Spark集群的安装及高可用配置
Spark集群的安装及高可用配置
前期需求:Hadoop和Scala必须已经安装完成
步骤:
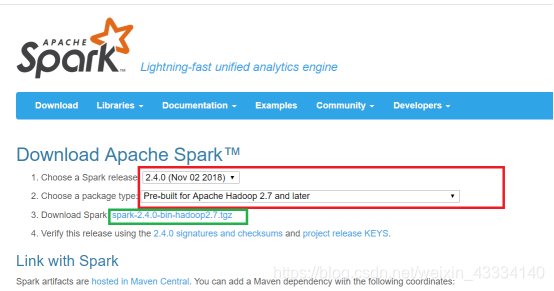
①进入spark下载网站中https://spark.apache.org/downloads.html
(红框的部分是选择tar包的版本,选择完毕之后点击绿框的部分下载)
②下载完成之后用xftp将安装包传服务器的opt文件夹下。然后用tar命令解压。解压完成之后删除安装包。再然后进入/etc/profile配置环境变量。加入下面的两条语句,然后保存并退出用source命令使其生效。
export SPARK_HOME=/opt/spark-2.4.0-bin-hadoop2.7
在export PATH的末尾加上 :
S
P
A
R
K
H
O
M
E
/
b
i
n
:
SPARK_HOME/bin:
SPARKHOME/bin:SPARK_HOME/sbin
③进入/opt/spark-2.4.0-bin-hadoop2.7/conf文件夹下,执行下面两条语句
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
④用vi命令分别修改spark-env.sh和slaves
spark-env.sh的末尾添加如下语句

前三个都指的是对应的安装目录,这个不多赘述,后面五个的意思如下
HADOOP_CONF_DIR:hadoop集群的配置文件的目录
SPARK_MASTER_IP:spark集群的Master节点的ip地址
SPARK_WORKER_MEMORY:每个worker节点能够最大分配给exectors的内存大小
SPARK_WORKER_CORES:每个worker节点所占有的CPU核数目
SPARK_WORKER_INSTANCES:每台机器上开启的worker节点的数目
slaves的末尾修改为(工作者节点,我这里选择2号和3号机,1号作为Master)

修改$SPARK_HOME/conf/spark_defaults.conf
在其尾部添加
spark.executor.extraClassPath=/opt/flume_tar_dir/libs/*
spark.driver.extraClassPath=/opt/flume_tar_dir/libs/*
主要是为了spark-submit 提交时不用指定jars,但是需要自己在idea打jar包时指定类打包,将打包好的jar传入该入境下,提交时不用写–class
例:spark-submit --master spark://hadoop1:7077,hadoop2:7077 OfflineProject.jar
配置Spark高可用
vi /usr/etc/spark-2.3.0-bin-hadoop2.7/conf/spark-evn.sh
修改内容如下:
#export SPARK_MASTER_IP=Master #注释掉该行,Spark自己管理集群的状态
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=Master:2181,Worker1:2181,Worker2:2181 -Dspark.deploy.zookeeper.dir=/spark" #通过Zookeeper管理集群状态
/spark 自己定义一个保存数据的路径
实现高可用得先在前两个节点上启动 spark-master.sh
然后停掉一个节点 访问8080 查看状态
⑤将/etc/profile以及Spark文件夹用scp命令分发到其他两台机子上。发送过去之后到其他两台机子的窗口里,用source命令使环境变量生效
⑥回到一号机,开启Zookeeper,然后执行start-dfs.sh命令(开不开zookeeper其实没什么影响,也没要求说必须开,但是作为平常的习惯还是开启了Zk)。执行之后进入/opt/spark-2.4.0-bin-hadoop2.7文件夹下,执行 ./sbin/start-all.sh(进入这里执行的目的是为了防止和hadoop里的同名文件冲突)

然后查看三台机子的节点(多了一个Master和两个Worker)



