sql关于group by之后把每一条记录的详情的某个字段值合并提取的方法
在利用group by写了统计语句之后,还有一个查看每一个记录详情的需求,
首先想到的是根据group by的条件去拼接查询条件,
但是条件有点多,拼接起来不仅麻烦,还容易出错,
所以想到要在group by之后同时把详情记录的ID给拼接成逗号分隔的字符串(‘1’,‘2’,‘3’)这种形式,这样再去取详情记录就很简单了
还是万能的博客园里面找到的方法:
select
route_code,domain_id,type_id,COUNT(id0) as cnt,
stuff(
(
----stuff函数用于删除指定长度的字符,并可以在指定的起点处插入另一组字符
select ','+cast(id0 as varchar)---字段拼接
from PMS_T_D_AssetInfo t
where t.route_code=PMS_T_D_AssetInfo.route_code
and t.domain_id=PMS_T_D_AssetInfo.domain_id
and t.type_id=PMS_T_D_AssetInfo.type_id
for xml path('')
)
, 1, 1, '') as idStr
--stuff将参数4的空字符串在参数1字符串的第1个(参数2)字符位置起替换掉1(参数3)个长度
from
PMS_T_D_AssetInfo
group by
route_code,domain_id,type_id
得到的结果如下:
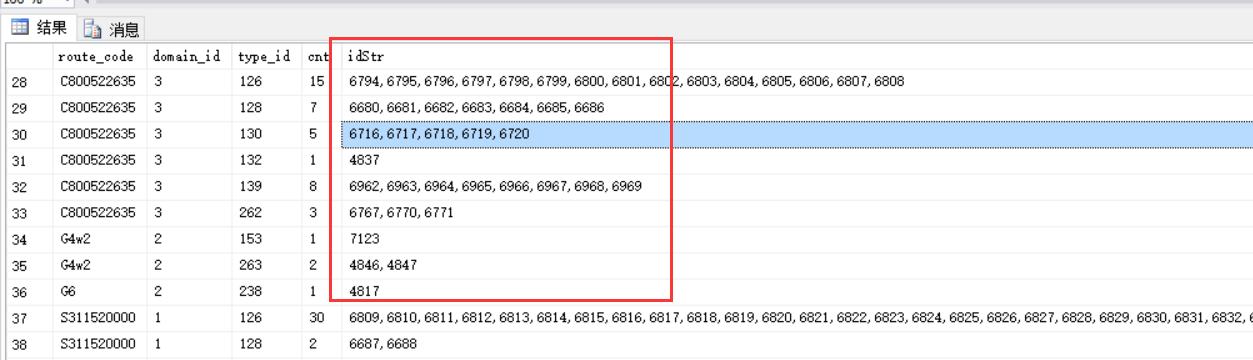
效果看上去很好,
但是,
统计数据大了之后,这个拼接字段会非常长,最后想想还是算了,还不如我直接拼接查询条件呢,
但是,这个方法还是不错的,在拼接字段明确有限的情况下可以用!
最后,
附上新认识的stuff函数简介:
一、作用
删除指定长度的字符,并在指定的起点处插入另一组字符。
二、语法
STUFF ( character_expression , start , length ,character_expression )
参数
character_expression
一个字符数据表达式。character_expression 可以是常量、变量,也可以是字符列或二进制数据列。
start
一个整数值,指定删除和插入的开始位置。如果 start 或 length 为负,则返回空字符串。如果 start 比第一个 character_expression 长,则返回空字符串。start 可以是 bigint 类型。
length
一个整数,指定要删除的字符数。如果 length 比第一个 character_expression 长,则最多删除到最后一个 character_expression 中的最后一个字符。length 可以是 bigint 类型。
返回类型
如果 character_expression 是受支持的字符数据类型,则返回字符数据。如果 character_expression 是一个受支持的 binary 数据类型,则返回二进制数据。
示例:
select STUFF('abcdefg',1,0,'') --结果为'1234abcdefg'
select STUFF('abcdefg',1,1,'') --结果为'1234bcdefg'
select STUFF('abcdefg',2,1,'') --结果为'a1234cdefg'
select STUFF('abcdefg',2,2,'') --结果为'a1234defg'
sql关于group by之后把每一条记录的详情的某个字段值合并提取的方法的更多相关文章
- SQL 一条记录的的两个字段值相同与不同的查询
select * from (select xm,je from table) a , (select xm01,je01 from table) bwhere a.xm = b.xm01and a. ...
