Jan 2023-Prioritizing Samples in Reinforcement Learning with Reducible Loss
1 Introduction
本文建议根据样本的可学习性进行抽样,而不是从经验回放中随机抽样。如果有可能减少代理对该样本的损失,则认为该样本是可学习的。我们将可以减少样本损失的数量称为其可减少损失(ReLo)。这与Schaul等人[2016]的vanilla优先级不同,后者只是对具有高损失的样本给予高优先级,这可能会导致数据点的重复采样,而这些数据点由于噪声而无法学习。
本文首先简要描述了当前在从缓冲区中采样时进行优先级排序的方法,然后给出了在强化学习中减少损失的直觉。
这些实验表明,与Hessel等人[2017]中使用的Schaul等人[2016]的损失项相比,基于可减少的损失进行优先级排序是一种更鲁棒的方法(如图1所示),并且可以在不增加任何额外计算复杂度的情况下进行集成。
2 Background
基本概念
2.1 Experience Replay
2.2 Target Networks
2.3 Off-Policy Algorithms
3 Related Work
3.1 Reducible Loss
优先训练在训练开始时保留训练数据的子集来训练小容量模型θho。
在训练期间,这个保留模型用于 衡量一个数据点是否可以在不经过训练的情况下学习
随着持有数据集的大小增加,这种估计变得更加准确。
主模型θ和保留模型在实际训练数据上的损失之间的差异被称为可减少损失Lr,它用于小批量采样中训练数据的优先级排序
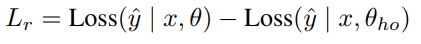
Lr被认为通过对数据点的训练来衡量信息的增益
3.2 Prioritization Schemes
Sinha-2020 提出了一种在当前策略平稳分布下,基于经验的似然度重新加权的方法,以保证重复可见状态值函数的近似误差较小
Lahire-2021介绍了大批量经验回放(LaBER),通过采用 an importance sampling view(重要性采样视图)来估计梯度,以克服PER的优先级过时及其超参数敏感性的问题。LaBER首先从回放缓冲区中采样一个大批次,然后计算梯度范数,最后按优先级向下采样到一个较小大小的小批次。
Kumar-2020提出了分布校正(DisCor),这是一种纠正反馈形式,可以使学习动态更加稳定。DisCor计算最优分布并执行加权Bellman更新以重新加权重放缓冲区中的数据分布。
受DisCor的启发, 后悔最小化经验重放(remn)-2021用an error network(误差网络)估计Q值的次优性。
拓扑经验回放(TER)-2022将智能体的experience组织成a graph(图),该图跟踪状态q值之间的依赖性。
4 Reducible Loss for Reinforcement Learning
受监督学习中优先训练的激励,我们提出了一种针对强化学习问题的优先排序方案,即智能体应该专注于具有更高的可减少TD误差的样本,而不是根据TD误差进行优先级排序,。这意味着,我们应该使用TD误差可以减少多少的度量,而不是TD误差
这意味着算法可以避免重复采样agent无法学习的点,并且可以专注于最小化可学习点的误差,从而提高样本效率
为了确定样本的学习能力,我们需要了解样本的目标是如何表现的,以及它是如何随时间变化的。
强化学习中的训练数据是由变化的策略生成的。因此,holdout model需要不时地更新。
因此,在基于Q学习的强化学习方法中,hold-out模型的一个很好的代理是Eq. 8中Bellman更新中使用的目标网络:
由于目标网络仅使用在线模型参数定期更新,因此它保留了代理在使用过时策略训练的旧数据上的性能。目标网络可以很容易地用作 没有在新样本上训练的hold-out model 的近似值。
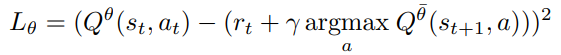
因此,我们将RL的可还原损失(ReLo)定义为数据点相对于在线网络(参数θ)和相对于目标网络(参数¯θ)的损失之差。

- 与PER相比相似之处,优先级方案在低优先级点的采样行为上
对于PER:不重要的数据点具有较低的Lθ,在ReLo中也将保持不重要。
因为如果Lθ很低,那么根据上述公式,ReLo也会很低。
这确保了我们保留了PER的理想行为,即不重复采样已经学习过的点- 不同之处在于存在较大的TD误差的采样点:
对于PER,如果由于转换本身的固有噪声,一个数据点可能具有很高的TD误差,即使在采样多次之后仍然保持很高,但它仍然具有较高的PER优先级。
但是它的优先级应该降低,因为可能有其他数据点更值得采样,因为它们有有用的信息,可以更快地学习。
对于ReLo:这样一个点会很低,因为Lθ和Lθ¯都很高
如果一个数据点被遗忘,那么Lθ将高于Lθ¯,并且ReLo将确保这些点被重新访问。
4.1 Implementation
我们应该为ReLo error创建一个映射fmap,它对所有值都是单调递增且非负的
当目标网络与主网络通过硬更新进行更新时,该值可以归零。然而,在一次更新之后,它很快变成非零
在实践中,我们发现将负值裁剪为零通过添加一个小参数来确保样本有最小概率:
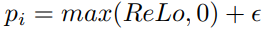
- 由于不需要任何额外的训练,ReLo在计算上并不昂贵。它只涉及通过目标网络的状态的一个额外的前向传递
对于ReLo,唯一需要计算的附加项: Qtgt(st, at)计算Lθ¯。- ReLo也没有引入任何额外的超参数
- ReLo不一定依赖于确切的损失公式;只需要额外计算关于目标网络参数¯θ的Lalg。
如果损失只是均方误差,那么ReLo可以被简化,可以用Qθ和Qθ¯的差来表示。
但对非策略Q学习方法的其他扩展修改了这一目标,例如分布式学习Bellemare等人[2017]最小化KL散度,但不能以相同的方式简化两个KL散度之间的差异。
为了使ReLo成为一种可以跨这些方法使用的通用技术,我们用Lθ和Lθ¯来定义它。
Algorithm 1

Jan 2023-Prioritizing Samples in Reinforcement Learning with Reducible Loss的更多相关文章
- Statistics and Samples in Distributional Reinforcement Learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! arXiv:1902.08102v1 [stat.ML] 21 Feb 2019 Abstract 我们通过递归估计回报分布的统计量,提供 ...
