chrome时,指定一个调试端口,供我们远程连接上去使用。
官方提供的具体函数是
pw.chromium.connect_over_cdp(cdp_url, timeout=0)
优点在于:
脚本和浏览器分离。脚本开不开,浏览器都不影响。只是需要自动化的时候,脚本才去工作。
缺点:
就是配置略麻烦。好在封装好之后,就是一次的麻烦,后面也会比较顺畅。
如何封装属于自己的快速启动类,python和java都可以,下次再聊。
下面以Chrome浏览器+动态代理为例构建多个不同的环境
由于Chrome自带的proxy 代理功能并不支持带账号密码的代理方式。
而我们采购的代理,肯定都是有账号密码的。
所以核心点是添加一个插件,配置上代理,能支持http和socks5的代理,并支持账号密码进行连接。
然后再通过python,调用系统的浏览器,产生不同的环境,使用不同的代理IP。就能达到目标。
直接上图
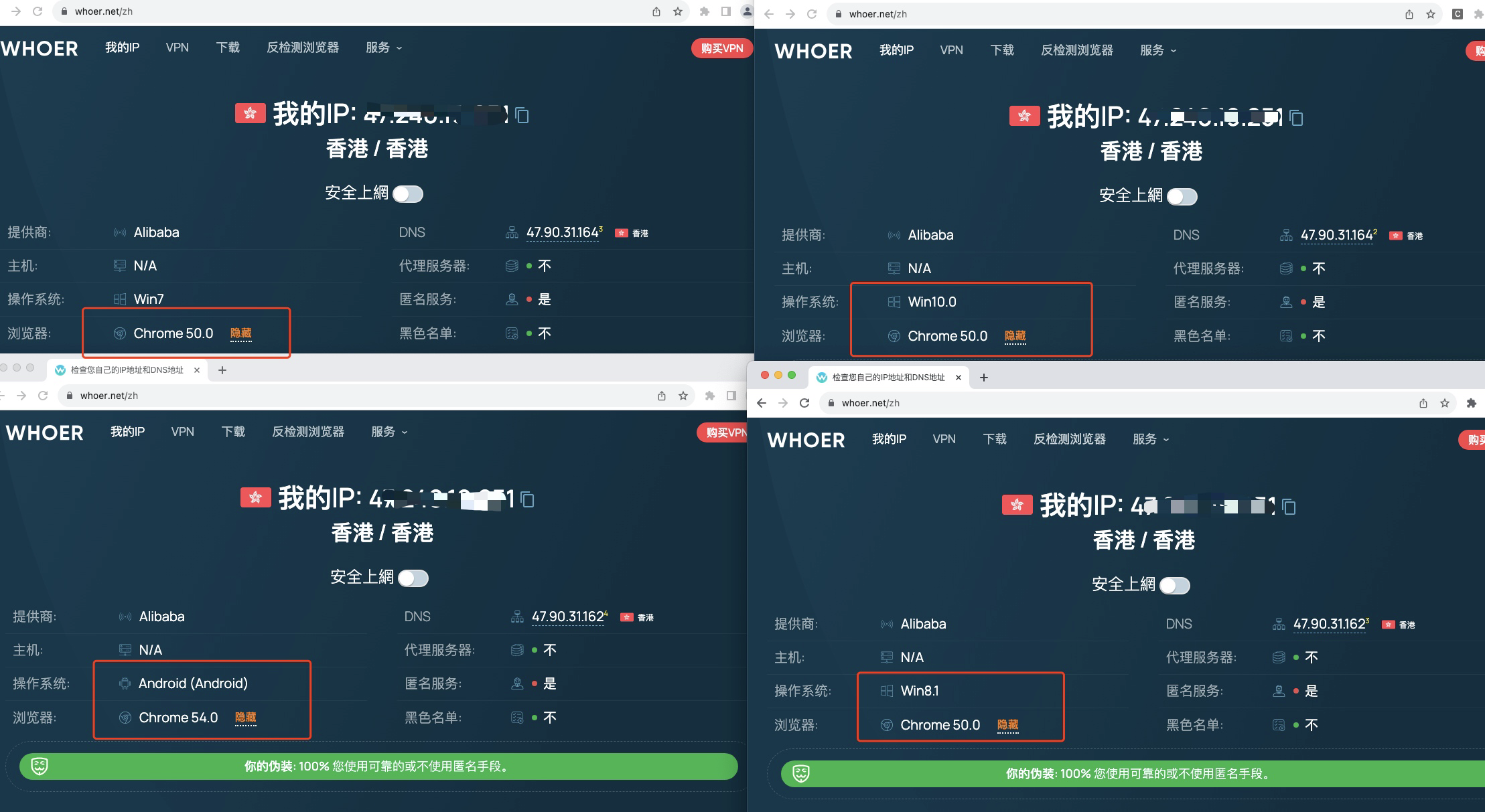
没有好用的收费代理,本地模拟了一个HK节点的代理。
可以看到4个浏览器的指纹已经不一样了。配合上代理,就是干净的环境了。
核心的逻辑在于启用不同的DataDir用户数据目录,加个独立的代理插件来支持http和socks5的代理,
1、核心1,使用python来快速启动Chrome
if sys.platform.startswith('linux'): # Linux
exe_name = 'chrome'
extParam.append('--no-sandbox')
elif sys.platform.startswith('win'): # Windows
win_path = 'C:\Program Files\Google\Chrome\Application\chrome.exe'
exe_name = win_path if os.path.exists(win_path) else 'chrome.exe'
elif sys.platform.startswith('darwin'): # Mac
exe_name = '/Applications/Google Chrome.app/Contents/MacOS/Google Chrome'
extParam.append('--no-sandbox')
# 启用UA
if config.get('user_agent'):
extParam.append(fr'--user-agent="{config.get("user_agent")}"')
# 启用无痕
if config.get('incognito'):
extParam.append('--incognito')
# 无开屏
if config.get('no_window'):
extParam.append('--no-startup-window')
command = fr'"{exe_name}" --remote-debugging-port={port} --user-data-dir="{data_dir}" --no-sandbox --disable-gpu --disable-software-rasterize --disable-background-networking --disable-background-mode --disable-sync --disable-blink-features=AutomationControlled --disable-client-side-phishing-detection --disable-default-apps --disable-desktop-notifications --disable-hang-monitor --disable-infobars --disable-notifications --disable-plugins-discovery --no-first-run --dns-prefetch-disable --ignore-certificate-errors --allow-running-insecure-content --test-type --origin-trial-disabled-features=WebGPU --no-default-browser-check --no-service-autorun --disable-popup-blocking --password-store=basic --disable-web-security --disable-dev-shm-usage --disable-component-update --disable-features=RendererCodeIntegrity --disable-features=FlashDeprecationWarning,EnablePasswordsAccountStorage {" ".join(extParam)}'
os.popen(command)
还有不少代码,就不往上面贴了。
2、核心点2,动态加载插件进不同的Chrome环境,各用各的代理。
def create_proxyauth_extension(proxy_host, proxy_port,
proxy_username, proxy_password,
scheme='http', plugin_dir=None):
"""
代理认证插件,返回代理插件的地址
Chrome使用带账号密码的代理IP
插件来源:https://github.com/henices/Chrome-proxy-helper
参考:https://ask.hellobi.com/blog/cuiqingcai/10307#articleHeader5
https://my.oschina.net/sunboy2050/blog/1858508
https://github.com/aneasystone/selenium-test/blob/master/08-proxy-with-password.py
https://developer.chrome.com/extensions/proxy
args:
proxy_host (str): 你的代理地址或者域名(str类型)
proxy_port (int): 代理端口号(int类型)
proxy_username (str):用户名(字符串)
proxy_password (str): 密码 (字符串)
kwargs:
scheme (str): 代理方式 默认http
plugin_dir (str): 扩展的目录路径
return str -> plugin_path
"""
# 插件目录
if not plugin_dir:
plugin_dir = os.path.join(get_data_dir('chrome_plugin'), f'custom_proxyauth_plugin')
if not os.path.exists(plugin_dir):
os.makedirs(plugin_dir)
# 生成的Zip文件地址
plugin_file = os.path.join(plugin_dir, f"proxy_plugin_{proxy_host}_{proxy_port}.zip")
# 旧文件清理掉
if os.path.exists(plugin_file):
os.remove(plugin_file)
manifest_json = """
{
"version": "1.0.0",
"manifest_version": 2,
"name": "Chrome Proxy",
"permissions": [
"proxy",
"tabs",
"unlimitedStorage",
"storage",
"<all_urls>",
"webRequest",
"webRequestBlocking"
],
"background": {
"scripts": ["background.js"]
},
"minimum_chrome_version":"22.0.0"
}
"""
