【转帖】eBay 云计算“网”事:网络超时篇
https://www.infoq.cn/article/JmCbkA0XX9NqrcX6loIo
- 2020-06-19
本文字数:5508 字
阅读完需:约 18 分钟

导读
eBay 自 2016 年开始将业务迁往 Kubernetes 容器平台,其间遇到了各种网络问题。云计算“网”事系列旨在介绍 eBay IE Cloud 团队 巧妙利用 eBPF 工具进行排查,并解决这些典型网络问题的事迹。该系列分为三篇: 网络超时篇、网络丢包篇及网络重传篇 。本篇主讲网络超时问题,希望能为类似问题的定位和解决提供思路。
背景介绍
eBay 从 2016 年 开始将 Kubernetes 项目作为下一代云平台方案。经过几年的发展实践,已经逐步完成各大主要业务往 Kubernetes 容器平台上的迁移。在这过程中,碰到大大小小的问题数不甚数。 其中大规模应用场景下的偶发性问题,一直是这些问题中的关键难点。 随机性,小概率发生,不容易复现,都给这类问题的现场捕捉和定位造成重重困难。定位和解决此类问题,一般需要数天甚至数周的时间。通过 eBPF 方式 来对内核进行剖析,是目前业内逐步开始探索的一个定位此类问题的方式,而 eBay 也在定位诸多问题中,渐渐累积开发了针对某些此类问题的 eBPF 工具。
云计算“网”事 系列文章,将从利用 eBPF 工具来解决 eBay 云平台碰到的几个典型网络问题入手,包含 网络延时、网络丢包、网络重传 三个方面,给出详细的摸索和排查分析过程,希望能为定位和解决相关问题提供思路。
应用运行在虚拟机或者物理机上,可以直接通过机器的网络端口进行数据传输,而在 Kubernetes 的节点上,容器运行在独立的 network namespace,通过 veth pair 接口来对外进行数据通信。一个常见的容器网络配置如图 1 所示:
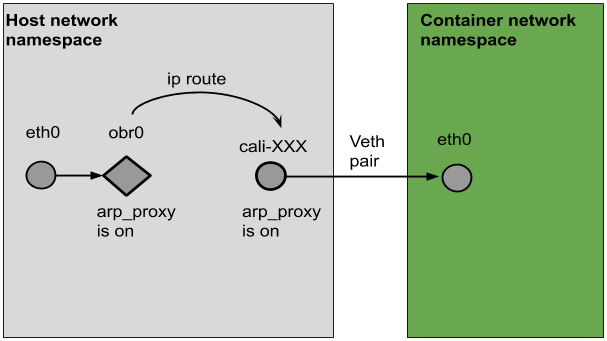
图 1
外部来容器的数据,经过物理机网卡 eth0 接收后,会经过路由,到达运行在主机 network namespace 的 cali 端口,再通过 veth pair 送到容器 network namespace 的 eth0 端口。在这中间会经过 iptables 或者 ipvs 的处理。容器往外发生数据,是接收数据的反向路径。