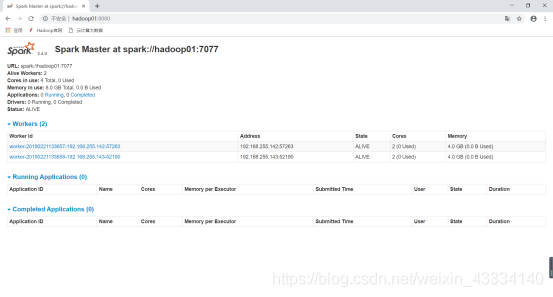
⑦进入Master所在机器的8080端口,可以查看Worker的信息
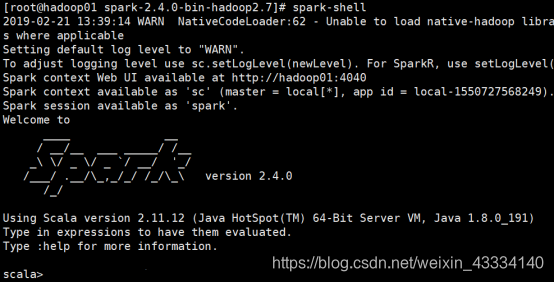
⑧在Master机器上执行 spark-shell命令。会出现如下语句
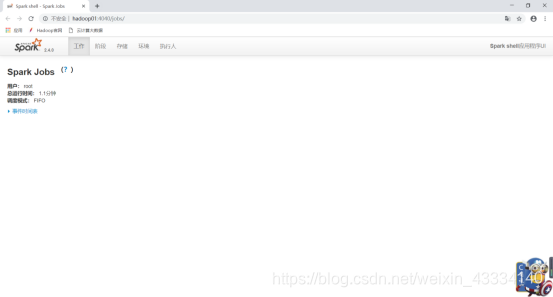
同样,在开启之后,也可以访问4040端口查看当前任务
至此,Spark集群安装就算圆满完成了。
Spark集群的安装及高可用配置的更多相关文章
- Apache shiro集群实现 (六)分布式集群系统下的高可用session解决方案---Session共享
Apache shiro集群实现 (一) shiro入门介绍 Apache shiro集群实现 (二) shiro 的INI配置 Apache shiro集群实现 (三)shiro身份认证(Shiro ...
- Apache shiro集群实现 (五)分布式集群系统下的高可用session解决方案
Apache shiro集群实现 (一) shiro入门介绍 Apache shiro集群实现 (二) shiro 的INI配置 Apache shiro集群实现 (三)shiro身份认证(Shiro ...
- Spark集群 + Akka + Kafka + Scala 开发(1) : 配置开发环境
目标 配置一个spark standalone集群 + akka + kafka + scala的开发环境. 创建一个基于spark的scala工程,并在spark standalone的集群环境中运 ...
- Spark系列—01 Spark集群的安装
一.概述 关于Spark是什么.为什么学习Spark等等,在这就不说了,直接看这个:http://spark.apache.org, 我就直接说一下Spark的一些优势: 1.快 与Hadoop的Ma ...
- openstack高可用集群21-生产环境高可用openstack集群部署记录
第一篇 集群概述 keepalived + haproxy +Rabbitmq集群+MariaDB Galera高可用集群 部署openstack时使用单个控制节点是非常危险的,这样就意味着单个节 ...
- k8s集群中部署Rook-Ceph高可用集群
先决条件 为确保您有一个准备就绪的 Kubernetes 集群Rook,您可以按照这些说明进行操作. 为了配置 Ceph 存储集群,至少需要以下本地存储选项之一: 原始设备(无分区或格式化文件系统) ...
- Docker namespace,cgroup,镜像构建,数据持久化及Harbor安装、高可用配置
1.Docker namespace 1.1 namespace介绍 namespace是Linux提供的用于分离进程树.网络接口.挂载点以及进程间通信等资源的方法.可以使运行在同一台机器上的不同服务 ...
- kubeadm安装集群系列-2.Master高可用
Master高可用安装 VIP负载均衡可以使用haproxy+keepalive实现,云上用户可以使用对应的ULB实现 准备kubeadm-init.yaml文件 apiVersion: kubead ...
- HAProxy+keepalived+MySQL 实现MHA中slave集群负载均衡的高可用
HAProxy+keepalived+MySQL实现MHA中slave集群的负载均衡的高可用 Ip地址划分: 240 mysql_b2 242 mysql_b1 247 haprox ...
- Cluster基础(四):创建RHCS集群环境、创建高可用Apache服务
一.创建RHCS集群环境 目标: 准备四台KVM虚拟机,其三台作为集群节点,一台安装luci并配置iSCSI存储服务,实现如下功能: 使用RHCS创建一个名为tarena的集群 集群中所有节点均需要挂 ...
随机推荐
- 记一次在openEuler系统下离线编译升级到openssh9.8p1
缘起 由于某个项目上甲方对服务器进行漏洞扫描,系统为:openEuler 22.03 (LTS-SP4).提示现有OpenSSH版本存在漏洞,需要升级到openssh-9.8p1的版本(目前最新),遂 ...
- GeoScene Pro处理并发布倾斜摄影(OSGB)
前言 看了网上好多教程,很多都不全,在自己操作的过程中遇到了很多问题,最后将我完整的流程整理出来,以供大家参考 从数据处理.优化.发布.加载完整流程都有 一.数据格式转换 1.全局搜索"创建 ...
- SpringBoot配置过滤器、拦截器
拦截器概述 Spring Boot提供了一种简单且强大的方式来定义和使用拦截器(Interceptor).Spring Boot的拦截器基于Spring框架的拦截器机制,可以在请求的处理过程中插入自定 ...
- 【Java】JDBC Part5.1 Hikari连接池补充
Hikari Connection Pool Hikari 连接池 HikariCP 官方文档 https://github.com/brettwooldridge/HikariCP Maven依赖 ...
- 【Mycat】01 概述
什么是Mycat? 数据库中间件 中间件:是一类连接软件组件和应用的计算机软件,以便于软件各部件之间的沟通. 例子:Tomcat,web中间件. 数据库中间件:连接java应用程序和数据库 为什么要用 ...
- 【GPU】如何两周内零经验手搓一个GPU | 美国工程师极限挑战 | 重写三次 | CUDA | SIMD | ISA指令集 | Verilog | OpenLane
地址: https://www.youtube.com/watch?v=FTh-c2ek6PU
- flex布局被内容被撑开及flex布局下定宽元素被压缩
实现效果使用flex进行左右布局,左边定宽200px,右边自适应,当右边内容过多,造成右边盒子被撑开,会造成两种问题 左边定宽盒子被压缩解决办法: flex-grow:0;//是否自动增长空间 fle ...
- CF1697C
C. awoo's Favorite Problem 首先,检查两个字符串中所有字母的计数是否相同. 然后考虑下面的重述.字符串s中的字母 b是静止的.而字母a和c则在字符串中移动.第一种移动是将字母 ...
- spring声明事务失效问题
问题: 在项目开发中遇到了一个spring事务失效的问题,检查配置文档,都没有问题,其他的类中的方法都能进行事务管理,而这个类中的方法却不行. 分析 查看代码发现三个问题: 原因1 ...
- 13. Advanced-control timers (TIM1 and TIM8)
1. 基本介绍 有三个基础的寄存器: 计数寄存器(TIMx_CNT,Counter register) 预分频寄存器(TIMx_PSC,Prescaler register) 自动重载寄存器(TIMx ...