background_js = string.Template(
"""
var config = {
mode: "fixed_servers",
pacScript: {},
rules: {
singleProxy: {
scheme: "${scheme}",
host: "${host}",
port: ${port}
},
bypassList: ["foobar.com"]
}
};
chrome.proxy.settings.set({value: config, scope: "regular"}, function() {});
function callbackFn(details) {
return {
authCredentials: {
username: "${username}",
password: "${password}"
}
};
}
chrome.webRequest.onAuthRequired.addListener(
callbackFn,
{urls: ["<all_urls>"]},
['blocking']
);
"""
).substitute(
host=proxy_host,
port=proxy_port,
username=proxy_username,
password=proxy_password,
scheme=scheme,
)
# 先写ZIP
with zipfile.ZipFile(plugin_file, 'w') as zp:
zp.writestr("manifest.json", manifest_json)
zp.writestr("background.js", background_js)
# 再手写文件过去
with open(os.path.join(plugin_dir, 'manifest.json'), 'w+') as fi:
fi.write(manifest_json)
with open(os.path.join(plugin_dir, 'background.js'), 'w+') as fi:
fi.write(background_js)
return plugin_file
Java也可以用同样的方式实现。后续配上Java的多线程。相信开100个窗口干活,不是什么难事。
Playwright在下载上传方面,比以前的Selenium要强很多。还有很多功能,下次再分享。
关注我的公众号:青塬科技,定期分享经验文章。
【自动化】使用PlayWright+代理IP实现多环境隔离的更多相关文章
- 使用TaskManager爬取2万条代理IP实现自动投票功能
话说某天心血来潮想到一个问题,朋友圈里面经常有人发投票链接,让帮忙给XX投票,以前呢会很自觉打开链接帮忙投一票.可是这种事做多了就会考虑能不能使用工具来进行投票呢,身为一名程序猿决定研究解决这个问题. ...
- 爬虫平台设置代理ip
首先从国外一个网站爬取了免费的代理ip信息存到mongodb中:接着代码设置: 在爬虫客户端抽象类中添加属性: 设置代理的代码其实就以下几句: firefoxProfile.setPreference ...
- UA池 代理IP池 scrapy的下载中间件
# 一些概念 - 在scrapy中如何给所有的请求对象尽可能多的设置不一样的请求载体身份标识 - UA池,process_request(request) - 在scrapy中如何给发生异常的请求设置 ...
- python爬虫成长之路(二):抓取代理IP并多线程验证
上回说到,突破反爬虫限制的方法之一就是多用几个代理IP,但前提是我们得拥有有效的代理IP,下面我们来介绍抓取代理IP并多线程快速验证其有效性的过程. 一.抓取代理IP 提供免费代理IP的网站还挺多的, ...
- Wireshark抓包分析/TCP/Http/Https及代理IP的识别
前言 坦白讲,没想好怎样的开头.辗转三年过去了.一切已经变化了许多,一切似乎从没有改变. 前段时间调研了一次代理相关的知识,简单整理一下分享之.如有错误,欢迎指正. 涉及 Proxy IP应用 原理/ ...
