join分析:shuffle hash join、broadcast hash join
Join 背景介绍
Join 是数据库查询永远绕不开的话题,传统查询 SQL 技术总体可以分为简单操作(过滤操作、排序操作 等),聚合操作-groupby 以及 Join 操作等。其中 Join 操作是最复杂、代价最大的操作类型,也是 OLAP 场景中使用相对较多的操作。
另外,从业务层面来讲,用户在数仓建设的时候也会涉及 Join 使用的问题。通常情况下,数据仓库中的表一般会分为“低层次表”和“高层次表”。
- 所谓“低层次表”:就是数据源导入数仓之后直接生成的表,单表列值较少,一般可以明显归为维度表或事实表,表和表之间大多存在外健依赖,所以查询起来会遇到大量 Join 运算,查询效率很差。
- “高层次表”:是在“低层次表”的基础上加工转换而来,通常做法是使用 SQL 语句将需要 Join 的表预先进行合并形成“宽表”,在宽表上的查询不需要执行大量 Join,效率很高。但宽表缺点是数据会有大量冗余,且相对生成较滞后,查询结果可能并不及时。
为了获得时效性更高的查询结果,大多数场景都需要进行复杂的 Join 操作。Join 操作之所以复杂,主要是通常情况下其时间空间复杂度高,且有很多算法,在不同场景下需要选择特定算法才能获得最好的优化效果。
本文将介绍 SparkSQL 所支持的几种常见的 Join 算法及其适用场景。
基本实现机制
shuffle hash join、broadcast hash join 两者归根到底都属于 hash join,只不过在 hash join 之前需要先 shuffle 还是先 broadcast。其实,hash join 算法来自于传统数据库,而 shuffle 和 broadcast 是大数据的皮(分布式),两者一结合就成了大数据的算法了。因此可以说,大数据的根就是传统数据库。既然 hash join 是“内核”,那就刨出来看看,看完把“皮”再分析一下。
1、hash join
先来看看这样一条 SQL 语句:
- select * from order,item where item.id = order.i_id
很简单一个 Join 节点,参与 join 的两张表是 item 和 order,join key 分别是 item.id 以及 order.i_id。现在假设这个 Join 采用的是 hash join 算法,整个过程会经历三步:
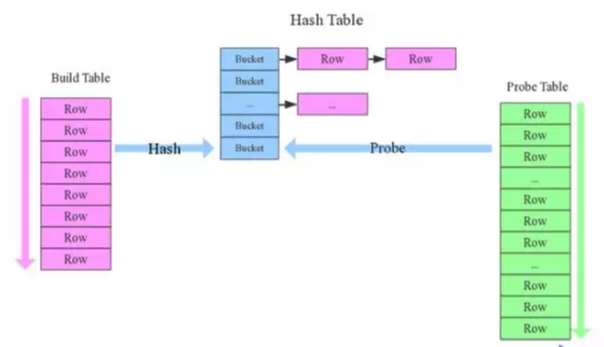
分步解释:
- 1. 确定 Build Table 以及 Probe Table:这个概念比较重要,Build Table 使用 join key 构建 Hash Table,而 Probe Table 使用 join key 进行探测,探测成功就可以 join 在一起。通常情况下,小表会作为 Build Table,大表作为 Probe Table。此事例中 item 为 Build Table,order 为 Probe Table。
- 2. 构建 Hash Table:依次读取 Build Table(item)的数据,对于每一行数据根据 join key(item.id)进行 hash,hash 到对应的 Bucket,生成 hash table 中的一条记录。数据缓存在内存中,如果内存放不下需要 dump 到外存。
- 3. 探测:再依次扫描 Probe Table(order)的数据,使用相同的 hash 函数映射 Hash Table 中的记录,映射成功之后再检查 join 条件(item.id = order.i_id),如果匹配成功就可以将两者 join 在一起。
基本流程可以参考上图,这里有两个小问题需要关注:
1. hash join 性能如何?
- 很显然,hash join 基本都只扫描两表一次,可以认为 o(a+b),较之最极端的笛卡尔集运算 a*b,不知甩了多少条街。
2. 为什么 Build Table 选择小表?
