一次Java服务内存过高的分析过程
现象
年前,收到了短信报警,显示A服务的某台机器内存过高,超过80%
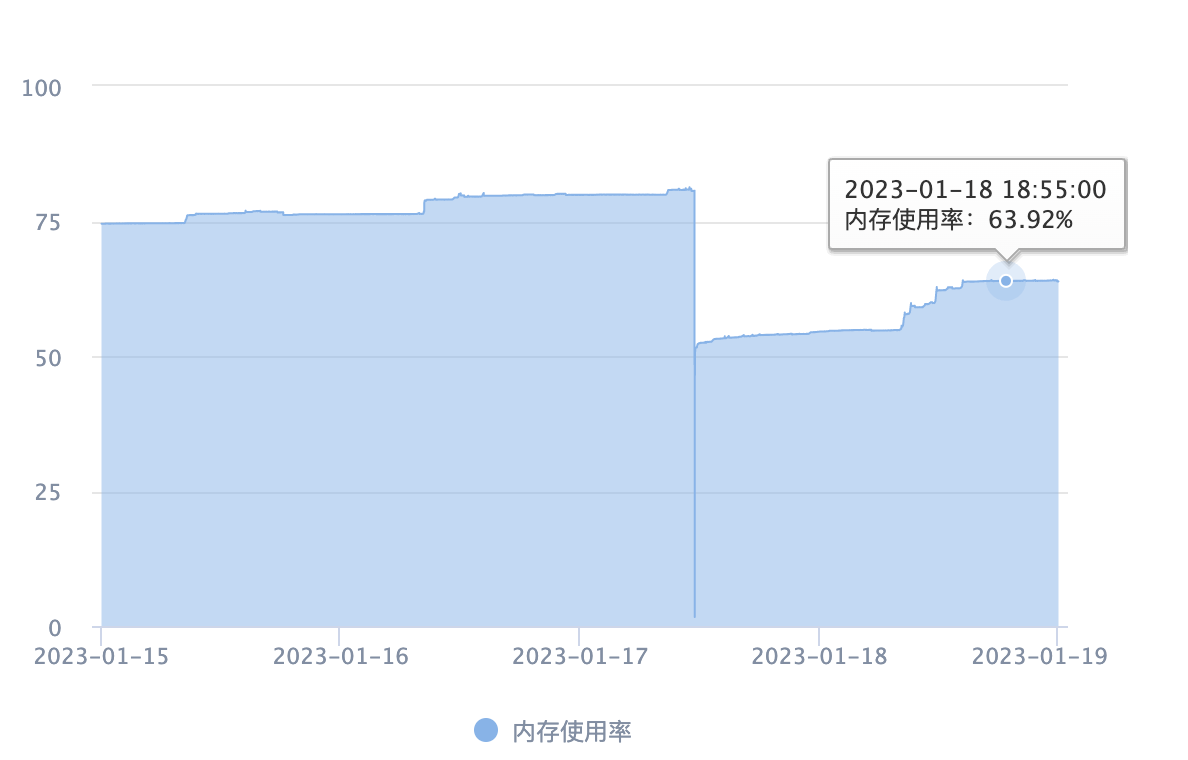
如上图所示,内存会阶段性增加。奇怪的是,十多台机器中只有这一台有这个问题
堆内内存分析
最先怀疑是内存泄漏的问题,所以首先使用jmap命令把堆dump下来
jmap -dump:format=b,file=service.hprof 1948
用MAT分析堆文件发现了一个奇怪的问题,下载下来7G的文件MAT显示的Size只有700M
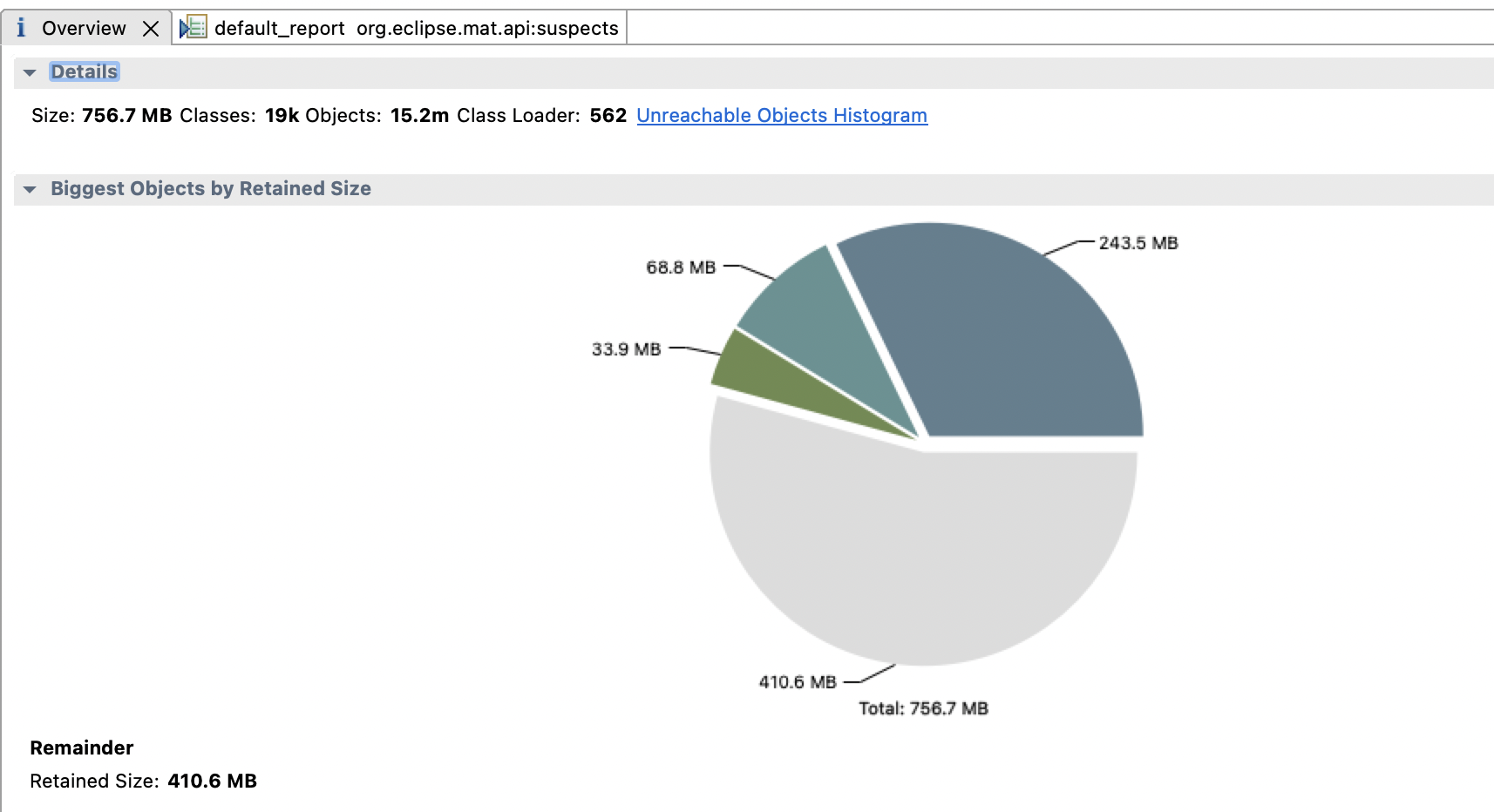
后来知道不加live选项会把堆中所有的对象dump下来,即使是已经是垃圾的对象
参考 what are "live" objects in java heap? (heap dump with jmap)
live 选项会在讲堆内容dump到文件时,强制做一次fullGC,剩下的就是live对象,也就是从GC Root可以寻达的对象
为什么有时不能用live呢,因为fullGC可能会让应用卡主,不能接受这种情况适用不增加live选项
后来我重新使用了live选项dump下来有900M
jmap -dump:live,file=live-dump.bin <pid>
MAT的内存泄漏报告
首先用MAT的Leak Suspect看一下
