使用flume将数据sink到kafka
flume采集过程:
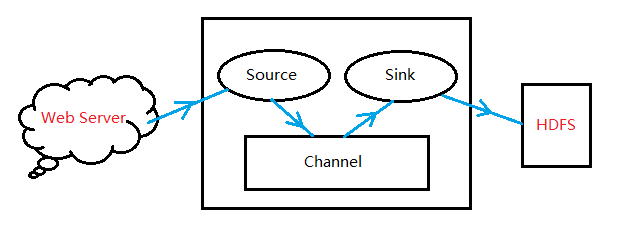
#说明:案例是flume监听目录/home/hadoop/flume_kafka采集到kafka;
启动集群
启动kafka,
启动agent,
flume-ng agent -c . -f /home/hadoop/flume-1.7.0/conf/myconf/flume-kafka.conf -n a1 -Dflume.root.logger=INFO,console
开启消费者
kafka-console-consumer.sh --zookeeper hdp-qm-01:2181 --from-beginning --topic mytopic
生产数据到kafka
数据目录:
vi /home/hadoop/flume_hbase/word.txt
12345623434
配置文件
vi flume-kafka.conf
#Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir=/home/hadoop/flume_kafka
# Describe the sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = mytopic
a1.sinks.k1.kafka.bootstrap.servers = hdp-qm-01:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.ki.kafka.producer.compression.type = snappy
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
使用flume将数据sink到kafka的更多相关文章
- 如何用Flink把数据sink到kafka多个(成百上千)topic中
需求与场景 上游某业务数据量特别大,进入到kafka一个topic中(当然了这个topic的partition数必然多,有人肯定疑问为什么非要把如此庞大的数据写入到1个topic里,历史留下的问题,现 ...
- 如何用Flink把数据sink到kafka多个不同(成百上千)topic中
需求与场景 上游某业务数据量特别大,进入到kafka一个topic中(当然了这个topic的partition数必然多,有人肯定疑问为什么非要把如此庞大的数据写入到1个topic里,历史留下的问题,现 ...
- flume将数据发送到kafka、hdfs、hive、http、netcat等模式的使用总结
1.source为http模式,sink为logger模式,将数据在控制台打印出来. conf配置文件如下: # Name the components on this agent a1.source ...
- flume接收http请求,并将数据写到kafka
flume接收http请求,并将数据写到kafka,spark消费kafka的数据.是数据采集的经典框架. 直接上flume的配置: source : http channel : file sink ...
- 大数据技术之Kafka
Kafka概述 1.1 消息队列 (1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除) 点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息 ...
- flume将数据写入各个组件
一.flume集成hdfs,将数据写入到hdfs a1.sources = r1 a1.sinks = k1 a1.channels = c ...
- 大数据平台搭建-kafka集群的搭建
本系列文章主要阐述大数据计算平台相关框架的搭建,包括如下内容: 基础环境安装 zookeeper集群的搭建 kafka集群的搭建 hadoop/hbase集群的搭建 spark集群的搭建 flink集 ...
- [Spring cloud 一步步实现广告系统] 16. 增量索引实现以及投送数据到MQ(kafka)
实现增量数据索引 上一节中,我们为实现增量索引的加载做了充足的准备,使用到mysql-binlog-connector-java 开源组件来实现MySQL 的binlog监听,关于binlog的相关知 ...
- HBase数据迁移到Kafka实战
1.概述 在实际的应用场景中,数据存储在HBase集群中,但是由于一些特殊的原因,需要将数据从HBase迁移到Kafka.正常情况下,一般都是源数据到Kafka,再有消费者处理数据,将数据写入HBas ...
- 将CSV的数据发送到kafka(java版)
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
随机推荐
- 说一下flex的属性
flex-grow项目的放大比例,默认为0,即如果存在剩余空间,也不放大. flex-shrink属性定义了项目的缩小比例,默认为1,即如果空间不足,该项目将缩小.负值对该属性无效. flex-bas ...
- Vue-Plugin-HiPrint
Vue-Plugin-HiPrint 是一个Vue.js的插件,旨在提供一个简单而强大的打印解决方案.通过 Vue-Plugin-HiPrint,您可以轻松地在Vue.js应用程序中实现高度定制的打印 ...
- 扩展实现Unity协程的完整栈跟踪
现如今Unity中的协程(Coroutine)方案已显得老旧,Unitask等异步方案可以做到异常捕获等yield关键字处理起来很麻烦的问题, 并且Unity官方也在开发一套异步方案,但对于临时加入到 ...
- UnityShader数学基础篇
Mathf Mathf和Math 1.Math是C#中封装好的用于数学计算的工具类,位于System命名空间中. 2.Mathf是Unity中封装好的用于数学计算的工具结构体,位于UnityEngin ...
- 热更学习笔记10~11----lua调用C#中的List和Dictionary、拓展类中的方法
[10]Lua脚本调用C#中的List和Dictionary 调用还是在上文中使用的C#脚本中Student类: lua脚本: print("------------访问使用C#脚本中的Li ...
- 使用 CompeletedFuture 实现异步调用
在我们平时写的项目中,异步调用是一个比较重要的优化手段,在 Java 中,提供了 CompletedFuture 供我们使用,具体实现如下: 例子 假如现在有一个需求,我需要去淘宝.天猫和京东去搜索某 ...
- redis安装和基础使用
redis安装 mkdir /server/tools -p cd /server/tools echo 'PATH=/usr/local/redis/src:$PATH' >>/etc/ ...
- 01-布局扩展-用calc来计算实现双飞翼布局
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8 ...
- vue绑定下拉框 vue修饰符
<select v-model="selected"> <option>请选择</option> <option>HTML</ ...
- kettle从入门到精通 第四十课 kettle 增量同步(分钟/小时级)
1.上一课我们学习了在数据量大的情况下的分页全量同步示例,本次我们一起学习下kettle 增量全量同步.有些业务场景不需要实时数据,比如每N分钟抽取一次数据等. 2.kettle增量全量同步示例依 ...