- python爬虫实战(一)——实时获取代理ip
在爬虫学习的过程中,维护一个自己的代理池是非常重要的. 详情看代码: 1.运行环境 python3.x,需求库:bs4,requests 2.实时抓取西刺-国内高匿代理中前3页的代理ip(可根据需求自 ...
- python使用代理ip发送http请求
一.需求背景 网站刷票时,经常会遇到限制一个ip只能投票一次的限制,为此需要使用代理ip 二.脚本如下: 1.Proxy_http.py使用代理ip发送httpr的get和post请求 #coding ...
- 【原创】验证代理IP是否有用
/// <summary> /// 验证代理IP是否有用 /// </summary> /// <param name="ip">IP地址< ...
- [python]爬代理ip v2.0(未完待续)
爬代理ip 所有的代码都放到了我的github上面, HTTP代理常识 HTTP代理按匿名度可分为透明代理.匿名代理和高度匿名代理. 特别感谢:勤奋的小孩 在评论中指出我文章中的错误. REMOTE_ ...
- 通过爬虫代理IP快速增加博客阅读量——亲测CSDN有效!
写在前面 题目所说的并不是目的,主要是为了更详细的了解网站的反爬机制,如果真的想要提高博客的阅读量,优质的内容必不可少. 了解网站的反爬机制 一般网站从以下几个方面反爬虫: 1. 通过Headers反 ...
随机推荐
- 乌班图安装docker
目录 一.前言 二.安装 2.1 设置仓库 2.3 安装 Docker Engine 2.4 安装特定版本的 Docker Engine: 2.5 测试 三.配置非 root 用户运行 Docker ...
- springboot项目导入外部jar包的bean的几种方式
背景 公司封装了基础包和日志包,将公共的配置抽取出来,供所有项目使用,因此就需要考虑,怎么引入外部jar包的Bean实例: 思考 因为公司的jar包就是普通的jar,不支持springboot的自动配 ...
- ElasticSearch-索引库、文档操作
1.elasticsearch的作用 elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容 2.elasticsearch和lucen ...
- vue-cli3创建多页面应用
首先用vue-cli3创建工程,我的全局安装了vue-cli2,又不想卸载掉:所以新建了一个文件夹安装vue-cli3:然后在该文件夹下创建工程: 同时安装vue-cli2和vue-cli3参考:ht ...
- vscode连不上云服务器,一直报超时错误|但是xshell那些又可以连上?为什么vscode连不上?|命令行输出管道报错 -bash: command not found 导致的一系列问题
前言 那么这里博主先安利一些干货满满的专栏了! 首先是博主的高质量博客的汇总,这个专栏里面的博客,都是博主最最用心写的一部分,干货满满,希望对大家有帮助. 高质量博客汇总https://blog.cs ...
- 小团队如何妙用 JuiceFS
早些年还在 ENJOY 的时候, 就已经在用 JuiceFS, 并且一路伴随着我工作过的四家小公司, 这玩意对我来说, 已经成了理所应当不可或缺的基础设施, 对于我服务过的小团队而言, 更是实实在在的 ...
- yapi 个人空间 这个分组的问题
总结:yapi个人空间分组的问题,我暂时不用理睬 他自己自由,但是 不允许他 创建非个人空间的分组.这点留意 避免不统一.所有的分组都必须我自己来创建,不允许他们私自创建.
- ASP.NET Core分布式项目实战(运行Consent Page)--学习笔记
任务21:运行Consent Page 修改 Config.cs 中的 RequireConsent 为 true,这样登录的时候就会跳转到 Consent 页面 修改 ConsentControll ...
- JS实现一个布隆过滤器
之前专门聊过令牌桶算法,而类似的方案还有布隆过滤器.它一般用于高效地查找一个元素是否在一个集合中. 用js实现如下所示: class BloomFilter { constructor(size, h ...
- 【Android】使用AIDL实现进程间传递对象案例
1 前言 在 Android--使用AIDL实现进程间通讯简单案例 中介绍了使用 AIDL 在进程间传递字符串,对于8种基本数据类型( byte.short.int.long.float.doub ...