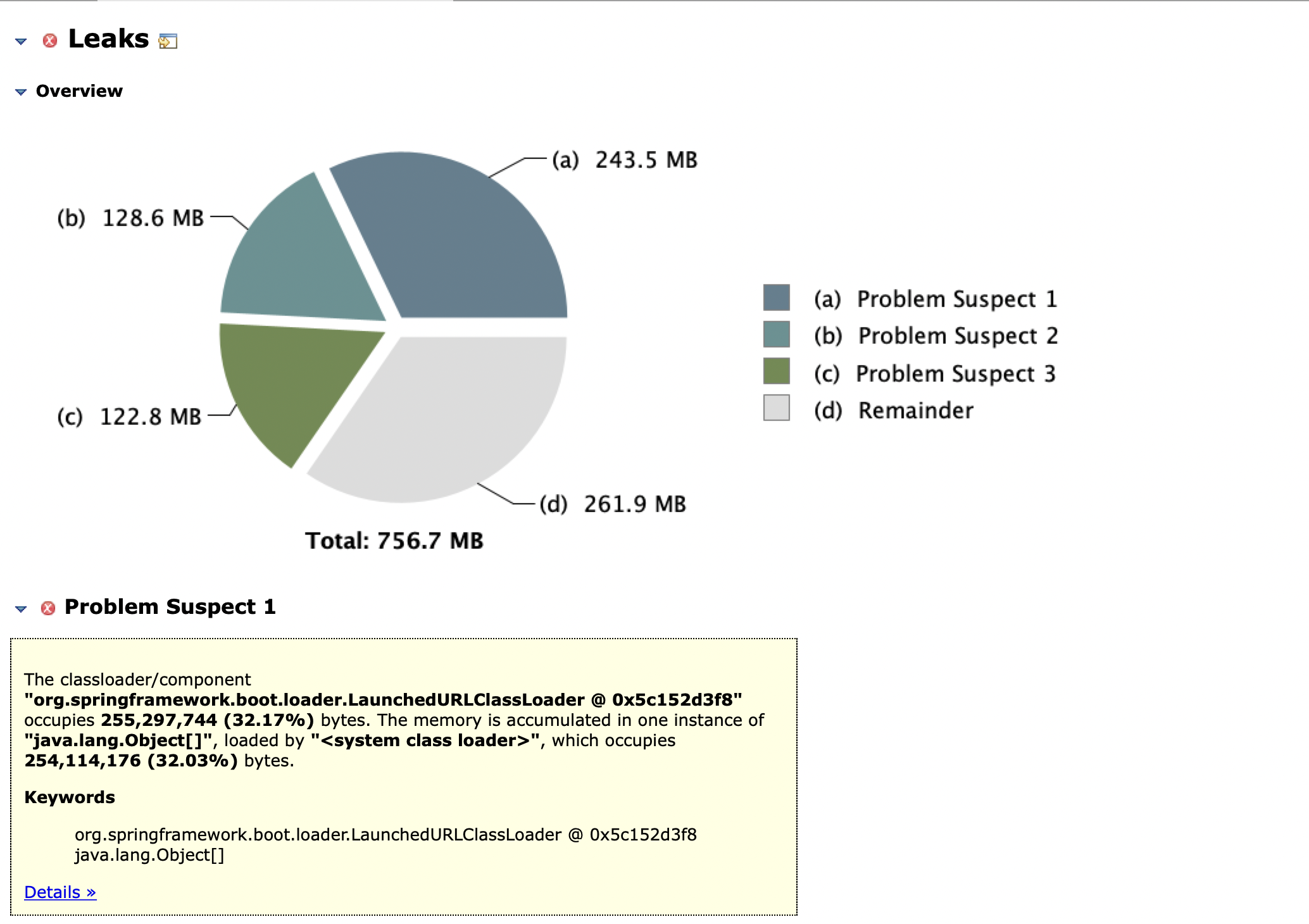
看到了org.springframework.boot.loader.LaunchedURLClassLoader这个对象有240M
因为一直不太清楚live选项的原因,所以就想用其他工具看看这7G到底都是什么
IDEA自带工具分析

把hprof拖入IDEA,就可以看到上图,上面分析了所有的对象,从占用的大小就可以看出来
其中的Shallow表示的是:
对象本身占用内存的大小,也就是对象头加成员变量(不是成员变量的值)的总和
Retained表示的是:
如果一个对象被释放掉,那会因为该对象的释放而减少引用进而被释放的所有的对象(包括被递归释放的)所占用的heap大小,即对象被垃圾回收器回收后能被GC从内存中移除的所有对象之和。
具体参考一文让你理解什么是shallow heap及retained heap
我们把前几名的Shallow加起来也有好几G了
也可以点进Object[]查看这700多万的对象数组都是什么

可以看到一个占用450M的Object[10240]属于LaunchedURLClassLoader

上图中可以看到这450M中TagCateSimilarityUtils占了200M, 这是一个本地缓存,虽然占的多了一点,通过比对正常服务器的堆转储,是没有问题的
查看int[]对象时,发现了很多Retained是0的对象,也就是说这些对象已经是不可达对象,只不过还没有被回收,那是不是就是只要让这些对象回收了,内存占用就下来了