- 道理很简单,因为构建的 Hash Table 最好能全部加载在内存,效率最高;这也决定了 hash join 算法只适合至少一个小表的 join 场景,对于两个大表的 join 场景并不适用。
上文说过,hash join 是传统数据库中的单机 join 算法,在分布式环境下需要经过一定的分布式改造,就是尽可能利用分布式计算资源进行并行化计算,提高总体效率。hash join 分布式改造一般有两种经典方案:
1.broadcast hash join
- 将其中一张小表广播分发到另一张大表所在的分区节点上,分别并发地与其上的分区记录进行 hash join。broadcast 适用于小表很小,可以直接广播的场景。
2. shuffler hash join
- 一旦小表数据量较大,此时就不再适合进行广播分发。这种情况下,可以根据 join key 相同必然分区相同的原理,将两张表分别按照 join key 进行重新组织分区,这样就可以将 join 分而治之,划分为很多小 join,充分利用集群资源并行化。
broadcast hash join
如下图所示,broadcast hash join 可以分为两步:

分步解释:
1.broadcast 阶段:
- 将小表广播分发到大表所在的所有主机。广播算法可以有很多,最简单的是先发给 driver,driver 再统一分发给所有 executor;要不就是基于 BitTorrent 的 TorrentBroadcast。
2. hash join 阶段:
- 在每个 executor 上执行单机版 hash join,小表映射,大表试探。
SparkSQL 规定 broadcast hash join 执行的基本条件为被广播小表必须小于参数 spark.sql.autoBroadcastJoinThreshold,默认为 10M。
shuffle hash join
在大数据条件下如果一张表很小,执行 join 操作最优的选择无疑是 broadcast hash join,效率最高。但是一旦小表数据量增大,广播所需内存、带宽等资源必然就会太大,broadcast hash join 就不再是最优方案。此时可以按照 join key 进行分区,根据 key 相同必然分区相同的原理,就可以将大表 join 分而治之,划分为很多小表的 join,充分利用集群资源并行化。如下图所示
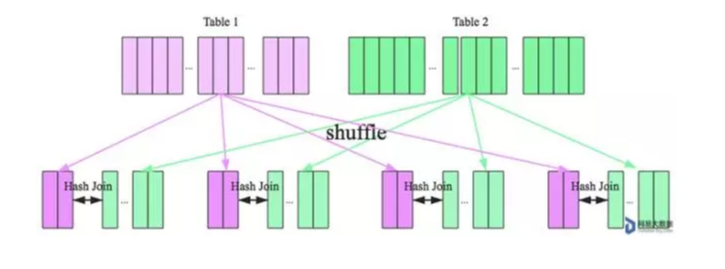
shuffle hash join 也可以分为两步:
1.shuffle 阶段:
- 分别将两个表按照 join key 进行分区,将相同 join key 的记录重分布到同一节点,两张表的数据会被重分布到集群中所有节点。这个过程称为 shuffle。
2. hash join 阶段:
- 每个分区节点上的数据单独执行单机 hash join 算法。
看到这里,可以初步总结出来如果两张小表 join 可以直接使用单机版 hash join;如果一张大表 join 一张极小表,可以选择 broadcast hash join 算法;而如果是一张大表 join 一张小表,则可以选择 shuffle hash join 算法;那如果是两张大表进行 join 呢?
sort merge join
SparkSQL 对两张大表 join 采用了全新的算法-sort-merge join,如下图所示
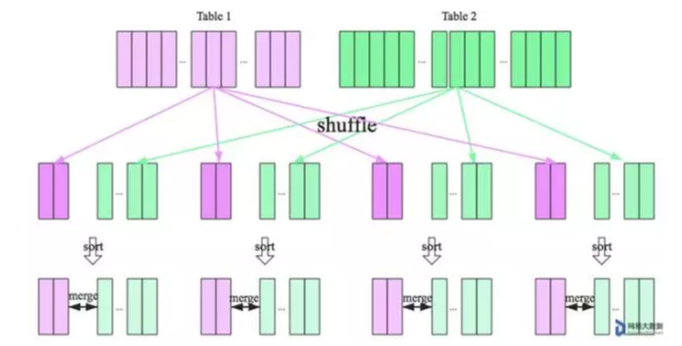
整个过程分为三个步骤:
1. shuffle 阶段:
- 将两张大表根据 join key 进行重新分区,两张表数据会分布到整个集群,以便分布式并行处理。
2. sort 阶段:
- 对单个分区节点的两表数据,分别进行排序。
3. merge 阶段:
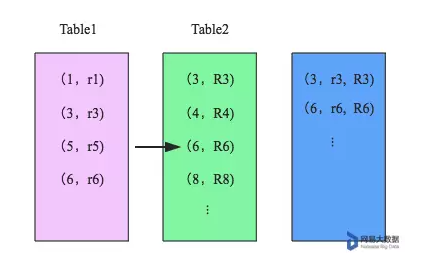
- 对排好序的两张分区表数据执行 join 操作。join 操作很简单,分别遍历两个有序序列,碰到相同 join key 就 merge 输出,否则取更小一边。如下图所示:
经过上文的分析,很明显可以得出来这几种 Join 的代价关系:cost(broadcast hash join) < cost(shuffle hash join) < cost(sort merge join),数据仓库设计时最好避免大表与大表的 join 查询,SparkSQL 也可以根据内存资源、带宽资源适量将参数 spark.sql.autoBroadcastJoinThreshold 调大,让更多 join 实际执行为 broadcast hash join。
参考资料
join分析:shuffle hash join、broadcast hash join的更多相关文章
- Spark(八)【利用广播小表实现join避免Shuffle】
目录 使用场景 核心思路 代码演示 正常join 正常left join 广播:join 广播:left join 不适用场景 使用场景 大表join小表 只能广播小表 普通的join是会走shuff ...