- (转) Deep Reinforcement Learning: Playing a Racing Game
Byte Tank Posts Archive Deep Reinforcement Learning: Playing a Racing Game OCT 6TH, 2016 Agent playi ...
- Awesome Reinforcement Learning
Awesome Reinforcement Learning A curated list of resources dedicated to reinforcement learning. We h ...
- (转) Deep Reinforcement Learning: Pong from Pixels
Andrej Karpathy blog About Hacker's guide to Neural Networks Deep Reinforcement Learning: Pong from ...
- 论文笔记之:Playing Atari with Deep Reinforcement Learning
Playing Atari with Deep Reinforcement Learning <Computer Science>, 2013 Abstract: 本文提出了一种深度学习方 ...
- [Reinforcement Learning] Model-Free Control
上篇总结了 Model-Free Predict 问题及方法,本文内容介绍 Model-Free Control 方法,即 "Optimise the value function of a ...
- [Reinforcement Learning] Model-Free Prediction
上篇文章介绍了 Model-based 的通用方法--动态规划,本文内容介绍 Model-Free 情况下 Prediction 问题,即 "Estimate the value funct ...
- [DQN] What is Deep Reinforcement Learning
已经成为DL中专门的一派,高大上的样子 Intro: MIT 6.S191 Lecture 6: Deep Reinforcement Learning Course: CS 294: Deep Re ...
- (zhuan) Evolution Strategies as a Scalable Alternative to Reinforcement Learning
Evolution Strategies as a Scalable Alternative to Reinforcement Learning this blog from: https://blo ...
- Machine Learning Algorithms Study Notes(5)—Reinforcement Learning
Reinforcement Learning 对于控制决策问题的解决思路:设计一个回报函数(reward function),如果learning agent(如上面的四足机器人.象棋AI程序)在决定 ...
随机推荐
- 痞子衡嵌入式:我为2021 TencentOS Tiny AIoT应用创新大赛做了场直播培训
TencentOS Tiny AIoT 应用创新大赛是腾讯 TencentOS 团队联合恩智浦半导体.安谋科技(Arm China)发起的线上开发者活动,主要面向中小企业嵌入式工程师.广大嵌入式开发者 ...
- D3和X6
D3 版本 d3已经更新到v7版本,中文文档只更新到v4版本,存在部分api不适用和过时问题 使用d3-darge插件布局,插件适配d3版本为v5,近年未更新 API 使用darge中setNode和 ...
- 用Java代码验证三门问题
三门问题(Monty Hall problem)亦称为蒙提霍尔问题,出自美国的电视游戏节目Let's Make a Deal. 问题名字来自该节目的主持人蒙提·霍尔(Monty Hall).参赛者会看 ...
- 「学习笔记」平衡树基础:Splay 和 Treap
「学习笔记」平衡树基础:Splay 和 Treap 点击查看目录 目录 「学习笔记」平衡树基础:Splay 和 Treap 知识点 平衡树概述 Splay 旋转操作 Splay 操作 插入 \(x\) ...
- 基于深度学习的鸟类检测识别系统(含UI界面,Python代码)
摘要:鸟类识别是深度学习和机器视觉领域的一个热门应用,本文详细介绍基于YOLOv5的鸟类检测识别系统,在介绍算法原理的同时,给出Python的实现代码以及PyQt的UI界面.在界面中可以选择各种鸟类图 ...
- java 环境变量配置详细教程(2023 年全网最详细)
前言: 在上一篇文章中,壹哥给大家重点讲解了 Java 实现跨平台的原理,不知道你现在有没有弄清楚呢?如果你还有疑问,可以在评论区留言- 之前的三篇文章,主要是理论性的内容,其实你暂时跳过不看也是可以 ...
- vue2双向绑定原理及源码解析
首先我们要知道VUE实现双向绑定的步骤是什么: 实现一个监听器 Observer 对数据对象进行遍历,包括子属性对象的属性,利用 Object.defineProperty() 对属性都加上 sett ...
- ASP.NET Core - 缓存之内存缓存(上)
1. 缓存 缓存指的是在软件应用运行过程中,将一些数据生成副本直接进行存取,而不是从原始源(数据库,业务逻辑计算等)读取数据,减少生成内容所需的工作,从而显著提高应用的性能和可伸缩性,使用好缓存技术, ...
- Java面向对象--接口和多态
final 关键字 最终修饰符 可以修饰 类 方法 变量 被final修饰后不能被继承 重写 二次赋值 修饰类时 该类不可以被继承 修饰方法时 该方法不能被重写 修饰变量时, 该变量只能赋值一次, 不 ...
- express获取登录服务器的IP地址
let ip = (req.headers['x-real-ip'] || req.connection.remoteAddress).slice(7);