解决垃圾回收问题
上面分析中看到了很多对象没有被回收,怀疑是没有FullGC(Mixed)所以老年代中的垃圾对象,一直都没回收,看了一下JVM参数
-Xmx8g -Xms8g -Xmn4g -Xss1024K -XX:PermSize=256m -XX:MaxPermSize=512m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:G1HeapRegionSize=32m -Dfastjson.parser.safeMode=true
调整为,删除了一些默认和不生效的参数,移除了Xmn,交给G1自己调整
-Xmx8g -Xms8g -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:G1HeapRegionSize=32m -Dfastjson.parser.safeMode=true
不过并没有解决问题,此时我发现了新的问题:
- 按理GC完只有不到1G的对象,为什么监控中会显示内存很高呢
- 设置了Xms=8g,按理一启动就会占用至少8G内存,监控为什么是从6G开始增长的
这个问题和虚拟内存和实际内存有关,可以参考linux top命令 实存(RES)与虚存(VIRT)详解
VIRT:
1、进程“需要的”虚拟内存大小,包括进程使用的库、代码、数据,以及malloc、new分配的堆空间和分配的栈空间等;
2、假如进程新申请10MB的内存,但实际只使用了1MB,那么它会增长10MB,而不是实际的1MB使用量。
RES:
1、进程当前使用的内存大小
2. 如果申请10MB的内存,实际使用1MB,它只增长1MB,与VIRT相反;
监控显示的内存是实际占用的内存,Xms设置的是虚拟内存,参考降低 Java 程序的“虚拟内存地址”占用
可以看出 Java Heap 与 Metaspace 紧挨着分配,两块一共占用了 3GB 的 Size(虚拟内存地址空间),而表征物理内存占用的 Rss 却只有 673288KB。也就是说,mmap 只是给进程分配一个线性区域(虚拟内存),并没有分配物理内存,只有当进程访问这块内存时,操作系统才会分配具体的内存页给进程,这就是 Linux 内存管理的延迟分配策略
内存一旦被分配给Java程序,就不会还给操作系统了,所以监控看起来内存就是只增不减,个人理解这样对于Java程序也是有好处的,不用频繁申请内存,对于垃圾的区域标记然后就可以重新写了
Java也存在JVM参数-XX:+AlwaysPreTouch 来实现启动就把堆内存全都申请到
为了抵消延迟分配策略,在进程启动时强制分配好 Java Heap 的物理内存,虽然增加了启动延时,但是可以减少进程运行时由于分配内存造成的延时
总结
堆内内存是正常的,不存在内存泄漏,只是正常的内存使用增长
堆外内存分析