网络超时篇
案例 1
某个运行在 Kubernetes 集群上的多实例应用,客户端发起的请求偶尔会超时。从现象来看,往某些节点上的服务发起的请求,每个小时的超时数会比其他的节点多几十次或者几百次。该 pod 提供对后段数据库的查询,然后返回结果给用户。客户端的超时时间是 400ms 。

超时信息:
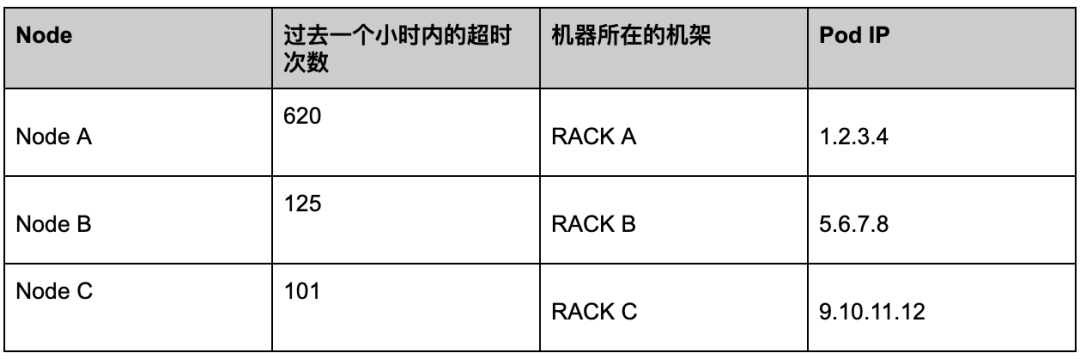
图 2
由图 2 可见,有一个节点的超时次数比较高,而其他节点的超时次数一个小时内也有 100 次左右。从总体上来看,一个小时内的调用到达万次以上,因此总体的 timeout 率不高。
针对这个问题,我们首先做了如下几个排查工作:
因为用户汇报了自从某个时间段开始,发现 timeout 的数量增加,所以我们先查看了那个时间段,是否有什么版本改动引起了问题,并排查了几个关联的修改,但没有发现和此类问题有直接的联系。
检查出问题机器的网络配置是否正确。为了减少数据包发送的乱序,提高性能,针对 cali 端口,使能了 RPS(Receive Packet Steering)。检查下来,该端口配置都没有问题。
节点的 CPU 使用率和负载并不高。
检查了出现超时问题比较多的节点及其相关 metrics 的信息,没有明显的节点的丢包统计和重传。从 timeout 的次数和总体的查询次数来看,这个也符合预期。
通过 qperf 来检测节点的 tcp 延时,并没有看到明显的延时问题。
使用 tcpdump 来抓取容器端口的数据并且同步观测容器的出错信息,当日志中打出出错信息的时候,tcpdump 上观测到有数据重传,如图 3 所示。该连接的 RTO 在 200ms 左右,所以当链路有问题的时候,是很可能发生重传的。

图 3
从其他的节点 ping 该节点,会有间断的延时突发问题。
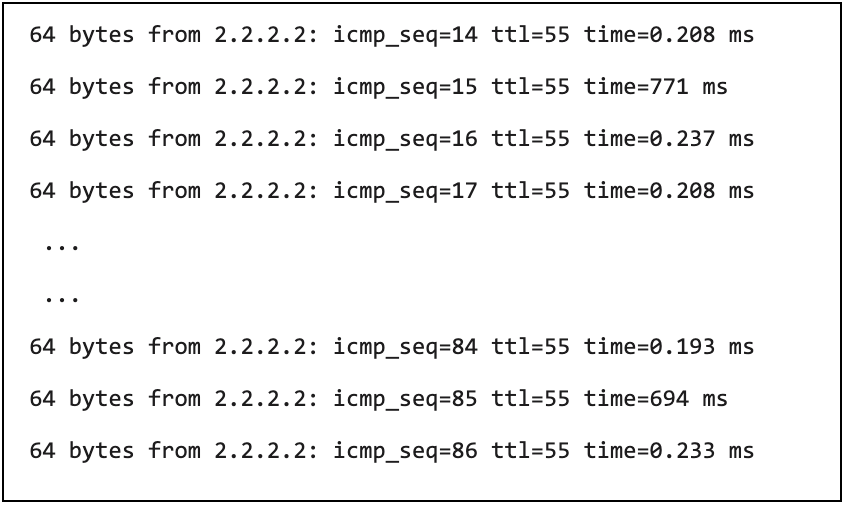
图 4
通过 ping pod 来复现问题,可以从图 4 看到有延时突然增多的现象,那就基本可以确定,数据从链路到容器的 tcp 协议栈,已经出现延时突发的问题了。 通过 ping 物理机的网卡,可以看到延时突发的现象基本消失,因此主机侧出问题的可能性比较大。
但是定位主机侧的问题,面临着很大的困难。