- 通过sql的stuff 把一列几行的记录拼接在一行一个字段
---通过sql的stuff 把一列几行的记录拼接在一行一个字段 select FID,a.FCustomerID as 工地ID , 应验收节点 = (stuff((select ',' + isn ...
- Sql语句groupBY分组后取最新一条记录的SQL
一.问题 groupBY分组后取最新一条记录的SQL的解决方案. 二.解决方案 select Message,EventTime from PT_ChildSysAlarms as a where E ...
- SQL SERVER 2008 字段值合并
/** * 通过 FOR XML PATH 语句,可以将字段的值进行合并. **/ CREATE TABLE tb_child ( name ), hobby ) ) go INSERT INTO t ...
- SQL 分组获取最近(大)一条记录
SELECT MAX( table.Column),.... FROM table.Name WHERE ....... GROUP BY 分组规则
- sql 中实现往表中插入一条记录并返回当前记录的ID
写一条存储过程,实现往User中插入一条记录并返回当前UserId(自增长id) --推荐写法 if(Exists(select * from sys.objects where name=N'Usp ...
- 【ORACLE】SQL查询出每个组中的第一条记录
CREATE TABLE [TestTable] ( ) NOT NULL , ) NOT NULL , ) ))) GO ALTER TABLE [TestTable] ADD PRIMARY KE ...
- 删除oracle 表中重复数据sql语句、保留rowid最小的一条记录
delete from tablename a where rowid > ( select min(rowid) from table_name b where b.id = a.id and ...
- sql server 更新满足条件的某一条记录
上图数据:SNum为”18004XXXXX000001K2GW 4000 L1C“,OffLineStation为“OP1010”的有两条数据,当where条件中为上述两者时会同时更新这两条数据,并不 ...
随机推荐
- 关于网络流sap算法
今天终于学习了网络流..之前一直很怕这类问题,个人觉得网络流算是图论里面最难的了.... sap学习下来感觉一般,关于解法都是意识流,细节也是蛮多的.. 我这里先贴一份模版,自已也加了点注释(只是个人 ...
- java笔记之面向对象
一.面向过程与面向对象的区别 1 面向过程:主要关注点是:实现的具体过程,因果关系[集成显卡的开发思路] * 优点:对于业务逻辑比较简单的程序,可以达到快速开发,前期投入成本较低. * 缺点:采用面向 ...
- 用asyncio的异步网络连接来获取sina、sohu和163的网站首页
代码如下: import asyncio async def wget(host): print('wget %s...' % host) connect = asyncio.open_connect ...
- mysql原创博客
http://blog.itpub.net/15480802/viewspace-1755100/
- 用yum安装完mysql后没有mysqld的问题
在Centos中用命令 yum install mysql安装数据库,但装完后运行mysqld启动mysql的时候提示找不到,通过 find / | grep mysqld 也没找到mysqld的目录 ...
- (原)未能启用约束。一行或多行中包含违反非空、唯一或外键约束的值与DATEADD
SQLServer2014,查询分析器中 这样的脚本是没有问题的:AND TPO.CREATEON <= DATEADD(DAY, 1, '2017/3/3 0:00:00') 但.NET D ...
- WebLogic 1036的镜像构建
WebLogic1035版本构建出来的镜像有问题,部署应用激活后返回的是后面pod的ip和端口号,在1036版本和12.1.3版本都无此问题. weblogic 1036的Dockerfile [ro ...
- go语言基础之iota枚举
1.iota (在常量的时候,当成枚举使用) 示例1 package main import "fmt" func main() { //1.iota常量自动生成器,每个一行,自动 ...
- 一个手绘normal的方法
https://polycount.com/discussion/98983/how-to-paint-flow-anisotropic-comb-maps-in-photoshop flow map ...
- Linux内核源码情景分析-系统调用
一.系统调用初始化 void __init trap_init(void) { ...... set_system_gate(SYSCALL_VECTOR,&system_call);//0x ...