在搜索LaunchedURLClassLoader内存泄漏问题时,看到了Spring Boot引起的“堆外内存泄漏”排查及经验总结,学到了如何进行堆外内存分析
一次完整的JVM堆外内存泄漏java故障排查记录也是一篇值得学习的如何分析堆外内存的文章
不过我们问题产生的原因和上面的不一致
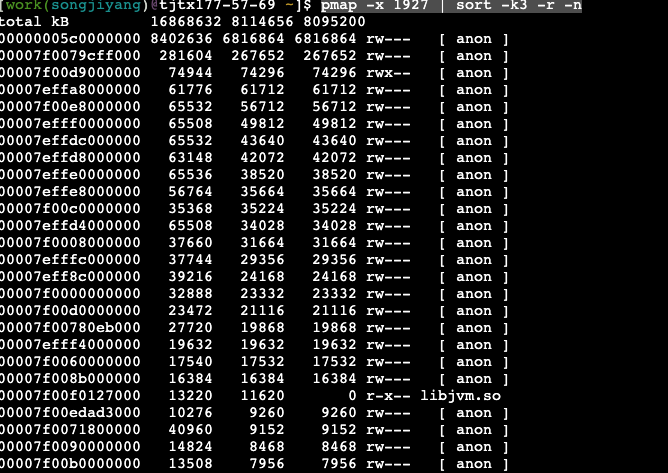
使用pmap分析应用的内存占用,但不太容易看出是什么占用了内存
pmap -x 1927 | sort -k3 -r -n
JVM的NativeMemoryTracking参数会看到更详细,不过需要重启,而且会有5%-10%的性能损耗
// 写在启动参数上面
-XX:NativeMemoryTracking=detail
// 生成内容在下图中
jcmd 1927 VM.native_memory detail scale=MB > temp3.txt
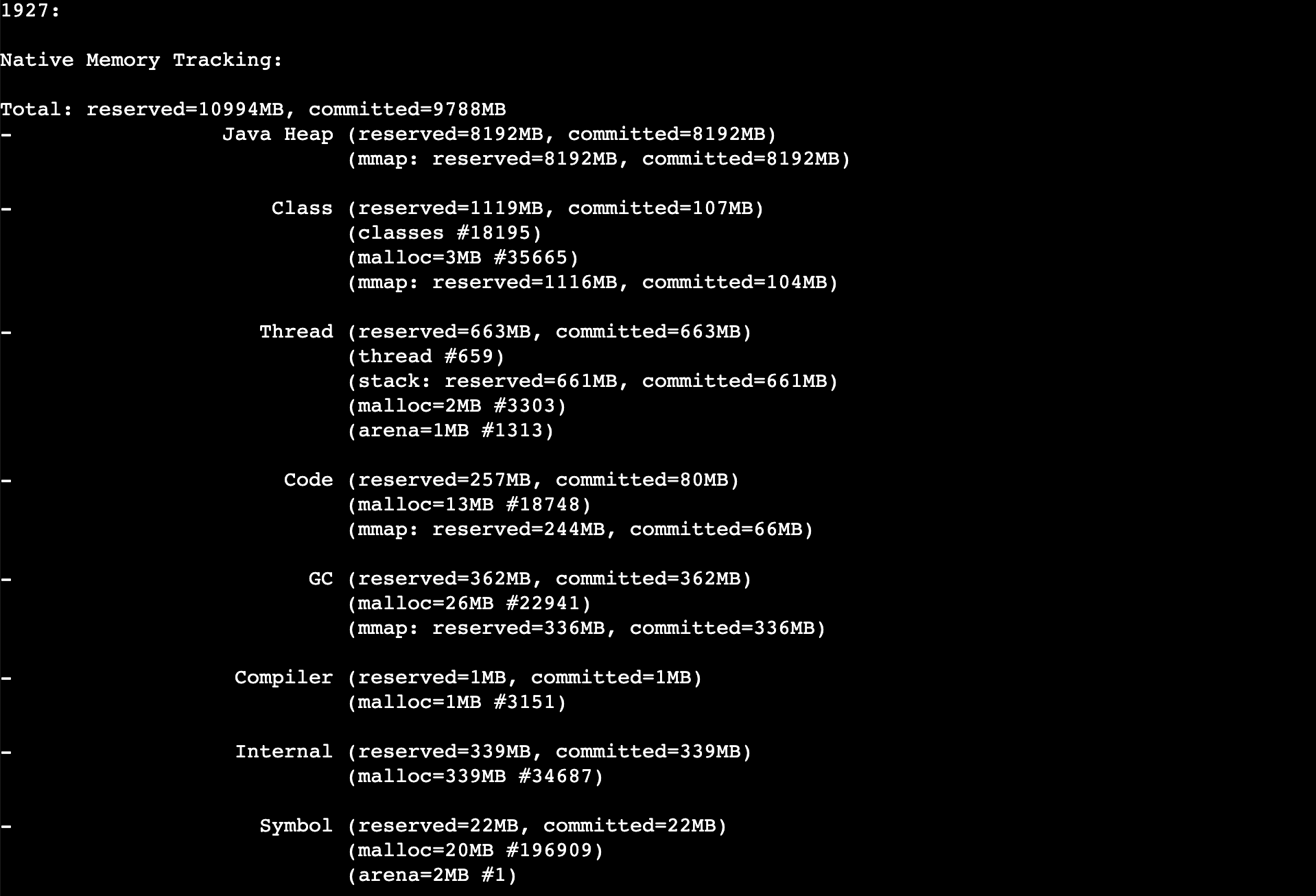
经过对堆外内存的观察,发现确实有一些比较高,例如线程占700M,发现了有很多不必要的线程,但不是随着时间不断增加的
上图中的Total一行的commited=9788MB,表示Java应用程序堆内加堆外内存最大可达这么多,这么一算12 * 0.8 = 9.6G,确实超了报警阈值
这样看来,堆外内存也没有问题,是Xmx和内存阈值设置的不匹配,导致内存正常使用的情况下报警了,也是没有合理预估堆外内存占用的原因,堆外占了快2G的内存