首先,在大规模的集群上,节点的 metrics 很多都是以分钟为间隔来进行抓取的,很多时候并不能反应出问题时间段内发生了什么。 假如因为某个时间段内的系统负载突然增高导致了延时问题,从 metrics 上往往是看不到的。另外,metrics 的精细化不够。例如 tcp 的丢包和重传,反映的是一个时间段内总的增长值,但如果问题是在很短的时间内发生的,那就很难说明两者之间有必然的相关性。
其次,很难直接找到和延时相关的证据。 一般都是看到某些异常,从离散的点去怀疑,不断修改验证,最后观察到问题没有再出现,说明问题已经解决。这也是目前在众多公众号文章看到定位系统问题的普遍解决方式。 因为 Linux 系统模块之间错综复杂的联系和相互影响,导致很多时候解决问题只能用排除法。 如果排除了怀疑的点后,问题仍旧没有改善,那就只能找新的点继续排除。该方法并不能说是不好,但肯定不是最优的解决问题的方式。因为就算解决了问题,很多时候还是无法找到引起问题的具体原因。
除此之外,利用 tcpdump 来处理这样的问题,会比较困难 ,得在主机的 eth0, cali 端口,容器的 eth0 同时长时间抓包,之后再将抓到的数据进行合并分析,看看是哪一节点引入的延时。另外 tcpdump 本身的 overhead,是否会导致延时的突发也是个未知数,而且也无法诊断是否是 iptables/ipvs 引起的延时。 还有 tcpdump 只能输出基本的数据包信息,但是有关内核的信息在定位问题的时候还是不够。 因此 tcpdump 只能作为一个辅助工具,无法完全依赖。
在这样的基础上,我们只能逐步排查是哪个模块引起的问题。思路是逐步停掉各种业务,然后进行 ping 测试,如果没有出现突发情况,则说明跟停掉的模块有很大的关系。
通过该方式,我们发现 kubelet 有很大的嫌疑 ,查看社区问题,找到一个类似的案例:
https://github.com/google/cadvisor/issues/1774#issuecomment-501907566
同我们碰到的问题一样,可以通过 drop cache 来进行修复。在继续往下深究的过程中,该问题的处理作者发布了一个博客:
https://github.blog/2019-11-21-debugging-network-stalls-on-kubernetes/
其中详细阐述了他们定位该问题的过程,以及引起该问题的原因。