- MySQL 使用profile分析慢sql,group left join效率高于子查询
MySQL 使用profile分析慢sql,group left join效率高于子查询 http://blog.csdn.net/mchdba/article/details/54380221 -- ...
- Thread.join()分析方法
API: join public final void join() throws InterruptedException 等待该线程终止. 抛出: InterruptedException - 假 ...
- EntityFramework 使用Linq处理内连接(inner join)、外链接(left/right outer join)、多表查询
场景:在实际的项目中使用EntityFramework都会遇到使用Ef处理连接查询的问题,这里做一些小例子如何通过Linq语法处理内连接(inner join).外连接(left/right oute ...
- SOFA 源码分析 — 负载均衡和一致性 Hash
前言 SOFA 内置负载均衡,支持 5 种负载均衡算法,随机(默认算法),本地优先,轮询算法,一致性 hash,按权重负载轮询(不推荐,已被标注废弃). 一起看看他们的实现(重点还是一致性 hash) ...
- 【数据库】left join(左关联)、right join(右关联)、inner join(自关联)的区别
left join(左关联).right join(右关联).inner join(自关联)的区别 用一张图说明三者的区别: 总结: left join(左联接) 返回包括左表中的所有记录和右表中关联 ...
- oracle 内连接(inner join)、外连接(outer join)、全连接(full join)
转自:https://premier9527.iteye.com/blog/1659689 建表语句: create table EMPLOYEE(EID NUMBER,DEPTID NUMBER,E ...
- 【转】【java源码分析】Map中的hash算法分析
全网把Map中的hash()分析的最透彻的文章,别无二家. 2018年05月09日 09:08:08 阅读数:957 你知道HashMap中hash方法的具体实现吗?你知道HashTable.Conc ...
- Hash表及hash算法的分析
Hash表中的一些原理/概念,及根据这些原理/概念: 一. Hash表概念 二. Hash构造函数的方法,及适用范围 三. Hash处理冲突方法,各自特征 四. ...
- 从实例分析ELF格式的.gnu.hash区与glibc的符号查找
前言 ELF格式的.gnu.hash节在设计上比较复杂,直接从glibc源码进行分析的难度也比较大.今天静下心来看了这篇精彩的文章,终于将布隆滤波器.算数运算转为位运算等一系列细节搞懂了(值得一提的是 ...
随机推荐
- IDEA 2019.3 plugins 插件搜索不出结果
proxy的url输入: http://127.0.0.1:1080 重启idea即可
- KingbaseES 中select for update语句引起的锁问题
背景 客户现场执行压测时候,发生周期性的TPS大幅下降,通过查看kwr报告发现DBcpu时间占DBtime时间很少,百分之90的DBtime花费在tuple锁等待上,等待事件类型是lock. 等待时间 ...
- Book-Riscv-XV6-Chap1
操作系统接口 – 阅读 xv6-riscv-book Xv6的时钟周期:定时器芯片两次中断之间的时间 xv6作为一个简单的操作系统,利用一个"内核kernel"向其他运行中的程序提 ...
- 【已解决】Hadoop_02 bash: start-all.sh: 未找到命令...Linux
在配置hadoop时需要进到/etc/profile中修改hadoop路径 #配置Hadoop和Java环境 export JAVA_HOME=/JDK-1.8 #你自己Java的安装路径 expor ...
- 5W1H聊开源之Why——为什么要参与开源?
中国开源的发展速度发展加快,个人和组织对于为开源作贡献有着前所未有的激情.据<2020年IT行业项目管理调查报告>,约四成受访者以自己开发开源项目.为他人提交项目代码.作为成员开发维护项目 ...
- ET8.1(一)简介
此系列文章逐个内容讲解ET8.1的新特性. ET8.1 发布,带来以下新特性: 1. 多线程多进程架构,架构更加灵活强大,多线程设计详细内容请看多线程设计课程 2. 抽象出纤程(Fiber)的概念 ...
- #二进制拆分,矩阵乘法#洛谷 6569 [NOI Online #3 提高组] 魔法值
题目 分析 考虑一个点的权值能被统计到答案当且仅当其到1号点的路径条数为奇数条. 那么设 \(dp[i][x][y]\) 表示从 \(x\) 到 \(y\) 走 \(i\) 步路径条数的奇偶性, 这个 ...
- #欧拉函数#洛谷 2303 [SDOI2012] Longge 的问题
题目 求\(\sum_{i=1}^n\gcd(n,i)\) 分析 \(=\sum_{i=1}^n\sum_{d|gcd(n,i)}\varphi(d)\) \(=\sum_{d|n}\varphi(d ...
- clang的lto特性的资料
clang对lto的支持,如下文章介绍的清晰.易懂. ThinLTO llvm+clang 添加 LTO(Link Time Optimization) 支持 编译优化之 - 链接时优化(LTO)入门 ...
- DevEco Studio的这些预览能力你都知道吗?
在万物互联的今天,开发者在应用/服务开发过程中,需要考虑应用/服务在不同设备上的运行效果.为满足这一需求,DevEco Studio 作为 HarmonyOS 和 OpenAtom OpenHarmo ...