将报警阈值调到85%,发现内存在周期性的增长和减少,并不会超过阈值,如下图
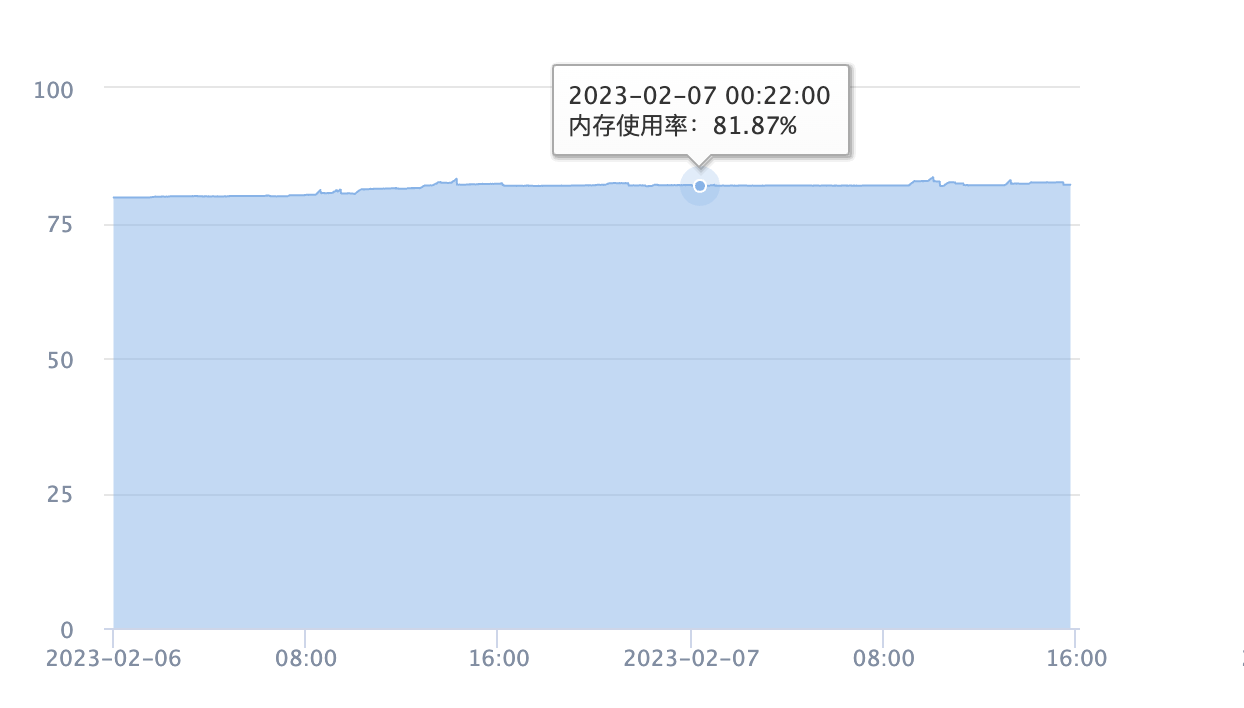
总结
服务的内存使用情况是正常的,无论是堆内还是堆外内存,需要做的是设置合理的堆内存大小,预估堆外内存大小,合理设置报警阈值
通过这次分析也学习了如何对Java程序内存进行分析,也学习了很多工具
也意思到监控工具的重要性,在看别人分析的过程中,一般都会对JVM资源进行监控,这样就能很明显看出资源的动态,因为我们目前没有这样的工具,所以分析起来就比较麻烦
附
前面提到其中只有一台机器有这个现象,还没有找到原因,不过有几个现象:
- 内存增长快
- 部分日志大小比其他机器大
- 耗时每隔一段时间会增加
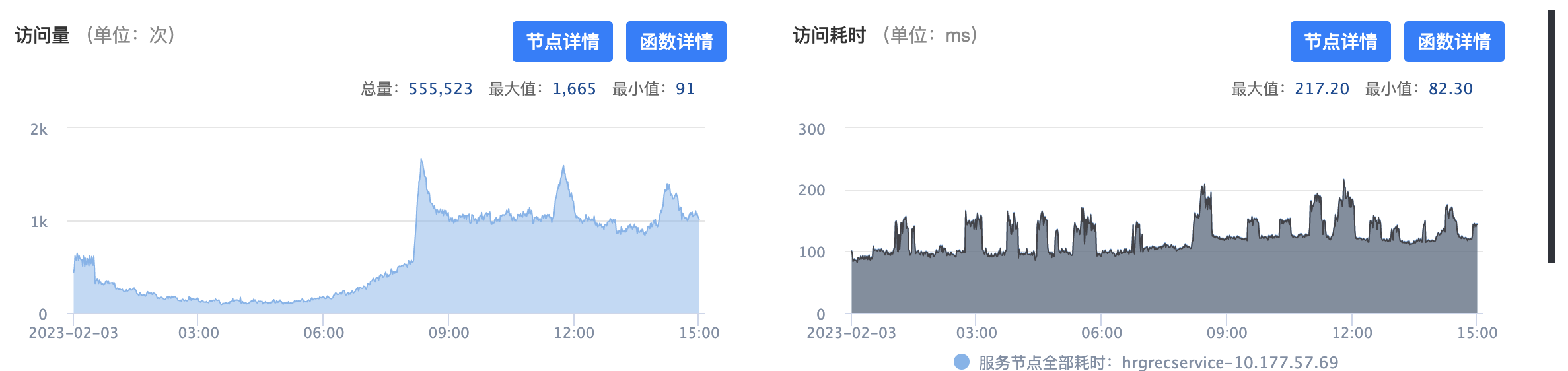
对比日志发现是Redis超时比较多,所以怀疑可能是机器网络的问题,不过目前还无结论
参考
[1] 一文让你理解什么是shallow heap及retained heap
[2] linux top命令 实存(RES)与虚存(VIRT)详解
[3] 降低 Java 程序的“虚拟内存地址”占用
[4] 一次完整的JVM堆外内存泄漏java故障排查记录
[5] Spring Boot引起的“堆外内存泄漏”排查及经验总结
一次Java服务内存过高的分析过程的更多相关文章
- Java服务器内存过高&CPU过高问题排查