简单来说,就是 pod 删除后,cgroup 还残留在 cache 中,导致 kubelet 获取根 cgroup 内存统计信息的系统调用耗费太长时间,进而影响了 ksoftirqd 对 softirq 的处理。而为何 cgroup 在容器删除后,还会有信息遗留呢,感兴趣的可以查看链接:
https://lwn.net/Articles/787614/
主机的延时问题会是经常碰到的一个难题 ,因此在定位该问题的过程中,我们就在想如何能够加速该类型问题的定位,而不用像定位本案例的时候,采取逐个排除的方式。主要的想法就是利用工具来快速找到数据产生延时的点,当获知数据在哪个路径上产生了延时之后,就可以针对性缩小范围进行下一步的排查。受开源项目https://github.com/yadutaf/tracepkt的启发, 我们也开发了基于 eBPF 的工具,来记录数据包在内核里面的处理流程。主要功能包括:
通过 TRACEEVENT 或者 kprobe 来探测网络协议栈在二层,三层和四层上的典型路径,例如 net:netif_rx,net:net_dev_queue,net:napi_gro_receive_entry,net:netif_receive_skb_entry 等。可以通过指定 IP 地址或者端口号等来抓取指定的数据包的处理事件。
当对应的函数被调用或者 event 被触发,则会从 skb 中获取当前的 network namespace、端口信息、CPU 核、调用时间、进程号、数据包的五元组、数据包长度等信息。
因为我们的节点上会同时使用 iptables 和 ipvs,所以也抓取了 iptables 和 ipvs 各个处理链的入口和出口,用于计算各个处理链的花费时间,以及已经处理链对数据包的处理策略,例如 ACCEPT,DROP 等。
案例 2
某个应用的实例有部署在虚拟机中,也有以容器部署到 kuberntes 集群中。应用的管理员从监控中发现,调用某个第三方 API 的超时比例不同,前者在 0.001% ,后者在 0.01%-0.04% ,之间差了数十倍,因此汇报出该问题,让我们去排查为何会有这样的差别。
经过沟通了解到,该用户客户端的超时时间是 100ms ,所有以容器部署的节点,超时的错误率都比运行在虚拟机上要高。于是我们开始着手定位该问题:
开始复现
在节点上进行 100 次的 API 调用,每次调用可以在 30ms-40ms 之间完成。
对节点容器进行 1 万次的 ping 操作,并没有发现有延时现象。
因此复现失败。
是否是由之前定位过的 kubelet 搜集获取 memory.stat 引起的呢?(详见案例 1)
用命令:
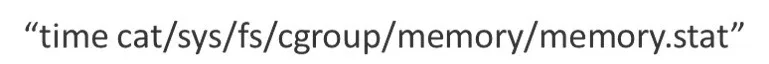
来计算读取 memory.stat 的消耗时间,大部分都超过了 50ms。因为客户端的超时时间设置为 100ms,而调用 API 的耗时在 30-40ms,再加上这个消耗的 50ms,是很可能导致超时的。于是执行 drop cache 的操作,很遗憾的是 drop cache 后,并没有让超时问题得到多少改善。
于是继续跑设计的 eBPF 工具,希望能查找到在主机的哪个位置产生了超时。
在抓取了超十万条数据记录后,用脚本对输出结果进行分析,根据输出条目的时间戳和数据包信息,过滤出在主机上有异常延时的数据包信息,如图 5 所示:
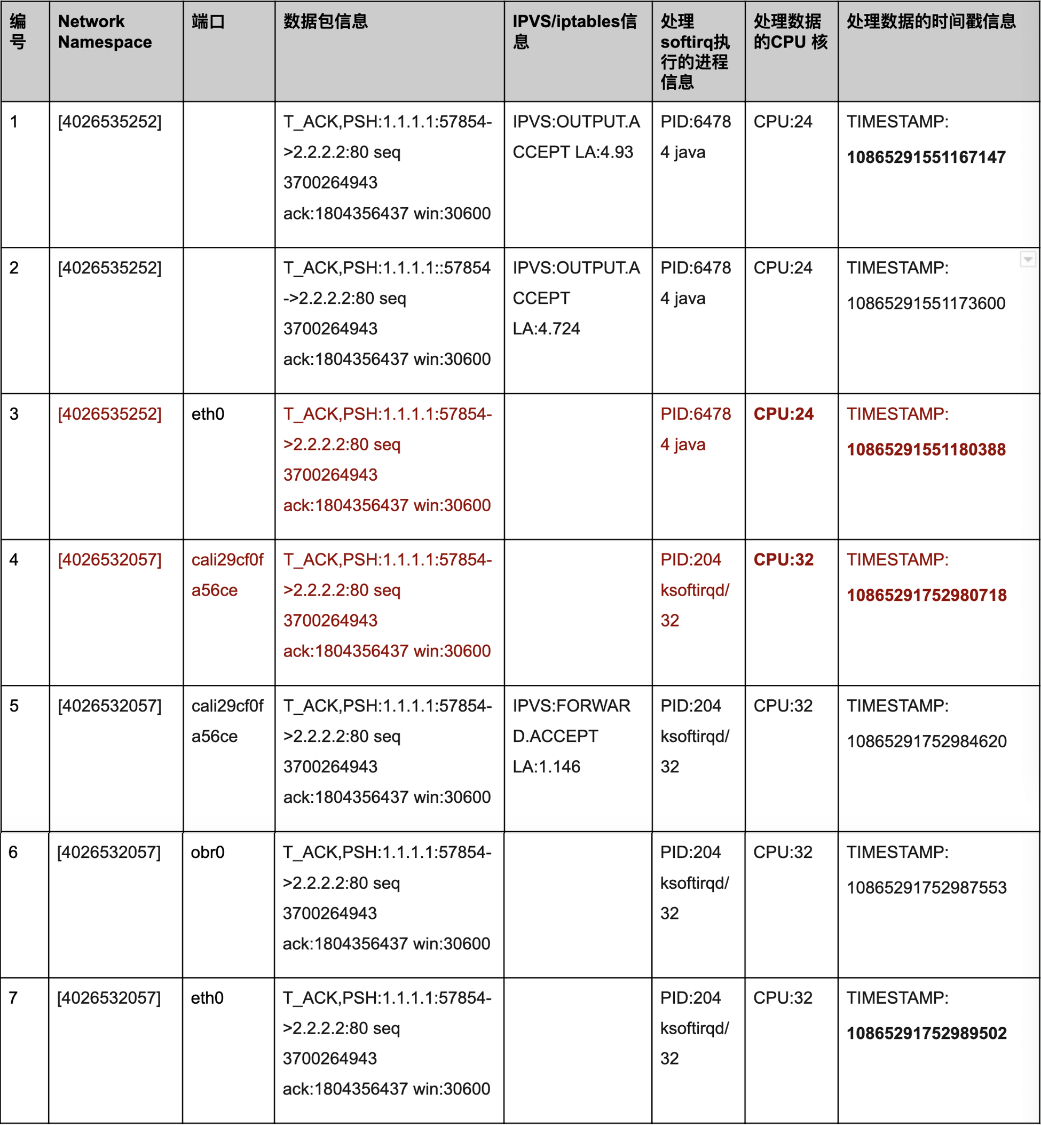
图 5
图 5 中的第二列代表了当前处理数据包的 network namespace,第三列代表当前数据包处理的端口,第四列显示了数据包信息,第五列显示了 IPVS 或者 iptables 对数据包的处理,第六列显示了处理 softirq 的进程信息,第七列显示了当前处理数据的 CPU 核,第八列显示了处理数据开始的时间戳,是系统的启动时间,单位为 ns。
从抓取数据信息来看,有数据包从容器发出到主机端口发送,时间使用 10865291752989502 - 10865291551167147 = 201822355ns, 也就是超过了 200ms,主要的时间消耗在从第 3 步到第 4 步之间 ,从容器的 network namespace 到主机的 network namespace,就超过 10865291752980718 - 10865291551180388 = 201800330 (> 200ms)。
在分析了多个数据超时的数据包后,发现他们具有同样的模版,那就是在主机 network namespace 上处理 veth pair 端口过来数据包的 CPU core,都是 32 。
通过 top 命令来查看该核的运行情况,发现该核的中断处理时间 si 会间歇性比较高,经常达到 30%的使用率,而节点的 load 很低,整体 CPU 的使用率也不高。

如果没有基于 eBPF 的工具,而是通过类似排查问题 1 这样的定位手段,想要定位到这一步,是需要很长的时间的,我们可能会注意到 32 的 si 会稍微高点,但是很难和网络延时问题进行直接的关联。 而有了 eBPF 工具,通过抓取数据,很快就得到了这样的关键信息,这些信息对于解决问题可谓是至关重要。
接着通过 perf,来查看下具体该核都在做什么事情,并生成火焰图(图 6)。
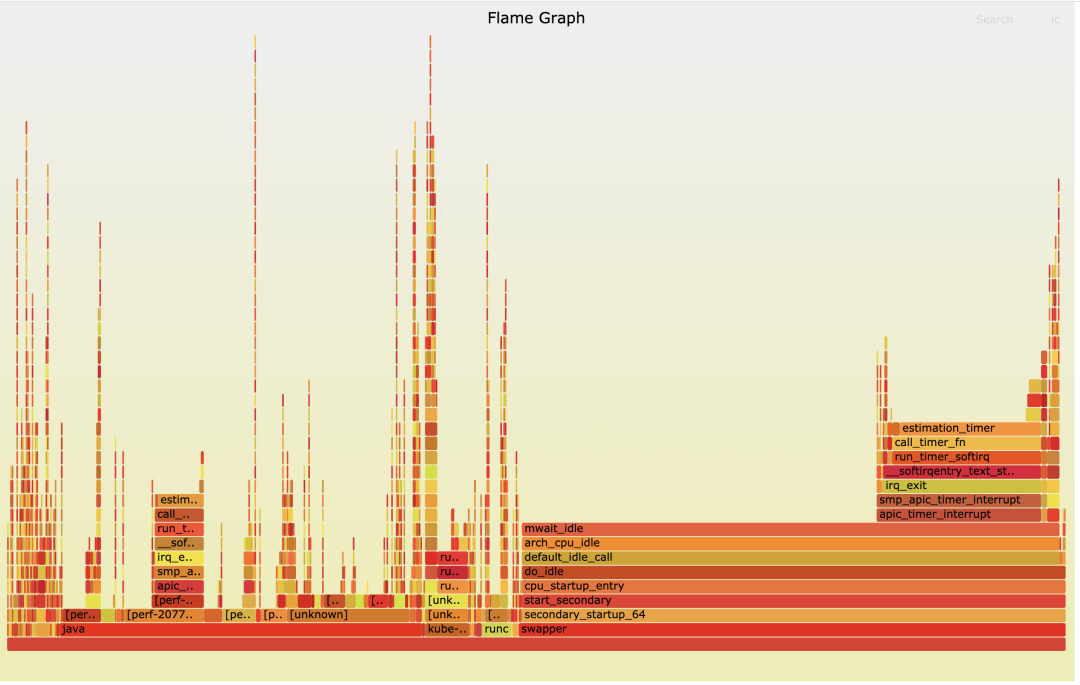
图 6
可以看到该核消耗了很大的一部分时间在处理 estimation_timer。而 si 比较高,要么 estimation_timer 的中断次数很多,要么处理某个中断耗时很长。
先看中断次数是否很多,通过我们自己开发的小工具,从/proc/interrupts 获取一段时间内该核的中断数量,结果显示该核上并没有很多 timer 中断数量,其他类型的中断也很少。
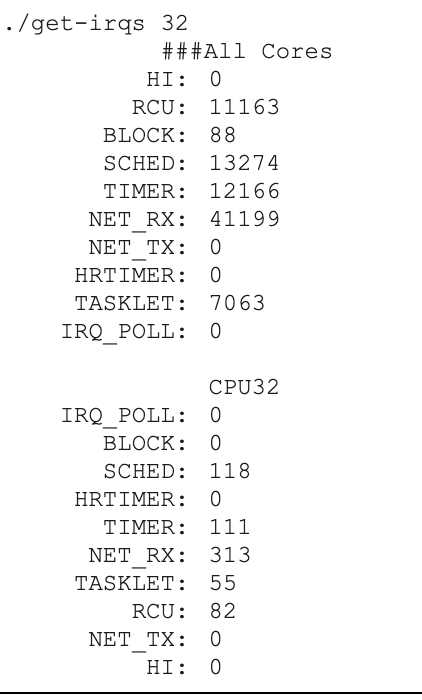
既然没有很多的中断,那么问题大概率是中断处理时间比较长。于是,我们对 bcc 的 softirq 工具https://github.com/iovisor/bcc/blob/master/tools/softirqs.py 进行了修改,让它只统计 CPU32 上不同类型的 softirq 耗时信息。在运行一段时间后,从输出结果中发现有 timer 的 softirq 执行时间在 262ms-524ms 之间。

从代码得知,estimation_timer 是由 ipvs 模块进行注册的:
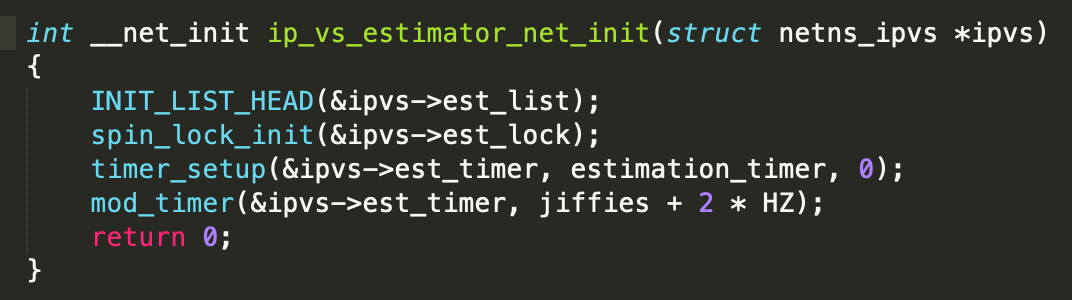

从 estimation_timer 的函数实现来看,它会调用 spin_lock 进行锁的操作,并且会查询每一条的 ipvs rules 进行相关操作。我们集群上的 service 比较多,因此在节点上,会存在很多的 ipvs 规则,导致 estimation_timer 的执行需要消耗大量的时间。
但是为什么只有在核 32 上会出现问题呢?