一.内存过高 1.内存过高一般有两种情况:内存溢出和内存泄漏 (1)内存溢出:程序分配的内存超出物理机的内存大小,导致无法继续分配内存,出现OOM报错 (2)内存泄漏:不再使用的对象一直占据着内存不释 ...
- 性能分析 | Java服务器内存过高&CPU过高问题排查
一.内存过高 1.内存过高一般有两种情况:内存溢出和内存泄漏 (1)内存溢出:程序分配的内存超出物理机的内存大小,导致无法继续分配内存,出现OOM报错 (2)内存泄漏:不再使用的对象一直占据着内存不释 ...
- 一个驱动导致的内存泄漏问题的分析过程(meminfo->pmap->slabtop->alloc_calls)
关键词:sqllite.meminfo.slabinfo.alloc_calls.nand.SUnreclaim等等. 下面记录一个由于驱动导致的内存泄漏问题分析过程. 首先介绍问题背景,在一款嵌入式 ...
- JAVA服务cpu占用高排查
最近线上机器偶尔有台cpu达到100%,还居高不下.同样负载的其他机器却正常,我想肯定是代码哪里有问题了 首先我们top看下 可定位到对应占用高的PID 然后=>ps -mp PID -o TH ...
- Java服务CPU占用高问题定位方法
1. 概述 提供一种简单的方法来定位CPU高的问题. 找到CPU高的进程,比如232543: 执行top -H -p pid,找到占用CPU最高的线程号,比如232544,转换成16进制38c60: ...
- java线程数过高原因分析
作者:鹿丸不会多项式 出处:http://www.cnblogs.com/hechao123 转载请先与我联系. 一.问题描述 前阵子我们因为B机房故障,将所有的流量切到了A机房,在经历了推送+ ...
- Mysql占用内存过高的优化过程
一.环境说明: 操作系统:CentOS 6.5 x86_64 数据库:Mysql 5.6.22 服务器:阿里云VPS,32G Mem,0 swap 二.问题情况: 1.某日发现公司线上系统的Mysql ...
- cpu 或 内存 偏高的分析套路
参考资料: https://mp.weixin.qq.com/s/fb9YxJr-yDdYQ86RE47y1w 1)通过针对此软件专业的分析工具或命令,找到占用cpu高的函数,2)通过调用栈(或源码搜 ...
- 记一次Mysql占用内存过高的优化过程
一.环境说明: 操作系统:CentOS 6.5 x86_64 数据库:Mysql 5.6.22 服务器:阿里云VPS,32G Mem,0 swap 二.问题情况: 1.某日发现公司线上系统的Mysql ...
- linux下分析java程序占用CPU、内存过高
一.CPU过高分析 1)使用TOP命令查看CPU.内存使用状态可以发现CPU占用主要分为两部分,一部分为系统内核空间占用CPU百分比,一部分为用户空间占用CPU百分比.其中CPU状态中标示id的为空闲 ...
随机推荐
- Python的国内安装源(也称为镜像源)
Python的国内安装源(也称为镜像源)数量会随着时间而增加或减少,因为新的镜像源可能会建立,而一些旧的镜像源可能会停止服务或不再更新.以下是一些常用的Python国内安装源(也称为PyPI镜像源): ...
- WEB服务与NGINX(24)- LNMP架构部署wordpress
目录 1. LNMP架构项目实战 1.1 LNMP架构介绍 1.2 LNMP架构部署wordpress 1.2.1 LNMP环境介绍 1.2.2 二进制部署mariadb 1.2.3 部署php-fp ...
- 莫队算法(基础莫队)小结(也做markdown测试)
莫队 基础莫队 本质是通过排序优化了普通尺取法的时间复杂度. 考虑如果某一列询问的右端点是递增的,那么我们更新答案的时候,右指针只会从左往右移动,那么i指针的移动次数是$O(n)$的. 当然,我们不可 ...
- 学习c# 7.0-7.3的ref、fixed特性并在Unity下测试
1.ref的一些运用 1.1 ref readonly 关于ref,一个主要应用是防止结构体拷贝,若返回的结构体不需要修改则用ref readonly,类似c++的const标记 : private ...
- 一文搞懂RESTful开发
REST(Representational State Transfer),表现形式状态转换,它是一种软件架构风格 当我们想表示一个网络资源的时候,可以使用两种方式: 传统风格资源描述形式 http: ...
- ollama 源代码中值得阅读的部分
阅读 Ollama 源代码以了解其内部工作机制.扩展功能或参与贡献,以下是一些值得重点关注的部分: 1. 核心服务模块: 查找负责启动和管理模型服务的主程序或类,这通常是整个项目的核心逻辑所在.关注如 ...
- kubernetes运行应用Controller3之Job、CronJob详解
成功启动一个Job 1.Job.spec.template.metadata,没有空格符的错误 [machangwei@mcwk8s-master ~]$ cat mcwJob1.yml apiVer ...
- 解决idea 控制台输出乱码问题:
解决idea 控制台输出乱码问题[IntelliJ IDEA 2022.1.3 (Ultimate Edition)]: 将两个地方文件编码设置成GBK 参考文档:https://blog.c ...
- 【BI 可视化插件】怎么做? 手把手教你实现
背景 对于现在的用户来说,插件已经成为一个熟悉的概念.无论是在使用软件. IDE 还是浏览器时,插件都是为了在原有产品基础上提供更多更便利的操作.在 BI 领域,图表的丰富性和对接各种场景的自定义是最 ...
- 3分钟部署 我的世界(Minecraft) 联机服务
游戏简介 我的世界(Minecraft)是一款沙盒类电子游戏,该游戏以玩家在一个充满着方块的三维空间中自由地创造和破坏不同种类的方块为主题.玩家在游戏中可以在单人或多人模式中通过摧毁或创造精妙绝伦的建 ...