通过 ftrace,我们抓取了 estimation_timer()的 function_graph, 从图 7 的结果可以看到,estimation_timer()在很多的核上都被执行,但是只有在 32 核上执行的时候,消耗了很多的时间,其他核上消耗的时间都很少。

图 7
在 kube-proxy 使用 ipvs 模式的节点上,只有主机的 host network namespace 才有很多的 ipvs rules,而在容器的 netowrk namespace 里面,并没有 ipvs rules 存在。从现象来看,核 32 应该是被用来处理 host network namespace 的 ipvs rules,而其他的核用来处理其它容器 network namespace 的 ipvs rules,所以才会有这么大的差别。
那为什么核 32 被用来处理 host network namespace,而不是其他的核呢?
从实验结果来看,该值是由加载 ipvs 模块时候的核决定的,如果通过 task_set 来设定加载 ipvs 模块的核,那么会由该核来执行 host network namespace 的 estimation_timer。
至此,我们已经知道了该问题的来龙去脉,解决方法主要是:
短期内 通过 live patch 将 estimation_timer 的执行功能替换来解决线上的问题,目前我们暂时不需要 estimation_timer 对不同的链路进行速率等的统计,所以暂时将功能替换为不执行任何操作。
在长期方案上 ,我们选择去除该 timer,通过 kernel thread 来定期执行 ipvs 相关的链路速率、数据包等的统计功能,也就是来完成之前 estimation_timer 的工作。该方案目前还在进行更多详细的测试。
总结——网络超时篇
网络超时问题,关键还是在于找寻网络超时的时间点。如果可以找出这个时间点,就能快速缩小问题范围,也为最终解决问题提供一个正确有力的指导方向。这事情如同穿衣服,第一个纽扣对上了,后面的其他纽扣也就自然而然对上了。
从上面两个案例的定位方式对比来看, 抛弃手忙脚乱进行各种尝试,而是利用工具,来寻找第一个纽扣 ,是在复杂的 Linux 环境下,快速定位此类问题的关键方法。利用 eBPF 可以对内核进行更深入的剖析,让我们初步感受到了它的威力。因此我们也将用它来定位其他类型的问题,详情请关注后续的丢包篇和重传篇。
本文转载自公众号 eBay 技术荟(ID:eBayTechRecruiting)。
原文链接:
【转帖】eBay 云计算“网”事:网络超时篇的更多相关文章
- NSURLConnection 网络超时的那些事(转别人整理的)
NSURLConnection 网络超时的那些事(转别人整理的) 在ios平台上做网络开发最常用的两个类: NSMutableURLRequest *urlRequest = [[NSMutableU ...
- 使用whistle模拟cgi接口异常:错误码、502、慢网速、超时
绝大多数程序只考虑了接口正常工作的场景,而用户在使用我们的产品时遇到的各类异常,全都丢在看似 ok 的 try catch 中.如果没有做好异常的兼容和兜底处理,会极大的影响用户体验,严重的还会带来安 ...
- 最新 网龙网络java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿.网龙网络等10家互联网公司的校招Offer,因为某些自身原因最终选择了网龙网络公司.6.7月主要是做系统复习.项目复盘.Le ...
- Charles模拟网络请求页面的网络超时测试
正常情况下网络连接超时可能的原因有以下几点: 1.网络断开,手动的关掉了网络的连接 2.网络阻塞,导致你不能在程序默认等待时间内得到回复数据包. 3.网络不稳定,网络无法完整传送服务器信息. 4.系统 ...
- pip安装拓展包--网络超时/Read timed out问题
pip安装拓展包--网络超时/Read timed out问题 解决方案:切换镜像源(墙皮太厚) 在后面加上: -i https://pypi.douban.com/simple example: p ...
- CentOS8Linux中配置网易云网络yum源安装软件
在CentOS8Linux中配置网易云网络yum源安装软件 前提是你的操作系统是CentOS-Linux 你已经配置好了本地yum源,并且你的网络是可用的. 本地yum源配置请参考:https://w ...
- (转)HttpURLConnection中设置网络超时
转:http://www.xd-tech.com.cn/blog/article.asp?id=37 Java中可以使用HttpURLConnection来请求WEB资源.HttpURLConnect ...
- day7_直播_网络编程篇(元昊老师著)
网络编程篇计算机网络: 多台独立的计算机用网络通信设备连接起来的网络.实现资源共享和数据传递. 比如,我们之前的学过的知识可以将D盘的一个文件传到C盘,但如果你想从你的电脑传一个文件到我的电脑上目前是 ...
- 入木三分学网络第一篇--VRRP协议详解第一篇(转)
因为keepalived使用了VRRP协议,所有有必要熟悉一下. 虚拟路由冗余协议(Virtual Router Redundancy Protocol,简称VRRP)是解决局域网中配置静态网关时,静 ...
- 云计算与OpenStack(虚拟机Nova篇)
<云计算与OpenStack(虚拟机Nova篇)> 基本信息 作者: 伯龙 程志鹏 张杰 出版社:电子工业出版社 ISBN:9787121201202 上架时间:2013-8-5 出版日期 ...
随机推荐
- 2021-01-04:mysql里的innodb引擎的数据结构,你有看过吗?
福哥答案2021-01-04: 面试官刚开始问我看过mysql源码没,然后问了这个问题.回答B+树,过不了面试官那关. 答案来自<MySQL技术内幕 InnoDB存储引擎 第2版>第四章, ...
- Java 中常见类型的判空方式
引用类型(Reference Types): 使用 == 运算符判断是否为 null. 使用 != 运算符判断是否不为 null. 使用 Objects.isNull() 方法判断是否为 null. ...
- python -m http.server在本地启动简单HTTP服务器的命令
1.python -m http.server 命令 python -m http.server 是一个用于在本地启动简单 HTTP 服务器的命令.这个命令会在当前工作目录启动一个基本的 HTTP ...
- 华为云FusionInsight MRS:千余节点滚动升级业务无中断
摘要:滚动升级作为大集群数据底座的必备能力,能够完美解决了传统大数据平台操作繁琐.业务停机.升级成本高等问题,实现一个架构的持续演进,业务无中断. 华为开发者大会2021(Cloud)大会期间,由华为 ...
- 教你用Java7的Fork/Join框架开发高并发程序
摘要:Fork/Join框架位于J.U.C(java.util.concurrent)中,是Java7中提供的用于执行并行任务的框架,其可以将大任务分割成若干个小任务,最终汇总每个小任务的结果后得到最 ...
- "error LNK2019: 无法解析的外部符号"原因分析
1.工程属性选择错误 问题: 分析: 新建的是控制台程序,但编译器和链接器却用的是windows子系统 解决办法: WINDOWS和CONSOLE选择 右键工程名, 打开属性,依次找到以下路径: 然后 ...
- 使用BAPI_NETWORK_COMP_*实现生产订单组件的增删改查
1.文档说明 对于生产订单组件的增删改有多种办法,比较常用的有使用内部函数CO_XT_COMPONENT_*,有改造BAPI_ALM_ORDER_MAINTAIN来实现,各有千秋. 本文档介绍,通过P ...
- 【JAVA基础】List处理
List处理 List使用Lists.partition()分片 public static <T> List<List<T>> partition(List< ...
- Codeforces Round #727 (Div. 2) A~D题题解
比赛链接:Here 1539A. Contest Start 让我们找出哪些参与者会干扰参与者i.这些是数字在 \(i+1\) 和 \(i+min(t/x,n)\)之间的参与者.所以第一个最大值 \( ...
- AtCoder Beginner Contest 198 个人题解(AB水题,C思维,D思维+全排列,E题DFS搜索,F懵逼)
补题链接:Here A - Div 题意:N 个不一样的糖,请问有多少种分法给 A,B两人 水题,写几组情况就能知道输出 \(N - 1\) 即可 B - Palindrome with leadin ...